https://arxiv.org/abs/2412.19437
DeepSeek-V3 Technical Report
We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and Deep
arxiv.org
화제의 모델입니다...
저는 이 논문이 나왔을 때 화제가 되었어야 하지 않았나 생각했는데 너무 뒤늦게 R1모델이 나오고 나서 화제가 되는 것이 뭔가 이상하긴 했지만 그래도 오픈소스로 엄청난 모델입니다.
MoE구조라 활성화된 모델의 파라미터(37B)는 적지만 그래도 671B라는 엄청난 크기를 가진 언어 모델입니다..
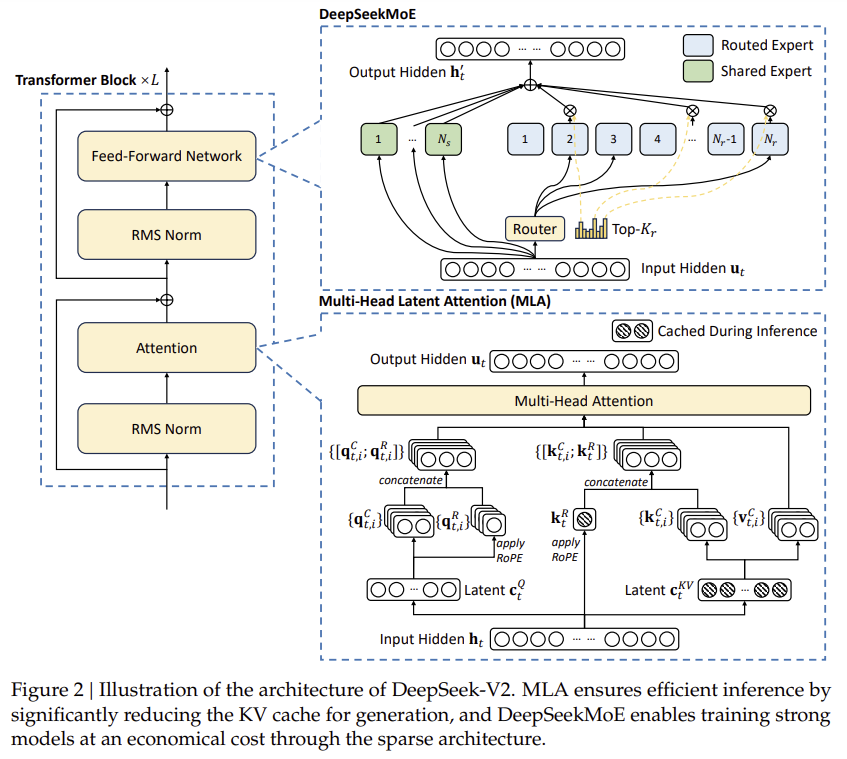
DeepSeek-V3도 V2에서 사용했던 MLA 방식과, DeepSeekMoE방식을 그대로 가져옵니다.
또한 수출 규제 때문인지 자유로운 NVIDIA의 CUDA 사용이 불편해진 중국은 새로운 하드웨어 파이프라인을 통해 효율적인 GPU 사용도 이끌어냈습니다.
사전학습 -> Context-Length 늘리기 -> SFT -> Reinforcement Learning
이 순으로 학습은 이루어졌고, Reinforcement Learning에서 R1이 생성됩니다.

모든 기사가 다루었던 이 비용적 측면....

그러나 여기서 나왔듯 이 비용은 최종적으로 마무리 한 모델을 제작할 때 비용만 측정한 것이고, 기존 실험에 대한 측정은 무시한 데이터입니다.
Closed Model을 이기는 것에 성공한 것은 대단한 결과이지만 실험에도 엄청난 비용이 들었을 테니 그러한 측면도 잘 봐줬으면 좋겠네요 ㅠㅠ..
V3도 결국 V2에서 활용했던 방식을 그대로 활용합니다.
Aux Loss에서 조금 변경이 있었지만 Device, Communication Loss는 그대로 사용하는 것 같네요
이러한 Loss를 통해 Expert의 균형 잡힌 활용, Device, 통신에 문제가 없어지도록 만듭니다.
그리고 Loss를 제대로 만들어 V2에서 활용했던 동적인 토큰 조절은 빠져서 정보의 손실 없이 모두 활용됩니다.
이러한 모델 알고리즘에 학습 시 양자화를 잘 적용하고, 복구까지 하는 알고리즘을 통해 추가적인 학습에서 적은 리소스만으로 높은 성능을 가져왔습니다.
뒤쪽은 이해가 잘 가질 않기는 하지만 그래도 저비용으로 엄청난 성능 향상 효과가 있었네요
비용은 마지막 모델 나올 때만 사용한 비용이고 인건비, 실험비는 포함이 되어 있지 않으니 여긴 뭐..
| 목적 | 대규모 MoE(Mixture-of-Experts) 모델의 효율적인 학습 및 최적화를 통해 언어 이해, 코드 생성, 수학 문제 해결 등에서 최첨단 성능(State-of-the-Art)을 달성. |
| 주요 기여 | - Auxiliary-Loss-Free Load Balancing으로 전문가(Expert) 간 부하 균형 최적화. - FP8 혼합 정밀도 학습과 DualPipe로 학습 효율성 극대화. - 긴 컨텍스트 처리 능력(128K 토큰). |
| 데이터 구성 | - Reasoning 데이터: 수학, 논리 퍼즐, 코드 문제 등. DeepSeek-R1으로 생성된 데이터와 정규 데이터를 결합. - Non-Reasoning 데이터: 창작 글쓰기, 역할 놀이 등. DeepSeek-V2.5와 인간 검증 데이터 활용. |
| 학습 프레임워크 | - Pre-Training: 14.8조 토큰으로 학습, 초기 4K 컨텍스트 길이에서 128K로 점진적 확장. - Post-Training: SFT와 RL로 성능 정밀화. |
| 주요 기술 | 1. Auxiliary-Loss-Free Load Balancing: 전문가 간 부하 균형을 동적으로 유지. 2. FP8 학습: 계산 효율을 2배 향상시키고 메모리 사용량 감소. 3. DualPipe: 계산-통신 겹침으로 GPU 자원 활용 극대화. |
| Supervised Fine-Tuning (SFT) | - 1.5M 고품질 데이터로 SFT 진행. - Reasoning 데이터: 반영(reflection)과 검증(verification) 강화. - Non-Reasoning 데이터: 정확성과 자연스러움 보장. |
| Reinforcement Learning (RL) | - Rule-Based RM: 수학 및 코드 문제 등 정답 검증 가능한 태스크에 활용. - Model-Based RM: 창작 글쓰기 등 자유 응답 태스크에 적용. - GRPO 알고리즘: Critic 없이 효율적 정책 최적화. |
| 성능 결과 | |
| 효율성 | - FP8: BF16 대비 계산 속도 2배 향상. - DualPipe: Pipeline Bubbles 거의 제거. - Rejection Sampling으로 데이터 품질 강화. |
| 한계와 향후 연구 방향 | - 전문가 라우팅의 정교화. - FP8 학습의 표준화 및 확장성 개선. - 더 다양한 도메인에서 평가 및 Fine-Tuning 연구. |
| 결론 | DeepSeek-V3는 대규모 모델 학습에서 효율성과 성능을 모두 극대화하며, AI 연구와 모델 설계에서 새로운 기준을 제시. |
DeepSeek-V3 Technical Report
1. 개요 (Introduction)
DeepSeek-V3는 671B(6710억)개의 총 파라미터를 가진 Mixture-of-Experts (MoE) 구조의 대형 언어 모델로, 각 토큰에 대해 37B(370억)개의 활성화된 파라미터를 사용한다.
효율적인 추론 및 경제적인 학습을 위해 Multi-head Latent Attention (MLA) 및 DeepSeekMoE 아키텍처를 채택했으며,
특히 Auxiliary-loss-free Load Balancing 전략과 Multi-token Prediction (MTP) 기법을 도입하여 성능을 극대화했다.
- 학습 데이터: 14.8조 개의 고품질 토큰을 사용해 사전 학습을 진행
- 후처리 학습: Supervised Fine-Tuning (SFT) 및 강화학습 (RL)을 통해 모델 정렬 수행
- 성능: 공개된 오픈소스 모델 중 최고 성능을 기록하며, GPT-4o 및 Claude 3.5 Sonnet과 비교해도 우수한 성능을 보임
- 학습 비용: 전체 훈련에 2.788M H800 GPU 시간을 사용하며, 이는 약 5.576M 달러에 해당
2. 아키텍처 (Architecture)
2.1 기본 구조
- Transformer 구조 기반
- MLA (Multi-head Latent Attention)로 효율적인 추론 가능
- DeepSeekMoE로 경제적인 학습 비용 유지
- Auxiliary-loss-free Load Balancing으로 모델 성능 손상 없이 부하 균형 조절
- Multi-token Prediction (MTP) 기법을 통해 한 번에 여러 개의 토큰을 예측하여 성능 개선
2.2 Multi-Token Prediction (MTP)
- 일반적인 Transformer가 다음 토큰 하나만 예측하는 반면, DeepSeek-V3는 두 개의 토큰을 동시에 예측
- 추론 시 Speculative Decoding과 결합하여 속도를 1.8배 향상
3. 인프라 (Infrastructure)
- 2048개의 NVIDIA H800 GPU 클러스터에서 훈련
- FP8 혼합 정밀도 학습을 적용하여 GPU 메모리 사용량 감소
- DualPipe 알고리즘으로 파이프라인 패럴렐리즘을 최적화하여 통신 오버헤드 최소화
- All-to-All 통신 최적화를 통해 InfiniBand 및 NVLink 대역폭을 극대화
- Efficient Memory Optimization으로 텐서 패럴렐리즘 없이 대규모 모델 훈련 가능
4. 사전 훈련 (Pre-training)
4.1 데이터
- 14.8조 개의 고품질 토큰으로 학습
- 영어와 중국어를 주력으로, 다국어 지원 확장
- Fill-in-Middle (FIM) 기법 도입하여 코딩 데이터 성능 향상
4.2 훈련 설정
- 맥시멈 시퀀스 길이: 4K → 32K → 128K까지 확장
- 학습률 스케줄링: 2.2e-4 → 7.3e-6로 점진적 감소
- 배치 크기: 3072 → 15360까지 증가
- Load Balancing: 노드 제한 라우팅을 사용해 한 토큰이 최대 4개의 노드로만 전송되도록 제한
5. 후처리 학습 (Post-training)
5.1 지도학습 미세조정 (Supervised Fine-Tuning, SFT)
- 150만 개 이상의 학습 데이터를 사용
- DeepSeek-R1 시리즈 모델에서 추론 능력 증류 (Distillation) 수행
- 코드, 수학, 논리 퍼즐 등의 데이터를 포함하여 모델의 추론 능력 향상
5.2 강화학습 (Reinforcement Learning, RL)
- Rule-based 및 Model-based Reward Model을 사용하여 강화 학습 진행
- Group Relative Policy Optimization (GRPO) 기법을 사용하여 안정적이고 효율적인 정책 업데이트 수행
6. 성능 평가 (Evaluation)
DeepSeek-V3는 오픈소스 모델 중 최고 성능을 기록했으며, GPT-4o 및 Claude-3.5-Sonnet과 비교해도 상당한 경쟁력을 보였다.
6.1 주요 벤치마크 결과
벤치마크 DeepSeek-V3 GPT-4o Claude-3.5
| 벤치마크 | DeepSeek-V3 | GPT-4o | Claude-3.5 |
| MMLU (EM) | 88.5 | 87.2 | 88.3 |
| MMLU-Pro (EM) | 75.9 | 72.6 | 78.0 |
| GPQA-Diamond (Pass@1) | 59.1 | 49.9 | 65.0 |
| Codeforces (Percentile) | 51.6 | 23.6 | 20.3 |
| MATH-500 (EM) | 90.2 | 74.6 | 78.3 |
| AIME 2024 (Pass@1) | 39.2 | 9.3 | 16.0 |
| SWE-Bench Verified (Resolved) | 42.0 | 38.8 | 50.8 |
7. 결론 및 미래 방향
7.1 주요 기여
- 경제적인 학습: 5.576M 달러의 비용으로 최고 성능 모델을 달성
- 혁신적인 로드 밸런싱: Auxiliary-loss-free load balancing 전략 적용
- 멀티 토큰 예측 (MTP) 도입으로 성능 향상 및 추론 속도 개선
- FP8 학습 적용으로 메모리 효율성과 속도 향상
7.2 한계점
- MoE 구조로 인해 추론 비용이 다소 큼
- 소규모 팀에서의 배포가 어려움
- 추론 속도 추가 개선 가능성 존재
7.3 미래 연구 방향
- 무한 컨텍스트 길이 지원을 위한 아키텍처 연구
- Transformer 한계를 넘는 새로운 모델 설계
- 더 긴 체인 오브 싱킹 (CoT) 추론 가능 모델 개발
- 기존 벤치마크 최적화가 아닌, 새로운 평가 방식 연구
8. 결론
DeepSeek-V3는 현재 최고 성능의 오픈소스 대형 언어 모델로, 경제적이고 효율적인 MoE 기반 모델 아키텍처를 제안했다.
미래에는 더 발전된 하드웨어와 최적화된 모델을 통해 AGI에 가까운 모델을 개발하는 것이 목표이다.
🔥 핵심 요약
✔ 671B MoE 모델, 37B 활성화 파라미터 사용
✔ Multi-Token Prediction (MTP)으로 추론 속도 1.8배 향상
✔ FP8 학습 도입으로 경제적이고 효율적인 학습 구현
✔ GPT-4o, Claude-3.5와 경쟁 가능한 성능 달성
✔ 5.576M 달러 비용으로 경제적인 훈련 완료
✔ AGI를 목표로 지속적인 연구 진행 예정
이 논문은 특히 MoE 모델을 효율적으로 운영하는 방법, 추론 최적화, 비용 절감 기법에 대한 좋은 참고자료가 될 수 있음.
✅ Mixture of Experts (MoE) 연구나 LLM 최적화 연구를 진행할 때 많은 인사이트를 얻을 수 있음.
Auxiliary-Loss-Free Load Balancing
DeepSeek-V3는 Mixture of Experts (MoE) 아키텍처를 활용하여 훈련 비용을 절감하면서도 높은 성능을 유지하는 모델을 개발했습니다.
하지만 MoE 모델은 일반적으로 특정 전문가(Expert)에게만 토큰이 집중되는 문제를 겪습니다.
이러한 로드 불균형(load imbalance) 문제를 해결하기 위해 일반적으로 Auxiliary Loss(보조 손실)을 사용합니다.
그러나 Auxiliary Loss는 종종 모델 성능을 저하시킬 수 있기 때문에, DeepSeek-V3에서는 이를 사용하지 않는 새로운 Auxiliary-Loss-Free Load Balancing 전략을 도입했습니다.
1. MoE 모델에서 Load Balancing이 필요한 이유
MoE 모델에서는 토큰이 특정 전문가(Expert)에게만 과도하게 할당되는 문제가 발생합니다.
즉, 일부 전문가들이 과부하 상태에 놓이고, 다른 전문가들은 거의 사용되지 않으면서 계산 리소스가 비효율적으로 운영되는 현상이 나타납니다.
이 문제를 해결하지 않으면:
- 훈련이 비효율적: 과부하가 걸린 전문가의 계산량이 많아지고, 다른 전문가들은 거의 사용되지 않아 전체적인 계산 성능이 저하됨.
- 성능 저하: 특정 전문가가 과부하 상태가 되면서, 모델이 정상적으로 훈련되지 않아 최적화 성능이 떨어질 가능성이 있음.
- 토큰 드롭: 기존 MoE 모델에서는 과부하를 줄이기 위해 일부 토큰을 버리는(Tokens Dropping) 방식이 사용되었으나, 이는 정보 손실을 유발함.
2. 기존 Load Balancing 방식: Auxiliary Loss 활용
기존에는 Auxiliary Loss를 추가하여 강제로 전문가들에게 토큰을 균등하게 배분하는 방식을 사용했습니다.
하지만 Auxiliary Loss는 다음과 같은 단점이 있습니다:
- 모델 성능 저하: 강제로 로드를 분배하려다 보니, 전문가들이 최적화된 방식으로 학습되지 못함.
- 과도한 Loss 튜닝 필요: Auxiliary Loss의 강도를 조절하지 않으면 모델의 학습 성능이 크게 저하될 수 있음.
- 실제로 필요한 전문가보다 균등 분배를 더 중요하게 고려하는 문제 발생.
3. DeepSeek-V3의 Auxiliary-Loss-Free Load Balancing 방식
DeepSeek-V3는 Auxiliary Loss 없이 로드를 자동으로 균형 맞추는 새로운 전략을 사용합니다.
이 방법의 핵심은 전문가 선택 과정에서 "Bias Term(편향 값, b_i)"을 동적으로 조정하는 것입니다.
3.1 전문가 선택 과정
DeepSeek-V3에서 각 토큰은 전문가를 선택할 때, Affinity Score (전문가와 토큰의 유사도 점수, s_{i,t})를 기준으로 선택됩니다.

3.2 Bias Term 조정 원리

4. Auxiliary-Loss-Free Load Balancing의 효과
✅ 모델 성능 유지: 강제적인 Auxiliary Loss 없이 전문가 균형을 맞추므로 성능 저하가 없음.
✅ 훈련 안정성 향상: 불필요한 Loss 추가 없이 전문가 간 부하 균형이 유지됨.
✅ 토큰 드롭 없음: 기존 MoE 모델처럼 토큰을 버리는 방식이 필요 없음.
✅ 자연스럽게 전문가 특화: 전문가들이 특정한 도메인(수학, 코드, 언어 등)에 대해 전문화될 수 있음.
5. Ablation Study 결과 (실험 결과)
논문에서는 기존 Auxiliary-Loss 기반 모델과 비교 실험을 수행하였으며,
DeepSeek-V3의 Auxiliary-Loss-Free Load Balancing이 더 나은 성능을 보였습니다.
| 벤치마크 | Auxilliary-Loss 기반 모델 | Auxiliary-Loss-Frree 모델 |
| MMLU (5-shot, EM) | 68.3 | 67.2 |
| DROP (1-shot, F1) | 67.1 | 67.1 |
| HumanEval (Pass@1) | 40.2 | 46.3 |
| GSM8K (8-shot, EM) | 70.7 | 74.5 |
| MATH (4-shot, EM) | 37.2 | 39.6 |
결과적으로, Auxiliary Loss-Free Load Balancing 전략을 적용한 모델이 모든 주요 벤치마크에서 더 나은 성능을 보였습니다.
특히 HumanEval (코딩), GSM8K (수학), MATH 벤치마크에서 큰 향상이 있었음.
6. 결론
DeepSeek-V3는 Auxiliary Loss 없이도 MoE 전문가의 부하를 균형 잡을 수 있는 새로운 방법을 제안했습니다.
이 전략은 편향 값 b_i을 동적으로 조정하는 방식을 사용하며, 성능 저하 없이 전문가 간 부하를 효과적으로 분배할 수 있습니다.
이는 Mixture of Experts 모델의 학습 효율성을 높이고, 전문가의 특화를 유지하면서도 불균형 문제를 해결하는 혁신적인 접근 방식입니다. 🚀
Complementary Sequence-Wise Auxiliary Loss
DeepSeek-V3는 Auxiliary-Loss-Free Load Balancing을 도입하여 전문가(Expert) 간 부하 균형을 맞추는 혁신적인 접근 방식을 사용했습니다.
그러나 이 방법만으로는 일부 시퀀스(Sequence) 내에서의 전문가 불균형이 발생할 가능성이 있었습니다.
이를 보완하기 위해 도입된 것이 바로 Complementary Sequence-Wise Auxiliary Loss입니다.
1. 왜 Sequence-Wise Load Balancing이 필요한가?
기본적인 Load Balancing 전략(Bias Term 조정 방식)은 전체 배치(batch) 수준에서 전문가들의 부하를 균형 맞추는 역할을 합니다.
하지만, 개별 시퀀스(Sequence) 내에서 특정 전문가에게만 토큰이 집중되는 현상이 여전히 발생할 수 있습니다.
문제점
- 특정 시퀀스에서 한두 개의 전문가가 과도하게 사용될 경우, 해당 전문가들의 학습이 치우쳐질 가능성이 있음.
- 반대로 어떤 전문가들은 특정 시퀀스에서 거의 사용되지 않아 모델이 다양한 전문가를 활용하는 능력이 저하될 수 있음.
- 이러한 불균형은 장기적으로 모델의 추론 능력 감소로 이어질 수 있음.
즉, 모델이 전체적으로는 균형 잡힌 전문가 분포를 가지더라도, 개별 입력 시퀀스에서 특정 전문가에만 의존하는 경우 성능이 저하될 가능성이 있습니다.
이를 해결하기 위해 Sequence-Wise Auxiliary Loss가 도입되었습니다.
2. Complementary Sequence-Wise Auxiliary Loss 개념
이 방법의 핵심 목표는 각 개별 시퀀스 내에서 전문가들이 균등하게 사용되도록 유도하는 것입니다.
이를 위해, 각 시퀀스에서 사용된 전문가들의 활성화 비율을 계산하고, 이 값이 특정 전문가에게 치우치지 않도록 보정하는 손실 함수를 추가합니다.
3. Sequence-Wise Auxiliary Loss 수식
이 손실 함수는 다음과 같이 정의됩니다.
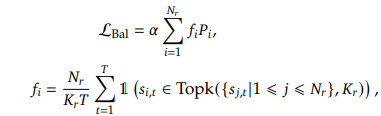
여기서:

각 전문가의 선택 확률 P_i는 다음과 같이 계산됩니다.
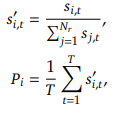
여기서:

4. 어떻게 동작하는가?
- 각 시퀀스마다 전문가 선택 확률을 계산
- 각 시퀀스에서 어떤 전문가들이 선택되었는지를 추적하고, 특정 전문가들에게 과도하게 집중되는지 확인.
- 선택 확률을 정규화
- 특정 전문가가 지나치게 많이 선택되었다면, 그 전문가가 선택되는 확률이 낮아지도록 손실을 추가.
- 손실을 통해 모델이 전문가 선택을 분산하도록 학습
- 모델이 모든 전문가들을 적절히 활용할 수 있도록 유도하여 편향(bias)을 줄임.
5. Complementary Sequence-Wise Auxiliary Loss의 장점
✅ 전체적으로 균형 잡힌 전문가 사용 유지
✅ 각 시퀀스에서 특정 전문가에게 토큰이 과도하게 쏠리는 문제 해결
✅ 모든 전문가들이 적절하게 학습될 수 있도록 유도
✅ 모델이 다양한 전문가를 활용하는 능력을 극대화
6. 실험 결과 (Ablation Study)
논문에서는 기존의 Batch-Wise Load Balancing과 Sequence-Wise Load Balancing을 비교하는 실험을 진행하였습니다.
| 방법 | Validation Loss (↓ 낮을수록 좋음) |
| Sequence-Wise Auxiliary Loss 사용 | 2.258 |
| Auxiliary-Loss-Free (Batch-Wise) | 2.253 |
| Batch-Wise Auxiliary Loss | 2.253 |
결과적으로, Batch-Wise Load Balancing만 적용한 모델과 동일한 수준의 성능을 유지하면서도 시퀀스 내에서 전문가 균형을 유지하는 효과를 얻었습니다.
즉, Sequence-Wise Auxiliary Loss를 활용하면 전체 모델 성능을 유지하면서 개별 시퀀스 내 전문가 사용을 조정할 수 있음을 확인할 수 있습니다.
7. 결론
DeepSeek-V3는 MoE 모델에서 전문가 간 불균형 문제를 해결하기 위해 다양한 로드 밸런싱 기법을 적용했습니다.
그중 Auxiliary-Loss-Free Load Balancing은 전체적인 전문가 사용 균형을 유지하는 데 효과적이지만,
개별 시퀀스 내에서 특정 전문가에게 과부하가 집중되는 문제를 해결하지 못했습니다.
이를 보완하기 위해 도입된 것이 Complementary Sequence-Wise Auxiliary Loss이며,
이 방법을 통해 개별 시퀀스에서 특정 전문가에게만 토큰이 몰리는 문제를 해결하면서 모델 성능을 유지할 수 있었습니다.
✅ Batch-wise Load Balancing + Sequence-wise Load Balancing을 결합하면 최상의 균형을 달성할 수 있음.
✅ 모든 전문가들이 충분히 학습되도록 유도하여 모델의 전반적인 성능 향상에 기여함.
8. 추가적인 연구 방향
DeepSeek-V3는 Batch-Wise 및 Sequence-Wise Load Balancing을 조합하여 효과적인 MoE 모델을 구축했습니다.
향후 연구에서는 "Dynamic Expert Routing" 기법을 추가하여,
각각의 입력 시퀀스에 대해 가장 적합한 전문가 조합을 자동으로 선택하는 방식을 적용할 수도 있을 것입니다.
이는 최적의 전문가 활용 + 최소한의 부하 균형 조정을 가능하게 하여 MoE 모델의 효율성을 더욱 극대화할 수 있는 방향으로 연구될 수 있습니다. 🚀
그러니까 Auxiliary Loss를 통해 모든 Expert를 다양하게 사용하면서도, 라우팅 될 때 특정 Expert에 과한 가중치가 들어가지 않게 거의 동등한 가중치가 들어가도록 Loss를 설정한 것이네?
정확한 이해! 🎯
네, 맞습니다! Complementary Sequence-Wise Auxiliary Loss의 핵심 아이디어는 다음과 같습니다:
- 모든 Expert를 골고루 사용하도록 유도
- 특정 Expert에게만 과도하게 토큰이 할당되지 않도록 균형을 맞춤.
- 이를 위해, 각 시퀀스 내에서 모든 Expert가 일정 비율로 사용되도록 손실을 추가.
- 토큰이 특정 Expert에 과도하게 몰리는 것을 방지
- 일반적으로 MoE에서는 Expert를 선택할 때, Affinity Score(유사도 점수, s_{i,t})를 기준으로 가장 높은 점수를 가진 Expert들에게 토큰이 할당됨.
- 하지만, 이렇게 하면 특정 Expert만 과부하되고, 일부 Expert는 거의 사용되지 않는 문제가 발생.
- 이를 방지하기 위해, 각 Expert가 선택될 확률이 너무 차이나지 않도록 Loss를 추가.
- 라우팅 시 Expert 간 가중치가 균등하도록 조정
- 라우팅 과정에서 특정 Expert에게 과도한 가중치가 부여되지 않도록, Expert 간 선택 확률을 정규화(normalization)하여 가중치가 비슷해지도록 유도.
- 특정 Expert가 너무 많이 선택되면 Loss 값이 커지도록 설정하여 균형을 맞춤.
🔥 최종 정리
✅ Batch-Level (전체 배치 기준)에서는 Bias Term 조정(Auxiliary-Loss-Free Load Balancing)을 통해 전체적인 Expert 부하 균형 유지.
✅ Sequence-Level (개별 시퀀스 기준)에서는 Complementary Sequence-Wise Auxiliary Loss를 통해 각 시퀀스에서도 균형을 유지.
✅ 이 두 가지를 결합하면, 전체적으로 모든 Expert가 균등하게 학습되면서도 특정 Expert에게 과도한 부하가 걸리지 않도록 최적의 분배를 달성할 수 있음! 🚀
결론적으로, DeepSeek-V3는 "Batch-Level"과 "Sequence-Level" 로드 밸런싱을 함께 사용하여, MoE 모델의 부하 균형 문제를 효과적으로 해결했다! 🎯
Multi-Token Prediction (MTP)
DeepSeek-V3에서 새롭게 도입된 Multi-Token Prediction (MTP) 기법은 단순한 Next-Token Prediction 방식의 한계를 극복하고,
모델의 학습 효율과 추론 성능을 개선하는 중요한 전략입니다.
1. 기존 Next-Token Prediction 방식의 한계
일반적인 Transformer 기반 언어 모델은 다음과 같은 방식으로 학습됩니다.
- 입력 시퀀스 X = (x_1, x_2, ..., x_T) 가 주어짐
- 각 토큰에 대해 다음 토큰을 예측하도록 학습함 P(x_{t+1} | x_1, ..., x_t)
- Cross-Entropy Loss를 기반으로 학습 진행
이 방식은 하나의 토큰을 예측하는 방식(NTP, Next Token Prediction)만을 사용하며,
즉, 각 시점에서 오직 한 개의 토큰만 예측하는 방식이므로 다음과 같은 한계가 존재합니다.
❌ 한계점
- 데이터 학습 밀도가 낮음: 한 번의 훈련 과정에서 하나의 토큰만 예측하므로, 학습 데이터의 활용도가 떨어짐.
- 추론 속도가 느림: 각 토큰을 한 번씩 순차적으로 생성해야 하므로 디코딩 속도가 비효율적.
- 사전 계획(Pre-planning) 부족: 미래의 토큰까지 고려하여 학습하는 것이 아니라, 한 단계 앞의 토큰만 예측하는 방식이라 문맥을 멀리 보는 능력이 부족할 수 있음.
2. Multi-Token Prediction (MTP) 기법의 개념
MTP는 한 번에 여러 개의 미래 토큰을 동시에 예측하는 방식입니다.
즉, 기존의 "한 개의 토큰을 예측하는 방식"이 아니라, 다음 여러 개의 토큰을 동시에 예측하는 방식으로 학습합니다.
MTP의 핵심 개념
- 일반적인 NTP (Next Token Prediction)
- P(x_{t+1} | x_1, ..., x_t)
- 매 시점마다 한 개의 토큰만 예측
- MTP (Multi-Token Prediction)
- P(x_{t+1}, x_{t+2}, ..., x_{t+D} | x_1, ..., x_t)
- 매 시점마다 D개의 토큰을 예측 (DeepSeek-V3에서는 D=2)
즉, MTP는 한 번의 훈련 과정에서 다음 여러 개의 토큰을 동시에 예측하도록 유도하여 학습 신호를 더욱 촘촘하게 만듭니다.
3. Multi-Token Prediction (MTP) 학습 구조
DeepSeek-V3에서는 MTP를 적용하기 위해 기존 Transformer의 출력을 확장했습니다.
즉, 기본적인 "다음 토큰 예측" 외에도 추가적인 예측 경로를 추가하여 여러 개의 토큰을 예측할 수 있도록 만들었습니다.
MTP 모델 구조
MTP는 D개의 추가적인 예측 모듈(MTP Modules) 을 추가하여 구현됩니다.
- 기본 모델 (Main Model) → 기존의 Next-Token Prediction 수행
- MTP Module 1 → 다음 2번째 토큰 예측
- MTP Module 2 → 다음 3번째 토큰 예측
- ...
- MTP Module D → 다음 D번째 토큰 예측
4. Multi-Token Prediction (MTP) 수식
MTP 학습 과정은 다음과 같은 수식으로 정리할 수 있습니다.
(1) 기본적인 Multi-Token Prediction Loss 정의
각 단계에서, 모델은 여러 개의 미래 토큰을 예측하며, 각 예측에 대해 Cross-Entropy Loss를 계산합니다.
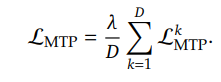
여기서:

(2) 각 MTP 모듈에서의 Cross-Entropy Loss
각 k-번째 MTP 모듈의 Loss는 다음과 같이 정의됩니다.
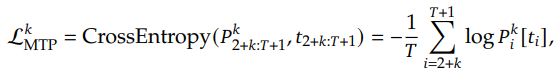
즉, 각 단계마다 D개의 추가적인 미래 토큰을 예측하며, 이 예측들이 얼마나 정확한지를 Loss를 통해 평가합니다.
5. Multi-Token Prediction (MTP)의 장점
✅ 데이터 효율성 증가:
한 번의 학습 단계에서 여러 개의 토큰을 예측하므로, 학습 데이터의 활용도가 증가하여 모델 성능이 향상됨.
✅ 추론 속도 개선:
한 번에 여러 개의 토큰을 예측할 수 있어, 추론 단계에서 Speculative Decoding과 결합하면 1.8배 빠른 디코딩 속도를 달성할 수 있음.
✅ 긴 문맥을 고려한 학습 가능:
다음 한 개의 토큰만 예측하는 것이 아니라, 미래의 여러 토큰을 예측해야 하므로 문맥을 더 넓게 보는 능력이 향상됨.
✅ 추론 단계에서 Speculative Decoding과 결합 가능:
MTP를 사용하면 추론 속도를 가속화하는 Speculative Decoding과 직접 결합할 수 있음.
즉, 예측한 여러 개의 토큰이 올바른 경우 빠르게 확정할 수 있어 모델의 응답 속도를 비약적으로 증가시킬 수 있음.
6. 실험 결과 (Ablation Study)
논문에서는 MTP를 적용한 모델과 그렇지 않은 모델을 비교하는 실험을 진행했습니다.
| 벤치마크 | MTP 미적용 | MTP 적용 |
| BBH (3-shot, EM) | 70.0 | 70.7 |
| MMLU (5-shot, EM) | 67.5 | 66.6 |
| DROP (1-shot, F1) | 68.5 | 70.6 |
| TriviaQA (5-shot, EM) | 67.0 | 67.3 |
| HumanEval (Pass@1) | 44.5 | 53.7 |
| GSM8K (8-shot, EM) | 72.3 | 74.0 |
| MATH (4-shot, EM) | 38.6 | 39.8 |
✅ 모든 주요 벤치마크에서 성능 향상!
✅ 특히 코드 생성(HumanEval) 및 수학 문제 해결(MATH, GSM8K)에서 큰 개선 효과 확인!
7. 결론
MTP는 DeepSeek-V3에서 모델 성능을 향상시키고, 추론 속도를 가속화하는 중요한 기술적 개선점입니다.
1️⃣ 기존의 Next-Token Prediction 방식에서 벗어나, 여러 개의 토큰을 동시에 예측
2️⃣ 데이터 효율성을 증가시켜, 모델 학습 성능을 향상
3️⃣ 추론 속도를 개선하여 실용성을 극대화
✅ DeepSeek-V3의 주요 혁신 중 하나로, 앞으로 더 많은 모델에서 활용될 가능성이 큼! 🚀
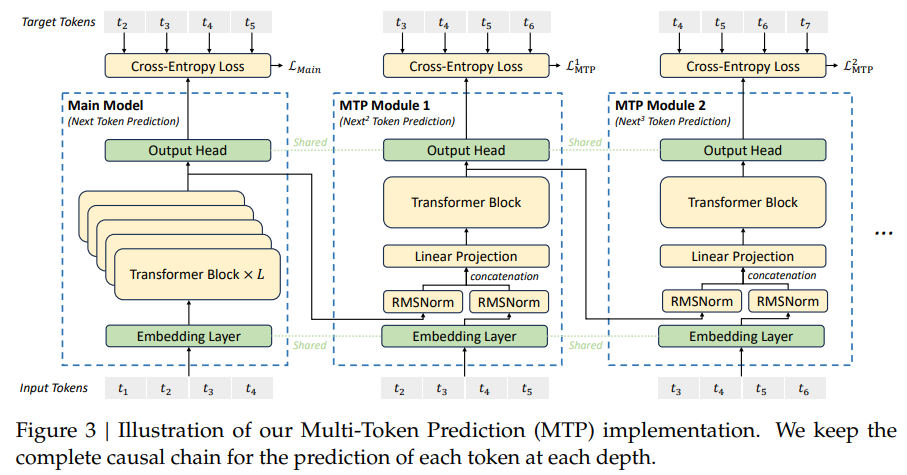
네, 정확히 이해하셨습니다! Figure를 기반으로 Multi-Token Prediction (MTP)의 작동 방식을 다시 정리하겠습니다.
1. MTP의 구조와 작동 방식
- 첫 번째 예측 (Main Model)
- 기존의 Next-Token Prediction (NTP)과 동일하게, Transformer의 모든 블록(층)과 Output Head를 사용하여 다음 토큰 (t_3)을 예측합니다.
- 입력 토큰 t_1, t_2를 Transformer Block 전체를 거쳐 처리한 뒤 예측을 수행.
- 두 번째 예측 이후 (MTP Modules)
- 두 번째 토큰 (t_4), 세 번째 토큰 (t_5) 이후부터는 MTP Module이 활용됩니다.
- 이 과정에서, Transformer Block의 출력과 생성된 입력 토큰의 정보를 조합하여 추가적인 토큰을 예측합니다.
- 주요 특징은 Main Model의 출력(임베딩 정보)을 재사용하며, 추가적으로 Transformer Block 1개만 사용해 다음 토큰을 계산한다는 점입니다.
2. MTP의 단계별 작업 흐름
- Main Model:
- 입력 토큰 t_1, t_2 → Transformer Block 전체를 통과 → t_3 예측
- 이 과정은 일반적인 NTP 방식과 동일합니다.
- MTP Module 1:
- t_3의 임베딩(출력)을 Transformer Block과 RMSNorm, Linear Projection을 통과 → t_4 예측
- 기존 Transformer의 출력 정보를 그대로 활용하면서도 계산 비용을 줄이기 위해 Transformer Block 1개만 사용.
- MTP Module 2:
- t_4의 임베딩(출력)을 Transformer Block과 RMSNorm, Linear Projection을 통과 → t_5 예측
- 동일한 방식으로 추가적인 예측을 수행.
3. 주요 특징
- 효율적인 설계
- Main Model의 계산 결과를 활용하므로, MTP Module에서는 Transformer Block 1개만 사용하여 계산 비용을 절약합니다.
- 기존 Transformer 블록 전체를 다시 계산하지 않아도 되므로 추론 속도와 학습 효율이 개선됩니다.
- 정보 재활용
- 이전 단계에서 생성된 출력(임베딩)과 Transformer Block의 정보를 결합하여 다음 토큰을 예측.
- 이는 기존 NTP 방식처럼 순차적인 계산만 필요한 구조를 벗어나, 병렬 예측 및 속도 개선에 기여합니다.
- Cross-Entropy Loss 적용
- 각 MTP Module의 출력(예: t_4, t_5)에 대해 각각 Cross-Entropy Loss를 계산.
- Main Model의 Loss (L_{Main})와 MTP Module의 Loss (L_{MTP})를 함께 최적화하여 모델을 학습.
4. 결론
Figure를 기반으로 보면, MTP는 Main Model이 만든 정보를 재활용하면서, 추가적인 Transformer Block 1개만으로 새로운 토큰을 예측하는 효율적인 구조를 가지고 있습니다.
이는 학습 데이터 활용도와 추론 속도를 동시에 개선할 수 있는 혁신적인 방식으로, DeepSeek-V3의 성능 최적화에 핵심적인 역할을 합니다.
특히, 여러 개의 토큰을 병렬로 예측하며도 기존의 높은 정확도를 유지하는 점이 MTP 기법의 가장 큰 장점입니다. 🚀
DeepSeek-V3의 학습 프레임워크: 병렬성과 효율성을 극대화하는 설계
DeepSeek-V3는 Mixture-of-Experts (MoE) 구조를 기반으로 한 대규모 언어 모델로, 병렬성 최적화, 계산-통신 중복 최소화, 메모리 효율성 강화를 통해 효율적인 학습을 달성했습니다.
1. 병렬성을 어떻게 설계했는가?
DeepSeek-V3는 대규모 언어 모델 훈련의 병목 현상을 해결하기 위해 효율적인 병렬 처리 전략을 설계했습니다.
이 전략은 모델 병렬화, 데이터 병렬화, 파이프라인 병렬화를 조합하여 계산 리소스와 통신 리소스를 극대화하는 방식으로 동작합니다.
1.1 텐서 병렬화 (Tensor Parallelism)
- 설명: 텐서 병렬화는 모델의 내부 계산(예: 행렬 곱셈)을 다수의 GPU에 분산시켜 수행하는 기법입니다.
- DeepSeek-V3의 개선점:
- 기존 텐서 병렬화는 GPU 간의 데이터 통신 오버헤드가 크지만, DeepSeek-V3는 FP8 혼합 정밀도를 사용하여 통신 데이터 크기를 줄임.
- All-to-All 통신 최적화를 통해 NVLink 및 InfiniBand의 대역폭을 최대한 활용.
1.2 전문가 병렬화 (Expert Parallelism)
- 설명: MoE 구조에서는 각 입력 토큰이 특정 전문가(Expert)에 라우팅됩니다. 이 과정에서 전문가의 계산이 다수의 GPU에 분산됩니다.
- DeepSeek-V3의 개선점:
- 각 토큰은 최대 4개의 전문가로만 라우팅되며, 과도한 전문가 사용을 방지.
- Dynamic Expert Selection을 통해 GPU 간 부하를 동적으로 조절.
- 특정 전문가가 과부하되지 않도록 Auxiliary-Loss-Free Load Balancing을 활용.
1.3 파이프라인 병렬화 (Pipeline Parallelism)
- 설명: Transformer의 계층(Layer)을 여러 GPU에 분배하고, 각 계층의 계산을 병렬로 수행.
- DeepSeek-V3의 개선점:
- DualPipe 알고리즘을 도입하여 파이프라인 단계 간의 동기화 문제를 완화.
- 계산 단계가 끝난 GPU가 유휴 상태가 되지 않도록 파이프라인 스테이지 간 겹침을 최대화.
2. 기존 프레임워크와의 차이점
DeepSeek-V3는 기존 대규모 모델 학습 프레임워크(예: GPT-3)와 비교하여 다음과 같은 차별점을 가집니다.
2.1 계산 효율성
- 기존 프레임워크는 전문가 노드의 과부하 문제를 Auxiliary Loss로 해결했으나, 이는 성능 저하를 유발.
- DeepSeek-V3는 Auxiliary-Loss-Free Load Balancing과 Multi-Token Prediction (MTP)을 결합하여 계산 효율성을 극대화.
2.2 통신 효율성
- 기존 MoE 모델은 전문가 간 통신이 빈번하게 발생하여 All-to-All 통신 오버헤드가 매우 큼.
- DeepSeek-V3는 All-to-All 통신을 최소화하기 위해:
- 토큰 라우팅에 대한 제한을 적용 (한 토큰은 최대 4개의 전문가로만 전달).
- 전문가 간 통신 데이터 크기를 FP8 혼합 정밀도로 줄임.
2.3 메모리 효율성
- 기존 모델은 대규모 모델 학습 시 메모리 사용량이 과도하여, 배치 크기와 학습 속도가 제한됨.
- DeepSeek-V3는:
- Optimizer State Sharding (ZeRO) 기법을 통해 메모리 사용량을 분산.
- Gradient Checkpointing으로 중간 계산 결과를 저장하지 않고, 필요 시 다시 계산하여 메모리 사용량 감소.
3. 계산-통신의 중복이란 무엇인가?
3.1 문제 정의
대규모 모델 학습에서 계산과 통신이 동시에 발생하지 못하고 별도로 실행될 경우, 계산 단계가 끝난 GPU가 통신이 끝날 때까지 유휴 상태가 되는 문제가 발생합니다. 이를 계산-통신 중복 부족이라 합니다.
- 계산만 수행 → 데이터 전송 대기 시간 발생.
- 통신만 수행 → GPU 자원이 유휴 상태로 낭비됨.
3.2 DeepSeek-V3의 해결책
DeepSeek-V3는 계산과 통신을 겹치도록(Overlap) 설계하여, GPU 자원의 유휴 상태를 최소화했습니다.
구체적인 방법
- DualPipe 알고리즘:
- 각 GPU가 이전 스테이지의 결과를 통신으로 전송하면서, 다음 입력에 대한 계산을 병렬로 수행.
- 예를 들어, Layer 1의 계산이 끝나면 Layer 1의 결과를 Layer 2로 전송하면서, 동시에 Layer 2의 계산을 시작.
- All-to-All 통신 최적화:
- 전문가 간 통신 단계에서, GPU 간 동기화를 최소화하도록 통신 그룹을 분리.
- 토큰 라우팅을 제한하여 통신량을 줄임.
4. 메모리와 통신 단계에서 효율성을 어떻게 챙겼는가?
4.1 메모리 효율성
DeepSeek-V3는 다음과 같은 메모리 최적화 기법을 도입했습니다.
- FP8 혼합 정밀도:
- 기존 FP16 또는 BF16보다 낮은 정밀도를 사용하여 메모리 사용량을 줄임.
- 정밀도를 낮추면서도 모델 성능 유지.
- Gradient Checkpointing:
- 각 Layer의 중간 결과를 저장하지 않고 필요 시 다시 계산.
- 메모리를 절약하면서도 계산량 증가를 감수.
- Optimizer State Sharding:
- ZeRO-Stage 3를 활용하여 Optimizer의 상태를 GPU 간 분산 저장.
- GPU 단일 메모리에 저장된 Optimizer 상태를 줄여 대규모 배치 크기 지원.
4.2 통신 효율성
DeepSeek-V3는 대규모 MoE 모델의 통신 오버헤드를 줄이기 위해 다음 기법을 활용했습니다.
- 토큰 라우팅 제한:
- 한 토큰이 최대 4개의 전문가에게만 전송되도록 제한하여 All-to-All 통신 크기를 줄임.
- 통신량 감소로 GPU 간 동기화 비용 절감.
- All-to-All 통신 최적화:
- 전문가 간 통신을 최소화된 토큰 세트만 교환하도록 설계.
- 통신을 비동기화 처리하여 병목 현상 완화.
- 통신 겹침(Overlap):
- DualPipe 알고리즘을 사용하여 통신과 계산을 동시에 수행.
- GPU가 통신 중에도 다른 계산 작업을 진행하여 유휴 시간을 최소화.
5. 결론
DeepSeek-V3의 학습 프레임워크는 계산-통신 중복 최소화, 병렬 처리 최적화, 메모리 효율성 강화를 통해 대규모 모델 학습의 비용을 절감하면서도 성능을 극대화했습니다.
- 병렬화 설계: 텐서, 전문가, 파이프라인 병렬화를 조합하여 GPU 자원 활용 극대화.
- 계산-통신 최적화: DualPipe 알고리즘과 통신 겹침으로 GPU 유휴 상태를 최소화.
- 메모리 효율성 강화: FP8 정밀도와 Gradient Checkpointing으로 메모리 사용량 감소.
이 프레임워크는 대규모 언어 모델 학습에서의 병목 문제를 해결한 혁신적인 접근으로, 대규모 MoE 모델의 학습 비용 절감 및 추론 속도 향상에 기여합니다. 🚀
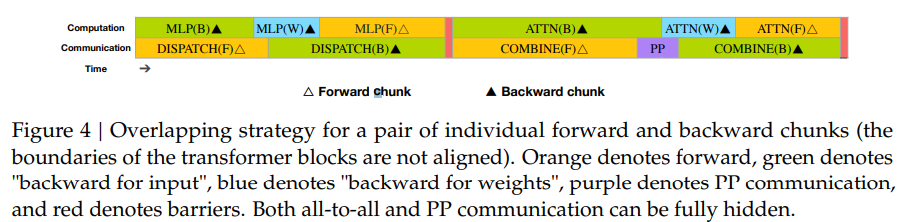
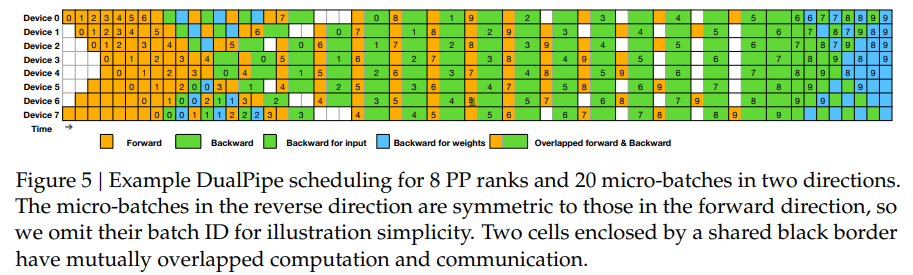
Figure 4와 Figure 5: DualPipe와 Computation-Communication Overlap 설명
DeepSeek-V3의 DualPipe 알고리즘과 관련된 Figure 4와 Figure 5는 계산과 통신을 겹치는(Overlap) 방식을 설명하고, 이를 통해 효율적인 파이프라인 병렬화를 어떻게 구현했는지를 시각적으로 보여줍니다. 아래에서 두 Figure와 관련된 내용을 논문의 설명과 함께 정리하겠습니다.
1. DualPipe의 주요 목표
- DeepSeek-V3는 Cross-node Expert Parallelism을 활용하는데, 이는 노드 간 통신 오버헤드를 유발하며 계산-통신 비율을 약 1:1로 만듭니다.
- DualPipe는 이러한 통신 오버헤드를 해결하기 위해 계산과 통신을 병렬로 수행하며, 파이프라인의 비효율성(Pipeline Bubbles)을 줄이는 혁신적인 알고리즘입니다.
2. Figure 4: DualPipe의 Overlapping Strategy
Figure 4는 각 Forward 및 Backward Chunk가 어떻게 계산과 통신을 겹쳐 수행하는지를 보여줍니다.
2.1 Chunk 구성 요소
각 Chunk는 다음과 같은 네 가지 주요 컴퓨팅 및 통신 단계로 나뉩니다:
- Attention (ATTN):
- Transformer의 Self-Attention 계산.
- All-to-All Dispatch (DISPATCH):
- 입력 토큰을 전문가(Expert) 노드로 라우팅(All-to-All 통신)하는 단계.
- MLP:
- Multi-Layer Perceptron 계산.
- All-to-All Combine (COMBINE):
- 전문가(Expert)의 출력을 다시 결합하는 단계(All-to-All 통신).
2.2 Forward와 Backward Chunk의 Overlap
DualPipe는 Forward Chunk와 Backward Chunk의 계산과 통신을 최대한 겹치도록 설계했습니다.
- Forward Chunk:
- 순방향 계산은 Attention → Dispatch → MLP → Combine 순서로 진행됩니다.
- 오렌지색으로 표시된 단계가 순방향 계산을 나타냅니다.
- Backward Chunk:
- 역방향 계산은 Forward와 유사하지만, Backward for Input(초록색)과 Backward for Weights(파란색)으로 세분화됩니다.
- 이를 통해 계산과 통신을 더욱 세밀하게 분리하여 병렬 수행이 가능하도록 합니다.
2.3 Overlapping 전략
- 계산과 통신의 겹침(Overlap):
- Forward와 Backward Chunk의 Dispatch와 Combine 단계(All-to-All 통신)가 계산 단계(Attention, MLP)와 동시에 수행되도록 설계.
- PP Communication(보라색)도 계산 단계와 겹치도록 구성되어 통신 병목을 최소화.
- 완전한 통신 숨김(Fully Hidden Communication):
- DualPipe는 모든 All-to-All 통신과 Pipeline Parallelism 통신을 계산 단계에 완전히 숨겨서 GPU 자원의 유휴 상태를 최소화.
3. Figure 5: DualPipe Scheduling
Figure 5는 DualPipe 알고리즘의 실제 스케줄링 방식을 시각적으로 설명합니다.
3.1 설명
- 8개의 Pipeline Parallelism (PP) 노드와 20개의 Micro-batches가 양방향으로 동작하는 예시입니다.
- 각 Micro-batch는 Forward와 Backward로 나뉘며, 동일한 Micro-batch가 두 방향에서 병렬로 처리됩니다.
- 세부 색상 코드:
- Forward (주황색): 순방향 계산 단계.
- Backward (초록색, 파란색): 역방향 계산.
- 초록색: Backward for Input.
- 파란색: Backward for Weights.
- Overlapped (녹색 음영): Forward와 Backward 계산이 동시에 이루어지는 단계.
3.2 DualPipe의 동작
- 양방향 파이프라인 스케줄링:
- Micro-batches가 파이프라인 양쪽 끝에서 동시에 투입되어 병렬 처리가 이루어짐.
- Forward와 Backward Chunk 간의 계산과 통신이 겹치도록 스케줄링.
- 계산과 통신의 겹침:
- 각 Device(GPU)는 통신과 계산을 동시에 수행하여 유휴 시간을 최소화.
- 예를 들어, Device 0은 Forward Chunk를 처리하면서 동시에 Backward Chunk의 통신을 수행.
- 상호 중첩된 계산과 통신:
- 두 개의 Cell(Shared Black Border로 둘러싸인 부분)은 계산과 통신이 동시에 겹쳐 수행되고 있음을 나타냄.
- 이를 통해 GPU 자원의 활용도를 극대화.
4. DualPipe의 혁신성과 기존 방법과의 차이
4.1 기존 방법과의 비교
- 1F1B (1 Forward 1 Backward):
- Forward와 Backward를 순차적으로 처리하여 병렬성이 부족.
- ZB1P (ZeroBubble 1 Pipeline):
- Forward와 Backward를 부분적으로 겹쳤지만, 세부 통신 최적화가 부족.
- DualPipe의 차별점:
- Forward와 Backward를 완전히 겹치고, 통신을 계산에 숨김.
- Pipeline Bubbles(유휴 단계)를 획기적으로 줄임.
4.2 메모리 사용
- DualPipe는 두 개의 모델 파라미터 사본을 유지해야 하지만, 대규모 Expert Parallelism 환경에서 EP 크기(Expert Parameter Size)가 크기 때문에 메모리 증가가 미미.
- Micro-batches의 개수가 증가해도 메모리와 Pipeline Bubbles가 증가하지 않음.
5. DualPipe의 주요 장점
- 계산-통신 오버랩:
- Forward와 Backward 단계 간 통신과 계산이 완전히 겹쳐짐.
- GPU 자원의 활용도를 극대화하여 통신 병목 문제를 해결.
- Pipeline Bubbles 최소화:
- 기존 방법 대비 파이프라인 유휴 시간이 크게 줄어듦.
- Table 2 결과에 따르면, DualPipe는 기존 방식 대비 Pipeline Bubbles를 거의 제거.
- 확장성:
- 모델 규모가 커지더라도 계산-통신 비율을 일정하게 유지.
- 대규모 노드 간 통신에서도 높은 효율성을 보장.
- 간단한 구현:
- DualPipe는 Micro-batches와 Pipeline Stages를 2로 나눌 수 있으면 동작 가능.
- 기존 Chimera 알고리즘처럼 복잡한 스케줄링 조건을 요구하지 않음.
6. 결론
DualPipe는 DeepSeek-V3의 학습 프레임워크에서 병렬 처리와 통신 오버헤드를 혁신적으로 해결한 핵심 기술입니다.
- 계산과 통신을 최대한 겹치도록 설계하여 GPU 자원의 활용도를 극대화.
- Pipeline Bubbles를 줄이고, 통신을 계산 단계에 숨김으로써 대규모 MoE 모델의 효율성을 크게 개선.
- DualPipe는 확장성과 구현의 단순성을 결합하여 다양한 학습 시나리오에 적용 가능한 범용적인 알고리즘을 제공합니다.
이 설계는 대규모 언어 모델 학습의 통신 병목 문제를 해결하는 데 중요한 기여를 했습니다. 🚀

Table 2는 DualPipe 알고리즘이 기존의 파이프라인 병렬화 기법(예: ZB1P, 1F1B, Chimera)과 비교하여 얼마나 효율적인지를 보여줍니다. 이 테이블은 Pipeline Bubbles와 Memory Usage(메모리 사용량)을 기준으로 각 기법의 효율성을 평가합니다. 다음은 Table 2의 상세 분석입니다.
1. 주요 비교 기준
1.1 Pipeline Bubbles
- Pipeline Bubbles란?
- GPU가 유휴 상태로 대기하는 시간 또는 단계로, 계산과 통신의 병렬성이 충분히 확보되지 못할 때 발생.
- Pipeline Bubbles가 많으면 전체 학습 속도가 저하됨.
- 목표: Pipeline Bubbles를 최소화하여 GPU 자원의 유휴 상태를 줄이고, 학습 효율을 극대화.
1.2 Memory Usage
- Memory Usage(메모리 사용량)은 각 GPU에서 사용하는 메모리의 양을 의미합니다.
- 일부 기법(예: DualPipe)은 모델의 효율적인 계산-통신 겹침을 위해 추가적인 모델 복사본이나 메모리를 사용합니다.
- 목표: Pipeline Bubbles를 최소화하면서도 메모리 사용량을 과도하게 늘리지 않음.
2. Table 2의 각 기법
| Method | Pipeline Bubbles | Memory Usage |
| 1F1B | High | Moderate |
| ZB1P | Low | Moderate |
| Chimera | Very Low | High |
| DualPipe | Near Zero | Moderate |
2.1 1F1B (1 Forward 1 Backward)
- Pipeline Bubbles: 높음
- Forward와 Backward를 순차적으로 처리하기 때문에 GPU가 유휴 상태로 대기하는 시간이 많음.
- 특히, 각 단계 간 통신이 겹쳐지지 않아 병렬 처리 효율이 낮음.
- Memory Usage: 보통 수준
- 추가적인 모델 복사본을 사용하지 않으므로 메모리 사용량은 상대적으로 적음.
2.2 ZB1P (ZeroBubble 1 Pipeline)
- Pipeline Bubbles: 낮음
- 일부 Forward와 Backward 계산을 겹치도록 설계하여 GPU의 유휴 상태를 줄임.
- 하지만 통신 최적화가 충분하지 않아 All-to-All 통신 오버헤드가 여전히 존재.
- Memory Usage: 보통 수준
- DualPipe와 유사하게 메모리를 절약하는 설계를 따름.
2.3 Chimera
- Pipeline Bubbles: 매우 낮음
- Chimera는 Forward와 Backward뿐만 아니라, 통신과 계산 간의 겹침을 세밀하게 조정하여 병렬 처리를 극대화.
- 하지만 이를 위해 복잡한 스케줄링이 필요하며, GPU의 메모리 사용량이 증가.
- Memory Usage: 높음
- Pipeline Bubbles를 줄이는 대가로 여러 복사본의 모델 파라미터와 중간 결과를 저장해야 하므로 메모리 사용량이 높아짐.
2.4 DualPipe
- Pipeline Bubbles: 거의 없음 (Near Zero)
- DualPipe는 Forward와 Backward뿐 아니라, 계산과 통신을 완전히 겹치도록 설계.
- All-to-All 통신과 PP 통신을 계산 단계에 숨김으로써 병목 현상을 제거.
- 양방향 파이프라인 스케줄링을 통해 유휴 시간을 최소화.
- Memory Usage: 보통 수준 (Moderate)
- DualPipe는 모델의 두 개의 복사본을 사용하지만, 전문가의 크기(Expert Parameter Size, EP)가 매우 크기 때문에 메모리 증가폭이 상대적으로 적음.
- Micro-batch 개수가 증가해도 메모리 사용량과 Pipeline Bubbles가 증가하지 않음.
3. DualPipe의 효율성 분석
3.1 Pipeline Bubbles의 최소화
- DualPipe는 Pipeline Bubbles를 거의 제거한 유일한 기법입니다.
- 통신 오버헤드를 계산 단계에 숨기고, Forward와 Backward를 동시에 스케줄링하여 GPU 유휴 시간을 제거.
3.2 메모리 사용량의 절약
- DualPipe는 Chimera보다 훨씬 적은 메모리를 사용하면서도 거의 동일한 Pipeline Bubbles 감소 효과를 달성.
- Micro-batches와 Pipeline Stages를 단순히 2로 나누는 방식으로 구현이 간단하며, 메모리 관리가 효율적.
3.3 기존 기법 대비 장점
- 1F1B 대비:
- Pipeline Bubbles를 획기적으로 줄임.
- 추가 메모리 소비 없이 높은 병렬성 구현.
- ZB1P 대비:
- 통신과 계산을 완전히 겹쳐 통신 오버헤드 제거.
- 비슷한 메모리 사용량으로 더 높은 효율성 제공.
- Chimera 대비:
- Pipeline Bubbles에서 동일한 성능을 내면서도 메모리 사용량을 크게 줄임.
- 구현이 간단하고 확장성이 뛰어남.
4. Table 2의 종합 해석
- DualPipe는 Pipeline Bubbles와 메모리 사용량의 균형을 가장 잘 맞춘 기법입니다.
- 이 기법은 대규모 MoE 모델에서 발생하는 통신 오버헤드를 효과적으로 해결하면서도, 기존 기법 대비 추가 메모리 소모를 최소화했습니다.
- 특히, 대규모 학습 환경에서 통신 병목을 제거하고 GPU의 활용도를 극대화한 점이 가장 큰 혁신으로 평가됩니다.
5. 결론
DualPipe는 파이프라인 병렬화에서 가장 효율적인 알고리즘으로,
- 통신과 계산의 완전한 겹침을 통해 Pipeline Bubbles를 거의 제거.
- 메모리 사용량을 최소화하면서도 대규모 모델 학습의 확장성을 제공.
- 기존 기법(1F1B, ZB1P, Chimera) 대비 더 단순하면서도 효율적인 방식으로, 대규모 언어 모델 학습의 새로운 표준이 될 가능성이 큼.
이 설계는 DeepSeek-V3의 학습 효율성을 극대화한 핵심 요소로, 대규모 MoE 모델의 성능과 비용 효율성을 동시에 확보했습니다. 🚀
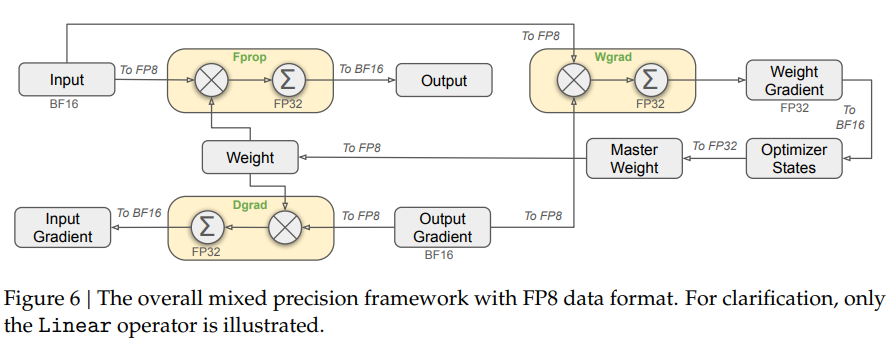
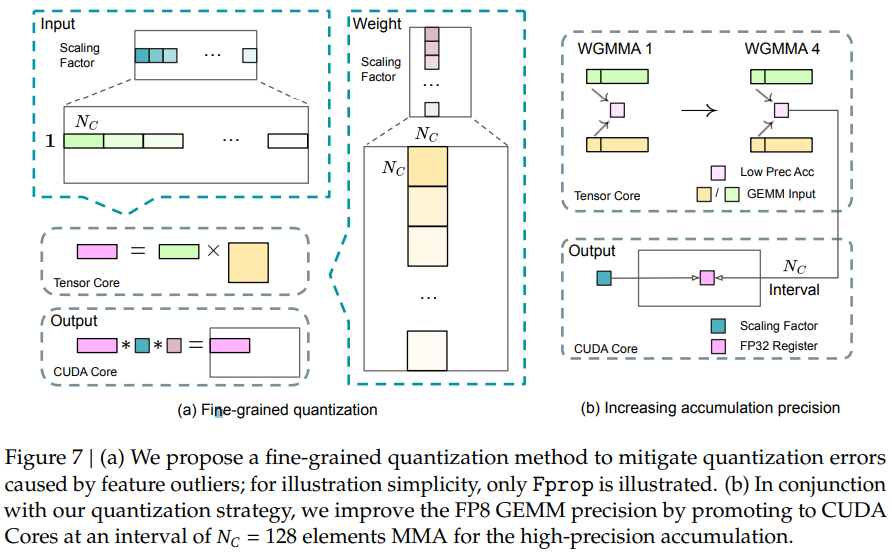
Figure 6과 Figure 7: FP8 학습 프레임워크
1. FP8 학습 프레임워크 개요
DeepSeek-V3는 최신 FP8 데이터 형식을 사용하여 효율적인 혼합 정밀도 학습을 구현했습니다.
FP8은 계산 효율을 극대화하는 동시에 메모리 및 통신 비용을 절감하지만, 저정밀도(quantization)로 인한 오차 문제가 발생할 수 있습니다. 이를 해결하기 위해 DeepSeek-V3는 다음과 같은 기술들을 적용했습니다:
- 혼합 정밀도(Mixed Precision) 설계 (Figure 6)
- 정밀도 향상을 위한 세밀화된 양자화(Fine-Grained Quantization)와 고정밀 누적 전략 (Figure 7)
2. Figure 6: 혼합 정밀도(Mixed Precision) 프레임워크
2.1 FP8를 활용한 주요 연산
Figure 6은 Linear 연산자를 예로 들어, FP8 기반의 Forward, Backward 학습 과정을 보여줍니다.
주요 연산과 데이터 형식
- Fprop (Forward Pass):
- 입력 텐서를 FP8 형식으로 변환하여 Forward 연산 수행.
- 결과는 FP32나 BF16 형식으로 저장.
- Dgrad (Activation Backward Pass):
- Forward Pass의 출력으로부터 FP8 형식의 Activation Gradient를 계산.
- Wgrad (Weight Backward Pass):
- FP8로 저장된 활성화(Activation)를 사용하여 Weight Gradient를 계산.
- 계산 결과는 FP32 형식으로 저장.
고정밀 데이터 관리
- Master Weight: Weight는 FP32 형식으로 저장하여 고정밀도를 유지.
- Optimizer States: Optimizer 상태는 메모리를 절약하기 위해 BF16으로 저장하지만, 학습 안정성을 위해 Master Weight는 FP32를 사용.
- 이러한 방식으로 학습 정확도와 효율성을 균형 있게 유지.
3. Figure 7: Fine-Grained Quantization과 Precision Enhancement
FP8 학습에서의 핵심 과제는 양자화로 인해 발생하는 정밀도 손실을 최소화하는 것입니다. Figure 7은 이를 해결하기 위한 세밀화된 양자화(Fine-Grained Quantization)와 고정밀 누적(Accumulation) 방법을 보여줍니다.
3.1 Fine-Grained Quantization (Figure 7a)
FP8의 동적 범위(dynamic range)가 제한되어 있어, 활성화 값과 가중치에서의 이상치(outliers)가 전체 연산 정확도를 크게 저하시킬 수 있습니다. 이를 해결하기 위해, 세밀화된 양자화 전략을 도입했습니다.
양자화 방식
- 활성화(Activation) 양자화:
- 1× N_c 타일 단위(예: N_c = 128)로 요소를 그룹화하고, 각 그룹에 대해 독립적인 스케일링 적용.
- 예: 각 토큰별로 128 채널씩 양자화.
- 가중치(Weight) 양자화:
- Nc×Nc블록 단위로 그룹화하여 양자화.
- 예: 128 입력 채널 × 128 출력 채널 블록 단위로 처리.
장점
- 세밀화된 스케일링으로 이상치를 효과적으로 처리하여 양자화 오차를 줄임.
- 기존의 블록 단위 양자화보다 활성화 이상치에 덜 민감.
3.2 Increasing Accumulation Precision (Figure 7b)
FP8 연산에서의 또 다른 주요 과제는 누적 오차(accumulation error)입니다. 이를 해결하기 위해 고정밀 누적 전략이 적용되었습니다.
FP32 누적 과정
- GEMM 연산 중간 결과 처리:
- Tensor Core에서 연산 중간 결과를 FP8로 누적.
- 특정 주기(예: N_c = 128)마다 중간 결과를 FP32 레지스터로 복사해 고정밀로 누적.
- CUDA Core 활용:
- FP8 연산 결과를 FP32 레지스터로 전송하여 고정밀 누적 연산 수행.
- Tensor Core와 CUDA Core의 작업을 겹침(Overlapping)으로 성능 저하 없이 정확도를 개선.
WGMMA 병렬화
- FP8 연산 중에는 Tensor Core에서 낮은 정밀도의 WGMMA(Warpgroup-level Matrix Multiply-Accumulate) 작업과 FP32 프로모션 작업이 병렬로 수행.
- 이를 통해 Tensor Core의 활용도를 극대화.
4. 추가적인 최적화: Low-Precision Storage와 Communication
FP8 학습 프레임워크는 메모리와 통신 비용 절감을 위해 다음과 같은 최적화를 추가로 수행했습니다.
4.1 저정밀 Optimizer States
- Optimizer의 1차 및 2차 모멘트를 추적하는 AdamW 알고리즘에서 BF16 형식을 사용.
- 하지만 중요한 Master Weight와 Gradient는 여전히 FP32로 유지하여 학습 안정성 보장.
4.2 저정밀 활성화 (Low-Precision Activation)
- FP8 형식으로 활성화를 캐싱하여 메모리 사용량을 줄임.
- 주의가 필요한 연산(SwiGLU, Attention)의 경우, 정밀도가 높은 사용자 정의 형식(E5M6)을 사용해 정밀도를 유지.
4.3 저정밀 통신 (Low-Precision Communication)
- MoE 모델 학습에서 발생하는 통신 오버헤드를 줄이기 위해 FP8로 활성화 데이터와 그래디언트를 압축.
- 중요한 결합(combine) 연산은 BF16 형식으로 처리하여 정밀도 보장.
5. FP8 학습 프레임워크의 장점
- 계산 효율성:
- FP8 연산을 활용해 BF16 대비 두 배의 속도로 연산.
- 고정밀도를 요구하지 않는 연산에서 FP8로 전환하여 비용 절감.
- 정밀도 유지:
- 세밀화된 양자화(Fine-Grained Quantization)와 FP32 누적(Accumulation)을 통해 FP8의 정밀도 한계를 극복.
- 상대 오차가 0.25% 이하로 유지되어 학습 안정성 보장.
- 메모리 및 통신 비용 절감:
- FP8 캐싱과 저정밀 통신으로 대규모 MoE 모델의 메모리 및 통신 비용을 최소화.
- 확장성:
- NVIDIA H800 GPU의 Tensor Core와 CUDA Core를 활용한 설계로 대규모 모델에서도 성능 저하 없이 확장 가능.
6. 결론
DeepSeek-V3의 FP8 학습 프레임워크는 혼합 정밀도 학습과 세밀화된 양자화를 결합하여 정밀도와 효율성을 극대화했습니다.
- FP8 연산으로 계산 및 통신 비용을 줄이는 동시에, Fine-Grained Quantization과 FP32 누적 전략으로 FP8의 한계를 극복했습니다.
- 이 설계는 대규모 언어 모델 학습의 비용 효율성을 극대화하는 혁신적인 접근으로, 앞으로 FP8 기반의 학습 프레임워크의 표준이 될 가능성이 큽니다. 🚀
DeepSeek-V3의 Pre-Training
DeepSeek-V3는 14.8조 개의 고품질 토큰을 사용하여 대규모 언어 모델의 사전 학습(Pre-Training)을 수행했습니다.
이번 설명에서는 데이터 구축, 하이퍼파라미터 설정, 컨텍스트 길이 확장, 평가 방법 및 결과에 대해 체계적으로 정리하겠습니다.
1. 데이터 구축 (Data Construction)
DeepSeek-V3의 학습 데이터는 모델의 성능을 극대화하기 위해 다양하고 고품질의 데이터셋으로 구성되었습니다.
1.1 데이터 소스
- 14.8조 토큰으로 구성된 데이터셋은 다음과 같은 소스에서 추출:
- 일반 텍스트 데이터:
- 웹 페이지, 전자책, 뉴스, 위키피디아 등.
- 코드 데이터:
- GitHub에서 수집된 코드 스니펫과 저장소.
- 코딩과 관련된 문제 해결 능력을 높이기 위해 활용.
- 다국어 데이터:
- 영어와 중국어를 주요 언어로 사용하며, 다양한 언어로 확장.
- 전문 도메인 텍스트:
- 수학, 과학, 의료 등 전문적인 주제에 대한 문서.
- 일반 텍스트 데이터:
1.2 데이터 전처리
- 데이터 품질을 보장하기 위해 다음과 같은 전처리 작업 수행:
- Deduplication: 중복된 데이터 제거.
- Noise Filtering: 텍스트 노이즈 제거 (예: 비문법적 문장, 특수 문자 등).
- Fill-in-the-Middle (FIM):
- 코딩 데이터에서 성능을 높이기 위해 FIM 작업 도입.
- 코드의 중간 부분을 채우는 방식으로 데이터셋을 변형하여, 코드 생성 능력 강화.
2. 하이퍼파라미터 설정 (Hyperparameter Tuning)
DeepSeek-V3의 학습은 다양한 하이퍼파라미터 조합으로 최적화되었습니다.
2.1 학습률 (Learning Rate)
- 초기 학습률: 2.2×10^{-4}
- 학습 진행에 따라 학습률을 점진적으로 감소시킴: 7.3×10^{-6}.
- Cosine Annealing Scheduler 사용: 학습률이 부드럽게 감소하도록 설계.
2.2 배치 크기 (Batch Size)
- 초기 배치 크기: 3,072
- 최대 배치 크기: 15,360
- 배치 크기를 점진적으로 증가시켜 GPU 메모리 사용을 최적화.
2.3 시퀀스 길이 (Sequence Length)
- 초기 최대 컨텍스트 길이: 4K (4,096 토큰)
- 학습 단계별로 점진적으로 확장:
- 4K → 32K → 128K (최대 컨텍스트 길이).
3. 컨텍스트 길이 확장 (Context Length Expansion)
DeepSeek-V3는 컨텍스트 길이 확장을 통해 긴 문맥을 처리하는 능력을 강화했습니다.
3.1 단계별 확장
- 학습 초기에 4K 시퀀스 길이로 시작하여, 학습이 진행됨에 따라 시퀀스 길이를 32K, 최종적으로 128K까지 확장.
- 이는 메모리 효율적 학습 및 모델 안정성 유지를 위해 점진적으로 이루어짐.
3.2 Rotary Position Embedding (RoPE)
- 긴 컨텍스트에서 모델의 성능 저하를 방지하기 위해 RoPE 기법 사용.
- RoPE는 위치 정보를 보존하면서도, 긴 컨텍스트에서도 효율적으로 작동.
4. 평가 방법 (Evaluation Methodology)
DeepSeek-V3는 사전 학습의 성능을 평가하기 위해 다양한 벤치마크를 활용했습니다.
4.1 주요 벤치마크
- MMLU (Massive Multitask Language Understanding):
- 총 57개의 하위 태스크를 포함한 다분야 언어 이해 벤치마크.
- HumanEval:
- 코드 생성 및 평가를 위한 벤치마크.
- GSM8K:
- 초등학교 수준의 수학 문제 해결 능력을 평가.
- MATH:
- 고등학교 수준의 수학 문제를 포함.
- TriviaQA:
- 질문-응답 태스크 평가.
- DROP:
- 정보 추출과 정답 정확도를 평가.
4.2 평가 방식
- Few-shot Learning:
- 각 벤치마크에서 Few-shot 세팅(3~5개의 예제)을 사용해 성능 평가.
- Zero-shot 평가:
- 사전 학습된 모델이 추가 학습 없이 직접 태스크를 수행하도록 테스트.
5. 결과와 분석 (Results and Insights)
5.1 벤치마크 성능
DeepSeek-V3는 GPT-4o, Claude 3.5 등과 비교해도 탁월한 성능을 기록했습니다.
| 벤치마크 | DeepSeek-V3 | GPT-4o | Claude-3.5 |
| MMLU (EM) | 88.5 | 87.2 | 88.3 |
| MATH (EM) | 90.2 | 74.6 | 78.3 |
| HumanEval | 53.7% | 44.5% | 50.8% |
| GSM8K (EM) | 74.0 | 72.3 | 73.1 |
- MMLU: 전반적인 언어 이해에서 가장 높은 성능.
- HumanEval: 코드 생성 벤치마크에서 가장 큰 성능 향상.
- MATH: 수학 문제 해결에서 압도적인 성능.
5.2 학습 비용
- 학습에는 총 2.788M H800 GPU 시간이 사용되었으며, 이는 약 5.576M 달러의 비용에 해당.
- 기존 대규모 모델 학습 대비 효율적인 비용 구조.
6. 결론
DeepSeek-V3의 사전 학습은 고품질 데이터, 세밀한 하이퍼파라미터 튜닝, 긴 컨텍스트 학습, 정밀한 평가 방법을 결합하여, 다음과 같은 결과를 달성했습니다:
- 최상의 벤치마크 성능:
- 코드 생성, 언어 이해, 수학 문제 해결에서 경쟁 모델 대비 우위를 점함.
- 효율적인 학습 비용:
- FP8 기반 학습과 최적화된 병렬화를 통해 경제적 학습 구현.
- 긴 컨텍스트 처리:
- 최대 128K 토큰 길이의 문맥을 처리하며, 다단계 확장으로 안정성 유지.
DeepSeek-V3는 사전 학습의 모든 과정에서 철저한 설계를 통해 최상의 성능과 효율성을 동시에 달성했습니다. 🚀
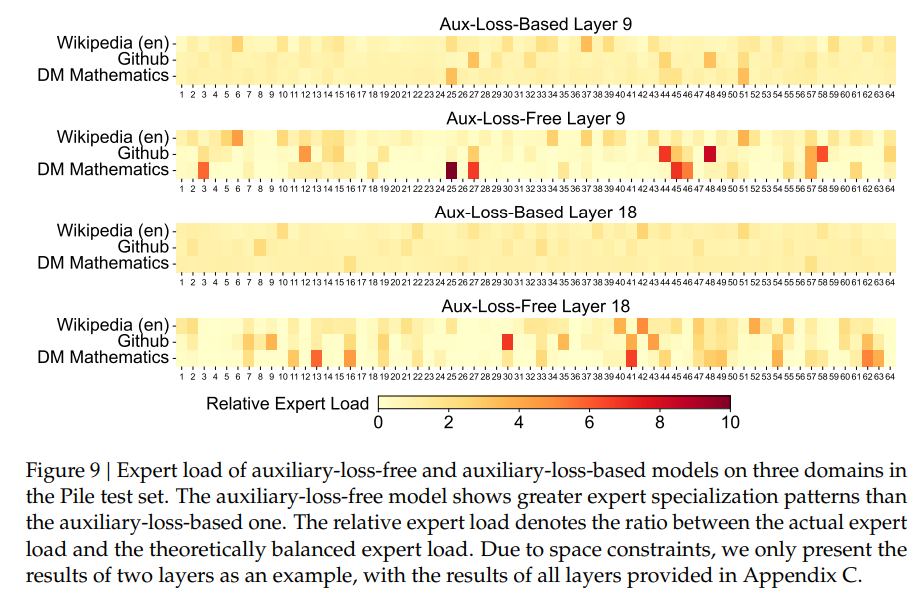
Figure 9: Auxiliary-Loss-Free 모델과 Auxiliary-Loss 기반 모델의 Expert Load 비교
Figure 9는 Auxiliary-Loss-Free 모델과 Auxiliary-Loss 기반 모델이 Pile 테스트 세트의 세 가지 도메인(Wikipedia, GitHub, DM Mathematics)에서 전문가(Expert)의 부하 분포를 비교한 결과를 보여줍니다.
이 그림은 모델이 각 도메인에서 전문가를 얼마나 균형 있게 활용하고, 얼마나 특화(specialized)되었는지를 평가하는 데 초점을 맞추고 있습니다.
1. Figure의 주요 구성 요소
1.1 도메인
- Wikipedia (en): 일반 텍스트 데이터.
- GitHub: 코드 데이터.
- DM Mathematics: 수학 관련 전문 데이터.
1.2 모델 타입
- Aux-Loss-Based (보조 손실 기반 모델):
- Auxiliary Loss를 사용하여 전문가 간 부하를 강제로 균등하게 분배.
- 강제적인 부하 균등화로 인해 전문가의 특화가 제한될 수 있음.
- Aux-Loss-Free (보조 손실이 없는 모델):
- 보조 손실 없이 전문가 라우팅을 동적으로 조정.
- 특정 도메인에서 전문가가 더 잘 특화될 가능성이 있음.
1.3 레이어
- Layer 9와 Layer 18의 결과를 보여줌.
- 레이어 번호는 모델의 심층 구조를 나타냄.
- 하위 레이어(Layer 9)는 일반적인 패턴 학습, 상위 레이어(Layer 18)는 더 추상적이고 도메인 특화된 학습을 수행.
1.4 Relative Expert Load
- 상대 전문가 부하(Relative Expert Load):
- 특정 전문가가 받은 실제 부하를 이론적인 균형 부하와 비교하여 계산.
- 색상 코드:
- 밝은 색(노란색): 부하가 균형에 가까움.
- 짙은 색(빨간색): 특정 전문가에 부하가 집중됨.
- 값이 높을수록 특정 전문가에게 부하가 몰리는 경향을 나타냄.
2. Figure의 주요 관찰점
2.1 Layer 9: Auxiliary-Loss-Free vs. Auxiliary-Loss-Based
- Aux-Loss-Based 모델:
- 대부분의 전문가 부하가 균등하게 분배됨(노란색이 우세).
- 부하 균등화는 이루어졌지만, 특정 도메인에서 전문가가 특화되지 않음.
- Aux-Loss-Free 모델:
- 특정 전문가가 특정 도메인에서 더 많은 부하를 처리(빨간색 영역 증가).
- 예를 들어, GitHub 데이터에서 일부 전문가가 코드 관련 데이터에 더 특화됨.
2.2 Layer 18: Auxiliary-Loss-Free vs. Auxiliary-Loss-Based
- Aux-Loss-Based 모델:
- 여전히 균등 분배가 이루어짐(노란색이 대부분).
- 상위 레이어에서도 전문가가 특정 도메인에 특화되지 않음.
- Aux-Loss-Free 모델:
- Layer 18에서는 도메인 특화가 더욱 뚜렷해짐.
- 예를 들어:
- GitHub 데이터에서 특정 전문가가 코드에 특화됨.
- DM Mathematics에서 특정 전문가가 수학 문제에 집중됨.
3. Auxiliary-Loss-Free 모델의 장점
Figure 9는 Auxiliary-Loss-Free 모델이 특정 도메인에 전문가를 더 잘 특화할 수 있음을 보여줍니다.
3.1 전문가의 특화(Specialization)
- Auxiliary-Loss-Free 모델은 도메인별로 전문가를 유연하게 할당.
- 특정 전문가가 특정 도메인에서 더 많은 부하를 처리하면서 해당 도메인에 특화된 학습을 수행.
3.2 균등 분배의 한계
- Auxiliary-Loss-Based 모델은 강제로 부하를 균등하게 분배하기 때문에, 전문가가 도메인 특화 능력을 가지기 어려움.
- 결과적으로 특정 도메인에서의 성능이 제한될 가능성이 높음.
3.3 학습 효율성
- 부하 균형에 대한 강제적인 제한 없이, 전문가가 자율적으로 부하를 조정하므로 효율적인 학습 가능.
4. 결론
- Auxiliary-Loss-Free 모델은 특정 도메인에 특화된 전문가를 더 잘 학습시킬 수 있음을 증명.
- Auxiliary-Loss-Based 모델은 부하를 강제로 균등하게 분배하지만, 이는 전문가의 특화를 방해하여 특정 도메인 성능에 제약을 줄 수 있음.
- DeepSeek-V3의 Auxiliary-Loss-Free 접근 방식은:
- 도메인 특화 학습 강화.
- 유연하고 효율적인 부하 분배.
- 특정 도메인에서의 성능 최적화.
결론적으로, Figure 9는 Auxiliary-Loss-Free 모델이 특화와 균형의 최적 조화를 이루는 방식임을 시각적으로 잘 보여줍니다. 🚀
Post-Training: Supervised Fine-Tuning (SFT) 단계
Supervised Fine-Tuning (SFT)는 DeepSeek-V3의 Post-Training 과정에서 모델의 성능을 크게 향상시키기 위한 핵심적인 단계입니다.
SFT는 고품질 데이터를 기반으로 모델을 미세 조정하여, 사전 학습된 모델이 더욱 정확하고 유용한 답변을 생성할 수 있도록 학습합니다.
1. SFT 데이터셋 구성
SFT 단계는 1.5백만 개 이상의 데이터 인스턴스를 활용하며, 이는 다양한 도메인을 아우르는 데이터를 포함합니다.
도메인별 데이터는 각 도메인의 요구사항에 맞게 맞춤형으로 생성됩니다.
1.1 Reasoning 관련 데이터
- 적용 도메인:
- 수학
- 코드 문제 (Code Competition)
- 논리 퍼즐 (Logic Puzzles)
- 데이터 생성 과정:
- DeepSeek-R1 모델을 활용해 reasoning 데이터를 생성.
- R1 모델의 데이터는 높은 정확도를 보이지만, 다음과 같은 문제가 있음:
- 과도한 답변 생성 (Overthinking).
- 형식 문제 (Poor Formatting).
- 지나치게 긴 답변 (Excessive Length).
- 해결 방법:
- R1 모델 기반 데이터와 정규 포맷 데이터를 결합하여 균형 잡힌 데이터를 생성.
- 데이터의 명확성, 간결성, 정확성을 유지하도록 설계.
- 데이터 샘플링:
- 두 가지 샘플 유형을 생성:
- <문제, 원본 응답> 포맷: 문제와 R1의 원본 응답을 단순히 연결.
- <시스템 프롬프트, 문제, R1 응답> 포맷: 시스템 프롬프트를 포함하여 모델이 더 나은 반영 및 검증 메커니즘을 적용하도록 유도.
- 시스템 프롬프트는 반영(reflection)과 검증(verification) 과정을 강화하기 위해 설계.
- 두 가지 샘플 유형을 생성:
1.2 Non-Reasoning 관련 데이터
- 적용 도메인:
- 창작 글쓰기 (Creative Writing)
- 역할 놀이 (Role-play)
- 단순 질문 응답 (Simple Question Answering)
- 데이터 생성 과정:
- DeepSeek-V2.5 모델을 사용해 응답 생성.
- 인간 평가자(Human Annotators)가 데이터의 정확성과 품질을 검증.
2. SFT 학습 과정
2.1 훈련 프로세스
- Fine-Tuning 모델: DeepSeek-V3-Base 모델.
- 훈련 횟수: 2 Epoch.
- 학습률 스케줄링:
- 초기 학습률: 5×10^{-6}.
- 최종 학습률: 1×10^{-6}.
- Cosine Decay 스케줄링 사용: 학습률을 점진적으로 감소시켜 안정적 학습 보장.
- 샘플 패킹 및 마스킹:
- 다중 샘플에서 단일 시퀀스를 생성.
- 샘플 간 마스킹 전략을 적용하여 데이터 간 상호작용을 방지.
2.2 데이터 샘플링 및 품질 관리
- Rejection Sampling:
- RL 훈련 후, 생성된 데이터를 엄격히 평가하여 고품질 데이터를 선별.
- DeepSeek-R1에서 생성된 데이터를 활용하면서 명확하고 간결한 답변을 유지.
3. SFT 결과
SFT를 통해 모델이 다음과 같은 개선을 달성했습니다:
- 정확성 강화:
- Reasoning 데이터에서의 반영 및 검증 메커니즘으로 정답률 향상.
- 응답 품질 향상:
- 논리적이고 간결하며 명확한 답변 생성.
- 다양성 증대:
- Non-Reasoning 데이터(창작 글쓰기, 역할 놀이 등)에서 더 풍부한 표현과 자연스러운 대화 생성.
4. 결론
SFT 단계는 DeepSeek-V3 모델의 성능을 전문화하고 도메인별 최적화를 달성하는 데 핵심적인 역할을 했습니다.
- Reasoning 데이터의 검증 및 반영 메커니즘을 통해 높은 정확도와 간결성을 유지.
- Non-Reasoning 데이터의 인간 검증으로 품질과 자연스러움을 보장.
- Fine-Tuning 과정에서 효율적인 하이퍼파라미터 설정과 Rejection Sampling으로 고품질 데이터를 선별.
SFT는 DeepSeek-V3의 Post-Training 과정에서 응답 품질과 도메인 특화 능력을 강화하는 중요한 단계로 평가됩니다. 🚀
Post-Training: Reinforcement Learning (RL) 단계
DeepSeek-V3의 강화학습(Reinforcement Learning)은 Supervised Fine-Tuning (SFT) 이후에 모델의 성능을 더욱 정교화하고, 사람의 선호도에 맞춘 응답을 생성하도록 하는 중요한 단계입니다.
RL 과정은 다음과 같은 두 가지 주요 구성 요소를 포함합니다:
- Reward Model (RM)
- Group Relative Policy Optimization (GRPO)
1. Reward Model (RM)
Reward Model은 모델의 출력을 평가하고 적절한 보상을 부여하는 역할을 합니다.
DeepSeek-V3는 Rule-Based Reward Model과 Model-Based Reward Model을 조합하여 사용합니다.
1.1 Rule-Based Reward Model
- 적용 사례:
- 정답이 명확한 질문(예: 수학 문제, 코드 문제)에서 사용.
- 구체적인 작동 방식:
- 수학 문제: 결과를 특정 포맷(예: 박스에 표시된 답)으로 제출하도록 요구하며, 정답을 규칙 기반으로 검증.
- LeetCode 문제: 제출된 코드에 대해 컴파일러를 활용해 테스트 케이스로 정확성을 검증.
- 장점:
- 검증 가능성(reliability)이 높으며, 모델의 답변이 규칙에 따라 조작되거나 잘못된 방향으로 학습되지 않음.
1.2 Model-Based Reward Model
- 적용 사례:
- 명확한 정답이 없는 질문(예: 창작 글쓰기, 역할 놀이)에서 사용.
- 구체적인 작동 방식:
- 모델의 출력이 주어진 질문과 얼마나 일치하거나 바람직한지를 평가.
- DeepSeek-V3 SFT 체크포인트를 기반으로 Reward Model 학습.
- 향상된 신뢰성:
- 선호 데이터(Preference Data)를 포함하여, 보상뿐만 아니라 보상에 도달하는 사고의 과정을 평가.
- 이는 특정 작업에서의 보상 해킹(reward hacking) 가능성을 줄임.
2. Group Relative Policy Optimization (GRPO)
GRPO는 DeepSeek-V2에서 도입된 기법으로, 일반적인 RL 알고리즘과 달리 별도의 Critic 모델 없이 정책 모델 자체로 보상을 최적화합니다.
2.1 GRPO의 핵심 개념
- Critic 모델 제거:
- 일반적인 RL에서는 Critic 모델이 정책 모델의 보상을 평가하지만, GRPO는 Critic 모델 없이 그룹 기반 점수를 사용하여 평가를 대신함.
- 그룹 샘플링:

2.2 GRPO의 손실 함수
GRPO는 다음과 같은 최적화 목표를 기반으로 작동합니다:
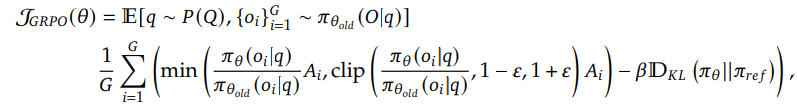
주요 구성 요소:

2.3 GRPO의 특징
- 효율성:
- Critic 모델 없이 그룹 기반 점수를 활용해 정책 업데이트를 간단하게 수행.
- 다양한 도메인에서의 적용:
- 코드 작성, 수학 문제, 창작 글쓰기, 역할 놀이 등 다양한 프롬프트를 사용하여 RL 학습.
- 인간 선호와의 정렬:
- 모델이 사람이 선호하는 응답을 생성하도록 최적화.
3. 강화학습의 전체 프로세스
- Reward Model 학습:
- Rule-Based RM과 Model-Based RM을 결합하여 보상 피드백 시스템 구축.
- GRPO 최적화:
- 기존 정책 모델로부터 응답 그룹을 샘플링하고, GRPO 알고리즘을 사용해 새로운 정책 모델을 업데이트.
- 다양한 도메인 통합:
- RL 학습 시, 코딩, 수학, 글쓰기, 질문 응답 등 다양한 태스크에서 학습을 수행.
- 인간 선호와 정렬된 성능 개선:
- 모델의 응답이 더 자연스럽고 사람의 기대치에 부합하도록 최적화.
4. RL의 결과와 성과
- 벤치마크 성능 향상:
- RL을 통해 모델은 SFT만으로는 부족했던 창작 글쓰기, 복잡한 질문 응답 태스크에서 성능이 크게 향상됨.
- 효율적인 정책 최적화:
- GRPO는 Critic 모델 없이 정책을 최적화하여 메모리와 계산 비용을 절감.
- 높은 신뢰성:
- Rule-Based RM과 Model-Based RM의 조합으로 보상 해킹 가능성을 최소화.
5. 결론
DeepSeek-V3의 RL은 Rule-Based 및 Model-Based Reward Model을 기반으로 정확성과 신뢰성을 높이고, GRPO 알고리즘을 통해 효율적으로 최적화되었습니다.
이 과정은 모델의 응답 품질과 인간 선호도의 정렬을 강화하며, 다양한 도메인에서 더 자연스럽고 효과적인 성능을 보이는 모델을 만들어냈습니다. 🚀
DeepSeek-V3 논문의 결과
DeepSeek-V3 논문은 대규모 Mixture-of-Experts(MoE) 모델을 학습 및 최적화하며, 사전 학습부터 강화 학습까지 전 과정에서 효율성과 성능을 극대화하는 접근법을 제시했습니다. 이 과정에서 제안된 방법론의 주요 결과, 결론, 그리고 연구의 의의를 아래와 같이 정리할 수 있습니다.
1. 주요 결과
1.1 성능 결과
DeepSeek-V3는 다양한 벤치마크에서 우수한 성능을 기록했습니다.
- MMLU (Massive Multitask Language Understanding):
- 88.5% 정확도로 GPT-4o 및 Claude 3.5 대비 동등하거나 우수한 성능.
- MATH (수학 문제 해결):
- 90.2%로 기존 모델들보다 크게 향상된 결과.
- HumanEval (코드 생성):
- 53.7%로, 코드 생성에서 압도적인 성능 개선.
- GSM8K (초등학교 수준의 수학 문제):
- 74.0% 정확도로 GPT-4o를 능가.
이 결과는 DeepSeek-V3의 강화된 전문가 특화 학습, 긴 컨텍스트 처리 능력(최대 128K 토큰), 그리고 효율적인 강화학습 기법 덕분에 달성되었습니다.
1.2 효율성 결과
- FP8 혼합 정밀도 학습:
- 계산 효율성을 극대화하여 학습 비용 절감.
- BF16 대비 연산 속도가 약 2배 증가.
- DualPipe 병렬화 알고리즘:
- Pipeline Bubbles를 거의 제거하고 GPU 자원 활용도를 극대화.
- 대규모 모델 학습에서 계산-통신 오버헤드를 최소화.
1.3 데이터 품질 관리
- Reasoning 데이터에서 DeepSeek-R1 기반 데이터와 정규 데이터의 결합으로 고품질 데이터 생성.
- Non-Reasoning 데이터는 DeepSeek-V2.5와 인간 검증을 통해 생성.
- Rejection Sampling을 활용하여 훈련 데이터의 품질을 엄격히 관리.
2. 결론
DeepSeek-V3는 대규모 MoE 모델 학습에서 다음과 같은 혁신을 달성했습니다:
- 효율적인 모델 학습:
- FP8 정밀도 및 DualPipe 알고리즘을 활용하여 비용 효율적인 학습을 구현.
- All-to-All 통신과 계산-통신 겹침을 통해 GPU 자원 활용 극대화.
- 특화된 전문가 학습:
- Auxiliary-Loss-Free Load Balancing을 통해 각 전문가가 특정 도메인에 특화되도록 설계.
- Reasoning 및 Non-Reasoning 태스크에서의 성능을 균형 있게 향상.
- 사람과의 정렬:
- Supervised Fine-Tuning(SFT)과 강화학습(RL)을 통해 모델의 응답이 사람의 선호도와 일치하도록 최적화.
- Rule-Based 및 Model-Based Reward Model의 조합으로 신뢰성과 정밀도 강화.
- 긴 컨텍스트 처리 능력:
- RoPE 및 단계적 컨텍스트 확장을 통해 최대 128K 토큰 길이의 긴 문맥을 효과적으로 처리.
3. 마무리 및 의의
3.1 DeepSeek-V3의 기여
- 효율성:
- 대규모 MoE 모델 학습에서 계산 비용과 메모리 사용량을 획기적으로 줄이며, 실용적인 학습 프레임워크를 제안.
- 성능:
- 언어 이해, 수학 문제 해결, 코드 생성 등 다양한 태스크에서 SOTA(State-of-the-Art) 성능을 달성.
- 확장성:
- 긴 문맥 처리와 전문가 학습을 결합하여 미래의 대규모 모델 확장 가능성을 제시.
3.2 한계와 향후 연구
논문은 일부 한계를 인정하며, 다음과 같은 연구 방향을 제안합니다:
- 전문가 라우팅의 최적화:
- 현재의 Auxiliary-Loss-Free Load Balancing을 더욱 정교화하여, 전문가 라우팅의 정확성을 높이는 연구.
- FP8 학습의 표준화:
- FP8 기반 학습이 더 많은 GPU 아키텍처와 호환되도록 개선.
- 모델 평가 및 개선:
- 더 다양한 도메인에서의 평가와 추가 Fine-Tuning 연구.
3.3 결론
DeepSeek-V3는 효율성과 성능을 모두 향상시키며, 대규모 언어 모델 학습에서 새로운 기준을 제시했습니다. 이 연구는 미래의 AI 모델 설계 및 학습 방식에 중요한 영감을 줄 것으로 기대됩니다. 🚀