가치 기반 에이전트는 V와 Q를 만든다.
V, Q 계산을 잘해야 최적의 정책을 찾을 수 있다.

가치 기반 : 가치 함수에 기반하여 액션 선택
모델 프리상황(v를 사용하기 힘들다)에서는 v를 보고 알 수 없기 때문에 q를 사용한다.
정책 기반 : 정책 함수에 기반하여 액션 선택
액터 크리틱 : 가치 함수와 정책 함수를 모두 사용한다.
액터 : 정책
크리틱 : v,q
벨류네트워크는 정책이 고정되어 있을 때 뉴럴넷을 이용하여 학습한다.
이렇게 만든 네트워크는 테이블 필요없이 input인 state만 주면 값이 튀어나온다.
업데이트 진행은 MSE를 활용한 경사 하강법과 동일하다. 그러나 강화학습에는 라벨이 없기 때문에 TD나 MC를 활용하여 True 값을 만들어 준다.
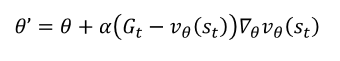

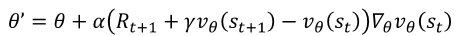
딥 Q 러닝
가치 기반 에이전트는 명시된 정책이 없다 -> 내재된 정책인 q를 활용하여 최대값으로 가자
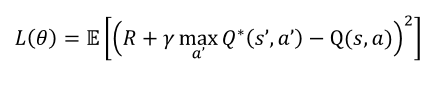
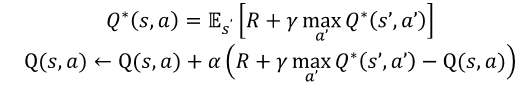
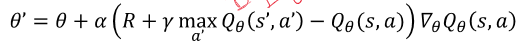
Q는 진행할수록 Q*에 가까워진다.
기댓값 연잔자를 없애기 위해 미니 배치를 활용하여 평균값을 사용한다.
Q러닝은 off-Policy 학습이다.

진행 순서
1. Q 파라미터 초기화
2. 에이전트 상태 초기화
3. 에피소드 끝날 때 까지 4번 반복
4. Q에 대해 입실론 그리디를 통해 액션 a 선택 -> a 실행 후 리워드와 s' 관측 -> s'에서 greedy를 통해 a' 선택 -> 파라미터 업데이트 -> s= s'
임의의 샘플을 가져와서 다른 정책을 사용해 본다!!

여기선 네트워크를 두개 사용한다.
PDF 문서 "[SJU-2024-1] 강화학습_08"의 내용을 요약하여 설명드리겠습니다.
8. 가치 기반 에이전트
8.1 밸류 네트워크의 학습
가치 함수와 정책 함수:

가치 기반 접근법:
- 가치 함수에 근거하여 액션을 선택.
- 모델-프리 상황에서는 액션-가치 함수 𝑞(𝑠, 𝑎)를 사용.
정책 기반 접근법:
- 정책 함수를 보고 직접 액션을 선택.
액터-크리틱(Actor-Critic):

밸류 네트워크의 학습:

손실함수와 그래디언트:
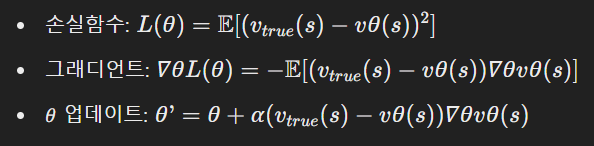
몬테카를로 리턴:

TD 타깃:

8.2 딥 Q러닝
Q러닝:
- 가치 기반 에이전트는 명시적 정책이 없으며, 액션-가치함수 𝑞(𝑠, 𝑎)를 이용.
- 벨만 최적 방정식과 테이블 업데이트 수식을 뉴럴넷으로 확장.
딥 Q러닝(DQN):

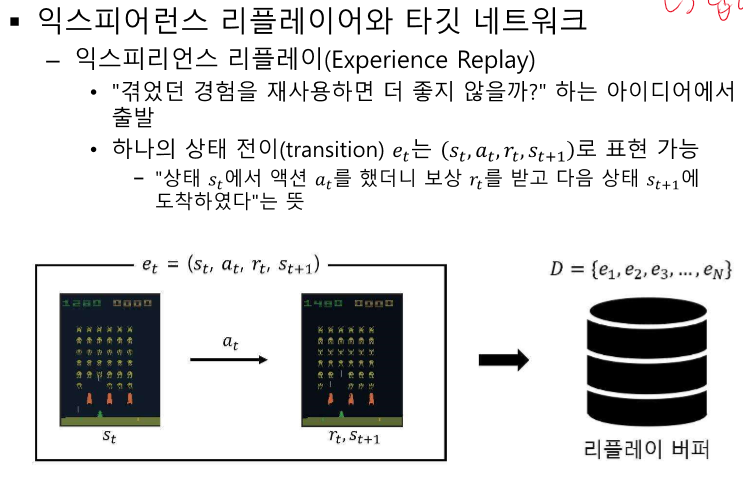
익스피어런스 리플레이(Experience Replay):
- 경험을 재사용하여 학습 효율성을 높임.
- 리플레이 버퍼에 최근 데이터를 저장하고, 학습 시 임의로 데이터를 뽑아서 사용.
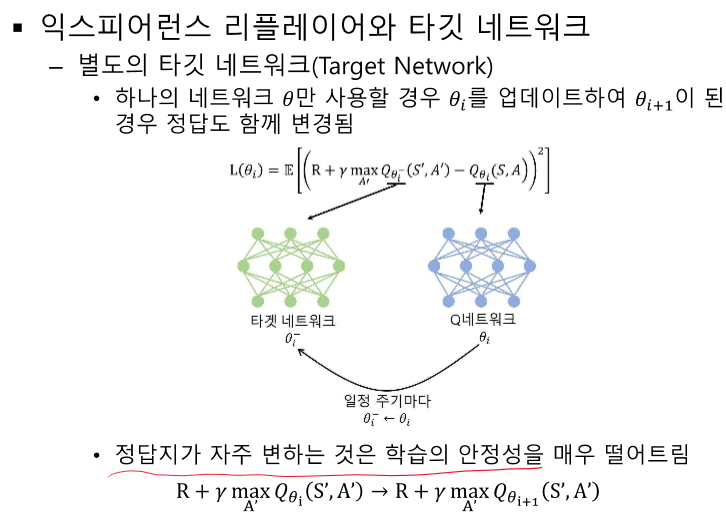
타깃 네트워크(Target Network):
- 하나의 네트워크만 사용할 경우 정답이 자주 변하여 학습 안정성이 떨어짐.
- 타깃 네트워크를 사용하여 정답을 고정시킴.
DQN 구현:
- 기본적인 Q-네트워크와 타깃 네트워크를 구성하고, 익스피어런스 리플레이를 사용하여 학습을 진행.
- gym 라이브러리를 사용하여 환경을 설정하고, PyTorch를 사용하여 Q-네트워크를 구현.
이 요약을 통해 가치 기반 에이전트와 딥 Q러닝의 개념, 학습 방법, 그리고 구현 방법을 이해할 수 있습니다. 가치 함수와 정책 함수를 뉴럴넷으로 표현하고, 이를 효율적으로 학습하는 다양한 기법들을 소개하고 있습니다. DQN의 경우 익스피어런스 리플레이와 타깃 네트워크를 통해 학습 안정성과 효율성을 높이는 방법을 설명합니다.
O, X 문제 (10문제)

- 정책 기반 방법은 정책 함수 (\pi(a|s))를 뉴럴넷으로 표현하여 직접 액션을 선택한다. (O)
- 해설: 정책 기반 방법은 뉴럴넷을 사용하여 정책 함수를 표현하고 직접 액션을 선택합니다.
- 밸류 네트워크 학습에서 손실 함수는 MSE를 사용하여 최적화된다. (O)
- 해설: 밸류 네트워크 학습에서는 손실 함수로 MSE를 사용하여 최적화합니다.
- Monte Carlo 리턴 방식은 TD 타깃 방식보다 더 빠르게 수렴한다. (X)
- 해설: Monte Carlo 리턴 방식은 전체 에피소드를 다 봐야 하기 때문에 수렴 속도가 느릴 수 있습니다.
- Q러닝은 가치 기반 에이전트에서 내재된 정책을 사용하여 학습한다. (O)
- 해설: Q러닝은 내재된 정책을 사용하여 학습합니다.

- 경험 재생(Experience Replay)은 이전의 경험을 재사용하여 학습 효율성을 높인다. (O)
- 해설: 경험 재생은 이전의 경험을 재사용하여 학습 효율성을 높입니다.
- 타깃 네트워크(Target Network)는 Q러닝에서 학습의 안정성을 높이기 위해 사용된다. (O)
- 해설: 타깃 네트워크는 학습의 안정성을 높이기 위해 사용됩니다.
- DQN은 off-policy 학습 알고리즘이다. (O)
- 해설: DQN은 off-policy 학습 알고리즘입니다.
- 미니 배치(mini-batch)는 데이터의 상관성을 높여 학습을 더 효율적으로 만든다. (X)
- 해설: 미니 배치는 데이터의 상관성을 낮춰 학습 효율을 높입니다.
빈칸 문제 (10문제)
- 밸류 네트워크(Value Network)는 뉴럴넷으로 가치 함수 (______)나 (______)를 표현하는 방식이다. (v_\pi(s), q_\pi(s, a))

- 밸류 네트워크 학습에서 손실 함수는 ______\를 사용하여 최적화된다. (MSE)
- 해설: 손실 함수로 MSE를 사용하여 최적화합니다.
- 첫 번째 대안인 Monte Carlo 리턴 방식에서는 기댓값 손실함수의 정답 자리에 ______\를 대입한다. (G_t)
- 해설: 기댓값 손실함수의 정답 자리에 (G_t)를 대입합니다.
- 두 번째 대안인 TD 타깃 방식에서는 기댓값 손실함수의 정답 자리에 ______\를 대입한다. (R_{t+1} + \gamma v_\theta(s_{t+1}))
- Q러닝은 내재된 정책(implicit policy)인 ______\를 이용하여 학습한다. (액션-가치함수)
- 해설: 내재된 정책인 액션-가치함수를 이용하여 학습합니다.
- (\epsilon)-greedy는 ______\를 선택하는 행동 정책이다. (액션)
- 경험 재생(Experience Replay)은 이전의 ______\를 재사용하여 학습 효율성을 높인다. (경험)
- 해설: 이전의 경험을 재사용하여 학습 효율성을 높입니다.
- 타깃 네트워크(Target Network)는 Q러닝에서 학습의 ______\를 높이기 위해 사용된다. (안정성)
- 해설: 타깃 네트워크는 학습의 안정성을 높이기 위해 사용됩니다.
- DQN은 ______\ 학습 알고리즘이다. (off-policy)
- 해설: DQN은 off-policy 학습 알고리즘입니다.
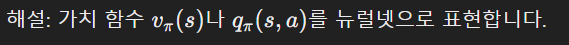


서술형 문제 (10문제)
- 가치 기반 에이전트의 밸류 네트워크 학습 방식을 설명하시오.

- 해설: 밸류 네트워크는 뉴럴넷을 사용하여 가치 함수를 학습하며, Monte Carlo 리턴과 TD 타깃 방식을 통해 손실 함수를 최적화합니다.
- Q러닝의 이론적 배경과 실제 적용 방식을 설명하시오.

- 해설: Q러닝은 액션-가치함수를 사용하여 학습하며, 벨만 최적 방정식을 적용하고 뉴럴넷으로 Q함수를 근사합니다. off-policy 학습 방법과 경험 재생, 타깃 네트워크를 통해 학습의 효율성과 안정성을 높입니다.
- 경험 재생(Experience Replay)의 개념과 그 효과를 설명하시오.
- 정답: 경험 재생은 이전의 경험을 저장하여 필요할 때 재사용하는 방법입니다. 리플레이 버퍼에 최근 데이터를 저장하고, 학습 시 이 데이터들을 임의로 샘플링하여 사용합니다. 이는 데이터의 상관성을 낮추고, 샘플 효율성을 높여 학습을 안정적이고 효율적으로 만듭니다.
- 해설: 경험 재생은 학습 효율성과 안정성을 높이기 위해 이전 경험을 재사용하는 방법입니다.
- 타깃 네트워크(Target Network)의 필요성과 그 역할을 설명하시오.
- 정답: 타깃 네트워크는 Q러닝에서 학습의 안정성을 높이기 위해 사용됩니다. 단일 네트워크로 학습할 경우 업데이트 과정에서 정답지가 자주 변하여 학습이 불안정해질 수 있습니다. 타깃 네트워크는 주기적으로 업데이트하여 정답지를 고정함으로써 안정적인 학습을 가능하게 합니다.
- 해설: 타깃 네트워크는 정답지를 고정하여 학습의 안정성을 높이는 역할을 합니다.
- (\epsilon)-greedy 정책이 강화학습에서 중요한 이유를 설명하시오.

- 해설: (\epsilon)-greedy 정책은 탐험과 활용의 균형을 맞추어 최적의 정책을 학습하는 데 중요합니다.
- 가치 기반 학습과 정책 기반 학습의 차이점을 설명하시오.

- 해설: 가치 기반 학습과 정책 기반 학습은 액션 선택 방식에서 차이가 있으며, 각각 Q러닝과 Actor-Critic 방법이 사용됩니다.
- Monte Carlo 리턴과 TD 타깃 방식의 차이점을 설명하시오.

- 해설: Monte Carlo 리턴과 TD 타깃 방식은 업데이트 시 사용하는 값에서 차이가 있으며, 각각의 장단점이 있습니다.
- 강화학습에서 뉴럴넷을 사용하는 이유와 그 장점을 설명하시오.
- 정답: 뉴럴넷은 복잡한 함수 근사를 수행할 수 있어 대규모 상태 공간에서도 효과적으로 학습할 수 있습니다. 이는 기존의 테이블 기반 방법이 상태 공간이 커질수록 비효율적이기 때문에 뉴럴넷을 사용하면 더 복잡한 환경에서 높은 성능을 발휘할 수 있습니다.
- 해설: 뉴럴넷은 복잡한 함수 근사와 대규모 상태 공간에서의 효율적인 학습을 가능하게 합니다.
- DQN의 pseudo code를 설명하고, 그 작동 원리를 서술하시오.
- 정답: DQN은 Q값을 근사하는 뉴럴넷 (Q_\theta)를 초기화하고, 에피소드마다 (\epsilon)-greedy 정책으로 액션을 선택하여 보상과 다음 상태를 관측합니다. 이후, 경험 재생 버퍼에 저장된 데이터로 미니 배치를 구성하여 손실 함수를 최소화하는 방향으로 뉴럴넷을 업데이트합니다. 주기적으로 타깃 네트워크를 업데이트하여 학습의 안정성을 유지합니다.
- 해설: DQN은 (\epsilon)-greedy 정책, 경험 재생, 타깃 네트워크를 통해 Q값을 근사하고 학습합니다.
- 강화학습에서 기댓값 손실함수의 역할과 그 중요성을 설명하시오.
- 정답: 기댓값 손실함수는 모델이 예측한 가치와 실제 가치 간의 차이를 최소화하기 위해 사용됩니다. 이는 모델의 예측 정확성을 높이고, 학습의 수렴 속도를 빠르게 하여 최적의 정책을 학습하는 데 중요합니다.
- 해설: 기댓값 손실함수는 모델의 예측 정확성을 높이고, 최적의 정책을 학습하는 데 중요한 역할을 합니다.
단답형 문제 (10문제)
- 밸류 네트워크(Value Network)는 뉴럴넷으로 가치 함수 (______)나 (______)를 표현하는 방식이다.
- 정책 기반 방법은 정책 함수 (______)를 뉴럴넷으로 표현하여 직접 액션을 선택한다.
- 밸류 네트워크 학습에서 손실 함수는 ______\를 사용하여 최적화된다.
- 정답: MSE
- 첫 번째 대안인 Monte Carlo 리턴 방식에서는 기댓값 손실함수의 정답 자리에 ______\를 대입한다.
- 정답: (G_t)
- 두 번째 대안인 TD 타깃 방식에서는 기댓값 손실함수의 정답 자리에 ______\를 대입한다.
- Q러닝은 내재된 정책(implicit policy)인 ______를 이용하여 학습한다.
- 정답: 액션-가치함수
- (\epsilon)-greedy는 ______를 선택하는 행동 정책이다.
- 정답: 액션
- 경험 재생(Experience Replay)은 이전의 ______를 재사용하여 학습 효율성을 높인다.
- 정답: 경험
- 타깃 네트워크(Target Network)는 Q러닝에서 학습의 ______를 높이기 위해 사용된다.
- 정답: 안정성
- DQN은 ______학습 알고리즘이다.
- 정답: off-policy

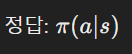

단답형 문제 (10문제)
- 밸류 네트워크(Value Network)는 뉴럴넷으로 가치 함수 (v_\pi(s))나 (q_\pi(s, a))를 표현하는 방식이다.
- 정답: (v_\pi(s)), (q_\pi(s, a))
- 해설: 가치 함수 (v_\pi(s))나 (q_\pi(s, a))를 뉴럴넷으로 표현합니다.
- 정책 기반 방법은 정책 함수 (\pi(a|s))를 뉴럴넷으로 표현하여 직접 액션을 선택한다.
- 정답: (\pi(a|s))
- 해설: 정책 함수 (\pi(a|s))를 뉴럴넷으로 표현하여 직접 액션을 선택합니다.
- 밸류 네트워크 학습에서 손실 함수는 MSE를 사용하여 최적화된다.
- 정답: MSE
- 해설: 손실 함수로 MSE를 사용하여 최적화합니다.
- 첫 번째 대안인 Monte Carlo 리턴 방식에서는 기댓값 손실함수의 정답 자리에 (G_t)를 대입한다.
- 정답: (G_t)
- 해설: 기댓값 손실함수의 정답 자리에 (G_t)를 대입합니다.
- 두 번째 대안인 TD 타깃 방식에서는 기댓값 손실함수의 정답 자리에 (R_{t+1} + \gamma v_\theta(s_{t+1}))를 대입한다.
- 정답: (R_{t+1} + \gamma v_\theta(s_{t+1}))
- 해설: 기댓값 손실함수의 정답 자리에 (R_{t+1} + \gamma v_\theta(s_{t+1}))를 대입합니다.
- Q러닝은 내재된 정책(implicit policy)인 액션-가치함수를 이용하여 학습한다.
- 정답: 액션-가치함수
- 해설: 내재된 정책인 액션-가치함수를 이용하여 학습합니다.
- (\epsilon)-greedy는 액션을 선택하는 행동 정책이다.
- 정답: 액션
- 해설: (\epsilon)-greedy는 액션을 선택하는 행동 정책입니다.
- 경험 재생(Experience Replay)은 이전의 경험을 재사용하여 학습 효율성을 높인다.
- 정답: 경험
- 해설: 이전의 경험을 재사용하여 학습 효율성을 높입니다.
- 타깃 네트워크(Target Network)는 Q러닝에서 학습의 안정성을 높이기 위해 사용된다.
- 정답: 안정성
- 해설: 타깃 네트워크는 학습의 안정성을 높이기 위해 사용됩니다.
- DQN은 off-policy 학습 알고리즘이다.
- 정답: off-policy
- 해설: DQN은 off-policy 학습 알고리즘입니다.
'인공지능 > 강화학습' 카테고리의 다른 글
| 강화학습 10장 - 알파고와 MCTS (0) | 2024.06.08 |
|---|---|
| 강화학습 9장 - 정책 기반 에이전트 (1) | 2024.06.08 |
| 강화학습 7강 - DEEP RL 개요 (1) | 2024.06.07 |
| Matlab 강화학습 - simulink 환경 만들기 및 에이전트 훈련시키기 (0) | 2024.05.10 |
| matlab 강화학습 onramp 8 - 에이전트 훈련시키기 (0) | 2024.05.09 |