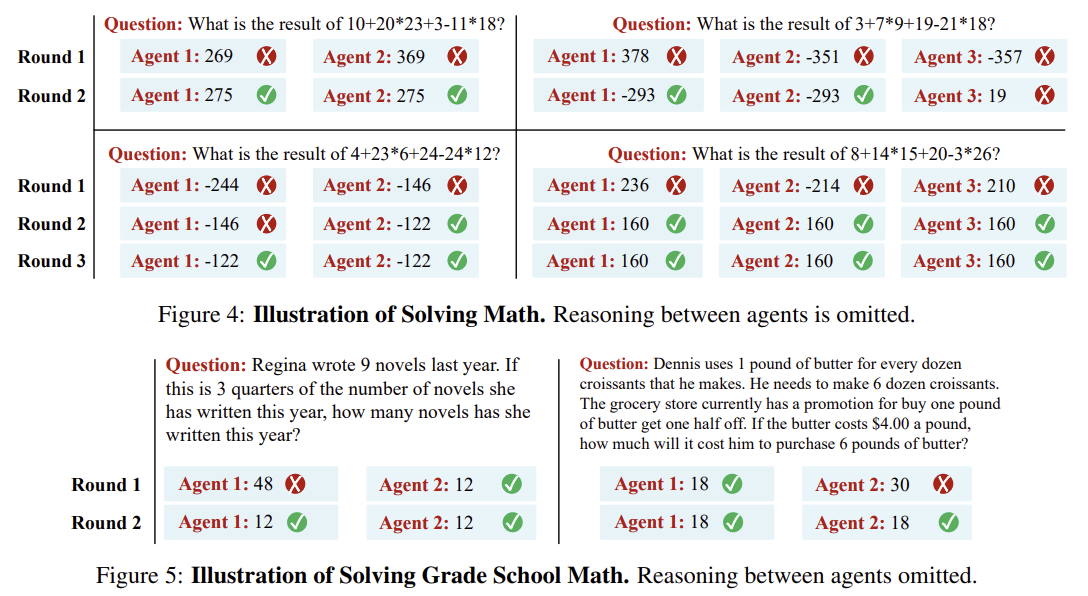
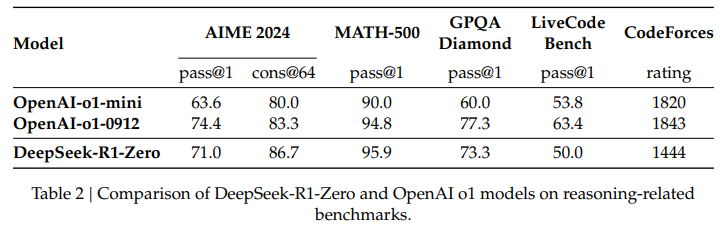
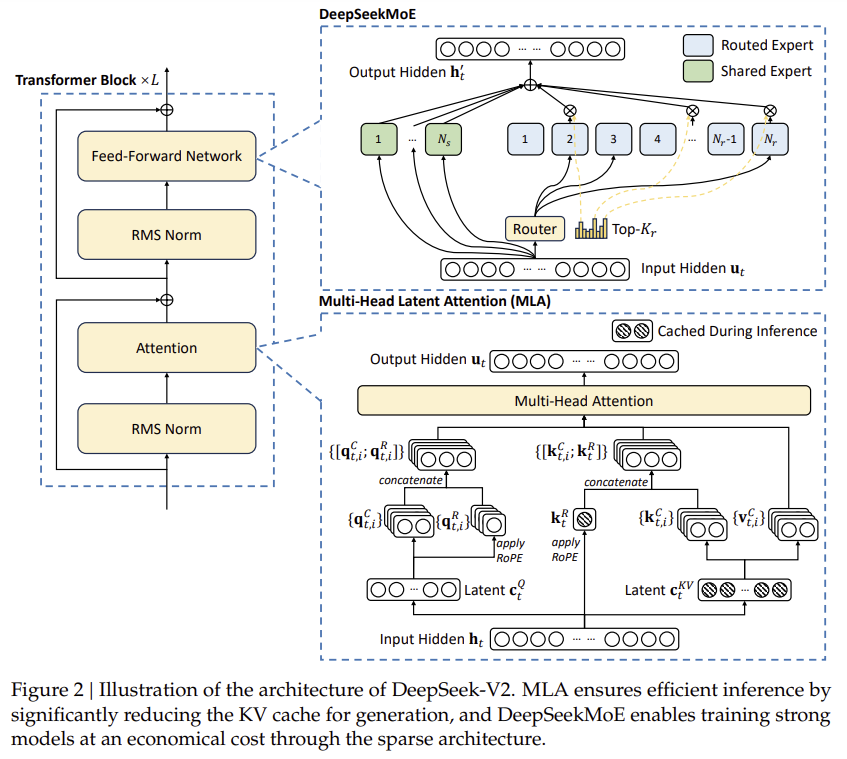
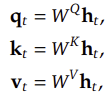https://arxiv.org/abs/2305.14325 Improving Factuality and Reasoning in Language Models through Multiagent DebateLarge language models (LLMs) have demonstrated remarkable capabilities in language generation, understanding, and few-shot learning in recent years. An extensive body of work has explored how their performance may be further improved through the tools of parxiv.org Agent 논문입니다! 그 중에서도 ..