테이블 대신에 함수를 사용한다
mse를 최소로 하는 선을 찾아서 없는 값들도 유추할 수 있다.
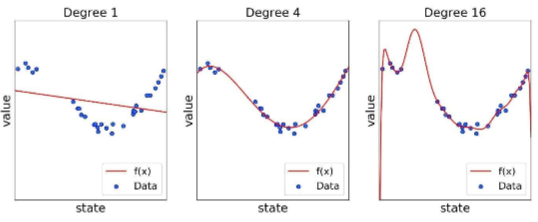
일반적인 직선 말고도 다항 함수를 사용하여 데이터 점들을 가장 가깝게 지나가게 할 수 있다.
고차함수에 가깝게 갈수록 mse는 떨어지겠지만 노이즈에 민감하게 반응한다
언더 피팅 : 함수의 유연성이 부족하여 주어진 데이터와 에러가 너무 크다.
오버 피팅 : 함수가 너무 유연하여 노이즈에 피팅해버리는 것
실험을 통해 주어진 데이터는 노이즈가 껴있기 때문에 적절하게 차수를 선정해야 한다.
강화학습에서 state가 너무 많으면 테이블의 모든 Value를 담을 수 없다. -> Value를 구하는 함수를 학습하자.
일반화 : 전체를 다 경험하지 못하더라도 일부 샘플만으로 전체를 추정하는 것
함수를 인공 신경망을 통해 복잡하게 만들어 보자!
인공신경망은 매우 유연한 함수로, 파라미터(free parameter)를 통해 유연성을 표현 가능하다. 손실함수와의 오차를 통해 파라미터를 학습하고, 편미분을 통해 모든 파라미터의 오차를 구할 수 있다.
편미분을 통해 기울기(gradient)를 구한다 -> w를 gradient (반대?) 방향으로 움직인다.
learning rage(학습률) : w를 얼마나 이동할지 결정하는 작은 상수 == 스탭 사이즈(step size)
이 과정을 gradient descent라고 부른다.

강화학습에선 다양한 딥러닝이 존재한다.
7. Deep RL 첫 걸음
7.1 함수를 활용한 근사
함수의 등장:
- 테이블 대신 함수를 이용하여 가치 함수를 근사.
- 예: ( f(x) = ax + b )
- 함수는 데이터가 많은 경우 유용.
함수의 복잡도:
- 다항 함수(polynomial function)를 사용하여 다양한 차수의 함수를 근사.
- 고차 함수일수록 데이터 노이즈에 민감함.
오버피팅과 언더피팅:
- 오버피팅: 너무 복잡한 함수를 사용하여 노이즈에 민감해지는 현상.
- 언더피팅: 함수의 유연성이 부족하여 데이터와의 오차가 큰 경우.
함수의 장점 - 일반화:
- 상태의 수가 많은 경우, 테이블 기반 접근법보다 함수 기반 접근법이 유리함.
- 새로운 데이터에 대해 예측 가능.
7.2 인공 신경망의 도입
인공 신경망(Artificial Neural Network):
- 매우 유연한 함수로, 프리 파라미터(free parameter)의 개수에 따라 유연성이 달라짐.
신경망 학습 - 경사하강법(Gradient Descent):
- 손실 함수(loss function)와 미분(derivative)을 이용하여 파라미터를 업데이트.
- 러닝 레이트(learning rate)를 사용하여 파라미터 업데이트 크기 조절.
파이토치를 이용한 신경망 학습 구현:
- PyTorch 라이브러리를 사용하여 신경망을 구축하고 학습.
- 신경망은 입력층, 은닉층, 출력층으로 구성됨.
- 코드 예제:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.fc1 = nn.Linear(1, 128)
self.fc2 = nn.Linear(128, 128)
self.fc3 = nn.Linear(128, 128)
self.fc4 = nn.Linear(128, 1, bias=False)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = F.relu(self.fc3(x))
x = self.fc4(x)
return x
def true_fun(X):
noise = np.random.rand(X.shape[0]) * 0.4 - 0.2
return np.cos(1.5 * np.pi * X) + X + noise
def plot_results(model):
x = np.linspace(0, 5, 100)
input_x = torch.from_numpy(x).float().unsqueeze(1)
plt.plot(x, true_fun(x), label="Truth")
plt.plot(x, model(input_x).detach().numpy(), label="Prediction")
plt.legend(loc='lower right', fontsize=15)
plt.xlim((0, 5))
plt.ylim((-1, 5))
plt.grid()
def main():
data_x = np.random.rand(10000) * 5
model = Model()
optimizer = optim.Adam(model.parameters(), lr=0.001)
for step in range(10000):
batch_x = np.random.choice(data_x, 32)
batch_x_tensor = torch.from_numpy(batch_x).float().unsqueeze(1)
pred = model(batch_x_tensor)
batch_y = true_fun(batch_x)
truth = torch.from_numpy(batch_y).float().unsqueeze(1)
loss = F.mse_loss(pred, truth)
optimizer.zero_grad()
loss.mean().backward()
optimizer.step()
plot_results(model)
if __name__ == '__main__':
main()7.3 인공 신경망 기반 강화학습
Deep RL for video games:
- DQN, Dueling DQN, DRQN, Actor-Critic, Reactor 등 다양한 신경망 기반 강화학습 알고리즘이 비디오 게임에 적용됨.
Deep RL for audio-based applications:
- 오디오 기반 애플리케이션에서도 Deep RL이 사용됨.
강의 내용은 함수 근사, 인공 신경망 도입, 그리고 인공 신경망 기반 강화학습에 대한 기초 개념과 구현 방법을 다루고 있습니다. 인공 신경망을 사용하여 복잡한 문제를 해결하고, 이를 강화학습에 적용하는 방법을 설명하고 있습니다.
ㅁㅁ
O, X 문제 (10문제)
- 함수 근사는 테이블 대신 함수를 이용하여 상태 가치를 저장하는 방법이다. (O)
- 해설: 함수 근사는 테이블 대신 함수를 사용하여 상태 가치를 저장하고 예측하는 방법입니다.
- 다항 함수는 1차 함수보다 복잡한 문제를 해결하는 데 유리하다. (O)
- 해설: 다항 함수는 1차 함수보다 더 복잡한 문제를 해결할 수 있는 유연성을 가지고 있습니다.
- 오버피팅은 모델이 훈련 데이터의 노이즈까지 학습하여 일반화 능력이 떨어지는 현상이다. (O)
- 해설: 오버피팅은 모델이 훈련 데이터의 노이즈까지 학습하여 새로운 데이터에 대한 예측 성능이 떨어지는 현상입니다.
- 언더피팅은 모델이 주어진 데이터의 패턴을 충분히 학습하지 못한 상태를 의미한다. (O)
- 해설: 언더피팅은 모델이 주어진 데이터의 패턴을 충분히 학습하지 못해 예측 성능이 낮은 상태를 의미합니다.
- 인공 신경망은 매우 유연한 함수로, 다양한 문제를 해결하는 데 사용될 수 있다. (O)
- 해설: 인공 신경망은 매우 유연한 함수로, 다양한 문제 해결에 사용됩니다.
- 그라디언트 디센트는 손실 함수를 최소화하기 위해 파라미터를 업데이트하는 알고리즘이다. (O)
- 해설: 그라디언트 디센트는 손실 함수를 최소화하기 위해 파라미터를 업데이트하는 알고리즘입니다.
- 인공 신경망 학습에서 편미분은 각 파라미터가 손실 함수에 미치는 영향을 계산하는 데 사용된다. (O)
- 해설: 편미분은 각 파라미터가 손실 함수에 미치는 영향을 계산하는 데 사용됩니다.
- 인공 신경망 학습에서 러닝 레이트는 파라미터 업데이트 크기를 결정하는 상수이다. (O)
- 해설: 러닝 레이트는 파라미터 업데이트 크기를 결정하는 상수입니다.
- DQN은 비디오 게임 환경에서 강화학습을 수행하는 알고리즘이다. (O)
- 해설: DQN은 비디오 게임 환경에서 강화학습을 수행하는 알고리즘입니다.
- DRQN은 인공 신경망을 사용하지 않는 강화학습 알고리즘이다. (X)
- 해설: DRQN은 인공 신경망을 사용하여 순차적인 데이터에 대한 강화학습을 수행하는 알고리즘입니다.
빈칸 문제 (10문제)
- 함수 근사는 테이블 대신 __를 이용하여 상태 가치를 저장하는 방법이다. (함수)
- 해설: 함수 근사는 테이블 대신 함수를 사용하여 상태 가치를 저장하고 예측하는 방법입니다.
- 다항 함수는 __ 함수보다 더 복잡한 문제를 해결할 수 있다. (1차)
- 해설: 다항 함수는 1차 함수보다 더 복잡한 문제를 해결할 수 있습니다.
- 오버피팅은 모델이 훈련 데이터의 __까지 학습하여 일반화 능력이 떨어지는 현상이다. (노이즈)
- 해설: 오버피팅은 모델이 훈련 데이터의 노이즈까지 학습하여 일반화 능력이 떨어지는 현상입니다.
- 언더피팅은 모델이 주어진 데이터의 패턴을 충분히 __하지 못한 상태를 의미한다. (학습)
- 해설: 언더피팅은 모델이 주어진 데이터의 패턴을 충분히 학습하지 못한 상태를 의미합니다.
- 인공 신경망은 매우 __한 함수로, 다양한 문제를 해결하는 데 사용될 수 있다. (유연)
- 해설: 인공 신경망은 매우 유연한 함수로, 다양한 문제 해결에 사용됩니다.
- 그라디언트 디센트는 손실 함수를 __하기 위해 파라미터를 업데이트하는 알고리즘이다. (최소화)
- 해설: 그라디언트 디센트는 손실 함수를 최소화하기 위해 파라미터를 업데이트하는 알고리즘입니다.
- 인공 신경망 학습에서 __는 각 파라미터가 손실 함수에 미치는 영향을 계산하는 데 사용된다. (편미분)
- 해설: 편미분은 각 파라미터가 손실 함수에 미치는 영향을 계산하는 데 사용됩니다.
- 인공 신경망 학습에서 __는 파라미터 업데이트 크기를 결정하는 상수이다. (러닝 레이트)
- 해설: 러닝 레이트는 파라미터 업데이트 크기를 결정하는 상수입니다.
- DQN은 __ 환경에서 강화학습을 수행하는 알고리즘이다. (비디오 게임)
- 해설: DQN은 비디오 게임 환경에서 강화학습을 수행하는 알고리즘입니다.
- DRQN은 인공 신경망을 사용하여 __ 데이터에 대한 강화학습을 수행하는 알고리즘이다. (순차적인)
- 해설: DRQN은 인공 신경망을 사용하여 순차적인 데이터에 대한 강화학습을 수행하는 알고리즘입니다.
서술형 문제 (10문제)
- 함수 근사 방법이 강화학습에서 중요한 이유를 설명하시오.
- 정답: 함수 근사 방법은 상태 공간이 매우 큰 경우, 모든 상태의 가치를 테이블에 저장하는 것이 비효율적이거나 불가능한 상황에서 사용됩니다. 함수 근사를 통해 일부 데이터만으로도 상태 가치를 예측할 수 있으며, 이를 통해 효율적인 학습과 일반화가 가능합니다.
- 해설: 함수 근사는 대규모 상태 공간을 효율적으로 처리하고, 일부 데이터로 전체를 추정할 수 있게 합니다.
- 오버피팅과 언더피팅의 차이를 설명하시오.
- 정답: 오버피팅은 모델이 훈련 데이터의 노이즈까지 학습하여 새로운 데이터에 대한 예측 성능이 떨어지는 현상이고, 언더피팅은 모델이 훈련 데이터의 패턴을 충분히 학습하지 못하여 예측 성능이 낮은 상태를 의미합니다.
- 해설: 오버피팅은 과적합 문제, 언더피팅은 부족 학습 문제입니다.
- 인공 신경망의 학습에서 그라디언트 디센트의 역할을 설명하시오.
- 정답: 그라디언트 디센트는 손실 함수를 최소화하기 위해 파라미터를 업데이트하는 알고리즘입니다. 이를 통해 모델이 주어진 데이터에 맞게 최적화됩니다.
- 해설: 그라디언트 디센트는 모델 최적화를 위한 핵심 알고리즘입니다.
- 인공 신경망 기반 강화학습의 장점을 설명하시오.
- 정답: 인공 신경망 기반 강화학습은 복잡한 상태와 행동 공간에서 높은 표현력을 가지며, 비선형 관계를 학습하여 더 나은 성능을 발휘할 수 있습니다.
- 해설: 인공 신경망은 복잡한 패턴을 학습하여 강화학습 성능을 향상시킵니다.
- DQN 알고리즘의 주요 특징을 설명하시오.
- 정답: DQN은 Q-러닝과 신경망을 결합하여 상태-행동 가치 함수를 근사합니다. 경험 재생 메모리와 고정된 타깃 네트워크를 사용하여 학습의 안정성을 높입니다.
- 해설: DQN은 Q-러닝과 신경망의 장점을 결합하여 강화학습 성능을 향상시킵니다.
- DRQN 알고리즘이 DQN과 다른 점을 설명하시오.
- 정답: DRQN은 순차적인 데이터를 처리하기 위해 RNN(Recurrent Neural Network)을 사용하여, 순차적인 상태 정보를 학습할 수 있습니다. 이는 비디오 게임이나 시간에 따른 상태 변화를 처리하는 데 유리합니다.
- 해설: DRQN은 순차적인 데이터 처리를 위해 RNN을 사용합니다.
- 오버피팅을 방지하기 위한 방법을 설명하시오.
- 정답: 오버피팅을 방지하기 위해서는 정규화 기법, 데이터 확장, 교차 검증, 조기 종료 등의 방법을 사용할 수 있습니다.
- 해설: 다양한 기법을 통해 오버피팅을 방지할 수 있습니다.
- 인공 신경망 학습에서 편미분이 중요한 이유를 설명하시오.
- 정답: 편미분은 각 파라미터가 손실 함수에 미치는 영향을 계산하여, 최적의 파라미터 값을 찾기 위한 경사하강법 등의 알고리즘에서 중요한 역할을 합니다.
- 해설: 편미분은 파라미터 최적화를 위한 중요한 계산입니다.
- 그라디언트 디센트의 러닝 레이트가 너무 크거나 작은 경우의 문제를 설명하시오
.
- 정답: 러닝 레이트가 너무 크면 학습이 불안정해지고, 너무 작으면 학습이 매우 느리게 진행됩니다. 적절한 러닝 레이트를 설정하는 것이 중요합니다.
- 해설: 러닝 레이트 설정은 학습의 안정성과 속도에 중요한 영향을 미칩니다.
- 인공 신경망 기반 강화학습의 한계를 설명하고, 이를 극복하기 위한 방법을 제안하시오.
- 정답: 인공 신경망 기반 강화학습은 많은 데이터와 계산 자원이 필요하며, 학습이 불안정할 수 있습니다. 이를 극복하기 위해 경험 재생, 타깃 네트워크, 적응형 학습률 등의 기법을 사용할 수 있습니다.
- 해설: 다양한 기법을 통해 인공 신경망 기반 강화학습의 한계를 극복할 수 있습니다.
단답형 문제 (10문제)
- 함수 근사란?
- 정답: 테이블 대신 함수를 사용하여 상태 가치를 저장하는 방법
- 해설: 함수 근사는 테이블 대신 함수를 사용하여 상태 가치를 저장하고 예측합니다.
- 다항 함수가 1차 함수보다 유리한 이유는?
- 정답: 더 복잡한 문제를 해결할 수 있는 유연성을 가짐
- 해설: 다항 함수는 더 복잡한 문제를 해결할 수 있습니다.
- 오버피팅이란?
- 정답: 모델이 훈련 데이터의 노이즈까지 학습하여 일반화 능력이 떨어지는 현상
- 해설: 오버피팅은 훈련 데이터의 노이즈까지 학습하는 문제입니다.
- 언더피팅이란?
- 정답: 모델이 주어진 데이터의 패턴을 충분히 학습하지 못한 상태
- 해설: 언더피팅은 데이터 패턴을 충분히 학습하지 못한 상태입니다.
- 인공 신경망의 본질은?
- 정답: 매우 유연한 함수
- 해설: 인공 신경망은 매우 유연한 함수입니다.
- 그라디언트 디센트의 목적은?
- 정답: 손실 함수를 최소화하기 위해 파라미터를 업데이트하는 것
- 해설: 그라디언트 디센트는 손실 함수를 최소화하기 위해 파라미터를 업데이트합니다.
- 인공 신경망 학습에서 편미분의 역할은?
- 정답: 각 파라미터가 손실 함수에 미치는 영향을 계산
- 해설: 편미분은 각 파라미터의 영향을 계산합니다.
- 러닝 레이트란?
- 정답: 파라미터 업데이트 크기를 결정하는 상수
- 해설: 러닝 레이트는 파라미터 업데이트 크기를 결정합니다.
- DQN의 주요 특징은?
- 정답: Q-러닝과 신경망을 결합하여 상태-행동 가치 함수를 근사
- 해설: DQN은 Q-러닝과 신경망을 결합합니다.
- DRQN의 주요 특징은?
- 정답: RNN을 사용하여 순차적인 상태 정보를 학습
- 해설: DRQN은 RNN을 사용하여 순차적인 상태 정보를 학습합니다.
'인공지능 > 강화학습' 카테고리의 다른 글
| 강화학습 9장 - 정책 기반 에이전트 (1) | 2024.06.08 |
|---|---|
| 강화학습 8강 - 가치 기반 에이전트 (1) | 2024.06.07 |
| Matlab 강화학습 - simulink 환경 만들기 및 에이전트 훈련시키기 (0) | 2024.05.10 |
| matlab 강화학습 onramp 8 - 에이전트 훈련시키기 (0) | 2024.05.09 |
| matlab 강화학습 onramp 7 - 액터와 크리틱 (0) | 2024.05.09 |