알파고는 2016년 3월 이세돌과 바둑을 둔 AI로 학습단계와 플래닝 단계가 나뉘어 있다.
학습 단계 : 사용될 재료를 미리 만들어 둔다.
플래닝 단계 : 대국 도중 실시간으로 이루어지며 바둑알을 어디에 놓을지 고민하는 과정으로 MCTS를 사용하였다.
MCTS(Monte Carlo Tree Search): 예측을 통해 끝까지 가보고 확률을 낸다.
학습이 모든 경우의 수를 파악한 것은 아니기 때문에 플래닝 단계를 활용하여 학습의 불안정성을 제거하고, 이후의 판세를 판단할 수 있다.

학습단계에서는 4개의 네트워크를 학습한다.
정책 네트워크 : sl(기보를 이용한 지도학습), roll(MCTS를 위한 지도학습), rl(스스로 대국하며 강화학습한 정책)
가치 네트워크 : rl
지도학습 정책 sl
19*19 convolution을 통해 한 개를 classification한다. (빠른 학습을 위해 단순하게 Conv를 단순하게 쌓아 학습)
3000만개의 기보 데이터를 통해 학습했으며 바둑판 정보를 사람 지식을 이용하여 만든 48층 feature를 input으로 제공한다.
57%의 정답률을 기록하며 아마 5단정도의 실력을 보여줬다.
롤아웃 정책 roll
sl의 가벼운 버전으로 선형 결합 레이어 한 개가 존재하여 속도가 매우 빠르다.
MCTS에서 같은 시간동안 더 많은 수를 시뮬레이션 할 수 있어 성능을 높여준다.
강화 학습 정책 rl
sl의 파라미터를 가져와서 rl끼리 경기를 시킨다. - 완전 초기화된 파라미터에서 학습하는 것 보다 빠르다.
학습된 rl을 일정 기준마다 풀에 넣어놓고 최신 모델과 경기를 시켜 최신 모델이 편향 되는 것을 막는다.
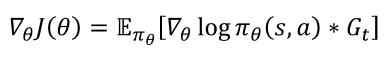
Policy Gradient 방법론을 사용하였고, 그중에서도 리턴만 있으면 학습할 수 있는 Reinforce알고리즘을 사용했다.
이 rl은 v를 만드는데 핵심 역할을 한다.
벨류 네트워크 rl
구조는 sl,rl과 동일하지만 output이 1개 값이다.
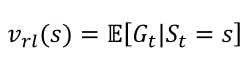
감쇄인자는 1이고, 승과 패에 대한 보상만 있기 때문에 s에서 시작하여 승자를 예측하는 함수이다.
v는 임의의 s를 input으로 넣었을 때 승자를 예측해준다.
MCTS : 그냥 많이 둬 보는 알고리즘
model free인 상황에서 쓰지 못하지만 바둑은 action에 대한 다음 state, 보상이 정해져있으므로 사용이 가능함
state에서 할 수 있는 다양한 action을 할 수 있는 만큼 진행해본다.
그 중 결과가 가장 좋은 action을 선택한다. - rl이 바로 내리는 결정보다 좋다.
노드= state, 엣지 = action
노드를 평가하고, 그 노드에 오기까지 거쳐온 모든 경로의 모든 엣지의 가치를 업데이트 한다.
이 평가를 바탕으로 가장 좋은 action 선택

경험이 많아질 수록 Q의 영향은 커지고, u의 영향은 작아진다.

Q를 왜 s78에서의 v를 평균내는게 아니라 리프 노드를 평균내냐?-> 게임 끝으로 갈 수록 정확해진다.

머리 속으로 트리를 확장하는 과정으로 정책은 함수로 가지고 있다.

가치를 계산하려면 끝까지 가야 한다.
벨류 네트워크를 이용하여 v 구하기
롤 아웃을 이용해 끝까지 가서 Z(이길지 질지)를 구하기
명확하게 유도되는 것도 아니고 그냥 같이 쓰면 좋겠는데 절반씩 해서 하이퍼 파라미터를 쓰거나, 이것 조차 네트웤에 넣는 등 다양한 방법이 있다.
V는 바로 구해지지만 z는 끝까지 가야 구할 수 있다.

Q 는 Backpropagation을 통해 학습한다.
게임을 진행할 수록 점점 정확해진다.
가장 밑의 노드가 제일 정확하다.
기존 Q에 V값을 업데이트 해준다.

정책이 중요하다. 파이가 있어야
Q,N이 업데이트 된다.
MCTS의 목적 -(현재 상태에서 가상의 상태에서 끝까지 가본 다음에 가장 효율적인 액션을 취한다.) 어떤 액션을 취할거냐
Q가 가장 큰 것을 선택하는 것이 일반적임
MCTS는 Q를 선택하는게 아니라 N을 보고 선택
기보가 왜 나왔는지 고민
-> 통계를 통한 좋은 수 찾기
--> 사람이 그 만큼 많이 뒀을까?
=> 인공지능이 사람이 둔 것보다 많이 둬보자
기보를 뛰어 넘어 보자(지도학습)
학습 단계에서 MCTS를 사용한다.
시계열 형태의 뉴럴넷을 사용하진 않았지만 비슷한 효과가 난다 -> 몇 개의 바둑판을 채널로 집어넣었다.
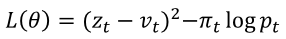
실제로 가본 곳에 대한 정보로 함수를 만든다.-> 가보지 않은 길에 대한 정보도 만들 수 있다.
MCTS는 기보의 역할을 한다.
뉴럴 넷이 다른 일을 하는 것이 아니다.
같은 네트워크를 써도 된다.
네트워크는 같은데 마지막 layer에서 두개의 출력을 뽑기
MCTS로 정책과 가치를 만들어 주는 f(theta)를 학습한다.
MCTS를 써서 이 데이터 샘플을 만든 뒤에 f(theta) - (Vrl의 역할을 하는)를 학습한다
MCTS를 쓴다는 것 자체가 이상하다. -> 4개가 없다.(파이 sl, 파이 roll, 파이 rl, Vrl)
Z는 더해서 평균을 취하는 형태이다.
파이는 확률이다. - 굉장히 작거나 1에 가까울 확률이 있다.->확률은 엔트로피로 사용한다.
f(theta) - 정책하고 가치를 표현할 수 있다.
p가 어디로 갈 지 정해준다.
MCTS로 시작한다.
f(theta) - 랜덤값으로 파라미터 지정되어 있음-> p,v가 엉망이다.
끝까지 가면 진다 이긴다가 나온다.
대국이 끝나면 z가 만들어 진다.
롤 아웃이 없으니까 MCTS를 써서 끝까지 간다.-> 생긴 z를 통해 학습에 사용된다. f(theta)
대국이 끝나야지만 f(theta)를 학습시킬 수 있다.
배치단위로 여러 대국을 학습에 사용할 수 있다.


노드가 만들어지면 확장 및 평가를 진행한다.
파이 Roll out이 없어서 끝까지 가볼 수 없다.
f(theta)는 무거워서 끝까지 돌리긴 오래걸린다.-> Vrl 만 사용한다.

업데이트하고 계속 반복한다.
학습과정에서 MCTS의 사용 - 정책과 z


10. 알파고와 MCTS
10.1 알파고
알파고 소개:
- 알파고는 2016년 3월 이세돌과 바둑을 둔 AI입니다.
- 학습(learning) 단계와 플래닝(decision-time planning) 단계로 나뉩니다.
- 학습 단계: 이세돌과 대국하기 전에 이루어지는 과정으로, 이후 단계에서 사용될 재료를 만듭니다.
- 플래닝 단계: 실시간으로 대국 도중 어디에 바둑알을 놓을지 결정하는 과정으로, MCTS(Monte Carlo Tree Search)를 사용합니다.
학습 단계:
- 실시간 플래닝에서 사용될 재료를 만듭니다.





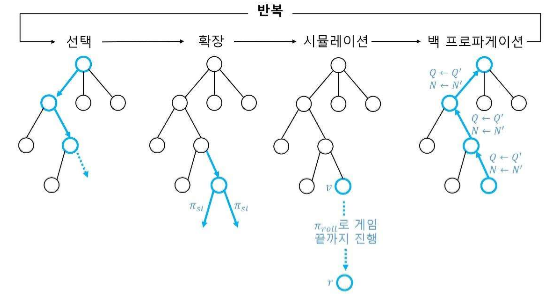
Monte Carlo Tree Search(MCTS):
- 주어진 상황에서 가능한 모든 액션을 시뮬레이션하여 최적의 액션을 선택하는 플래닝 알고리즘.
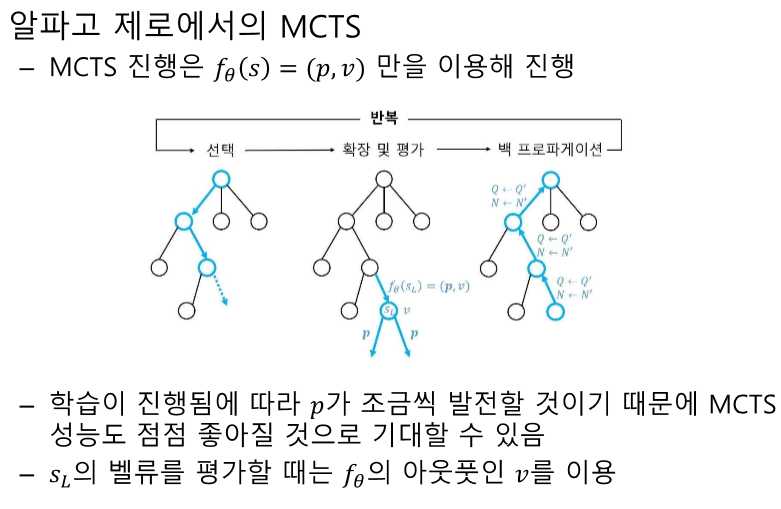
- 선택, 확장, 시뮬레이션, 백 프로파게이션의 4단계로 구성.
- 선택: 루트 노드에서 리프 노드까지 경로를 따라감.
- 확장: 리프 노드를 트리에 추가.
- 시뮬레이션: 리프 노드부터 게임이 끝날 때까지 빠르게 시뮬레이션.
- 백 프로파게이션: 리프 노드의 가치를 루트 노드까지 전파.
10.2 알파고 제로
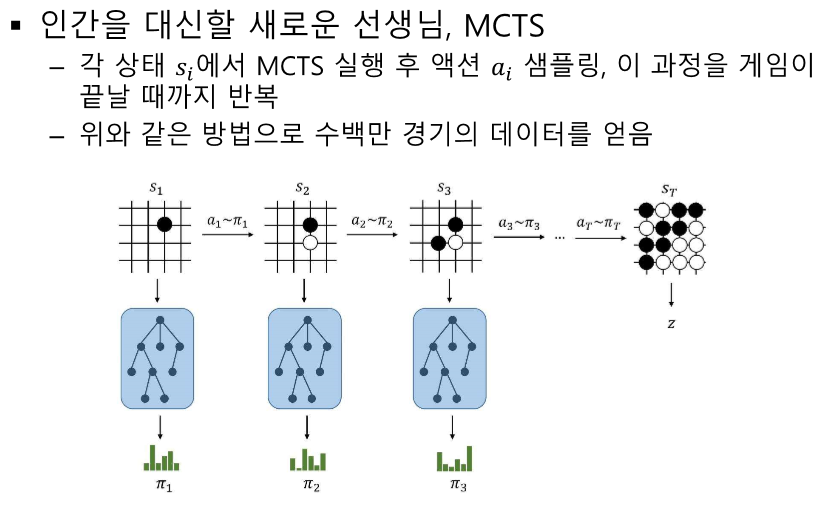
알파고 제로 소개:
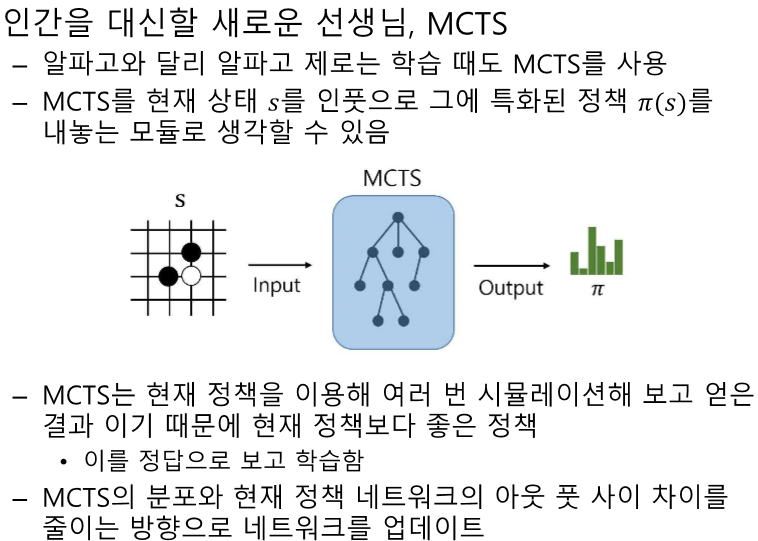
- 알파고 제로는 인간의 기보 데이터를 사용하지 않고 MCTS를 통해 자가 학습하는 AI입니다.
- MCTS를 현재 상태를 인풋으로 하여 특화된 정책을 내놓는 모듈로 사용.
- 각 상태에서 MCTS를 실행하여 얻은 정책을 학습.

알파고와 알파고 제로의 차이점:
- 알파고는 전문가 기보를 사용하여 지도 학습, 알파고 제로는 자체 플레이를 통한 강화 학습만 사용.
- 알파고는 정책 네트워크와 가치 네트워크를 별도로 학습, 알파고 제로는 단일 신경망에서 정책 확률과 가치 예측을 제공.
- 알파고는 지도 학습으로 구축된 정책 네트워크의 출력을 사용, 알파고 제로는 자체 플레이로 학습된 신경망의 정책 출력을 사용.
- 알파고는 롤아웃 정책을 사용, 알파고 제로는 롤아웃 정책을 사용하지 않음.
이 요약을 통해 알파고와 알파고 제로의 학습 방식, MCTS의 원리와 적용 방법에 대해 이해할 수 있습니다. 알파고는 인간의 기보 데이터를 활용한 학습과 MCTS를 결합하여 강력한 성능을 발휘했으며, 알파고 제로는 MCTS를 통해 자가 학습하여 인간 데이터 없이도 높은 성능을 보여주었습니다.
O, X 문제 (10문제)
- 알파고는 2016년 이세돌과의 대국에서 MCTS를 사용했다. (O)
- 해설: 알파고는 이세돌과의 대국에서 MCTS를 사용했습니다.
- 알파고의 학습 단계에서 사용되는 네트워크는 2개이다. (X)
- 해설: 알파고의 학습 단계에서는 3개의 정책 네트워크와 1개의 밸류 네트워크, 총 4개의 네트워크가 사용됩니다.
- 지도 학습 정책 (\pi_{sl})은 바둑 기사의 기보 데이터를 활용하여 학습된다. (O)
- 해설: 지도 학습 정책 (\pi_{sl})은 바둑 기사의 기보 데이터를 활용하여 학습됩니다.
- 롤아웃 정책 (\pi_{roll})은 (\pi_{sl})보다 더 복잡한 구조를 가지고 있다. (X)
- 해설: 롤아웃 정책 (\pi_{roll})은 (\pi_{sl})보다 간단한 구조를 가지고 있습니다.
- 강화 학습 정책 (\pi_{rl})은 self-play를 통해 강화된다. (O)
- 해설: 강화 학습 정책 (\pi_{rl})은 self-play를 통해 강화됩니다.
- 알파고의 보상함수는 경기를 이기면 1, 지면 -1이다. (O)
- 해설: 알파고의 보상함수는 경기를 이기면 1, 지면 -1입니다.
- 밸류 네트워크 (v_{rl})는 19x19 크기의 아웃풋을 가진다. (X)
- 해설: 밸류 네트워크 (v_{rl})는 단일 값을 아웃풋으로 가집니다.
알파고의 학습에 사용된 GPU는 50대이다. (O)해설: 알파고의 학습에는 50대의 GPU가 사용되었습니다.
- MCTS는 선택, 확장, 시뮬레이션, 백프로파게이션의 4단계로 구성된다. (O)
- 해설: MCTS는 선택, 확장, 시뮬레이션, 백프로파게이션의 4단계로 구성됩니다.
- 알파고 제로는 학습 시 롤아웃 정책을 사용한다. (X)
- 해설: 알파고 제로는 학습 시 롤아웃 정책을 사용하지 않습니다.
빈칸 문제 (10문제)
- 알파고는 이세돌과의 대국 도중 실시간 플래닝 알고리즘으로 __을 사용했다. (MCTS)
- 해설: 알파고는 실시간 플래닝 알고리즘으로 MCTS를 사용했습니다.
- 알파고의 학습 단계는 __를 만드는 과정이다. (재료)
- 해설: 학습 단계는 MCTS에 필요한 재료를 만드는 과정입니다.
- 지도 학습 정책 (\pi_{sl})은 19x19=__개의 클래스로 분류한다. (361)
- 해설: 지도 학습 정책 (\pi_{sl})은 361개의 클래스로 분류합니다.
- 롤아웃 정책 (\pi_{roll})의 정확도는 __%이다. (24)
- 해설: 롤아웃 정책 (\pi_{roll})의 정확도는 24%입니다.
- 강화 학습 정책 (\pi_{rl})은 policy gradient 방법론 중 __ 알고리즘을 사용한다. (REINFORCE)
- 해설: 강화 학습 정책 (\pi_{rl})은 REINFORCE 알고리즘을 사용합니다.
- 밸류 네트워크 (v_{rl})의 손실함수는 __로 정의된다. (MSE)
- 해설: 밸류 네트워크 (v_{rl})의 손실함수는 MSE로 정의됩니다.
- MCTS는 주어진 시간 안에 최대한 많은 게임을 __해 보는 방법론이다. (시뮬레이션)
- 해설: MCTS는 최대한 많은 게임을 시뮬레이션해 보는 방법론입니다.
- MCTS는 __, 확장, 시뮬레이션, 백프로파게이션의 4단계로 구성된다. (선택)
- 해설: MCTS는 선택, 확장, 시뮬레이션, 백프로파게이션의 4단계로 구성됩니다.
- 알파고 제로는 학습 시 인간의 __을 사용하지 않는다. (기보)
- 해설: 알파고 제로는 학습 시 인간의 기보를 사용하지 않습니다.
- 알파고 제로에서 MCTS는 현재 정책보다 __ 정책을 제공한다. (좋은)
- 해설: MCTS는 현재 정책보다 좋은 정책을 제공합니다.
서술형 문제 (10문제)
- 알파고의 학습 단계와 실시간 플래닝 단계의 차이점을 설명하시오.
- 정답: 알파고의 학습 단계는 MCTS에 필요한 재료를 미리 만들어 두는 과정이며, 실시간 플래닝 단계는 이세돌과의 대국 도중에 실시간으로 MCTS를 사용하여 어디에 바둑알을 놓을지 결정하는 과정입니다.
- 해설: 학습 단계는 준비 과정이고, 실시간 플래닝 단계는 실제 대국 중 의사결정 과정입니다.
- 지도 학습 정책 (\pi_{sl})의 학습 방법과 구조를 설명하시오.
- 정답: 지도 학습 정책 (\pi_{sl})은 바둑 기사의 기보 데이터를 활용하여 학습되며, 바둑판의 상태 정보를 입력으로 받아 19x19=361개의 바둑 칸 중 둘 수 있는 곳에 대해 돌을 내려놓을 확률을 반환합니다. 13개의 컨볼루션 레이어로 구성되어 있으며, 48겹의 바둑판 정보를 인풋으로 받습니다.
- 해설: 지도 학습 정책 (\pi_{sl})은 기보 데이터를 활용하고, 컨볼루션 레이어로 구성된 신경망 구조를 가집니다.
- 롤아웃 정책 (\pi_{roll})의 역할과 필요성을 설명하시오.
- 정답: 롤아웃 정책 (\pi_{roll})은 (\pi_{sl})의 간단한 버전으로, 속도가 매우 빠르기 때문에 MCTS 단계에서 많은 수를 시뮬레이션할 수 있습니다. 이는 MCTS의 성능을 향상시키는 데 중요한 역할을 합니다.
- 해설: 롤아웃 정책 (\pi_{roll})은 빠른 속도로 많은 수를 시뮬레이션하여 MCTS의 성능을 높입니다.
- 강화 학습 정책 (\pi_{rl})의 학습 과정과 보상함수에 대해 설명하시오.
- 정답: 강화 학습 정책 (\pi_{rl})은 self-play를 통해 학습되며, policy gradient 방법론 중 REINFORCE 알고리즘을 사용합니다. 보상함수는 경기를 이기면 1, 지면 -1을 부여하며, 중간 보상은 없습니다.
- 해설: 강화 학습 정책 (\pi_{rl})은 self-play와 REINFORCE 알고리즘을 통해 학습되며, 단순한 보상함수를 사용합니다.
- 밸류 네트워크 (v_{rl})의 역할과 학습 방법을 설명하시오.
- 정답: 밸류 네트워크 (v_{rl})는 특정 상태에서 게임의 승자를 예측하는 함수로, 학습 결과로 주어진 상태에서 1을 받을지, -1을 받을지를 예측합니다. 손실함수는 MSE를 사용하며, 50개의 GPU로 1주일간 학습되었습니다.
- 해설: 밸류 네트워크 (v_{rl})는 게임의 승자를 예측하며, MSE 손실함수를 사용하여 학습됩니다.
- MCTS의 4단계인 선택, 확장, 시뮬레이션, 백프로파게이션에 대해 설명하시오.
- 정답: MCTS의 선택 단계는 루트 노드에서 리프 노드까지 이동하며 액션을 선택하는 과정입니다. 확장 단계는 리프 노드를 트리에 추가하고 에지 정보를 초기화하는 과정입니다. 시뮬레이션 단계는 리프 노드에서 게임을 끝까지 시뮬레이션하여 밸류를 계산하는 과정입니다. 백프로파게이션 단계는 리프 노드의 밸류를 루트 노드까지 전파하여 업데이트하는 과정입니다.
- 해설: MCTS는 선택, 확장, 시뮬레이션, 백프로파게이션의 4단계를 통해 상태와 액션을 평가하고 업데이트합니다.
- 알파고 제로의 학습 방법
과 알파고와의 차이점을 설명하시오.
- 정답: 알파고 제로는 인간의 기보 없이 self-play와 MCTS를 사용하여 학습합니다. 알파고와 달리 정책 네트워크와 밸류 네트워크를 하나의 신경망에서 학습하며, 롤아웃 정책을 사용하지 않습니다. 이는 더 효율적이고 강력한 학습 방법을 제공합니다.
- 해설: 알파고 제로는 self-play와 MCTS를 사용하여 학습하며, 알파고와 달리 하나의 신경망을 사용하고 롤아웃 정책을 사용하지 않습니다.
- MCTS에서 시뮬레이션 단계의 역할을 설명하시오.
- 정답: MCTS의 시뮬레이션 단계는 리프 노드에서 게임을 끝까지 시뮬레이션하여 해당 노드의 밸류를 계산하는 과정입니다. 알파고는 두 가지 방법(롤아웃 정책과 밸류 네트워크)으로 시뮬레이션을 수행하며, 결과를 결합하여 노드의 밸류를 계산합니다.
- 해설: 시뮬레이션 단계는 리프 노드의 밸류를 계산하여 노드를 평가하는 데 중요한 역할을 합니다.
- 알파고와 알파고 제로에서 MCTS의 사용 방식 차이점을 설명하시오.
- 정답: 알파고는 실시간 대국에서 MCTS를 사용하고, 학습 시에는 롤아웃 정책을 사용합니다. 반면, 알파고 제로는 학습과 대국 모두에서 MCTS를 사용하며, 롤아웃 정책을 사용하지 않습니다. 또한, 알파고 제로는 MCTS 결과를 기반으로 신경망을 업데이트합니다.
- 해설: 알파고는 실시간 대국에서 MCTS를 사용하고, 학습 시에는 롤아웃 정책을 사용합니다. 알파고 제로는 학습과 대국 모두에서 MCTS를 사용하며, 롤아웃 정책을 사용하지 않습니다.
- 알파고 제로에서 신경망의 업데이트 방법을 설명하시오.
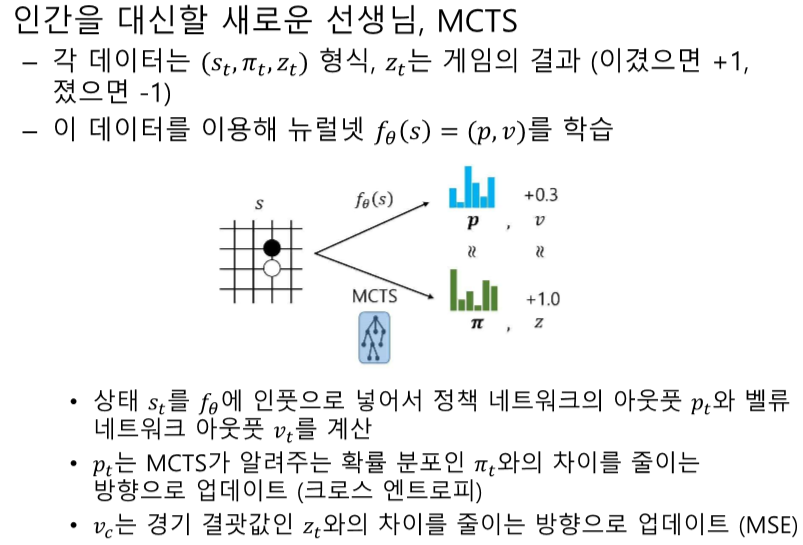
- 정답: 알파고 제로는 MCTS 결과를 기반으로 신경망을 업데이트합니다. 각 상태 (s_t)에서 MCTS를 실행하고, 결과로 나온 정책 분포 (\pi_t)와 벨류 (v_t)를 사용하여 신경망을 업데이트합니다. 정책 네트워크는 MCTS의 정책 분포와의 크로스 엔트로피를 최소화하고, 벨류 네트워크는 실제 게임 결과와의 MSE를 최소화합니다.
- 해설: 알파고 제로는 MCTS 결과를 기반으로 신경망을 업데이트하며, 크로스 엔트로피와 MSE를 최소화합니다.
단답형 문제 (10문제)
- 알파고는 이세돌과의 대국 도중 실시간 플래닝 알고리즘으로 무엇을 사용했는가?
- 정답: MCTS
- 해설: 알파고는 실시간 플래닝 알고리즘으로 MCTS를 사용했습니다.
- 알파고의 학습 단계에서 사용되는 네트워크는 몇 개인가?
- 정답: 4개 (3개의 정책 네트워크, 1개의 밸류 네트워크)
- 해설: 알파고의 학습 단계에서는 4개의 네트워크가 사용됩니다.
- 지도 학습 정책 (\pi_{sl})은 바둑 기사의 무엇을 활용하여 학습되는가?
- 정답: 기보 데이터
- 해설: 지도 학습 정책 (\pi_{sl})은 바둑 기사의 기보 데이터를 활용하여 학습됩니다.
- 롤아웃 정책 (\pi_{roll})의 정확도는 몇 %인가?
- 정답: 24%
- 해설: 롤아웃 정책 (\pi_{roll})의 정확도는 24%입니다.
- 강화 학습 정책 (\pi_{rl})은 어떤 알고리즘을 사용하여 학습되는가?
- 정답: REINFORCE
- 해설: 강화 학습 정책 (\pi_{rl})은 REINFORCE 알고리즘을 사용합니다.
- 밸류 네트워크 (v_{rl})의 손실함수는 무엇인가?
- 정답: MSE
- 해설: 밸류 네트워크 (v_{rl})의 손실함수는 MSE입니다.
- MCTS는 주어진 시간 안에 최대한 많은 게임을 무엇해 보는 방법론인가?
- 정답: 시뮬레이션
- 해설: MCTS는 주어진 시간 안에 최대한 많은 게임을 시뮬레이션해 보는 방법론입니다.
- 알파고 제로는 학습 시 인간의 무엇을 사용하지 않는가?
- 정답: 기보
- 해설: 알파고 제로는 학습 시 인간의 기보를 사용하지 않습니다.
- 알파고 제로에서 MCTS는 현재 정책보다 어떤 정책을 제공하는가?
- 정답: 좋은 정책
- 해설: MCTS는 현재 정책보다 좋은 정책을 제공합니다.
- 알파고 제로에서 신경망의 업데이트 방법은 무엇을 기반으로 하는가?
- 정답: MCTS 결과
- 해설: 알파고 제로는 MCTS 결과를 기반으로 신경망을 업데이트합니다.
'인공지능 > 강화학습' 카테고리의 다른 글
| 강화학습 12강 - Deep RL 심화 (1) | 2024.06.09 |
|---|---|
| 강화학습 11강 - 강화학습 실습 예제 (1) | 2024.06.08 |
| 강화학습 9장 - 정책 기반 에이전트 (1) | 2024.06.08 |
| 강화학습 8강 - 가치 기반 에이전트 (1) | 2024.06.07 |
| 강화학습 7강 - DEEP RL 개요 (1) | 2024.06.07 |