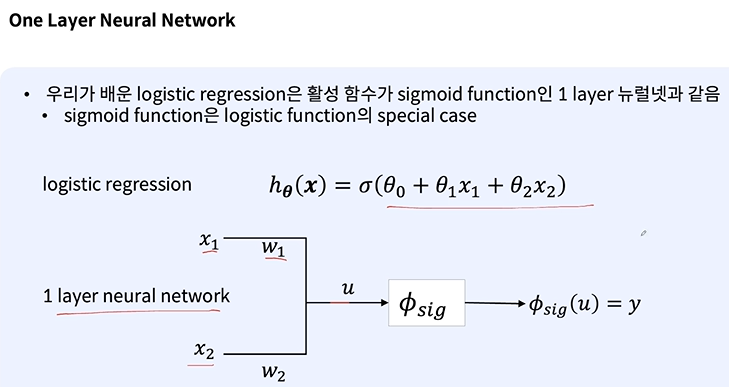
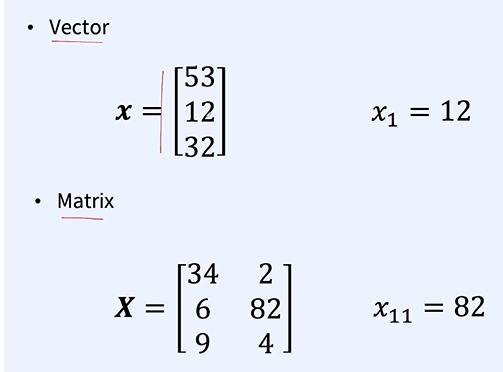이전에 계속 배웠었던 내용이다. 앞과 뒤만 짤라서 그대로 사용하는 것! 첫번째는 그냥 학습하면 된다. 두번째는 A의 파라미터를 B에 그대로 집어넣고 그대로 학습한다. A와 B의 입 출력의 개수가 다르기 때문에 FC나 입력부분을 수정해줘야 한다. 세번째는 A가 학습한 것을 남기기 위해 특정 영역은 프리즈 시킨다. 이렇게하면 A의 학습내용을 잃지 않을 수 있다. 그러나 B 특화에 도달하지 못할 수 있으므로 잘 선택해야 한다. 데이터가 많고 사전 학습 모델과 성격이 다름 => 동물 분류와 의료 분류 데이터셋 많고 사전 학습 모델도 같음 == 동물 분류 두개 각각 경우의 수에 따라 다른 전략을 선택한다. 이 4가지 경우의 전략을 잔 선택해야 한다. 거리가 줄어들도록 학습을 하게 된다. 모든 로스를 다 더하는 방..