2강 - Text mining
자연어 처리 - 사람의 언어를 컴퓨터가 이해할 수 있는 체계인 숫자로 변환하여 번역, 감성분석, 정보 요약 등 다양한 TASK를 처리하는 것
컴퓨터가 이해할 수 있는 체계로의 변환 == encoding (one hot encoding) -> embedding (vector representation)
근데 이게 언어의 특성 때문에 어렵다!
1. 동음 이의어
2. 사회적으로 공유되는 정보, 지식, 경험들
3. 모호성

POS - 품사 (명사, 형용사, 동사..)
Named entities - 인물, 지역, 나라...
Syntax - 문법(의존 관계, 수식..)
3강 - word embedding
이전에는 원 핫 인코딩을 통해 단순히 단어 수의 차원을 통해 인코딩하여 sparse했다
TD == 통계를 활용한 임베딩 방식 - 특정 문서에서 단어가 얼마나 나왔는지 표현한다.

의미적으로 비슷한 단어는 벡터가 비슷하다.

유사도는 이 Cos을 통해 구한다.
문서가 많아질수록, 단어가 많을수록 이 방식은 효율이 떨어진다.
-> 모든 문서에서 자주 나온다 == 중요도( 가중치)가 낮다
-> 일부 문서에서만 나온다 == 중요도 ( 가중치)가 높다
=> TF-IDF!!

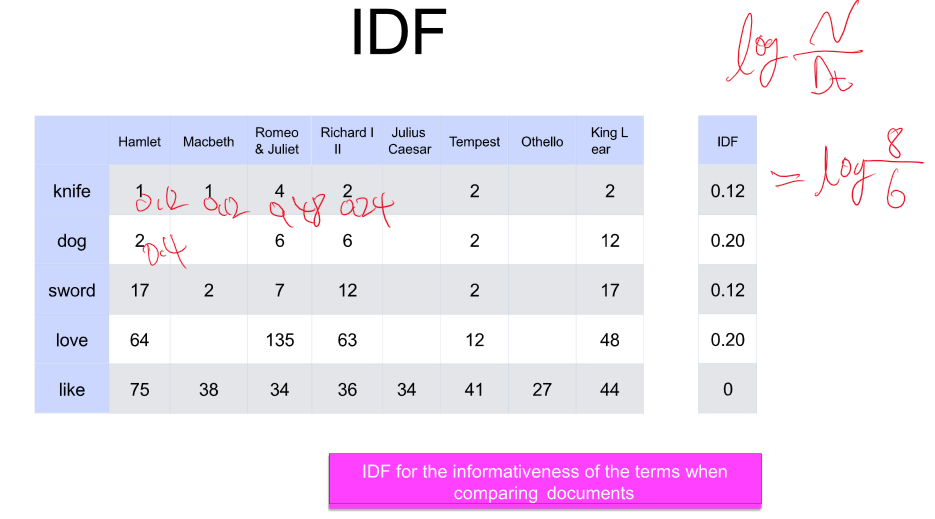
그러나 여기서도 문서가 많아질수록 Sparse vectors (희소 백터)가 되는 것을 피할 수 없다.
Dense vector로 어떻게 변환할까? - 주변 단어 맞추기를 통해 FCN을 지도 학습시켜 파라미터를 사용하자!
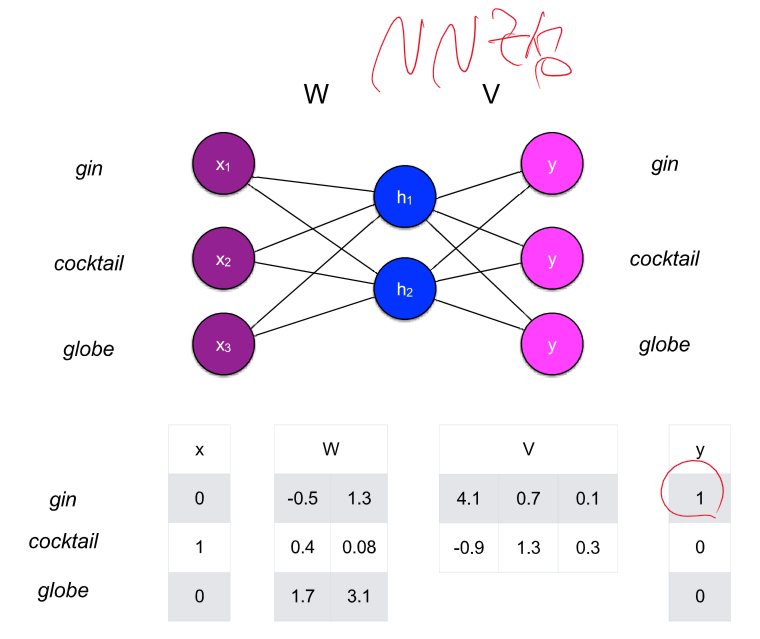
이렇게 구한 embedding을 표현해보면 비슷한 단어들의 cos 유사도는 높게 나오고 관련 없는 단어는 0이 나오게 된다.
라벨링이 잘 되어있는 데이터 - 모델 학습용으로 사용
라벨링이 안 되어있는 데이터 - 단어의 분포를 알기 위해 학습용으로 사용
4강 - Word embedding 2
vector representation - 문맥에 대한 분포 포함, 비슷한 문맥에서 나타나는 단어들은 비슷한 백터 표현을 가진다.
그러나 순서 정보가 없다.
Word embedding - 미리 학습했던 자주 나오는 단어에 대해서는 성능이 좋다.
But 모르는 단어에 대한 대처가 필요하다. -> 기본형으로 변환 (Sub word)
Subword 모델은 텍스트 데이터를 처리할 때, 단어를 더 작은 단위인 subwords나 morphemes로 분해하여 사용하는 방법입니다. 이 접근 방식은 언어의 모르는 단어(out-of-vocabulary, OOV) 문제를 줄이고, 언어의 구조적인 세부사항을 더 잘 반영할 수 있도록 합니다. 예를 들어, "unhappiness"라는 단어를 "un-", "happy", "-ness"와 같은 의미 있는 조각으로 분할하여 학습에 활용할 수 있습니다. 이러한 모델은 BERT나 GPT와 같은 현대의 NLP 시스템에서 널리 사용됩니다.

FastText는 Facebook에서 개발한 자연어 처리 라이브러리로, Word2Vec의 아이디어를 기반으로 합니다. 하지만 FastText는 각 단어를 개별적인 단위로만 처리하는 대신에, 단어를 여러 개의 n-gram(subwords)으로 분해하여 각 n-gram의 임베딩을 학습하고, 최종 단어의 표현을 이들 n-gram 벡터의 합으로 계산합니다. 이 접근법은 단어 내에 내재된 형태학적 정보를 활용할 수 있게 하며, 특히 희귀 단어나 신조어 처리에 유리하고, 다양한 언어의 복잡한 형태학을 가진 단어들에 대해서도 더 강력한 표현력을 제공합니다.
자연어는 순서가 있는 데이터이므로 RNN 계열이 사용된다.
Bidriectional RNN - 양방향 RNN (ELMo 다음 단어 예측)
-> Contextualized embedding - 단어의 의미가 문장에 따라 다르다. -> 문장의 구성에 따라 임베딩이 변한다.
자연어 처리 수업 자료 요약
이 자료는 단어 임베딩에 대한 깊은 이해를 제공하고, 구체적인 모델들과 그 기능에 대해 설명합니다. 여기에는 Word2Vec, GloVe, FastText와 같은 정적 단어 임베딩 방법과 ELMo, BERT와 같은 컨텍스트에 민감한 동적 임베딩 방법이 포함됩니다. 또한, 어텐션 메커니즘과 이를 통한 단어의 중요성 학습, 양방향 RNN(BiRNN)과 이를 활용한 언어 모델링에 대해서도 다룹니다.
OX 퀴즈 / 빈칸 퀴즈
- Word2Vec은 컨텍스트를 고려하여 단어 임베딩을 생성한다. (O/X)
- GloVe는 단어의 공동 출현 정보를 기반으로 임베딩을 수행한다. (O/X)
- FastText는 _____를 활용하여 단어를 임베딩한다.
- BERT는 단방향 언어 모델로 설계되었다. (O/X)
- ELMo는 _____의 영향을 받아 단어의 임베딩을 결정한다.
- 어텐션 메커니즘은 모든 단어에 동일한 중요도를 부여한다. (O/X)
- 양방향 RNN은 과거와 미래의 컨텍스트 모두를 고려한다. (O/X)
- BERT의 학습 과정에는 _와 _ 예측이 포함된다.
- FastText는 훈련되지 않은 단어에 대해서도 효과적인 임베딩을 제공할 수 있다. (O/X)
- Word2Vec과 GloVe는 각각 컨텍스트의 순서를 고려하고 고려하지 않는다. (O/X)
퀴즈 정답
- Word2Vec은 컨텍스트를 고려하여 단어 임베딩을 생성한다. (O)
- GloVe는 단어의 공동 출현 정보를 기반으로 임베딩을 수행한다. (O)
- FastText는 서브워드(subword) 정보를 활용하여 단어를 임베딩한다.
- BERT는 단방향 언어 모델로 설계되었다. (X, BERT는 양방향 컨텍스트를 고려)
- ELMo는 컨텍스트의 영향을 받아 단어의 임베딩을 결정한다.
- 어텐션 메커니즘은 모든 단어에 동일한 중요도를 부여한다. (X, 중요도는 단어마다 다름)
- 양방향 RNN은 과거와 미래의 컨텍스트 모두를 고려한다. (O)
- BERT의 학습 과정에는 마스크된 언어 모델링(Masked Language Modeling)와 다음 문장 예측(Next Sentence Prediction)이 포함된다.
- FastText는 훈련되지 않은 단어에 대해서도 효과적인 임베딩을 제공할 수 있다. (O)
- Word2Vec과 GloVe는 각각 컨텍스트의 순서를 고려하고 고려하지 않는다. (X, GloVe는 순서를 고려하지 않으며 Word2Vec은 윈도우 내에서의 순서를 부분적으로 고려)
5강 - Deep learning recap 1
affine - 이전에 들어온 값 or input을 파라미터와 곱하고 bias를 더하는 과정(xw + b = h)
Softmax를 사용하는 이유 - 최대값에 민감하게 반응
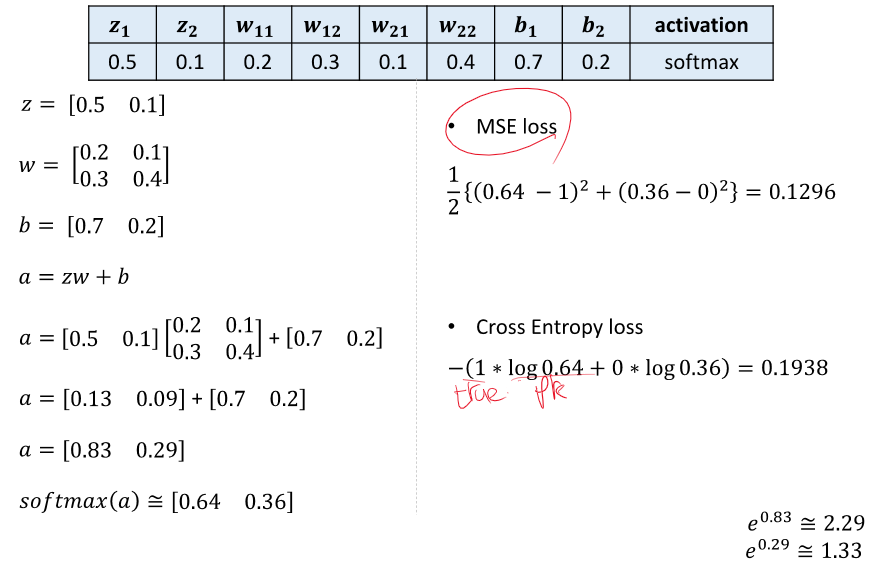
Loss function을 이용한 gradient decent 사용하여 파라미터 및 편향 업데이트 == 항상 미분하는게 문제....
미분 == 체인룰을 활용하여 이전 값을 계속해서 사용하기!
이건 다른 강의 자료에서 가져오겠습니다.




깔끔하게 보기 좋게 정리를 해둔게..
6강 - Deep learning recap 2
SGD - 샘플마다 업데이트하기 때문에 진동이 크지만 학습 속도가 빠르다.
batch learning - 모든 데이터 셋을 다 사용한 뒤 업데이트를 하면 진동은 적지만 local min에 빠질 가능성이 크다.
mini-batch - 두 가지를 적절하게 섞어서 1epoch를 batch 사이즈로 나눠서 iteration번 학습
Momentum - 이전의 기울기를 가지고 누적해가면서 업데이트 - Local min에서 빠져나갈 수 있어도 global min에 빠질 수 있다.
Adagrad(RMSProp) - 업데이트를 진행할 수록 학습이 lr이 점점 작아져 학습이 조금만 된다.
Adam - Momentum + Adagrad
데이터 셋 = training (80%) + validation(10%) + test(10%)
overfitting - training 데이터만 잘 맞추는 경우
해결 : early stopping, Dropout, Weight decay, Weight Restriction(가중치 제한), Data Augmentation
batch normalization - 분포를 변화시켜 레이어의 기능 활성화
weight initalization - xavier (Sigmoid), He (ReLU)
ensemble - 히든레이어가 많아서 오버피팅이 났다. -> 여러 모델을 만들어서 평균하자 => 오버피팅 방지, 다양성 증가
7강 Text Classification with CNN
classification은 여러 개 중 한 개가 될 수 있고, 여러 개 중 여러 개가 될 수 있다.
정확도 : 예측 중 정답을 얼마나 맞췄는지
정밀도(Precision) : 예측한 Positive 중 True인 것 (암이라고 예측했는데 암인 경우)
재현율(recall) : True인데 Positive로 예측한 것(암인데 암이라고 예측하는 경우)
1종오류 : False인데 Positive로 예측 (남자한테 임신했습니다.)
2종오류 : True인데 Negative로 예측 (임신한 여자한테 임신 아닙니다.)
F1 score (조화평균) : 1/{(1/Precision) + (1/recall)}
Macro-averaging : 그냥 평균한 recall과 precision
여러개의 카테고리를 가진다 - Cross Entropy with SoftMax
두 개중 한개 - Binary Cross Entropy with Sigmoid
언어 모델에서의 CNN을 왜 사용하는가 ? - 단어의 가변적 길이, 단어의 n-gram feature - Cross Entropy with SoftMax 사용
Embedding -> Convolution -> activation -> pooling(유의미한 값만 추출하기) -> FCN 구조
여기서 Embedding은 Word2Vec을 사용해 고정된 값을 사용할 수 있고, 랜덤값을 통해 학습할 수 있다.
어떻게?
CNN을 통한 NLP 분류 문제에서 임베딩을 학습하는 방법에는 여러 가지가 있습니다. 특히, Word2Vec을 사용하거나 모델 훈련 과정에서 랜덤 초기화된 값으로부터 임베딩을 직접 학습하는 방법이 일반적입니다. 각 접근 방식의 핵심 개념과 차이점을 살펴보겠습니다:
1. 사전 훈련된 임베딩 사용 (예: Word2Vec)
- Word2Vec: 이 방법은 대량의 텍스트 데이터를 사용하여 단어 간의 관계를 벡터 공간에 임베딩하는 비지도 학습 기법입니다. Word2Vec에는 크게 두 가지 모델이 있습니다:
- CBOW (Continuous Bag of Words): 주변 단어를 기반으로 특정 단어를 예측합니다.
- Skip-Gram: 특정 단어를 기반으로 주변 단어를 예측합니다.
- 사전 훈련된 Word2Vec 모델을 사용하면, 이미 잘 훈련된 벡터를 사용하여 모델의 성능을 높일 수 있고 훈련 시간을 단축할 수 있습니다. 이 벡터들은 문맥적 유사성을 잘 포착하여 특정 NLP 작업에 바로 적용 가능합니다.
2. 임베딩 레이어를 통한 학습
- 랜덤 초기화: 임베딩 레이어를 모델의 일부로 포함시키고, 훈련 과정에서 입력 문장의 단어를 해당 임베딩 벡터로 변환합니다. 초기 벡터는 무작위로 설정되며, 역전파를 통해 점진적으로 조정됩니다.
- 이 방법은 특정 문제에 최적화된 임베딩을 학습할 수 있도록 해줍니다. 즉, 범용적인 Word2Vec과 달리 특정 데이터셋과 작업에 맞춰 임베딩이 조정됩니다.
선택 기준
- 데이터의 크기와 특성: 충분한 훈련 데이터가 없다면 사전 훈련된 임베딩이 더 유리할 수 있습니다.
- 작업의 특수성: 특정 도메인이나 문제에 맞춰진 임베딩을 필요로 한다면, 직접 학습하는 방법이 더 적합할 수 있습니다.
- 성능과 자원: 사전 훈련된 임베딩은 계산 비용을 줄이고 모델 성능을 빠르게 향상시킬 수 있습니다.
CNN에서 이러한 임베딩을 사용하면, 학습된 벡터들을 기반으로 텍스트의 고차원 특성을 추출하고, 이를 통해 문장이나 문서의 분류를 효과적으로 수행할 수 있습니다.
8강 - Machine Translation with RNN
RNN은 시간적 순서가 있는 시계열 데이터를 받아 hidden state를 통해 이전 데이터를 전송해준다.
-> NLP Task에서 사용이 가능하다.
기본적으로 RNN에서 사용되는 파라미터는 공유된다.
단어의 길이 == RNN의 길이
낮은 차원의 RNN - 문자 단어 레벨의 feature
높은 차원의 RNN - 문장 구조, 긍 부정 등 feature => Multi-layer RNN (너무 많으면 overfitting이 일어나므로 적당히)
RNN도 결국 일정한 길이의 input이 필요하기 때문에 padding이 필요하다.
RNN한계
Long-term dependency : activation function의 사용으로 인한 정보 손실 -> GATE를 사용해서 해결
LSTM

거리가 멀어도 정보 전달에 효율적이다.
Seq2Seq - Encoder(단어를 임베딩, 문장 의미 추출), Decoder(단어를 생성한다) 구조
1. model complexity가 좋아진다.( 일반화를 더 잘하고 feature를 잘 추출한다.)
2. DATA의 양과 질이 좋아진다.
Seq2Seq 모델을 사용하는 것 자체가 데이터의 양이나 질을 직접적으로 향상시키는 것은 아닙니다. 그러나 Seq2Seq 모델이 RNN에 비해 모델 복잡성이 좋아진다는 표현은, Seq2Seq 모델이 더 복잡하고 효율적인 데이터 처리 구조를 가지고 있어서, 같은 데이터에 대해 더 높은 성능을 낼 수 있다는 의미로 해석할 수 있습니다.
Seq2Seq 모델은 특히 번역, 요약, 대화 시스템 등에서 입력 시퀀스를 출력 시퀀스로 변환하는 문제에서 뛰어난 성능을 보이는데, 이는 다음과 같은 이유 때문입니다:
- 긴 시퀀스 처리: Seq2Seq 구조는 인코더와 디코더 구성을 통해 긴 입력 시퀀스를 효율적으로 처리하고, 해당 정보를 캡슐화하여 디코더로 전달할 수 있습니다. 이는 특히 긴 문장이나 문서를 다룰 때 유리합니다.
- 정보 보존: Seq2Seq 모델은 입력 시퀀스의 전체적인 맥락을 보다 잘 이해하고 이를 기반으로 출력을 생성할 수 있습니다. 이는 특히 번역과 같은 작업에서 중요한데, 문장의 전체적인 의미를 이해하고 이를 다른 언어로 표현해야 하기 때문입니다.
- 모델의 학습능력 강화: Seq2Seq 구조는 복잡한 패턴을 학습할 수 있는 능력이 뛰어나며, 이를 통해 훈련 데이터에서 다양한 언어적 특징과 구조를 더 잘 포착할 수 있습니다.
그러나 "데이터의 양과 질이 좋아진다"는 표현은, Seq2Seq 모델이 기존 데이터를 더 효과적으로 활용하여 높은 성능을 발휘할 수 있다는 것을 의미합니다. 즉, 데이터 자체의 변경이 아니라 데이터를 처리하는 모델의 능력이 개선된다는 관점에서 이해할 수 있습니다. 이는 더 나은 일반화, 예측 정확도, 그리고 결과적으로 더 높은 모델 성능으로 이어질 수 있습니다.
"Seq2Seq is optimized as a single system, backpropagation operates 'end to end'"라는 문장은 Seq2Seq 모델의 학습 방식과 구조에 대한 설명입니다. 여기서 말하는 핵심 포인트는 다음과 같습니다:
- 단일 시스템 최적화: Seq2Seq 모델은 인코더와 디코더를 포함하는 하나의 연속된 시스템으로 구성되며, 이 두 부분은 분리된 개별 구성요소가 아닌 하나의 통합된 아키텍처로서 최적화됩니다. 이는 모델의 모든 파라미터가 하나의 목표, 즉 최종 출력 시퀀스의 정확성을 향상시키기 위해 공동으로 조정되고 튜닝된다는 것을 의미합니다.
- 엔드 투 엔드 역전파: '엔드 투 엔드' 역전파는 입력 데이터가 모델의 인코더 부분에서 시작하여 디코더를 거쳐 최종 출력까지 처리되는 전체 과정에서 이루어지는 그래디언트 기반의 학습 방법입니다. 이 방식을 통해 입력 시퀀스와 관련된 손실에서 발생한 그래디언트가 모델 전체에 걸쳐 역방향으로 전파되며, 이 과정에서 모델의 모든 가중치가 업데이트됩니다.
이 접근 방식의 장점은 모델이 전체적인 맥락을 유지하면서 학습할 수 있다는 것입니다. 인코더와 디코더의 연결을 통해 얻은 정보의 흐름이 자연스럽게 유지되므로, 입력 데이터의 복잡한 패턴과 관계를 더 효과적으로 학습할 수 있습니다. 이는 번역, 요약, 자동 대화 생성 등의 작업에서 특히 중요한데, 이들 작업은 입력 데이터의 정확한 이해와 이를 바탕으로 한 적절한 출력 생성이 필수적이기 때문입니다.
Greedy decoding - 가장 높은 확률의 단어를 선택하는 것 -> 되돌아 갈 수 없는 문제가 발생
Beam Search decoding - n개의 단어에서 n개의 단어를 추출하면서 높은 확률 n개만 남겨두고 계속 진행하는 것

전체적인 문장을 얻을 수 있다!
Seq2Seq의 한계
병목 현상 : 마지막 단어의 영향이 제일 크다 -> attention의 등장
디코더의 시작값과 인코더의 모든 값 내적 -> attention score를 softmax하기 -> 값을 weight(아마 encoder 값일 거다)와 곱하여 디코더 값과 concat하기

attention을 본다 == encoder의 어느 값이 중요하다
BLUE 평가 - 기계가 한 번역과 사람이 한 번역을 n-gram단위로 비교하면서 진행한다. (좋은 평가는 아니다. 기계 번역이 괜찮을 수 있지만 사람의 번역과 단어가 다르면 점수가 낮기 때문)




9강 - Text summarization + Transformer
요약 = 원문 X를 요약해서 Y로 출력
Extractive summarization - 원문에서 제일 중요해 보이는 문장 출력(classification과 비슷한 과정)
Abstractive summarization - 원문을 읽고 중요한 문장을 생성한다.
Text Generation 평가 방식
Content overlap metrics : BLUE와 비슷하다.얼마나 잘 커버하냐를 보여준다.

번역 - Precision : 너무 짧으면 안된다. 정확한 번역이 필요하다.
요약 - Recall : 최대한 기존의 내용을 포함해야한다.
RNN(Seq2Seq)의 병목현상을 해결하기 위해 Transformer 등장 (attention만으로 구성해보자)
Transformer = self-attention + masked attention + attention + Multi-Head attention
self-attention : Gate와 같은 역할. 인코더에 한번, 디코더에 한번 있다.
Decorder는 Endorder 마지막 layer의 값을 계속 참조하여 단어 생성
RNN layer를 삭제함으로써 사라진 위치정보는 positional encoding을 통해 위치정보를 주입한다.
Self-attention = query + key + value

Q*k -> dk를 통한 scaling -> softMax하여 유사도 구하기 -> v곱하기
Multi-head attention : CNN에서 feature map을 여러개 가지는 것과 유사한 개념으로 임베딩 벡터가 너무 길기 때문에 잘라서 각각의 QKV마다 다른 feature를 뽑는다.
그 후 나온 값들은 batch normalization과 residual connection을 진행한다.
residual connection == skip connection?
네, residual connection과 skip connection은 종종 동일한 개념으로 사용되곤 합니다. 둘 다 신경망에서 특정 레이어의 입력을 해당 레이어의 출력에 더함으로써, 입력 정보가 네트워크를 통과할 때 손실되는 것을 줄이는 역할을 합니다.
- Residual Connection: 이는 주로 ResNet 아키텍처에서 볼 수 있습니다. 입력 x를 몇 개의 레이어를 거친 후의 출력에 직접 더해줍니다. 이를 통해 입력 정보가 네트워크의 깊은 부분까지 직접적으로 전달될 수 있어, 깊은 네트워크에서의 학습이 용이해집니다. 이러한 연결은 "identity shortcut connection"이라고도 불리며, 기본적으로 입력 x를 f(x)의 출력에 더하여 결과적으로는 f(x) + x가 됩니다.
- Skip Connection: 이 용어는 일반적으로 입력을 한 레이어나 몇 개의 레이어를 건너뛰고 출력에 직접 연결할 때 사용됩니다. 이것은 정보가 네트워크를 더 효율적으로 통과하도록 돕고, 깊은 네트워크에서의 그래디언트 소실 문제를 완화합니다.
두 용어는 기능적으로 유사하여 신경망에서 깊은 레이어로의 효율적인 정보 전달을 가능하게 하는 것을 목적으로 하며, 따라서 같은 맥락에서 사용될 수 있습니다. 그러나 "residual connection"은 특히 ResNet과 같이 특정 레이어의 출력에 원래 입력을 더하는 구조를 설명할 때 주로 사용되는 반면, "skip connection"은 더 일반적인 용어로, 다양한 아키텍처와 맥락에서 입력을 건너뛰어 연결하는 모든 경우를 포괄합니다.
그럼 Encorder 끝!

decorder도 크게 다른 점은 없다
Masked attention - 뒷 부분의 정보를 사용하지 않기 위해 지금 출력한 정보만 사용한다(학습시에만 사용되는 내용이다.)
끝!
'인공지능 > 자연어 처리' 카테고리의 다른 글
| 자연어 처리 중간고사 대비 Chat GPT 퀴즈 (0) | 2024.04.16 |
|---|---|
| Chat GPT 통한 자연어 처리 중간고사 OX, 빈칸 퀴즈 문제 (0) | 2024.04.16 |
| 자연어 처리 정리 9강 - Text Summarization + Transformer(self, multi,masked attention) (0) | 2024.04.15 |
| 자연어 처리 정리 - 8강 Machine Translation with RNN (0) | 2024.04.13 |
| 자연어 처리 정리 - 7강 Text classification with CNN (0) | 2024.04.13 |