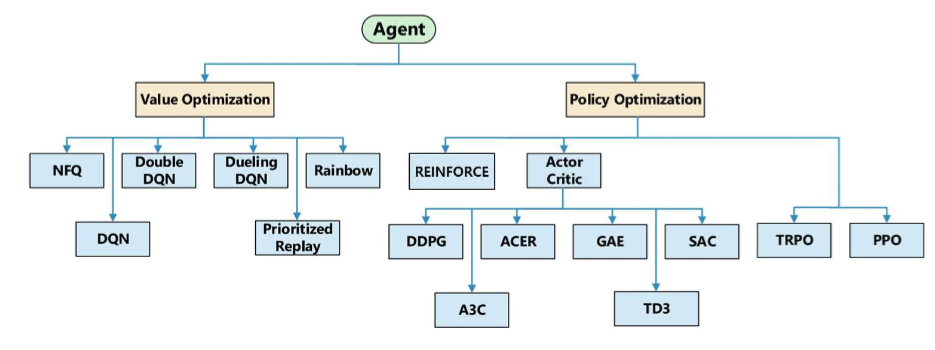
Value optimization 방식
Neural Fitted Q Iteration (NFQ)
신경망을 활용하여 Q 함수를 근사한다.
기본 뉴럴넷 형식이고, Q를 뉴럴넷으로 구현하였다.
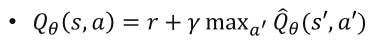
장 : 비선형 함수 근사를 통해 복잡한 환경에서도 사용 가능하다.
단 : 데이터 활용 측면에서 효율성 떨어짐
Deep Q Learning (DQN)
심층 신경망을 활용하여 Q 함수를 근사한다.

장 : replay memory를 사용하여 샘플 효율성을 높였다.
단 : 불안정한 학습과 과적합 문제가 발생 가능하다.
Q를 뉴럴넷을 통해 구한다. == 학습이 불안정해지고, 오버피팅이 발생할 수 있다.
데이터 셋이 많을 수록 좋아진다. -> 데이터 샘플이 편향성을 가지지 않고, 다양한 형태를 가져야 한다 == Q를 학습하는데 편향이 될 수 있다.
Q가 에피소드 끝까지 진행 후 학습을 진행하면 조금 괜찮으나 끝까지 가기 어렵기 때문에 TD와 같은 방식을 사용하며 불안정해진다.
NFQ(Neural Fitted Q Iteration)와 DQN(Deep Q-Learning)은 둘 다 Q-함수를 신경망으로 근사하지만, 그 차이는 신경망의 깊이뿐만 아니라 다른 여러 측면에서도 나타납니다. 아래에서 두 알고리즘의 주요 차이점을 설명하겠습니다.
NFQ (Neural Fitted Q Iteration)
특징:
- 비선형 함수 근사:
- NFQ는 Q-함수를 비선형 신경망으로 근사합니다. 이는 단순히 선형 모델을 사용하는 것보다 더 복잡한 상태-액션 공간을 학습할 수 있게 합니다.
- 훈련 방식:
- NFQ는 일반적으로 배치(batch) 학습을 사용합니다. 이는 모든 경험을 한 번에 네트워크에 전달하여 훈련합니다.
- 경험을 수집한 후, Q-함수를 한 번에 업데이트합니다.
- 사용 데이터:
- NFQ는 주로 과거 경험 데이터셋을 사용하여 훈련합니다. 이 데이터셋은 정적일 수 있으며, 업데이트 과정에서 추가 경험을 수집하지 않을 수 있습니다.
- 알고리즘의 단계:
- 환경에서 경험 데이터를 수집합니다.
- 수집된 데이터를 통해 신경망을 업데이트합니다.
장점:
- 비선형 함수 근사를 통해 복잡한 환경에서 학습할 수 있습니다.
단점:
- 배치 학습으로 인해 메모리와 계산 자원이 많이 필요할 수 있습니다.
- 데이터 활용 효율성이 낮을 수 있습니다.
DQN (Deep Q-Learning)
특징:
- 심층 신경망 사용:
- DQN은 심층 신경망(딥 러닝)을 사용하여 Q-함수를 근사합니다. 이는 여러 층을 통해 복잡한 패턴을 학습할 수 있게 합니다.
- 재현 메모리 (Replay Memory):
- DQN은 경험 재현 메모리를 사용하여 샘플 효율성을 높입니다. 에이전트는 경험을 수집한 후, 이 경험을 재현 메모리에 저장합니다.
- 학습 시, 재현 메모리에서 무작위로 미니배치를 샘플링하여 Q-함수를 업데이트합니다.
- 타깃 네트워크 (Target Network):
- DQN은 타깃 네트워크를 사용하여 학습의 안정성을 높입니다. 이는 학습 네트워크의 가중치를 일정 간격으로 타깃 네트워크에 복사하는 방식으로, 목표 값의 변동성을 줄입니다.
- 알고리즘의 단계:
- 에이전트가 환경과 상호작용하며 경험을 수집합니다.
- 경험을 재현 메모리에 저장합니다.
- 재현 메모리에서 무작위로 미니배치를 샘플링하여 신경망을 업데이트합니다.
- 일정 간격으로 타깃 네트워크를 업데이트합니다.
장점:
- 재현 메모리를 통해 샘플 효율성을 높이고, 경험의 중복 사용을 통해 학습 성능을 향상시킵니다.
- 타깃 네트워크를 사용하여 학습의 안정성을 높입니다.
단점:
- 학습 과정이 불안정할 수 있으며, 과적합 문제가 발생할 수 있습니다.
- 메모리와 계산 자원이 많이 필요합니다.
요약
- NFQ는 배치 학습과 비선형 함수 근사를 통해 Q-함수를 학습합니다. 이는 복잡한 환경에서도 학습이 가능하지만, 데이터 활용 효율성이 낮고 메모리와 계산 자원이 많이 필요할 수 있습니다.
- DQN은 심층 신경망, 재현 메모리, 타깃 네트워크를 사용하여 Q-함수를 학습합니다. 이는 샘플 효율성을 높이고 학습의 안정성을 높이지만, 학습 과정이 불안정할 수 있으며 과적합 문제가 발생할 수 있습니다.
따라서 NFQ와 DQN은 신경망을 사용하여 Q-함수를 근사한다는 공통점이 있지만, 학습 방법, 경험 데이터 활용, 그리고 학습 안정성 측면에서 차이가 있습니다.
Double DQN
두개의 Q함수를 사용하여 Q 값의 과추정을 줄였다.
참조하는 Q는 매번 학습하는 것이 아니라 일정 턴마다 학습한다.

장 : Q 값의 과추정을 줄여 학습 안정성을 높였다.
단 : DQN에 비해 계산 비용이 증가
Dueling DQN
상태 가치 함수와 이득 함수를 분리하여 Q 함수를 근사하였다.
두 개의 Q를 이용하는 것이 아니라 V와 A를 통해 Q를 구한다.(A = Q - V)
A는 action 자체의 가치로 복잡해 보이나 성능이 많이 오른다.

장 : 상태의 가치와 행동의 이득을 분리하여 더 안정적인 Q 값 추정 가능하다.
단 : 구현이 복잡하고 계산 비용이 증가한다.
Prioritized Replay DQN
중요한 경험을 우선적으로 학습하도록 재현 메모리를 개선하였다.
샘플 자체의 중요도가 다를 수 있다. => 중요도(Pi)를 설정하여 중요도가 높은 것을 우선 or 여러 번 학습한다.
TD error = 현재 Q와 다음 Q의 차이 == 내가 경험했을 때 얼마나 변화하냐 -> 값이 크게 변하면 중요한 샘플
무조건 변화가 큰 것이 중요도가 높은 것은 아니지만 수렴에 크게 기여한다.
알파를 키울수록 우선순위가 강조된다.

장 : 중요 경험을 우선 학습하여 샘플 효율성을 높였다.
단 : 재현 메모리 관리가 복잡하고, 추가적인 계산 비용을 발생한다.
Rainbow
DQN + Double DQN + Deuling DQN + Prioritized Experience Replay + Multi-step learning + Distributional RL + Noisy Networks
Distribution - 분산 : 여러개를 만들어 개별적으로 학습 후 모아서 최종 모델 만들기 - 비동기식 엑터 크리틱

장 : 다양한 DQN 변형을 결합하여 높은 성능을 보인다.
단 : 구현이 복잡하고 계산 비용이 매우 높다.

Policy optimiztion methods
Reinforce
에피소드 단위로 누적된 보상을 기반으로 정책을 업데이트한다.
G를 일반화 해서 사용하기도 한다. r, Q, V, A 등 다양하게 가능하다.

장 : 직접 정책을 최적화 하므로 높은 표현력 가능
단 : 높은 분산으로 인해 학습이 불안정할 수 있다.
Deep deterministic policy gradient (DDPG)
연속 행동 공간에서 사용되는 Actor Critic 방식이다.
액터를 위한 목적함수 : 정책 함수를 만들어서 극대화 한다.
크리틱을 위한 목적 함수 : Q를 뉴럴넷으로 학습시켜 최소화 한다.

장 : 연속 행동 공간에서 효과적으로 학습 가능하다
단 : 하이퍼파라미터 튜닝이 까다롭다.
Ansynchronous advantage Actor-Critic (A3C)
병렬 학습을 통해 정책과 가치 함수를 학습한다.
개별적으로 학습 후 합치거나 데이터 샘플을 여러 개 모아 커다란 데이터 셋을 만들어 학습 시킬 수 있다.
싱크가 맞아야만 효과가 있다.(on-Policy 라던지...)

장 : 병렬 학습을 통해 학습 속도 향상
단 : 동기화 오버헤드 발생 가능
Actor-Critic with experience replay(ACER)
경험 재현을 통해 A3C의 단점을 보완하였다.

장 : 경험 재현을 통해 학습 안정성 향상
단 : 재현 메모리 관리의 복잡성 증가
Generalized advantage estimation(GAE)
가치 추정의 편향을 줄이기 위해 사용한다.
감마를 빼서 곱한다 == n-step로 보면 된다. 추정된 advantage를 확인한다.

장 : 가치 추정의 편향 감소
단 : 계산 비용의 증가
Twin delayed DDPG(TD3)
DDPG의 단점을 보완하였다.
Q를 두개 만들고, 시작점이 다르다 => 각각 업데이트 하면서 가지고 가고, 참조할 땐 작은 것을 참조한다.

장 : Q값의 과추정 문제 완화
단 : 계산 비용 증가
Soft actor-critic(SAC)
엔트로피 정규화를 통해 정책의 탐험성을 증가

장 : 안정적이고 샘플의 효율적인 학습 가능
단 : 엔트로피 매개변수 알파의 튜닝이 필요하다.
Trust region policy optimization (TRPO)
정책 업데이트의 신뢰 영역을 제한하여 학습 안정성을 높였다.

장 : 정책 업데이트의 신뢰 영역을 제한하여 안정적 학습 가능
단 구현 복잡성과 계산 비용 증가
Proximal policy optimization (PPO)
정책 업데이트의 신뢰 영역을 제한하여 학습 안정성을 높였다.
old - 타겟, Theta - 현재
두 개의 비율을 이용해 곱해준다.
ACER과 비슷한 느낌이다.

장 : 구현이 비교적 간단하고, 효율적인 학습이 가능하다.
단 : 하이퍼파라미터 입실론의 적절한 설정이 필요하다.

12. Deep RL 심화
강의 내용은 두 가지 주요 주제로 나누어집니다:
- Value optimization methods
- Policy optimization methods
12.1 Value Optimization Methods
Neural Fitted Q Iteration (NFQ):
- 신경망을 사용하여 Q-함수를 근사
- 비선형 함수 근사를 통해 복잡한 환경에서도 학습 가능
- 데이터 활용 측면에서 효율성이 떨어짐
Deep Q learning (DQN):
- 심층 신경망을 사용하여 Q-함수를 근사
- 재현 메모리(replay memory)를 사용하여 샘플 효율성을 높임
- 불안정한 학습과 과적합 문제 발생 가능
Double DQN:
- 두 개의 Q-함수를 사용하여 Q-값의 과추정을 줄임
- 학습 안정성을 높임
- 계산 비용이 증가
Dueling DQN:
- 상태-가치 함수와 이득 함수를 분리하여 Q-함수를 근사
- 상태의 가치와 행동의 이득을 분리하여 더 안정적인 Q-값 추정 가능
- 구현이 복잡하고 계산 비용이 증가
Prioritized Replay DQN:
- 중요한 경험을 우선적으로 학습하도록 재현 메모리를 개선
- 중요 경험을 우선 학습하여 샘플 효율성을 높임
- 재현 메모리 관리가 복잡하고 추가적인 계산 비용 발생
Rainbow:
- DQN, Double DQN, Dueling DQN, Prioritized Experience Replay, Multi-step learning, Distributional RL, Noisy Networks를 결합하여 높은 성능을 발휘
- 구현이 복잡하고 계산 비용이 매우 높음
알고리즘 비교:
- NFQ: 복잡한 환경 학습 가능, 대규모 데이터 학습 어려움
- DQN: 샘플 효율성 증가, 불안정한 학습
- Double DQN: Q-값 과추정 감소, 계산 비용 증가
- Dueling DQN: 안정적 Q-값 추정, 구현 복잡성 증가
- Prioritized Replay DQN: 샘플 효율성 증가, 관리 복잡성 증가
- Rainbow: 높은 성능, 계산 비용 증가
12.2 Policy Optimization Methods
REINFORCE (Monte Carlo Policy Gradient):
- 에피소드 단위로 누적된 보상을 기반으로 정책을 업데이트
- 직접 정책을 최적화하므로 높은 표현력 가능
- 높은 분산으로 인해 학습이 불안정할 수 있음
Deep Deterministic Policy Gradient (DDPG):
- 연속 행동 공간에서 사용되는 Actor-Critic 방법
- 연속 행동 공간에서 효과적으로 학습 가능
- 하이퍼파라미터 튜닝이 까다로움
Asynchronous Advantage Actor-Critic (A3C):
- 병렬 학습을 통해 정책과 가치 함수를 학습
- 병렬 학습을 통해 학습 속도 향상
- 동기화 오버헤드 발생 가능
Actor-Critic with Experience Replay (ACER):
- 경험 재현을 통해 A3C의 단점을 보완
- 경험 재현을 통해 학습 안정성 향상
- 재현 메모리 관리의 복잡성 증가
Generalized Advantage Estimation (GAE):
- 가치 추정의 편향을 줄이기 위해 사용
- 가치 추정의 편향 감소
- 계산 비용 증가
Twin Delayed DDPG (TD3):
- DDPG의 단점을 보완
- Q-값의 과추정 문제 완화
- 계산 비용 증가
Soft Actor-Critic (SAC):
- 엔트로피 정규화를 통해 정책의 탐험성을 증가
- 안정적이고 샘플 효율적인 학습 가능
- 엔트로피 매개변수 𝛼의 튜닝 필요
Trust Region Policy Optimization (TRPO):
- 정책 업데이트의 신뢰 영역을 제한하여 학습 안정성을 높임
- 정책 업데이트의 신뢰 영역을 제한하여 안정적 학습 가능
- 구현 복잡성과 계산 비용 증가
Proximal Policy Optimization (PPO):
- 정책 업데이트의 신뢰 영역을 제한하여 학습 안정성을 높임
- 구현이 비교적 간단하고 효율적인 학습 가능
- 하이퍼파라미터 𝜖의 적절한 설정 필요
알고리즘 비교:
- REINFORCE: 높은 표현력, 높은 분산으로 인한 학습 불안정
- DDPG: 연속 행동 공간에서 효과적 학습, 하이퍼파라미터 튜닝 까다로움
- A3C: 병렬 학습으로 학습 속도 향상, 동기화 오버헤드 발생 가능
- ACER: 학습 안정성 향상, 재현 메모리 관리의 복잡성 증가
- GAE: 가치 추정의 편향 감소, 계산 비용 증가
- TD3: Q-값 과추정 문제 완화, 계산 비용 증가
- SAC: 안정적이고 샘플 효율적 학습, 엔트로피 매개변수 𝛼 튜닝 필요
- TRPO: 안정적 학습 가능, 구현 복잡성과 계산 비용 증가
- PPO: 구현이 비교적 간단하고 효율적 학습 가능, 하이퍼파라미터 𝜖 설정 필요
강의 내용은 강화학습의 심화 주제를 다루며, 가치 최적화 및 정책 최적화 방법을 중심으로 다양한 알고리즘을 설명하고 있습니다. 각 알고리즘의 특징, 장단점, 대표 수식 및 의사 코드를 제공하여 이해를 돕고 있습니다.
O, X 문제 (10문제)
- Neural Fitted Q Iteration (NFQ)은 신경망을 사용하여 Q-함수를 근사한다. (O)
- 해설: NFQ는 신경망을 사용하여 Q-함수를 근사합니다.
- Deep Q Learning (DQN)은 재현 메모리를 사용하여 샘플 효율성을 높인다. (O)
- 해설: DQN은 재현 메모리를 사용하여 샘플 효율성을 높입니다.
- Double DQN은 두 개의 Q-함수를 사용하여 Q-값의 과추정을 줄인다. (O)
- 해설: Double DQN은 두 개의 Q-함수를 사용하여 Q-값의 과추정을 줄입니다.
- Dueling DQN은 상태-가치 함수와 이득 함수를 분리하여 Q-함수를 근사한다. (O)
- 해설: Dueling DQN은 상태-가치 함수와 이득 함수를 분리하여 Q-함수를 근사합니다.
- Prioritized Replay DQN은 모든 경험을 동일하게 학습한다. (X)
- 해설: Prioritized Replay DQN은 중요한 경험을 우선적으로 학습합니다.
- Rainbow 알고리즘은 다양한 DQN 변형을 결합하여 높은 성능을 발휘한다. (O)
- 해설: Rainbow는 다양한 DQN 변형을 결합하여 높은 성능을 발휘합니다.
- REINFORCE는 에피소드 단위로 누적된 보상을 기반으로 정책을 업데이트한다. (O)
- 해설: REINFORCE는 에피소드 단위로 누적된 보상을 기반으로 정책을 업데이트합니다.
- Deep Deterministic Policy Gradient (DDPG)는 이산 행동 공간에서 사용된다. (X)
- 해설: DDPG는 연속 행동 공간에서 사용됩니다.
- Asynchronous Advantage Actor-Critic (A3C)는 병렬 학습을 통해 학습 속도를 향상시킨다. (O)
- 해설: A3C는 병렬 학습을 통해 학습 속도를 향상시킵니다.
- Proximal Policy Optimization (PPO)은 정책 업데이트의 신뢰 영역을 제한하여 학습 안정성을 높인다. (O)
- 해설: PPO는 정책 업데이트의 신뢰 영역을 제한하여 학습 안정성을 높입니다.
빈칸 문제 (10문제)
- Neural Fitted Q Iteration (NFQ)은 신경망을 사용하여 __를 근사한다. (Q-함수)
- 해설: NFQ는 신경망을 사용하여 Q-함수를 근사합니다.
- Deep Q Learning (DQN)은 __ 메모리를 사용하여 샘플 효율성을 높인다. (재현)
- 해설: DQN은 재현 메모리를 사용하여 샘플 효율성을 높입니다.
- Double DQN은 두 개의 Q-함수를 사용하여 Q-값의 __을 줄인다. (과추정)
- 해설: Double DQN은 두 개의 Q-함수를 사용하여 Q-값의 과추정을 줄입니다.
- Dueling DQN은 상태-가치 함수와 __ 함수를 분리하여 Q-함수를 근사한다. (이득)
- 해설: Dueling DQN은 상태-가치 함수와 이득 함수를 분리하여 Q-함수를 근사합니다.
- Prioritized Replay DQN은 중요한 __를 우선적으로 학습한다. (경험)
- 해설: Prioritized Replay DQN은 중요한 경험을 우선적으로 학습합니다.
- Rainbow 알고리즘은 다양한 DQN __을 결합하여 높은 성능을 발휘한다. (변형)
- 해설: Rainbow는 다양한 DQN 변형을 결합하여 높은 성능을 발휘합니다.
- REINFORCE는 에피소드 단위로 누적된 __을 기반으로 정책을 업데이트한다. (보상)
- 해설: REINFORCE는 에피소드 단위로 누적된 보상을 기반으로 정책을 업데이트합니다.
- Deep Deterministic Policy Gradient (DDPG)는 __ 행동 공간에서 사용된다. (연속)
- 해설: DDPG는 연속 행동 공간에서 사용됩니다.
- Asynchronous Advantage Actor-Critic (A3C)는 __ 학습을 통해 학습 속도를 향상시킨다. (병렬)
- 해설: A3C는 병렬 학습을 통해 학습 속도를 향상시킵니다.
- Proximal Policy Optimization (PPO)은 정책 업데이트의 __ 영역을 제한하여 학습 안정성을 높인다. (신뢰)
- 해설: PPO는 정책 업데이트의 신뢰 영역을 제한하여 학습 안정성을 높입니다.
서술형 문제 (10문제)
- Neural Fitted Q Iteration (NFQ)의 장점과 단점을 설명하시오.
- 정답: 장점은 비선형 함수 근사를 통해 복잡한 환경에서도 학습이 가능하다는 점입니다. 단점은 데이터 활용 측면에서 효율성이 떨어진다는 것입니다.
- 해설: NFQ는 비선형 함수 근사를 통해 복잡한 환경에서 학습이 가능하지만, 데이터 활용 효율성이 낮습니다.
- Deep Q Learning (DQN)의 학습 과정과 재현 메모리의 역할을 설명하시오.
- 정답: DQN은 심층 신경망을 사용하여 Q-함수를 근사합니다. 재현 메모리는 에이전트의 경험을 저장하여 샘플 효율성을 높이고, 과거 경험을 재사용하여 학습 안정성을 향상시킵니다. 경험을 무작위로 샘플링하여 네트워크를 업데이트합니다.
- 해설: DQN은 재현 메모리를 사용하여 샘플 효율성을 높이고, 과거 경험을 재사용하여 학습 안정성을 향상시킵니다.
- Double DQN의 특징과 장점을 설명하시오.
- 정답: Double DQN은 두 개의 Q-함수를 사용하여 Q-값의 과추정을 줄입니다. 이를 통해 학습 안정성을 높이고, 과추정 문제를 완화할 수 있습니다. 그러나 DQN에 비해 계산 비용이 증가하는 단점이 있습니다.
- 해설: Double DQN은 Q-값의 과추정을 줄여 학습 안정성을 높이지만, 계산 비용이 증가합니다.
- Dueling DQN의 구조와 이점에 대해 설명하시오.
- 정답: Dueling DQN은 상태-가치 함수와 이득 함수를 분리하여 Q-함수를 근사합니다. 이를 통해 상태의 가치와 행동의 이득을 분리하여 더 안정적인 Q-값 추정이 가능합니다. 그러나 구현이 복잡하고 계산 비용이 증가하는 단점이 있습니다.
- 해설: Dueling DQN은 상태 가치와 행동의 이득을 분리하여 안정적인 Q-값 추정이 가능하지만, 구현이 복잡하고 계산 비용이 증가합니다.
- Prioritized Replay DQN의 중요성과 단점을 설명하시오.
- 정답: Prioritized Replay DQN은 중요한 경험을 우선적으로 학습하여 샘플 효율성을 높입니다. 이는 학습 속도를 높이고, 중요 경험을 효과적으로 반영할 수 있습니다. 그러나 재현 메모리 관리가 복잡하고 추가적인 계산 비용이 발생하는 단점이 있습니다.
- 해설: Prioritized Replay DQN은 중요한 경험을 우선 학습하여 샘플 효율성을 높이지만, 재현 메모리 관리가 복잡하고 추가적인 계산 비용이 발생합니다.
- Rainbow 알고리즘이 다양한 DQN 변형을 결합하여 높은 성능을 발휘할 수 있는 이유를 설명하시오.
- 정답: Rainbow는 DQN, Double DQN, Dueling DQN, Prioritized Experience Replay, Multi-step learning, Distributional RL, Noisy Networks를 결합하여 각각의 장점을 최대한 활용합니다. 이를 통해 높은 성능을 발휘할 수 있지만, 구현이 복잡하고 계산 비용이 매우 높습니다.
- 해설: Rainbow는 다양한 DQN 변형의 장점을 결합하여 높은 성능을 발휘하지만, 구현이 복잡하고 계산 비용이 높습니다.
- REINFORCE 알고리즘의 주요 개념과 단점을 설명하시오.
- 정답: REINFORCE는 에피소드 단위로 누적된 보상을 기반으로 정책을 업데이트하는 Monte Carlo Policy Gradient 방법입니다. 높은 표현력을 가지지만, 보상의 높은 분산으로 인해 학습이 불안정할 수 있습니다.
- 해설: REINFORCE는 에피소드 단위로 정책을 업데이트하는 방법으로 높은 표현력을 가지지만, 높은 분산으로 인해 학습이 불안정할 수 있습니다.
- Deep Deterministic Policy Gradient (DDPG)의 장단점을 설명하시오.
- 정답: DDPG는 연속 행동 공간에서 효과적으로 학습할 수 있는 Actor-Critic 방법입니다. 이는 높은 샘플 효율성과 안정성을 제공하지만, 하이퍼파라미터 튜닝이 까다롭고, 학습 과정이 복잡합니다.
- 해설: DDPG는 연속 행동 공간에서 효과적이지만, 하이퍼파라미터 튜닝이 까다롭습니다.
- Asynchronous Advantage Actor-Critic (A3C)의 병렬 학습 방법과 장단점을 설명하시오.
- 정답: A3C는 병렬 학습을 통해 정책과 가치 함수를 동시에 학습합니다. 이는 학습 속도를 향상시키고, 다양한 환경에서 학습할 수 있는 장점을 가지지만, 동기화 오버헤드가 발생할 수 있는 단점이 있습니다.
- 해설: A3C는 병렬 학습을 통해 학습 속도를 높이지만, 동기화 오버헤드가 발생할 수 있습니다.
- Proximal Policy Optimization (PPO)의 주요 개념과 이점을 설명하시오.
- 정답: PPO는 정책 업데이트의 신뢰 영역을 제한하여 학습 안정성을 높이는 방법입니다. 이는 구현이 비교적 간단하고, 효율적인 학습이 가능하며, 하이퍼파라미터 𝜖의 적절한 설정이 필요합니다.
- 해설: PPO는 신뢰 영역을 제한하여 안정성을 높이고, 구현이 비교적 간단하지만, 하이퍼파라미터 설정이 필요합니다.
단답형 문제 (10문제)
- Neural Fitted Q Iteration (NFQ)은 무엇을 사용하여 Q-함수를 근사하는가?
- 정답: 신경망
- 해설: NFQ는 신경망을 사용하여 Q-함수를 근사합니다.
- Deep Q Learning (DQN)은 무엇을 사용하여 샘플 효율성을 높이는가?
- 정답: 재현 메모리
- 해설: DQN은 재현 메모리를 사용하여 샘플 효율성을 높입니다.
- Double DQN은 두 개의 무엇을 사용하여 Q-값의 과추정을 줄이는가?
- 정답: Q-함수
- 해설: Double DQN은 두 개의 Q-함수를 사용하여 Q-값의 과추정을 줄입니다.
- Dueling DQN은 상태-가치 함수와 무엇을 분리하여 Q-함수를 근사하는가?
- 정답: 이득 함수
- 해설: Dueling DQN은 상태-가치 함수와 이득 함수를 분리하여 Q-함수를 근사합니다.
- Prioritized Replay DQN은 중요한 무엇을 우선적으로 학습하는가?
- 정답: 경험
- 해설: Prioritized Replay DQN은 중요한 경험을 우선적으로 학습합니다.
- Rainbow 알고리즘은 다양한 DQN 변형을 결합하여 무엇을 발휘하는가?
- 정답: 높은 성능
- 해설: Rainbow는 다양한 DQN 변형을 결합하여 높은 성능을 발휘합니다.
- REINFORCE는 에피소드 단위로 누적된 무엇을 기반으로 정책을 업데이트하는가?
- 정답: 보상
- 해설: REINFORCE는 에피소드 단위로 누적된 보상을 기반으로 정책을 업데이트합니다.
- Deep Deterministic Policy Gradient (DDPG)는 어떤 행동 공간에서 사용되는가?
- 정답: 연속 행동 공간
- 해설: DDPG는 연속 행동 공간에서 사용됩니다.
- Asynchronous Advantage Actor-Critic (A3C)는 무엇을 통해 학습 속도를 향상시키는가?
- 정답: 병렬 학습
- 해설: A3C는 병렬 학습을 통해 학습 속도를 향상시킵니다.
- Proximal Policy Optimization (PPO)은 정책 업데이트의 무엇을 제한하여 학습 안정성을 높이는가?
- 정답: 신뢰 영역
- 해설: PPO는 정책 업데이트의 신뢰 영역을 제한하여 학습 안정성을 높입니다.
'인공지능 > 강화학습' 카테고리의 다른 글
| AI 경진대회 - 구성 요소 정하기 (0) | 2024.07.16 |
|---|---|
| AI 경진대회 - 환경 구성하기 matlab Driving Scenario Designer (0) | 2024.07.15 |
| 강화학습 11강 - 강화학습 실습 예제 (1) | 2024.06.08 |
| 강화학습 10장 - 알파고와 MCTS (0) | 2024.06.08 |
| 강화학습 9장 - 정책 기반 에이전트 (1) | 2024.06.08 |