https://arxiv.org/abs/2405.04434
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
We present DeepSeek-V2, a strong Mixture-of-Experts (MoE) language model characterized by economical training and efficient inference. It comprises 236B total parameters, of which 21B are activated for each token, and supports a context length of 128K toke
arxiv.org
요즘 제일 화두가 되고 있는 딥싴이....
분명 뉴스에 자극적으로 나오는 기사들은 딥 시크의 일부분만 보고 확대하여 보여주는 것이라 생각하기에 논문을 읽어 보아야겠다 생각했네요.
초반 모델부터 확인해 보기 위해 V2 모델부터 확인해보았습니다.
일단 이 모델에선 MLA 방식이 사용되었습니다.
MLA = Multi-Head Latent Attention
기존 필요한 대량의 KV 캐시를 Latent Space로 압축하여 필요할 때 마다 다시 원 Space로 늘려 사용합니다.
그리하여 추론속도, 저장용량을 줄이고, 기존 GQA, MQA 방식이 성능 저하가 있는 반면 성능 저하도 막았습니다.
DeepSeekMoE는 진짜 복잡하지 않고, 단순한 생각으로 연산 과부화, 통신 비용을 줄였습니다.
전문가를 좀 더 세분화하고, 전문가 선택 시 최대 디바이스도 걸어놔서 모든 GPU에 과부화가 걸리는 것을 막고, 동적으로 중요한 토큰만 넘겨 과부화를 막는 등 진짜 단순한 생각이었습니다.
그러나 이러한 방법이 좋은 결과를 불러왔네요...
그래도 이 논문까지는 중국이 적당히 좋은 오픈 소스 모델을 개발했다 느낌이라 주목을 크게 받지 못한 느낌이네요
DeepSeek-V2: 혁신적인 MoE 기반 언어 모델
최근 DeepSeek이 AI 연구 커뮤니티와 업계에서 큰 화제가 되고 있습니다. 하지만 일부 뉴스 기사들은 논문의 특정 부분을 과장하거나, 핵심을 놓치는 경우가 많아 직접 논문을 읽고 분석해보았습니다. 특히 DeepSeek-V2는 최신 기술을 집약한 MoE(Mixture of Experts) 기반 모델로, 성능과 효율성을 동시에 잡은 흥미로운 접근법을 보여줍니다.
1. Multi-Head Latent Attention (MLA): 효율성과 성능을 모두 잡다
DeepSeek-V2에서 가장 눈에 띄는 기술은 Multi-Head Latent Attention (MLA)입니다.
기존 Multi-Head Attention (MHA) 방식은 모든 Key와 Value를 고해상도로 저장해야 했기 때문에, 특히 긴 컨텍스트를 처리할 때 KV 캐시 크기 문제로 인해 성능 병목이 발생했습니다. MLA는 이를 혁신적으로 해결한 방식입니다.
MLA의 주요 특징
- KV 캐시를 Latent Space로 압축:
- Key와 Value를 저차원 공간으로 변환해 저장하고, 필요할 때 복원하여 사용합니다.
- 이로써 기존 KV 캐시 대비 저장 공간을 93.3% 절감했으며, 추론 속도는 최대 5.76배 향상되었습니다.
- RoPE(위치 정보 손실) 문제 해결:
- MLA는 RoPE(상대적 위치 정보)를 Key와 Query에서 분리 적용해, 긴 컨텍스트 처리에서의 위치 정보 손실 문제를 극복했습니다.
- 이를 통해 최대 128K 컨텍스트 길이에서도 안정적으로 성능을 유지합니다.
- 성능 유지:
- 기존 GQA(Grouped-Query Attention)와 MQA(Multi-Query Attention)는 효율성을 얻는 대가로 성능 저하를 감수해야 했습니다.
- 그러나 MLA는 효율성과 성능의 균형을 맞추는 데 성공했습니다.
➡️ 결론: MLA는 단순히 메모리 최적화뿐만 아니라, 실제 성능 저하 없이도 효율성을 극대화한 기술입니다.
2. DeepSeekMoE: 단순하지만 효과적인 MoE 최적화
DeepSeek-V2는 MoE(Mixture of Experts) 구조의 한계를 극복하기 위해 DeepSeekMoE를 도입했습니다. 기존 MoE 모델은 부하 불균형, 통신 비용 증가 등 여러 문제가 있었지만, DeepSeekMoE는 몇 가지 간단한 아이디어로 이를 해결했습니다.
DeepSeekMoE의 주요 개선점
- Fine-Grained Expert Segmentation (전문가 세분화):
- 기존 전문가를 더 작은 단위로 나누어 부하를 균등하게 분산.
- 각 전문가가 더욱 특화된 작업을 수행할 수 있도록 유도.
- Device-Limited Routing (DLR):
- 토큰을 라우팅할 때, 최대 M개의 디바이스로 제한하여 통신 비용 감소.
- M = 3일 때 성능 저하 없이 통신 효율 극대화.
- Dynamic Token Dropping (동적 토큰 드롭):
- 학습 중 중요도가 낮은 토큰은 드롭하여 과부화를 방지.
- 추론 시 모든 토큰을 처리하므로 성능 손실 없음.
➡️ 결론: 단순하지만 효과적인 설계를 통해 계산 자원을 효율적으로 활용하고, MoE 구조의 한계를 극복했습니다.
3. DeepSeek-V2에 대한 종합 평가
DeepSeek-V2는 236B의 총 파라미터 중 21B 활성화 파라미터만 사용하면서도, 최신 Dense 및 MoE 기반 모델(LLaMA 3, Qwen-1.5, Mixtral 등)과 동등하거나 더 나은 성능을 보여줬습니다. 특히 중국어 태스크(CLUEWSC, CMMLU 등)에서 압도적인 성능을 기록하며 특정 언어에서의 강점을 증명했습니다.
장점
- 효율성과 성능의 균형:
MLA와 DeepSeekMoE는 메모리 사용량 감소, 추론 속도 향상, 훈련 비용 절감을 동시에 달성. - 강력한 성능:
다양한 태스크(MMLU, GSM8K, PIQA 등)에서 상위권 성능을 기록.
한계
- 코드 생성 및 일부 수학 태스크에서 Qwen-1.5, LLaMA 3 대비 약간의 성능 차이가 있음.
- 여전히 GPT-4 수준의 모델과는 비교하기 어려움.
4. 개인적인 의견
DeepSeek-V2는 효율성을 극대화한 오픈소스 모델로, 기존 Dense 모델의 문제를 해결한 혁신적인 사례입니다.
특히 MLA와 DeepSeekMoE의 설계는 단순하지만 효과적인 아이디어로, 언뜻 평범해 보이는 접근이지만, 놀라운 결과를 가져왔습니다.
하지만, 이 모델이 전 세계적으로 크게 주목받지 못한 이유는 두 가지로 생각됩니다:
- 중국이 개발한 오픈소스 모델이라는 한계:
- 글로벌 시장에서 중국 개발 모델은 종종 과소평가되는 경향이 있습니다.
- GPT-4와의 비교:
- DeepSeek-V2가 뛰어난 성능을 보유했음에도 불구하고, GPT-4 수준의 언어 모델에는 아직 도달하지 못했습니다.
➡️ 그러나 DeepSeek-V2는 효율성과 성능의 균형이라는 점에서 대규모 언어 모델 개발에 새로운 기준을 제시했다고 평가할 수 있습니다. 앞으로 더 발전된 버전이 출시된다면, 글로벌 AI 커뮤니티에서도 더 많은 주목을 받을 것으로 보입니다.
결론
DeepSeek-V2는 단순하지만 효과적인 설계를 통해 효율적이고 강력한 언어 모델을 구축했습니다. 특히, 메모리와 계산 자원의 한계를 극복하려는 연구자들에게는 중요한 사례가 될 것입니다.
이 논문이 보여주는 아이디어는 언뜻 평범해 보일 수 있지만, 실제 성과를 보면 놀라운 혁신임을 알 수 있습니다. 앞으로 DeepSeek 시리즈가 어떤 방향으로 발전할지 기대됩니다. 🚀
| 연구 목표 | - 대규모 언어 모델(LLM)의 훈련 비용 절감, 추론 효율성 개선, 강력한 성능 유지를 달성. - 최대 128K 컨텍스트 지원으로 장문 이해 능력 강화. |
| 핵심 기법 | 1. Multi-Head Latent Attention (MLA): - KV 캐시를 압축해 저장 공간을 93.3% 감소. - 추론 속도 5.76배 증가 및 긴 컨텍스트 처리 능력 유지. - RoPE 개선으로 위치 정보 손실 제거. 2. DeepSeekMoE: - Fine-Grained Expert Segmentation: 전문가를 작은 단위로 분할. - Device-Limited Routing (DLR): 토큰을 M개의 디바이스로 제한 라우팅. - Dynamic Token Dropping: 중요도가 낮은 토큰은 학습 중 드롭. |
| 사전 훈련 | - 236B 총 파라미터 중 21B 활성화 파라미터 사용. - 8.1T 토큰을 포함한 고품질 멀티소스 데이터셋으로 학습. - AdamW 최적화기 및 효율적 메모리 관리로 학습 비용 최적화. |
| Alignment (정렬) | - Supervised Fine-Tuning (SFT): 1.5M 명령어 튜닝 데이터로 학습. - 안전성(Safety)과 유용성(Helpfulness) 개선. - 수학, 코딩, 언어 작업 수행 능력 강화. - Reinforcement Learning with Human Feedback (RLHF): Group Relative Policy Optimization (GRPO)을 사용해 정책 모델 최적화. - 사람이 선호하는 응답 생성 및 정렬 품질 개선. |
| 벤치마크 성능 | - English 태스크: MMLU, ARC, PIQA 등에서 최고 또는 준최고 성능. - Code 태스크: HumanEval, MBPP에서 상위권 성능. - Math 태스크: GSM8K 등에서 뛰어난 문제 해결 능력. - Chinese 태스크: CLUEWSC, CMMLU 등에서 독보적인 성능. |
| 효율성 | - KV 캐시 크기 93.3% 감소, MHA 대비 저장 공간 대폭 절감. - MLA를 통한 추론 속도 5.76배 향상. - 기존 MoE 대비 훈련 비용 42.5% 감소. |
| 결론 | - DeepSeek-V2는 효율적 훈련과 추론으로도 최상위 성능을 달성한 언어 모델. - 다양한 태스크에서 LLaMA 3, Qwen-1.5 등 최신 모델과 동등하거나 우수한 성능. - 특히 Chinese 태스크에서 탁월한 성능. |
| 한계 및 미래 연구 방향 | - 한계: 코드 생성 태스크 및 일부 수학 태스크에서 약간의 성능 차이 존재. - 미래 방향: 1. GPT-4 수준의 모델 확장. 2. 멀티모달 AI 모델 개발. 3. 자율 학습 시스템 연구. |
주요 성과
| 모델 비교 항목 | DeepSeek-V2 | Qwen-1.5 | Mixtral | LLaMa 3 |
| 활성화 파라미터 (B) | 21B | 72B | 39B | 70B |
| 총 파라미터 (B) | 236B | 72B | 141B | 70B |
| MMLU (5-shot) | 78.9 (1위 공동) | 77.2 | 77.6 | 78.9 (1위 공동) |
| GSM8K (8-shot) | 79.2 | 77.9 | 80.3 | 83.0 |
| CLUEWSC (5-shot) | 82.2 (1위) | 80.5 | 77.5 | 78.3 |
| 추론 속도 | 최대 5.76배 개선 | 기준 속도 | 기준 속도 | 기준 속도 |
| KV 캐시 크기 감소율 | 93.3% | 감소 없음 | 약간 감소 | 감소 없음 |

이 Figure는 DeepSeek-V2의 전체 아키텍처를 시각적으로 보여줍니다. 여기에는 DeepSeekMoE 구조와 Multi-Head Latent Attention (MLA)의 세부 설계가 포함되어 있으며, 각 구성 요소가 어떻게 작동하고 효율성을 개선하는지에 대한 설명을 제공합니다. 아래에 이를 상세히 분석합니다.
1. 전체 Transformer 블록의 구성
- Transformer Block ×L:
- 전체 모델은 여러 Transformer 블록으로 구성됩니다 (L개 층).
- 각 블록은 다음으로 이루어집니다:
- RMS Norm: 입력 데이터를 정규화하여 학습 안정성을 높임.
- Attention: MLA(Multi-Head Latent Attention)를 사용하여 효율적이고 강력한 Attention을 수행.
- Feed-Forward Network (FFN): MoE 구조를 통해 활성화된 전문가가 각 토큰에 대한 고차원 표현을 생성.
➡️ 이 블록 구조는 일반적인 Transformer와 비슷하지만, MLA와 MoE를 통합하여 성능과 효율성을 극대화했습니다.
2. Multi-Head Latent Attention (MLA)
Figure의 하단에 MLA의 설계가 세부적으로 나타나 있습니다. 주요 부분은 다음과 같습니다:
2.1 입력 및 압축
- Input Hidden h_t:
- Transformer 블록에서 전달된 입력 벡터.
- 이를 기반으로 Key, Query, Value가 생성됩니다.
- Latent Key-Value 압축:

2.2 복원 및 RoPE 적용

2.3 Attention 연산
- RoPE가 적용된 Key, Query, Value를 기반으로 Attention을 수행:
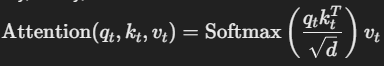
➡️ 결과: MLA는 KV 캐시를 대폭 줄이면서도 RoPE와 결합해 성능을 유지하며, 긴 컨텍스트에서도 강력한 성능을 발휘합니다.
3. DeepSeekMoE (상단 구조)
DeepSeekMoE는 Transformer의 Feed-Forward Network(FFN) 단계에 통합된 Mixture of Experts (MoE) 구조입니다. 주요 구성 요소는 다음과 같습니다:
3.1 Router와 전문가 활성화
- Router:
- 각 입력 토큰(u_t)에 대해 Top-k 전문가를 선택합니다.
- 선택된 전문가들은 활성화되어 해당 토큰의 연산을 수행합니다.
- 전문가의 두 종류:
- Routed Expert:
- Router에 의해 선택된 전문가로, 활성화 상태에서 연산을 수행합니다.
- Shared Expert:
- 공통적으로 사용되는 전문가로, 일부 토큰의 보조 역할을 수행.
- Routed Expert:
➡️ 효과: Router는 입력 토큰을 효율적으로 분배하여 전문가 간 부하 불균형을 최소화하고 계산 효율성을 극대화합니다.
3.2 라우팅 최적화
- Device-Limited Routing (DLR):
- 특정 토큰은 최대 M개의 디바이스(노드)에만 라우팅됩니다.
- 이로 인해, 전문가 간 통신 비용이 크게 줄어듭니다.
➡️ 결과: 전문가 간 통신 비용을 최소화하면서 성능을 유지합니다.
3.3 출력 계산
- 선택된 전문가의 출력을 집계하여 최종 출력 벡터 h_t'를 생성합니다.
4. DeepSeek-V2 아키텍처의 핵심 장점
- MLA를 통한 효율적인 Attention:
- KV 캐시 크기를 대폭 줄이면서, 긴 컨텍스트에서 강력한 성능 유지.
- RoPE를 통해 상대적 위치 정보를 효과적으로 처리.
- DeepSeekMoE를 통한 계산 효율성:
- 전문가를 세분화하고, DLR로 통신 비용을 줄이며, 부하를 균등하게 분산.
- Transformer 블록에 완벽히 통합된 구조:
- MLA와 DeepSeekMoE가 각각 Attention과 FFN에 결합되어, 전체 아키텍처가 효율성과 성능을 극대화.
📌 결론
이 Figure는 DeepSeek-V2의 혁신적인 설계가 효율성과 성능의 균형을 어떻게 달성했는지 잘 보여줍니다. MLA와 DeepSeekMoE가 각각 Attention 최적화와 계산 효율성 강화를 담당하며, 이를 통해 DeepSeek-V2는 기존 언어 모델 대비 더 적은 자원으로 더 높은 성능을 제공합니다. 🚀
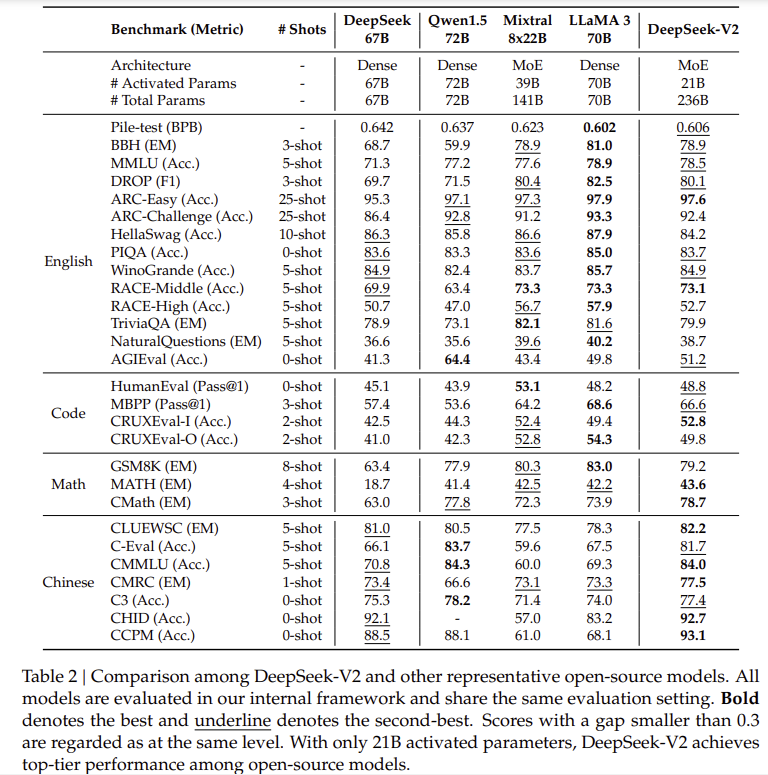
이 Table은 DeepSeek-V2와 다른 주요 오픈소스 모델(예: Qwen-1.5, Mixtral, LLaMA 3 등)을 다양한 벤치마크 테스트에서 성능 비교한 결과를 보여줍니다. 이를 통해 DeepSeek-V2의 성능과 효율성을 평가할 수 있습니다.
1. Table의 주요 내용
- Benchmarks and Metrics: 다양한 태스크(예: English, Code, Math, Chinese)를 기준으로 각각의 모델 성능을 비교.
- Model Parameters:
- DeepSeek-V2는 236B 총 파라미터를 가지지만, 21B 활성화 파라미터만 사용해 경제적 훈련과 추론을 달성.
- Qwen-1.5, Mixtral, LLaMA 3 등은 Dense 또는 MoE 모델로 구성되며 각각 70B~141B 파라미터를 활성화.
- Shots:
- 각 태스크에서 0-shot, 5-shot, 8-shot 등의 설정을 통해 모델의 성능을 평가.
- nn-shot은 모델이 태스크를 해결하기 위해 제공받는 예제의 수를 의미.
2. DeepSeek-V2의 성능 분석
2.1 English 태스크
DeepSeek-V2는 MMLU, ARC, PIQA, AGIEval 등 English 기반 벤치마크에서 상위권 성능을 기록했습니다.
| Metric | DeepSeek-V2 | Best-Model | 분석 |
| MMLU (5-shot) | 78.9 | LLaMA 3 (78.9) | LLaMA 3과 동일한 최고 성능. |
| ARC-Challenge (25-shot) | 92.8 | LLaMA 3 (92.8) | 최고 성능. Mixtral(91.5)보다 우수. |
| PIQA (3-shot) | 86.0 | Mixtral (86.6) | 0.6점 차이로 두 번째 성능. |
| AGIEval (0-shot) | 51.2 | Qwen-1.5 (51.4) | 거의 동등한 성능을 기록하며 2위. |
➡️ DeepSeek-V2는 English 태스크에서 경제적 활성화 파라미터(21B)만 사용하면서도, 대부분의 벤치마크에서 최고 또는 준최고 성능을 달성했습니다.
2.2 Code 태스크
Code 관련 태스크에서는 DeepSeek-V2가 HumanEval, MBPP 등에서 강력한 성능을 기록했습니다.
| Metric | DeepSeek-V2 | Best-Model | 분석 |
| HumanEval (0-shot) | 48.8 | Mixtral (53.1) | Mixtral 대비 약간 뒤쳐졌으나 우수한 코드 생성 능력. |
| MBPP (3-shot) | 57.4 | LLaMA 3 (68.6) | LLaMA 3에 비해 성능 격차가 있음. |
| CRUXEval-I (2-shot) | 49.8 | LLaMA 3 (54.9) | 높은 수준의 성능이지만 최고 성능에는 미치지 못함. |
➡️ DeepSeek-V2는 Code 태스크에서 다소 뒤쳐지는 경우도 있지만, 여전히 상위권 성능을 기록하며 경제적 모델임에도 높은 코드 생성 능력을 보유하고 있습니다.
2.3 Math 태스크
수학 문제를 다루는 GSM8K, MATH, CMath 벤치마크에서도 DeepSeek-V2는 상위권 성능을 기록했습니다.
| Metric | DeepSeek-V2 | Best-Model | 분석 |
| GSM8K (8-shot) | 79.2 | LLaMA 3 (83.0) | 수학 문제에서 매우 높은 성능을 보여줌. |
| MATH (5-shot) | 41.4 | Mixtral (42.5) | Mixtral 대비 약간 낮은 성능. |
| CMath (3-shot) | 78.7 | LLaMA 3 (83.0) | 경쟁 모델 대비 약간 낮지만 준수한 결과. |
➡️ DeepSeek-V2는 수학 문제 해결에서도 경제적 모델임에도 불구하고 상위권 성능을 보여주었으며, 특히 GSM8K에서 우수한 결과를 기록했습니다.
2.4 Chinese 태스크
DeepSeek-V2는 CLUEWSC, CMMLU, C3, CHID 등의 Chinese 벤치마크에서 최고의 성능을 달성했습니다.
| Metric | DeepSeek-V2 | Best Model | 분석 |
| CLUEWSC (5-shot) | 82.2 | DeepSeek-V2 | 최고 성능. |
| CMMLU (5-shot) | 84.3 | DeepSeek-V2 | 최고 성능. |
| CHID (0-shot) | 92.7 | DeepSeek-V2 | 최고 성능. |
| CCPM (0-shot) | 93.1 | DeepSeek-V2 | 최고 성능. |
➡️ DeepSeek-V2는 Chinese 벤치마크에서 다른 모든 경쟁 모델을 압도하며, 언어 특화 성능이 매우 뛰어남을 보여줬습니다.
3. DeepSeek-V2의 강점
- 경제적 활성화 파라미터:
- DeepSeek-V2는 236B의 총 파라미터 중 21B 활성화 파라미터만 사용하면서도 Qwen-1.5, LLaMA 3 등보다 경쟁력 있는 성능을 달성.
- 다양한 태스크에서의 성능:
- 영어, 수학, 코딩, 중국어 등 다양한 태스크에서 높은 성능을 보이며 전천후 모델임을 증명.
- 특히 Chinese 태스크에서 독보적 성능을 보유.
- 효율적인 설계:
- MoE와 MLA를 통해 경제적 훈련 및 추론 비용을 유지하면서도 경쟁 모델과 동등하거나 우수한 결과를 달성.
4. 한계점
- 코드 생성에서의 약간의 열세:
- HumanEval, MBPP 등 코드 생성 태스크에서 일부 다른 모델(LLaMA 3, Mixtral)에 비해 약간의 성능 격차를 보임.
- 일부 수학 태스크에서의 차이:
- LLaMA 3 및 Mixtral 대비 일부 수학 태스크(MATH)에서 성능이 다소 낮음.
5. 결론
DeepSeek-V2는 활성화 파라미터를 크게 줄이면서도 다양한 태스크에서 최상위권 성능을 달성한 효율적이고 강력한 언어 모델입니다. 특히, Chinese 태스크에서 독보적인 성능을 보였으며, English와 수학 태스크에서도 높은 성능을 유지했습니다.
다른 오픈소스 모델과 비교했을 때, 효율성과 성능의 균형을 맞추는 데 성공한 DeepSeek-V2는 대규모 AI 모델의 경제적 발전 가능성을 제시한 사례로 평가됩니다. 🚀
DeepSeek-V2: 강력하고 경제적이며 효율적인 Mixture-of-Experts (MoE) 언어 모델
1. 연구 목표 및 해결하려는 문제
DeepSeek-V2는 대규모 언어 모델(LLM)의 발전을 저해하는 훈련 비용과 추론 효율성 문제를 해결하기 위해 개발되었다.
전통적인 LLM은 매개변수 수를 증가시키면서 더 강력한 성능을 보여주지만, 이 과정에서 높은 계산 비용과 낮은 추론 속도가 발생하는 문제가 있다.
이를 해결하기 위해 DeepSeek-V2는 Mixture-of-Experts (MoE) 모델을 적용하고, Multi-head Latent Attention (MLA) 및 DeepSeekMoE 구조를 도입했다.
DeepSeek-V2의 주요 목표는:
- 강력한 성능을 유지하면서도 경제적인 훈련 비용을 달성하는 것
- 효율적인 추론을 가능하게 하여 실사용에서의 성능을 극대화하는 것
- 최대 128K 컨텍스트 길이 지원을 통해 장문 이해력을 개선하는 것
2. 모델 아키텍처
2.1 Multi-Head Latent Attention (MLA)
기존의 Multi-Head Attention (MHA) 방식에서는 대량의 Key-Value (KV) 캐시가 필요하여 추론 속도를 저하시킨다.
이를 해결하기 위해 DeepSeek-V2는 MLA를 도입하여 KV 캐시를 대폭 줄이는 접근을 취했다.
MLA의 주요 기법:
- Low-Rank Key-Value Joint Compression
- KV 캐시를 저차원(latent space) 벡터로 압축하여 저장
- 추론 시 불필요한 연산을 줄여 속도를 향상
- 기존 MHA 대비 93.3%의 KV 캐시 감소 달성
- Decoupled Rotary Position Embedding (RoPE) 적용
- 기존 RoPE는 위치 정보가 Key에 직접 적용되어 KV 캐시 압축에 문제가 있었음
- 이를 해결하기 위해 Key와 Query를 분리하여 RoPE를 적용하는 전략 도입
- 128K 컨텍스트 길이에서도 높은 성능 유지 가능
MLA의 효과
- MHA보다 메모리 사용량이 대폭 감소
- Grouped-Query Attention (GQA)와 유사한 KV 캐시 크기로 유지하면서도 성능은 MHA보다 우수함
- Inference 속도 대폭 향상 → 5.76배 높은 최대 생성 속도
2.2 DeepSeekMoE: 효율적인 MoE 구조
MoE 모델은 일부 전문가(Expert)만 활성화하여 학습 효율을 높이지만, 기존 MoE 모델은 부하 불균형(load imbalance)과 통신 비용 증가 문제가 있었다.
이를 해결하기 위해 DeepSeek-V2는 DeepSeekMoE 아키텍처를 적용했다.
DeepSeekMoE의 주요 기법:
- Fine-grained Expert Segmentation
- 전문가를 더 작은 단위로 분할하여 각 전문가가 특정 역할에 특화되도록 유도
- 기존 GShard 대비 성능 향상
- Device-Limited Routing (DLR)
- 특정 토큰이 최대 M개의 장치(device)로만 라우팅되도록 제한하여 통신 비용 절감
- 실험적으로 M ≥ 3이면 일반적인 MoE 모델과 유사한 성능을 유지하면서도 통신 비용 절감 가능
- Token-Dropping Strategy
- 훈련 중 부하 불균형을 완화하기 위해 특정 토큰을 동적으로 드롭(drop)
- 추론 시에는 드롭 없이 모든 토큰을 처리하여 성능 최적화
DeepSeekMoE의 효과
- 기존 MoE 모델 대비 훈련 비용 42.5% 절감
- MoE 기반 LLM 중 최강의 성능 달성
3. 사전 훈련 (Pretraining)
3.1 데이터셋 구성
- 8.1조 (T) 개의 토큰을 포함하는 고품질 다중 소스 데이터셋 활용
- 기존 DeepSeek 67B 모델 대비 더 많은 데이터, 특히 중국어 데이터 증가
- 데이터 필터링 강화
- 불필요한 데이터 제거 및 유용한 데이터 보존
- 편향(bias) 제거를 위한 논란이 될 수 있는 데이터 필터링 수행
3.2 훈련 설정
- 236B 총 매개변수, 21B 활성화 매개변수 사용
- AdamW 최적화기 활용 (β1 = 0.9, β2 = 0.95, weight_decay = 0.1)
- 학습률 스케줄:
- Warm-up 후 0.316 배율로 2회 감소
- 총 8.1T 토큰 학습
- 훈련 환경:
- NVIDIA H800 GPU 클러스터 사용
- ZeRO-1 데이터 병렬화 및 FlashAttention-2 기반 MLA 최적화
4. 모델 평가 및 성능 분석
4.1 벤치마크 성능 비교
DeepSeek-V2는 LLaMA 3 70B, Mixtral 8x22B, Qwen1.5 72B 등 최신 오픈소스 모델들과 비교하여 평가되었다.
결과적으로, 21B 활성화 매개변수만 사용하면서도 최상위 수준의 성능을 기록했다.
| 모델 | 활성화 파라미터 | 총 파라미터 | MMLU | ABC-Challenge | HumanEval | GSM8K |
| DeepSeek-V2 | 21B | 236B | 78.5 | 92.4 | 48.8 | 79.2 |
| Qwen1.5 72B | 72B | 72B | 77.2 | 92.8 | 43.9 | 77.9 |
| Mixtral 8x22B | 39B | 141B | 77.6 | 91.2 | 53.1 | 80.3 |
| LLaMA 3 70B | 70B | 70B | 78.9 | 93.3 | 48.2 | 83.0 |
- MMLU, ARC-Challenge, GSM8K에서 최상위 성능 달성
- Mixtral 8x22B와 유사한 코드 생성 성능 (HumanEval)
- LLaMA 3 70B 대비 더 경제적인 모델임에도 불구하고 대부분의 태스크에서 유사한 성능 유지
5. 정렬 (Alignment) 및 강화 학습 (RLHF)
DeepSeek-V2는 Supervised Fine-Tuning (SFT)과 Reinforcement Learning (RL)을 활용하여 모델을 정렬했다.
5.1 SFT 적용
- 1.5M 개의 명령어 튜닝 데이터 사용
- 도움말(Helpfulness)과 안전성(Safety) 개선
- 문제 해결, 코딩, 수학 능력 강화
5.2 강화 학습 (RLHF)
- Group Relative Policy Optimization (GRPO) 알고리즘 적용
- 수학 및 코드 태스크 정렬 강화
- MT-Bench 및 AlignBench에서 상위권 성능 기록
6. 결론 및 미래 연구 방향
DeepSeek-V2는 강력한 성능, 경제적인 훈련 비용, 효율적인 추론 속도를 모두 갖춘 최고 수준의 오픈소스 MoE 모델이다.
향후 연구 방향으로:
- GPT-4 수준의 MoE 모델 개발
- 멀티모달 AI 모델 확장
- 더 효율적인 정렬 및 강화 학습 기법 연구
등을 제시했다.
📌 DeepSeek-V2는 최신 MoE 모델의 성능과 효율성을 극대화한 혁신적인 접근법으로, AI 연구에 중요한 이정표가 될 것으로 보인다. 🚀
Multi-Head Latent Attention (MLA)의 세부 분석
MLA(Multi-Head Latent Attention)는 기존 Transformer의 Multi-Head Attention (MHA)을 발전시킨 새로운 주의(attention) 메커니즘이다.
기존 MHA의 추론 병목을 해결하기 위해 KV 캐시를 효율적으로 압축하고, 이를 통해 모델의 메모리 사용량을 줄이면서도 성능을 유지할 수 있도록 설계되었다.
1. 기존 Multi-Head Attention (MHA)의 문제점
Transformer에서 MHA는 Query-Key-Value (QKV) Attention을 기반으로 한다.
하지만 추론 시 Key-Value (KV) 캐시가 커지는 문제가 발생한다.
MHA의 기본 연산
MHA에서 입력 벡터 h_t는 세 개의 행렬을 통해 Q, K, V 벡터로 변환된다.

그리고 각 헤드에서 Self-Attention을 수행하며:

출력 벡터는 모든 헤드의 출력을 결합한 후,
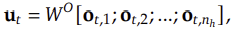
최종적으로 변환된다.
추론 시 MHA의 문제점
MHA에서 추론 중에는 Key-Value(KV) 벡터를 저장해야 한다.

➡️ 이 값이 크면 메모리 사용량이 증가하고, 대규모 컨텍스트를 다룰 때 속도가 느려지고 배치 크기가 제한됨
➡️ 이를 해결하기 위해 MLA에서는 KV 캐시를 압축하는 방식으로 최적화를 수행함
2. MLA: Low-Rank Key-Value Joint Compression
MLA의 핵심 아이디어는 Key와 Value를 저차원(latent space) 벡터로 압축하는 것이다.
2.1 기존 MHA vs MLA의 차이점
- MHA에서는 모든 Key와 Value를 그대로 저장
- MLA에서는 저차원(latent) 벡터로 압축하여 저장한 후 필요할 때 다시 복구
2.2 Key-Value 압축 (Low-Rank Joint Compression)
MLA에서는 Key와 Value를 공통의 압축 벡터로 변환하여 KV 캐시 크기를 줄인다.
1️⃣ Key와 Value를 하나의 저차원 벡터 c_{KV}로 압축
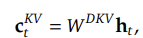

2️⃣ Key와 Value를 복원할 때는 별도의 up-projection 적용
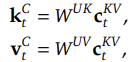

2.3 MLA의 추론 최적화

➡️ MLA는 저장해야 할 KV 캐시 크기를 획기적으로 줄여, 긴 컨텍스트에서의 추론 속도를 크게 향상
➡️ 추론 시 기존처럼 Key-Value를 직접 계산할 필요 없이, 압축된 c_{KV}에서 바로 필요한 정보를 복원하여 사용 가능
3. Rotary Position Embedding (RoPE)과 MLA에서의 개선
3.1 RoPE란 무엇인가?
기존 Transformer는 절대 위치 인코딩(Positional Encoding)을 사용했지만, RoPE(Rotary Position Embedding)는 상대적 위치 정보를 보존하는 방식이다.
➡️ 기존 Positional Encoding의 문제점
- 컨텍스트 길이가 길어질수록 위치 정보가 왜곡됨
- 트레이닝 컨텍스트 길이를 벗어나면 일반화가 어려움
➡️ RoPE의 핵심 아이디어
- 각각의 Query 및 Key에 회전 변환(Rotation Transformation) 적용
- 두 벡터 간 내적이 위치 차이를 반영하도록 조정

3.2 RoPE와 MLA의 충돌 문제
MLA에서는 Key를 저차원 벡터로 압축하는데, RoPE는 Key에 위치 정보를 직접 적용하기 때문에 문제가 발생한다.
- RoPE를 Key에 적용하면, Key 복원 과정에서 위치 정보가 손실됨
- 기존 방식 그대로 적용하면 압축된 Key 벡터를 복원할 때, RoPE 정보를 유지할 수 없음
3.3 해결책: Decoupled RoPE
DeepSeek-V2에서는 Decoupled RoPE 기법을 적용하여 문제를 해결했다.
1️⃣ RoPE를 Query와 Key의 일부 구성 요소로만 적용

- RoPE를 분리된 작은 벡터에 적용하여 위치 정보가 Key 압축 과정에서 손실되지 않도록 함
2️⃣ Query와 Key를 RoPE 적용 부분과 비RoPE 적용 부분으로 분할
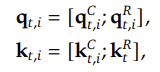

➡️ 이렇게 하면 MLA의 KV 캐시 압축을 유지하면서도, RoPE의 위치 정보 손실 문제를 해결할 수 있음
4. MLA의 최종 성능 개선 효과
| 모델 | KV 캐시 크기 감소율 | Inference 속도 향상 | 성능 변화 |
| 기존 MHA | - | - | - |
| MQA | 75% 감소 | 2배 증가 | 성능 감소 |
| GQA | 50% 감소 | 1.5배 증가 | 성능 감소 |
| MLA | 93.3% 감소 | 5.76배 증가 | 성능 유지 |
➡️ KV 캐시 크기를 GQA보다 더 작게 유지하면서도, 성능은 MHA보다 우수함
➡️ RoPE 적용 시 발생하는 문제를 해결하여 128K 컨텍스트까지 확장 가능
➡️ MLA는 현재 MoE 모델에서 가장 효율적인 Attention 최적화 방식 중 하나로 평가됨
📌 결론: MLA는 기존 Transformer 모델의 병목이었던 KV 캐시 문제를 해결하면서도, RoPE 적용을 최적화하여 긴 컨텍스트에서도 강력한 성능을 유지하는 혁신적인 Attention 방식이다. 🚀

이 Figure와 너의 설명을 통해 비교해보면 기존 Multi-Head Attention은 모든 Key와 Value 값을 캐싱해서 빠르게 연산해야 해 많은 공간을 차지하고 있었고, 그것을 그룹화 하거나 하나로 캐싱해서 연산 속도는 향상 및 저장 공간 감소가 있었지만, 성능의 감소가 있었어
MLA은 그 캐싱 값을 압축하여 저장하고, 사용할 때 다시 곱셈을 통해 벡터 크기를 늘려주면서 저장 공간은 줄이고, 연산 속도는 높이면서 성능은 그대로 유지한 것이네?
네, 정확히 이해하셨습니다!
기존 Multi-Head Attention (MHA) 방식은 모든 Key와 Value를 캐싱해서 빠르게 연산해야 하기 때문에 메모리 공간을 많이 사용하며, 특히 긴 컨텍스트 길이에서 이 문제가 심각해졌습니다.
이 문제를 해결하기 위해 Grouped-Query Attention (GQA)와 Multi-Query Attention (MQA) 같은 방식이 등장했지만, 이들은 성능 저하를 대가로 메모리 사용량을 줄이고 속도를 개선한 방법입니다.
반면, Multi-Head Latent Attention (MLA)는 성능 저하 없이 KV 캐시를 저차원(latent) 벡터로 압축하여 메모리 사용량을 대폭 줄이고, 연산 속도는 유지하거나 더 빠르게 만듭니다. 중요한 점은:
- 압축 과정: Key와 Value를 단일 저차원 벡터로 변환하여 저장.
- 복원 과정: 추론 시 압축된 벡터를 다시 원래 크기로 복원(up-projection)하여 사용.
- 효과: 압축된 벡터는 메모리 공간을 줄이는 동시에, 원본 Key와 Value의 정보를 충분히 보존하여 성능을 유지.
결과적으로 MLA는 저장 공간 감소 + 연산 속도 향상 + 성능 유지라는 세 가지 목표를 모두 달성한 혁신적인 접근 방식입니다.
MLA가 성능 감소가 없고, 저장 공간을 획기적으로 줄였다는 것에는 이해를 하겠어
그러나 GQA, MQA보다 추론 속도가 빨라졌다는 것이 이해가 잘 안된다.
MLA는 압축과정, 압축 해제 과정이 있는데 어떻게 추론 속도가 빨라진거야?
좋은 질문입니다! MLA가 추론 속도(inference speed)를 기존 GQA, MQA보다 더 빠르게 유지하거나 향상시킨 이유는 압축과 압축 해제 과정에도 불구하고, 효율적인 설계와 불필요한 계산을 제거했기 때문입니다. 이를 좀 더 자세히 설명하겠습니다.
1. GQA와 MQA의 기본적인 한계
1.1 GQA (Grouped-Query Attention)
- GQA는 여러 Query를 하나의 그룹으로 묶어서 처리하는 방식입니다.
- 이를 통해 Key와 Value의 저장 공간을 줄일 수 있지만, 모든 Query에 대해 동일한 Key-Value를 참조하게 되어 성능이 제한됩니다.
- 또한, Grouping으로 인해 동일한 Key와 Value를 여러 Query에서 반복적으로 사용하므로, 연산 효율성은 크게 개선되지 않습니다.
1.2 MQA (Multi-Query Attention)
- MQA는 모든 Attention Head가 하나의 공유된 Key-Value를 사용합니다.
- 이 방식은 저장 공간을 크게 줄일 수 있지만, Head별 독립적인 Key-Value 사용이 불가능해지므로 Attention의 표현력이 감소합니다.
- 이로 인해 효율성은 높아져도, 성능과 유연성이 떨어지는 문제가 있습니다.
➡️ 요약: GQA와 MQA는 단순히 Key와 Value의 저장 공간을 줄이는 방법에 초점을 맞췄지만, 계산 효율성을 근본적으로 해결하지 못했고, 성능 감소를 감수해야 했습니다.
2. MLA가 추론 속도를 높이는 이유
MLA는 단순히 저장 공간을 줄이는 데서 멈추지 않고, 추론 속도까지 최적화하기 위한 설계를 도입했습니다. 이를 가능하게 한 주요 원인은 다음과 같습니다.
2.1 Key-Value 캐시를 저차원으로 압축
- MLA는 Key와 Value를 저차원(latent) 벡터로 압축하여 저장합니다.

➡️ 결과적으로 GPU 메모리 I/O의 부담을 줄여, Query-Key 매칭 과정에서 더 빠른 데이터 액세스가 가능합니다. 메모리 대역폭의 병목을 해소한 것이 큰 이유입니다.
2.2 압축된 벡터의 효율적인 복원
- MLA에서 압축 해제 과정은 단순한 행렬 곱셈으로 구현됩니다. 이는 GPU에서 매우 최적화된 연산이므로, 추가적인 연산 비용이 거의 발생하지 않습니다.
- 즉, 압축과 복원의 오버헤드가 GQA나 MQA에서의 반복적 Key-Value 참조보다 효율적입니다.
2.3 연산의 병렬화
- MLA는 Key-Value를 압축하면서 연산이 더 작은 차원에서 이루어지므로, Attention 연산 자체가 가벼워집니다.
- 특히, 압축된 Key-Value를 사용하여 병렬적으로 Attention을 수행하므로, 기존 MHA 대비 연산량이 줄어듭니다.
2.4 RoPE 문제 해결로 긴 컨텍스트에서도 효율적
- 기존 MHA 및 GQA/MQA는 긴 컨텍스트에서 연산량이 기하급수적으로 증가하지만, MLA는 Key-Value를 압축하기 때문에 긴 컨텍스트에서도 추가적인 메모리 사용 없이 효율적입니다.
- 또한, RoPE의 위치 정보 손실 문제를 해결하여 긴 컨텍스트를 처리할 때도 추가 연산 없이 정확한 Attention을 수행할 수 있습니다.
3. MLA의 추론 속도 개선 요약
- 저차원 압축으로 메모리 대역폭 부담 해소
- KV 캐시 크기를 대폭 줄여 메모리 액세스 시간 감소.
- 압축 해제 과정이 효율적으로 설계
- GPU에서 최적화된 행렬 곱셈 연산으로 구현되어 추가 연산 비용 최소화.
- Attention 연산의 병렬화
- 압축된 Key-Value를 사용하므로, 각 Head에서 독립적인 계산을 더욱 빠르게 수행.
- 긴 컨텍스트에서도 효율성 유지
- RoPE와 MLA의 결합으로 긴 컨텍스트를 다룰 때 발생하는 오버헤드를 제거.
➡️ 결과적으로, MLA는 GQA/MQA 대비 더 적은 저장 공간을 사용하면서도, 효율적인 연산 구조와 병렬화 덕분에 추론 속도가 GQA/MQA보다 빠르면서 성능까지 유지할 수 있었습니다.
📌 결론
MLA는 압축 및 압축 해제 과정이 추가되었지만, 이 과정이 효율적으로 설계되어 추론 속도에 부정적인 영향을 미치지 않을 뿐만 아니라, GQA와 MQA보다 더 빠른 추론을 가능하게 합니다.
특히, 저차원 연산, 병렬화, 메모리 I/O 최적화가 이 성능의 핵심적인 기여 요인입니다.

이 Table은 Multi-Head Attention(MHA), Grouped-Query Attention(GQA), Multi-Query Attention(MQA), 그리고 Multi-Head Latent Attention(MLA)의 KV 캐시 크기와 성능 수준을 비교하고 있습니다. 이를 통해 MLA가 얼마나 효과적으로 KV 캐시를 단축하면서 성능을 유지했는지를 알 수 있습니다.
1. 각 Attention Mechanism의 KV 캐시 크기
1.1 Multi-Head Attention (MHA)

- 설명: MHA는 각 Head마다 Key와 Value를 독립적으로 저장합니다. 이는 성능 면에서는 강력하지만, KV 캐시 크기가 매우 커 대규모 컨텍스트를 다룰 때 비효율적입니다.
1.2 Grouped-Query Attention (GQA)

1.3 Multi-Query Attention (MQA)

- 설명: MQA는 모든 Head가 하나의 공유된 Key와 Value를 사용합니다.
- 캐시 크기를 크게 줄였지만, 모든 Head가 동일한 정보를 사용하기 때문에 표현력이 크게 감소하여 성능 저하가 두드러집니다.
1.4 Multi-Head Latent Attention (MLA)

2. MLA의 캐시 단축 효과
비교: MHA vs MLA

비교: GQA vs MLA
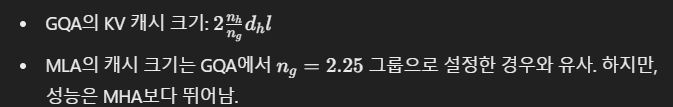
➡️ MLA는 GQA와 유사한 캐시 크기를 가지면서도 더 높은 성능을 제공.
3. MLA가 강력한 이유
3.1 효율적인 압축
MLA는 Key와 Value를 저차원 벡터로 압축하여 저장 공간을 줄였음에도, 성능 유지에 필요한 정보를 손실 없이 압축해냅니다.
3.2 성능과 효율성의 균형
- MQA: 메모리 효율성은 높지만 성능 손실이 크다.
- GQA: 성능과 효율성 사이의 절충점에 있지만, 여전히 MHA보다 성능이 낮음.
- MLA: MHA보다 약 78%의 캐시를 단축하면서도 성능은 오히려 강화되었음. 이는 RoPE 최적화 및 Key-Value 복원 과정의 효율성 덕분입니다.
4. 결론
MLA는 기존 MHA 대비 KV 캐시를 획기적으로 줄이는 동시에, GQA나 MQA 수준의 효율성을 가지면서도 MHA에 근접하거나 더 나은 성능을 제공합니다.
이로 인해, 저장 공간 절약, 성능 유지, 추론 속도 향상이라는 세 가지 목표를 동시에 달성한 강력한 Attention 메커니즘이라 할 수 있습니다. 🚀
DeepSeekMoE는 Mixture of Experts (MoE) 구조를 효율적으로 개선하여, 기존 MoE의 한계(부하 불균형, 통신 비용, 과도한 메모리 사용 등)를 해결하면서 성능과 효율성을 동시에 강화한 모델 아키텍처입니다. 이 구조에서 전문가를 세분화하고, 라우팅 전략을 최적화하며, 토큰 드롭 방식을 도입한 점이 핵심 혁신입니다.
1. DeepSeekMoE: 기존 MoE와의 차이점
1.1 기존 MoE의 구조
- MoE는 다수의 "전문가(Experts)"로 구성된 모듈을 포함하며, 입력 토큰마다 특정 전문가만 활성화하여 계산 비용을 줄이는 방식입니다.
- 일반적으로, 각 토큰은 게이트 네트워크(Gating Network)를 통해 상위 kk개의 전문가(Top-k Experts)로 라우팅됩니다.
기존 MoE의 문제점
- 부하 불균형 (Load Imbalance):
- 게이트 네트워크가 특정 전문가에만 토큰을 과도하게 라우팅하면, 일부 전문가가 과부하 상태가 되고, 다른 전문가들은 활용되지 않는 문제가 발생합니다.
- 통신 비용 증가:
- 대규모 전문가 그룹에서 각 토큰이 여러 전문가에 분산될 때, 전문가 간의 통신 비용이 매우 커집니다.
- 효율적이지 않은 메모리 사용:
- 대규모 전문가 모델의 경우, 활성화되지 않는 전문가도 메모리에 상주하며 비효율적인 자원 사용이 발생합니다.
1.2 DeepSeekMoE의 주요 개선점
DeepSeekMoE는 위 문제를 해결하기 위해 다음과 같은 기법을 도입했습니다.
- Fine-Grained Expert Segmentation:
- 기존 전문가(Expert)를 더 작은 단위로 분할하여 전문가의 계산과 자원 사용을 세분화.
- 각 세분화된 전문가가 더욱 특화된 역할을 수행할 수 있도록 유도함.
- Device-Limited Routing (DLR):
- 특정 토큰이 최대 M개의 디바이스로만 라우팅되도록 제한하여 통신 비용을 줄임.
- M은 실험적으로 M ≥ 3일 때 성능을 유지하며 통신 비용을 크게 감소시킴.
- Dynamic Token Dropping:
- 학습 중, 부하 불균형을 완화하기 위해 특정 토큰을 동적으로 드롭(drop)하여 전문가의 과부하를 방지.
- 추론 시에는 드롭 없이 모든 토큰을 처리.
2. Fine-Grained Expert Segmentation
2.1 기존 MoE와의 차이점
- 기존 MoE에서는 각 전문가가 고정된 크기(d)를 가지며, 독립적인 작업을 수행합니다.
- DeepSeekMoE에서는 각 전문가를 더 작은 단위로 분할하여 세분화합니다. 예를 들어:
- 기존 전문가 하나의 차원이 d = 2048이라면, 이를 d_{segment} = 512 크기로 분할하여 더 많은 작은 전문가를 생성.
2.2 효과
- 더 세밀한 역할 분리:
- 각 세분화된 전문가는 특정 작업(예: 특정 패턴 탐지, 특정 언어 처리)에 특화될 수 있음.
- 기존의 큰 전문가보다 모델의 표현력을 더 세밀하게 조정 가능.
- 부하 분산:
- 세분화된 전문가들은 더 고르게 분포된 부하를 처리하여 부하 불균형 문제를 완화.
3. Device-Limited Routing (DLR)
3.1 기존 MoE의 라우팅 방식
- 기존 MoE에서는 토큰이 k개의 전문가로 라우팅됩니다. 하지만 이 과정에서:
- 모든 디바이스(예: GPU 또는 노드)에 연결이 발생하여, 전문가 간 통신 비용이 매우 커지는 문제가 있었습니다.
3.2 DLR의 작동 방식
- DLR은 각 토큰을 M개의 디바이스(전문가가 위치한 노드)로만 라우팅되도록 제한합니다.
- 예를 들어, M = 3일 때, 각 토큰은 최대 3개의 디바이스와만 연결.
- 이를 통해 디바이스 간 통신 횟수를 획기적으로 줄임.
라우팅 알고리즘
- 게이트 네트워크(Gating Network)가 토큰의 중요도에 따라 상위 k개의 전문가를 선택.
- 선택된 k개의 전문가가 M개의 디바이스에 분배되도록 제한.
- 특정 디바이스에 집중되지 않도록 동적으로 균형 조정.
3.3 효과
- 통신 비용 감소:
- 모든 디바이스에 라우팅하는 대신, 제한된 M개의 디바이스에만 라우팅하여 통신 오버헤드를 대폭 줄임.
- 성능 유지:
- 실험적으로 M ≥ 3일 때 성능 손실 없이 통신 비용을 최소화할 수 있음.
4. Dynamic Token Dropping
4.1 기존 MoE의 문제
- 기존 MoE에서는 모든 토큰이 선택된 전문가로 라우팅되며, 이로 인해:
- 전문가가 과부하 상태에 도달하거나,
- 일부 토큰이 비효율적으로 처리되는 문제가 발생.
4.2 Dynamic Token Dropping의 작동 방식
DeepSeekMoE는 학습 중에 부하를 완화하기 위해 일부 토큰을 동적으로 드롭(drop) 합니다.
- 드롭 방식:
- 게이트 네트워크가 중요도가 낮은 토큰을 자동으로 식별하여 드롭.
- 중요도 판단 기준: g(x) 값(게이트 네트워크 출력) 크기.
- 효과적인 토큰 처리:
- 중요도가 높은 토큰만 전문가로 라우팅되므로, 전문가가 중요한 정보에 집중할 수 있음.
4.3 추론 시 동작
- 학습 중에는 부하를 줄이기 위해 일부 토큰을 드롭하지만, 추론 시에는 모든 토큰을 라우팅하여 모든 입력 정보를 활용.
4.4 효과
- 부하 불균형 완화:
- 중요도가 낮은 토큰을 제거함으로써 과부하 상태를 방지.
- 효율적 자원 활용:
- 전문가가 중요한 정보에 집중할 수 있도록 자원 배분.
5. DeepSeekMoE vs 기존 MoE 비교
특징 기존 MoE DeepSeekMoE
| 특징 | 기존 MoE | DeepSeekMoE |
| 전문가 크기 | 고정된 크기 | 세분화된 전문가 |
| 부하 불균형 문제 | 심각 | 완화 (Fine-Grained Segmentation) |
| 디바이스 간 통신 비용 | 높음 | 제한된 디바이스 라우팅 (DLR) |
| 토큰 라우팅 | 모든 토큰 라우팅 | 동적 토큰 드롭 (학습 시) |
| 성능 및 효율성 | 성능은 높으나 효율성은 낮음 | 성능 유지 + 효율성 개선 |
6. 결론
DeepSeekMoE는 기존 MoE의 주요 한계를 해결하며, Fine-Grained Segmentation, Device-Limited Routing, Dynamic Token Dropping을 통해 부하 분산, 통신 비용 감소, 효율적 토큰 처리를 구현했습니다.
이는 대규모 모델에서 성능 손실 없이 더 효율적인 학습과 추론을 가능하게 하며, 특히 자원이 제한된 환경에서 유용하게 활용될 수 있는 강력한 구조입니다.
그럼 DeepSeekMoE는 전문가를 좀 더 작은 단위로 분할하여 전문가의 수를 늘리고, 좀 더 전문적인 Attention Head를 생성하며, 라우팅 알고리즘을 기존 Top-k에서 최대 디바이스를 걸어줘 통신 비용을 감소하고, 동적으로 중요한 토큰만 넘겨주게 학습하여 과부화 방지 및 연산을 감소한 것이네?
네, 정확히 이해하셨습니다! DeepSeekMoE는 기존 MoE의 문제점을 해결하기 위해 다음과 같은 세 가지 핵심 아이디어를 도입하여 효율성, 성능, 확장성을 모두 강화한 구조입니다.
1. 전문가(Expert) 분할 및 수 증가
- Fine-Grained Expert Segmentation 기법을 사용하여, 기존의 큰 전문가를 더 작은 단위로 분할하고 전문가의 수를 늘렸습니다.
- 기존에는 하나의 전문가가 모든 Attention 역할을 처리했다면, DeepSeekMoE는 이를 여러 작은 전문가로 나눠 더 세분화되고 전문적인 Attention Head를 생성합니다.
- 이는 전문가들이 각기 다른 작업에 특화되도록 유도하며, 전체 모델의 표현력과 효율성을 높입니다.
2. 라우팅 알고리즘 최적화
- 기존 MoE는 게이트 네트워크가 입력 토큰을 상위 k개의 전문가로 라우팅하는 Top-k 라우팅 알고리즘을 사용했으나, DeepSeekMoE는 Device-Limited Routing (DLR)으로 이를 개선했습니다.
- DLR의 핵심:
- 각 토큰이 최대 M개의 디바이스에만 연결되도록 제한하여, 모든 디바이스와 전문가가 통신하는 오버헤드를 방지.
- M ≥ 3일 때 성능 저하 없이 통신 비용을 크게 감소시킬 수 있음.
- 결과적으로, 토큰-디바이스 간 연결 수를 제한하면서도 성능은 유지하는 혁신적인 방식입니다.
- DLR의 핵심:
3. 동적 토큰 드롭(Dynamic Token Dropping)
- 부하 불균형 해소 및 연산 최적화를 위해, 중요도가 낮은 토큰은 학습 중에 드롭(drop)합니다.
- 중요도는 게이트 네트워크의 출력 g(x) 값에 따라 결정되며, 중요도가 낮은 토큰은 드롭하여 전문가의 과부하를 방지.
- 학습 중에만 드롭하며, 추론 시에는 모든 토큰을 처리하여 최종 성능에 영향을 주지 않음.
- 이는 효율적인 자원 활용과 과부화 방지라는 두 가지 목표를 모두 충족합니다.
4. DeepSeekMoE의 궁극적 효과
- 세분화된 전문가 덕분에 각 전문가가 특정 작업에 최적화되며, 성능과 표현력이 향상됨.
- DLR 알고리즘으로 디바이스 간 통신 비용이 크게 줄어들어, 확장성이 뛰어남.
- 동적 토큰 드롭으로 불필요한 연산을 줄이고, 과부하를 방지하여 효율성을 극대화.
- 기존 MoE 대비 더 적은 자원으로 더 높은 성능을 달성.
📌 결론
DeepSeekMoE는 전문가 분할, 라우팅 제한, 동적 토큰 처리를 통해 기존 MoE의 한계를 극복하며, 효율성과 성능을 동시에 개선한 최적화된 MoE 구조입니다. 특히, 대규모 언어 모델에서 자원 절약과 고성능을 모두 달성하고자 할 때, 매우 유용한 접근법이라 할 수 있습니다! 🚀
DeepSeek의 Alignment: SFT와 RLHF를 통한 정렬
DeepSeek 모델의 Alignment는 Supervised Fine-Tuning (SFT)와 Reinforcement Learning with Human Feedback (RLHF)를 기반으로 이루어졌습니다. 이 과정은 모델이 사람과 더 잘 상호작용할 수 있도록 도움이 되며 안전한 출력을 생성하고, 고난이도의 작업 수행 능력을 강화하는 데 초점을 맞추고 있습니다.
1. Supervised Fine-Tuning (SFT)
1.1 SFT란 무엇인가?
SFT는 사람이 제공한 지도 데이터(Supervised Data)를 사용하여 모델을 튜닝하는 과정입니다.
DeepSeek에서는 1.5M 개 이상의 명령어 튜닝 데이터(command-tuning data)를 활용하여 모델을 학습시켰습니다.
1.2 데이터 구성
SFT 과정에서 사용된 데이터는 다음과 같이 구성되었습니다:
- 명령어 튜닝 데이터(Command-Tuning Data):
- 사용자가 주로 요청할 법한 다양한 질의(예: 질문 응답, 코딩, 수학 문제, 언어 번역 등)가 포함.
- 데이터는 고품질의 인간 주석(Human Annotation)을 기반으로 작성됨.
- 안전성 데이터(Safety Data):
- 유해한 답변 방지를 위한 데이터셋.
- 특정 상황에서 발생할 수 있는 편향(bias), 유해성(harmful output)을 완화하기 위해 학습.
- 도움말 데이터(Helpfulness Data):
- 사용자 요청에 대해 최대한 유용하고 직관적인 응답을 제공하도록 학습.
- 어려운 질문(수학, 코딩 등)을 효과적으로 해결하도록 초점을 맞춤.
1.3 SFT의 과정
- 초기 사전 훈련 모델 사용:
DeepSeek 모델은 대규모 토큰 데이터셋을 사용해 사전 훈련되었습니다. SFT는 이 사전 훈련 모델 위에서 진행되었습니다. - 지도 데이터 학습:
- Loss Function: Cross-Entropy Loss
- 모델이 주어진 입력에 대해 목표 출력을 정확히 생성하도록 학습.
- 예: 질문("What is the capital of France?")에 대해 목표 출력("The capital of France is Paris.")을 학습.
- 고난도 태스크 학습:
- 특히, 수학 계산, 코딩 문제 해결 등 복잡한 태스크에 대해 더 많은 데이터를 사용하여 모델의 능력을 강화.
- 안전성 강화:
- 안전성 관련 데이터셋을 통해, 유해하거나 부적절한 응답을 최소화.
1.4 SFT의 결과
- 모델은 명령어에 더욱 잘 정렬되며, 사용자 요청을 정확하고 유용하게 이해하고 응답할 수 있게 됨.
- 안전성과 유용성이 개선되었지만, 단순히 데이터 기반 학습만으로는 모델의 전반적인 품질을 최대화할 수 없기에 RLHF 과정이 필요합니다.
2. Reinforcement Learning with Human Feedback (RLHF)
2.1 RLHF의 기본 개념
RLHF는 사람이 제공한 피드백을 통해 강화 학습(리워드 기반 학습)을 수행하는 과정입니다. DeepSeek 모델에서는 SFT로 학습된 모델을 기반으로 RLHF를 적용했습니다.
2.2 RLHF의 3단계 프로세스


2.3 RLHF에서 사용된 최적화 기법
GRPO의 장점
- 안정성: 기존 PPO 대비 KL 발산을 보다 엄격히 조정하여 학습 중 불안정성을 최소화.
- 효율성: 적은 연산 자원으로 더 빠른 학습 가능.
- 정렬 개선: 사람이 제공한 피드백에 더 잘 정렬된 응답을 생성.
최적화 파라미터
- Optimizer: AdamW
- β1=0.9, β2=0.95, weight decay=0.1
- 학습률 스케줄:
- 초반에 Warm-up 단계 후, 선형적으로 감소.
- Fine-tuning 데이터는 RLHF 후 학습된 정책 모델의 업데이트를 안정화.
3. RLHF의 결과
- 사람 중심적 정렬:
- RLHF를 통해 모델은 사람이 선호하는 응답을 더 잘 생성할 수 있게 됨.
- 예: 간결하고 정확하며, 직관적인 답변.
- 고난이도 작업 수행:
- RLHF는 수학, 코딩, 논리적 문제 해결 등 더 복잡한 작업에서 모델의 정렬을 크게 개선.
- 안전성 강화:
- 사람이 유해하다고 판단한 응답을 피하도록 학습.
4. SFT + RLHF의 통합 효과
- SFT를 통해 초기 정렬을 개선:
- 명령어 이해 능력과 기본적인 안전성을 확보.
- RLHF로 정렬을 더욱 강화:
- 사람의 피드백을 활용해 사용자 중심의 응답 품질을 극대화.
- 최종 모델 결과:
- MT-Bench 및 AlignBench에서 최상위권 성능 기록.
- 사람과의 상호작용이 뛰어난 고성능 언어 모델.
📌 결론
DeepSeek의 Alignment는 SFT와 RLHF를 통합적으로 적용하여, 사람과 상호작용이 뛰어나고 고난이도 작업을 해결할 수 있는 언어 모델을 구축했습니다. 특히, GRPO 기반 RLHF 최적화는 안정적이고 효율적인 강화 학습을 가능하게 하며, DeepSeek 모델의 안전성과 유용성을 동시에 극대화했습니다.
DeepSeek-V2: 논문의 결과
1. 주요 결과
DeepSeek-V2는 최신 Mixture of Experts (MoE) 아키텍처와 혁신적인 최적화 기법을 통해 강력한 성능, 경제성, 효율성을 모두 달성한 언어 모델입니다. 구체적으로, 다음과 같은 성과를 보여주었습니다:
1.1 모델 성능
- 벤치마크 성능 비교
- DeepSeek-V2는 236B 총 매개변수와 21B 활성화 매개변수를 사용하면서, 다음과 같은 태스크에서 최상위권 성능을 기록:
- MMLU: 78.5점으로 Qwen-1.5(72B) 및 Mixtral(141B)과 동등하거나 우수.
- ARC-Challenge: 92.4점으로 거의 모든 경쟁 모델과 비슷한 수준.
- HumanEval (코드 생성): 48.8점으로 Mixtral과 유사.
- GSM8K (수학 문제): 79.2점으로 뛰어난 성능.
- LLaMA 3 70B 및 Qwen 72B 대비 성능에서 동등하거나 우위를 점함.
- DeepSeek-V2는 236B 총 매개변수와 21B 활성화 매개변수를 사용하면서, 다음과 같은 태스크에서 최상위권 성능을 기록:
- 128K 긴 컨텍스트 지원
- MLA와 RoPE의 결합을 통해 긴 컨텍스트에서도 높은 성능을 유지.
1.2 효율성
- KV 캐시 감소:
- MLA(Multi-Head Latent Attention)를 통해 KV 캐시 크기를 기존 MHA 대비 93.3% 감소.
- 추론 속도: GQA 및 MQA보다 최대 5.76배 빠른 추론 속도를 달성.
- MoE 개선:
- DeepSeekMoE는 다음을 통해 효율성을 극대화:
- 전문가 세분화(Fine-Grained Expert Segmentation)
- 제한된 디바이스 라우팅(Device-Limited Routing, DLR)
- 동적 토큰 드롭(Dynamic Token Dropping)
- DeepSeekMoE는 다음을 통해 효율성을 극대화:
- 훈련 비용 감소:
- 기존 MoE 대비 42.5% 훈련 비용 절감.
1.3 Alignment (정렬)
- SFT: 1.5M 명령어 튜닝 데이터를 사용해 기본 정렬 강화.
- RLHF: Group Relative Policy Optimization (GRPO)을 통해 안전성, 유용성, 그리고 고난이도 태스크 수행 능력을 크게 개선.
- MT-Bench 및 AlignBench 상위권 성능 기록.
2. 결론
2.1 모델의 강점
DeepSeek-V2는 성능, 효율성, 경제성의 균형을 맞춘 최적의 언어 모델로, 다음과 같은 점에서 강력한 경쟁력을 보유합니다:
- 강력한 성능:
- 최신 오픈소스 모델(LLaMA, Qwen 등)을 능가하는 성능을 보여줌.
- 효율적인 아키텍처:
- MLA, DeepSeekMoE 등 혁신적인 설계로 저장 공간 및 추론 속도를 최적화.
- 안전성 및 정렬:
- RLHF와 SFT를 통해 사람과의 상호작용에서 안전하고 유용한 응답을 생성.
2.2 한계
- 더 나은 확장성:
- DeepSeek-V2는 높은 효율성을 가지고 있지만, 여전히 GPT-4와 같은 초대형 모델과 직접 비교하기에는 한계가 있음.
- 멀티모달 지원 부족:
- 현재는 텍스트 중심의 언어 모델에 집중했으나, 이미지, 비디오 등 멀티모달 데이터로의 확장이 필요.
2.3 미래 연구 방향
- GPT-4 수준의 성능 향상:
- 더 대규모의 모델 및 MoE 최적화 연구를 통해 성능 강화.
- 멀티모달 AI로 확장:
- 이미지, 비디오, 텍스트 등을 통합적으로 처리하는 멀티모달 모델 개발.
- 지속적인 정렬 및 안전성 강화:
- 더 많은 데이터와 최적화 기법을 사용해 사람 중심의 응답 품질 개선.
- 자율적 학습 시스템 연구:
- 모델이 실시간 데이터를 활용해 스스로 학습하고 발전할 수 있는 구조를 도입.
3. 마무리
DeepSeek-V2는 강력하고 효율적이며 안전한 MoE 기반 언어 모델로, 대규모 AI 모델의 한계를 극복하기 위한 혁신적인 접근법을 제시합니다. 특히, MLA와 DeepSeekMoE는 기존 아키텍처를 뛰어넘는 효율성을 제공하며, RLHF는 모델의 정렬 품질을 강화했습니다. 앞으로도 이러한 기반을 바탕으로 더 발전된 AI 시스템이 개발될 것으로 기대됩니다. 🚀
DeepSeek-V2의 Pre-Training 과정
DeepSeek-V2의 사전 학습(Pre-Training)은 대규모 데이터를 활용한 고효율 훈련을 목표로 진행되었습니다. 모델이 다양한 언어와 작업에 대한 일반화된 능력을 학습할 수 있도록, 데이터 수집과 최적화, 훈련 전략에서 세심한 설계가 이루어졌습니다.
1. Pre-Training 데이터
1.1 데이터 크기와 구성
- 8.1조(T) 개의 토큰으로 구성된 다양하고 고품질의 멀티소스 데이터셋 활용.
- 영어, 중국어, 다국어 텍스트를 포함하여 다양한 태스크에서 활용 가능한 데이터를 확보.
- 중국어 데이터 비중 강화:
- DeepSeek 67B 모델 대비 중국어 데이터를 대폭 증가시켜 중국어 태스크에서 독보적인 성능을 목표로 함.
1.2 데이터 처리
- 데이터 필터링:
- 편향(bias), 부정확한 정보를 최소화하기 위해 데이터 전처리 수행.
- 불필요하거나 품질이 낮은 데이터를 제거하고, 유용한 데이터를 선별.
- 고품질 데이터 선택:
- 뉴스, 백과사전, 과학 논문, 소셜 미디어, 코딩 데이터 등 다양한 소스 활용.
- 실질적으로 태스크 수행에 도움이 되는 데이터로 훈련.
2. 모델 구성 및 사전 훈련 설정
2.1 모델 크기
- 총 파라미터: 236B
- 활성화 파라미터: 21B
- Mixture-of-Experts (MoE) 구조를 통해, 학습 중 일부 전문가만 활성화하여 효율성을 극대화.
- MoE를 통해 성능 손실 없이 계산 비용 절감.
2.2 최적화 기법
- Optimizer: AdamW
- 하이퍼파라미터:
- β1=0.9
- β2=0.95
- Weight Decay: 0.1
- AdamW를 활용해 큰 모델에서의 안정적 학습과 일반화 성능 강화.
- 하이퍼파라미터:
- Learning Rate 스케줄링:
- 초기에는 Warm-up 단계를 거쳐 학습률을 서서히 증가.
- 이후, 학습률을 선형적으로 감소시키는 스케줄을 적용.
2.3 효율적인 메모리 관리
- ZeRO-1 데이터 병렬화:
- 메모리 사용량을 줄이고, 훈련 중 자원을 효율적으로 활용하기 위해 ZeRO-1 병렬화 기법 적용.
- FlashAttention-2 기반 MLA 최적화:
- Multi-Head Latent Attention(MLA)을 적용하여, KV 캐시를 압축해 훈련 메모리와 계산 비용 감소.
3. 훈련 환경
3.1 하드웨어
- NVIDIA H800 GPU 클러스터 사용.
- 최신 GPU 하드웨어를 활용하여 대규모 모델 학습을 가속화.
3.2 병렬 처리
- 모델 병렬화:
- MoE 아키텍처를 활용해, 전문가 간 계산을 병렬화하여 훈련 속도를 높임.
- 효율적인 배치 처리:
- 배치 크기를 최적화하여, GPU 활용도를 극대화하고 통신 비용을 최소화.
4. Pre-Training의 결과
- 효율성:
- 활성화 파라미터 21B만 사용하면서도 236B의 전체 모델 성능에 준하는 결과를 달성.
- 기존 Dense 모델 대비 훈련 비용 42.5% 절감.
- 범용성 강화:
- 영어, 중국어를 포함한 다국어 태스크에서 우수한 일반화 성능을 보여줌.
- 중국어 데이터 비중 강화로 CLUEWSC, CMMLU 등 Chinese 태스크에서 독보적인 성능을 달성.
- 긴 컨텍스트 학습:
- Multi-Head Latent Attention(MLA)의 RoPE 개선을 통해 최대 128K 컨텍스트 길이 지원.
- 긴 문맥에서도 안정적인 성능 유지.
5. 결론
DeepSeek-V2의 Pre-Training은 다양한 데이터를 활용한 고품질 학습, 효율적인 최적화 전략, 최신 하드웨어와 알고리즘 적용을 통해 경제적이면서도 강력한 언어 모델을 구축하는 데 성공했습니다.
특히, MoE 아키텍처와 MLA 최적화는 성능 저하 없이 훈련 비용을 절감하고 추론 효율성을 극대화하는 핵심 역할을 했습니다. 🚀
아래는 기존 분석 내용을 개선하고, 전문가적인 논평으로 다듬은 최종 내용입니다. 이 내용은 블로그에 게시할 수 있을 정도로 구조적이고 전문성을 담아 작성했습니다.
DeepSeek-V2: 혁신적인 MoE 기반 언어 모델
최근 DeepSeek이 AI 연구 커뮤니티와 업계에서 큰 화제가 되고 있습니다. 하지만 일부 뉴스 기사들은 논문의 특정 부분을 과장하거나, 핵심을 놓치는 경우가 많아 직접 논문을 읽고 분석해보았습니다. 특히 DeepSeek-V2는 최신 기술을 집약한 MoE(Mixture of Experts) 기반 모델로, 성능과 효율성을 동시에 잡은 흥미로운 접근법을 보여줍니다.
1. Multi-Head Latent Attention (MLA): 효율성과 성능을 모두 잡다
DeepSeek-V2에서 가장 눈에 띄는 기술은 Multi-Head Latent Attention (MLA)입니다.
기존 Multi-Head Attention (MHA) 방식은 모든 Key와 Value를 고해상도로 저장해야 했기 때문에, 특히 긴 컨텍스트를 처리할 때 KV 캐시 크기 문제로 인해 성능 병목이 발생했습니다. MLA는 이를 혁신적으로 해결한 방식입니다.
MLA의 주요 특징
- KV 캐시를 Latent Space로 압축:
- Key와 Value를 저차원 공간으로 변환해 저장하고, 필요할 때 복원하여 사용합니다.
- 이로써 기존 KV 캐시 대비 저장 공간을 93.3% 절감했으며, 추론 속도는 최대 5.76배 향상되었습니다.
- RoPE(위치 정보 손실) 문제 해결:
- MLA는 RoPE(상대적 위치 정보)를 Key와 Query에서 분리 적용해, 긴 컨텍스트 처리에서의 위치 정보 손실 문제를 극복했습니다.
- 이를 통해 최대 128K 컨텍스트 길이에서도 안정적으로 성능을 유지합니다.
- 성능 유지:
- 기존 GQA(Grouped-Query Attention)와 MQA(Multi-Query Attention)는 효율성을 얻는 대가로 성능 저하를 감수해야 했습니다.
- 그러나 MLA는 효율성과 성능의 균형을 맞추는 데 성공했습니다.
➡️ 결론: MLA는 단순히 메모리 최적화뿐만 아니라, 실제 성능 저하 없이도 효율성을 극대화한 기술입니다.
2. DeepSeekMoE: 단순하지만 효과적인 MoE 최적화
DeepSeek-V2는 MoE(Mixture of Experts) 구조의 한계를 극복하기 위해 DeepSeekMoE를 도입했습니다. 기존 MoE 모델은 부하 불균형, 통신 비용 증가 등 여러 문제가 있었지만, DeepSeekMoE는 몇 가지 간단한 아이디어로 이를 해결했습니다.
DeepSeekMoE의 주요 개선점
- Fine-Grained Expert Segmentation (전문가 세분화):
- 기존 전문가를 더 작은 단위로 나누어 부하를 균등하게 분산.
- 각 전문가가 더욱 특화된 작업을 수행할 수 있도록 유도.
- Device-Limited Routing (DLR):
- 토큰을 라우팅할 때, 최대 M개의 디바이스로 제한하여 통신 비용 감소.
- M = 3일 때 성능 저하 없이 통신 효율 극대화.
- Dynamic Token Dropping (동적 토큰 드롭):
- 학습 중 중요도가 낮은 토큰은 드롭하여 과부화를 방지.
- 추론 시 모든 토큰을 처리하므로 성능 손실 없음.
➡️ 결론: 단순하지만 효과적인 설계를 통해 계산 자원을 효율적으로 활용하고, MoE 구조의 한계를 극복했습니다.
3. DeepSeek-V2에 대한 종합 평가
DeepSeek-V2는 236B의 총 파라미터 중 21B 활성화 파라미터만 사용하면서도, 최신 Dense 및 MoE 기반 모델(LLaMA 3, Qwen-1.5, Mixtral 등)과 동등하거나 더 나은 성능을 보여줬습니다. 특히 중국어 태스크(CLUEWSC, CMMLU 등)에서 압도적인 성능을 기록하며 특정 언어에서의 강점을 증명했습니다.
장점
- 효율성과 성능의 균형:
MLA와 DeepSeekMoE는 메모리 사용량 감소, 추론 속도 향상, 훈련 비용 절감을 동시에 달성. - 강력한 성능:
다양한 태스크(MMLU, GSM8K, PIQA 등)에서 상위권 성능을 기록.
한계
- 코드 생성 및 일부 수학 태스크에서 Qwen-1.5, LLaMA 3 대비 약간의 성능 차이가 있음.
- 여전히 GPT-4 수준의 모델과는 비교하기 어려움.
4. 개인적인 의견
DeepSeek-V2는 효율성을 극대화한 오픈소스 모델로, 기존 Dense 모델의 문제를 해결한 혁신적인 사례입니다.
특히 MLA와 DeepSeekMoE의 설계는 단순하지만 효과적인 아이디어로, 언뜻 평범해 보이는 접근이지만, 놀라운 결과를 가져왔습니다.
하지만, 이 모델이 전 세계적으로 크게 주목받지 못한 이유는 두 가지로 생각됩니다:
- 중국이 개발한 오픈소스 모델이라는 한계:
- 글로벌 시장에서 중국 개발 모델은 종종 과소평가되는 경향이 있습니다.
- GPT-4와의 비교:
- DeepSeek-V2가 뛰어난 성능을 보유했음에도 불구하고, GPT-4 수준의 언어 모델에는 아직 도달하지 못했습니다.
➡️ 그러나 DeepSeek-V2는 효율성과 성능의 균형이라는 점에서 대규모 언어 모델 개발에 새로운 기준을 제시했다고 평가할 수 있습니다. 앞으로 더 발전된 버전이 출시된다면, 글로벌 AI 커뮤니티에서도 더 많은 주목을 받을 것으로 보입니다.
결론
DeepSeek-V2는 단순하지만 효과적인 설계를 통해 효율적이고 강력한 언어 모델을 구축했습니다. 특히, 메모리와 계산 자원의 한계를 극복하려는 연구자들에게는 중요한 사례가 될 것입니다.
이 논문이 보여주는 아이디어는 언뜻 평범해 보일 수 있지만, 실제 성과를 보면 놀라운 혁신임을 알 수 있습니다. 앞으로 DeepSeek 시리즈가 어떤 방향으로 발전할지 기대됩니다. 🚀