
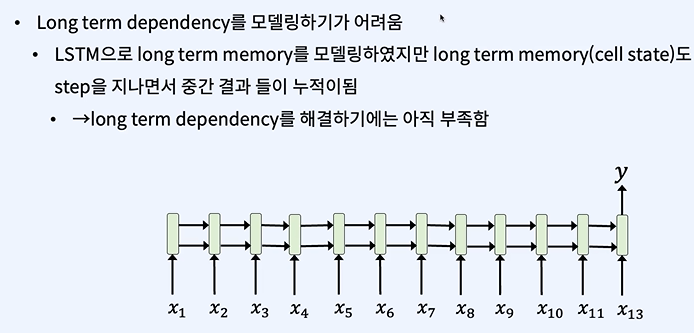
번역 모델과 같은 경우에서 이러한 문제가 많이 생겼다.

필요한 정보들의 스코어(soft max를 한 attention score)와 가중합을 통해 ctx를 만들어서 연산을 통해 합치고 today가 나오게 된다.

RNN이나 CNN을 사용하지 않고 작성한 논문

encoder과 decoder의 역할은 이전과 똑같다.

input에서 +로 바로 연결해주는 skip connection이 적용되어 있는 것을 볼 수 있다.
norm은 layer norm을 사용하게 된다.
FF는 1layer 이다. 다중 레이어 X
N번 만큼 인코더 블록을 여러번 반복하게 된다.


Query Linear와의 유사성을 내적을 통해 계산하고 소프트 맥스를 통해 attention 가중치를 구한다.

현재의 나 자신 (x1)과 다른 것 (x2,x3)와의 유사성을 구하여 계산한다고 생각하면 된다.

Query Linear, key Linear, Value Linear을 쪼개서 사용하고 남은 부분은 나중에 사용한다.
나머지는 위와 동일하다.
그 후 나머지 부분을 진행 후 y1 뒤에 이어 붙이면 된다.


이렇게 하면 위치를 알 수 있게 된다.

'인공지능 > 자연어 처리' 카테고리의 다른 글
| 자연어 처리 - NN을 이용한 classification, regression 실습 (1) | 2024.01.25 |
|---|---|
| 자연어 처리 - Multi task learning (0) | 2024.01.25 |
| 자연어 처리 - RNN, LSTM (0) | 2024.01.17 |
| 자연어 처리 - auto encoder, CNN (0) | 2024.01.17 |
| 자연어 처리 - Loss function (0) | 2024.01.17 |