RNN

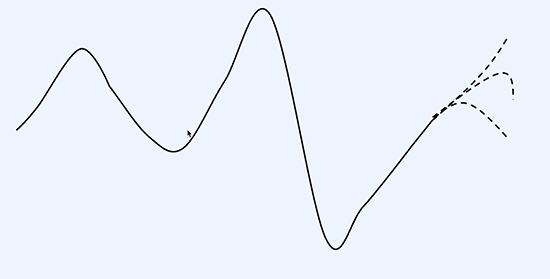
우린 이 점선으로 된 부분을 예측해야 한다.
그냥 MLP를 사용하면 현재 데이터나 과거 데이터나 신경쓰지 않는다.
CNN은 패턴을 잡는 모델이라 순서를 신경쓰지 않아 문제가 생긴다.
시간의 순서를 신경써야 한다.

inductive bias = 사람의 직관

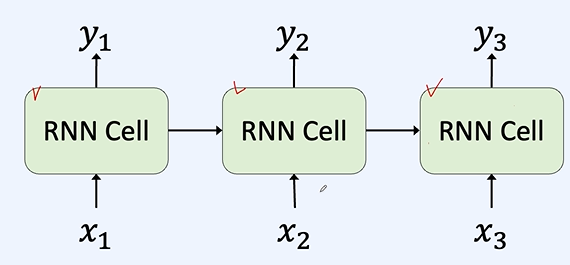

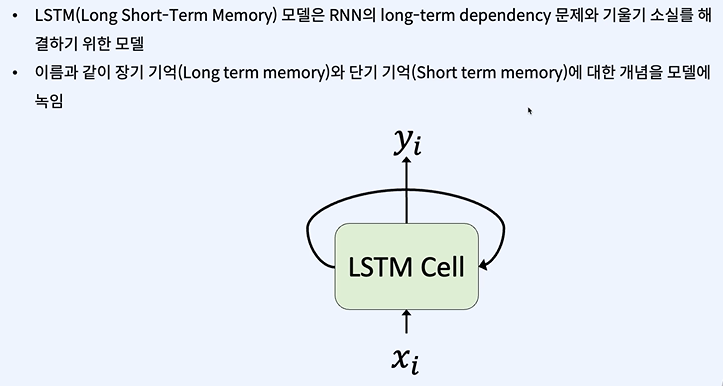
h = 이전에서 넘어온 데이터
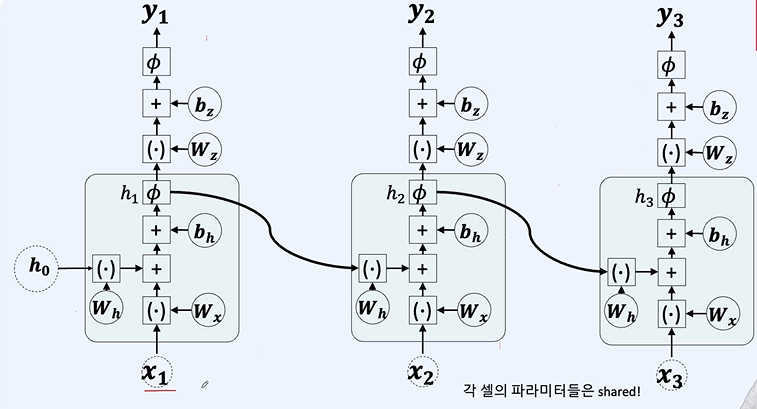

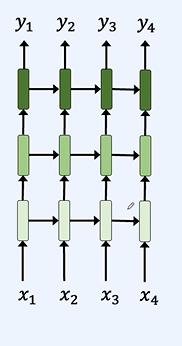
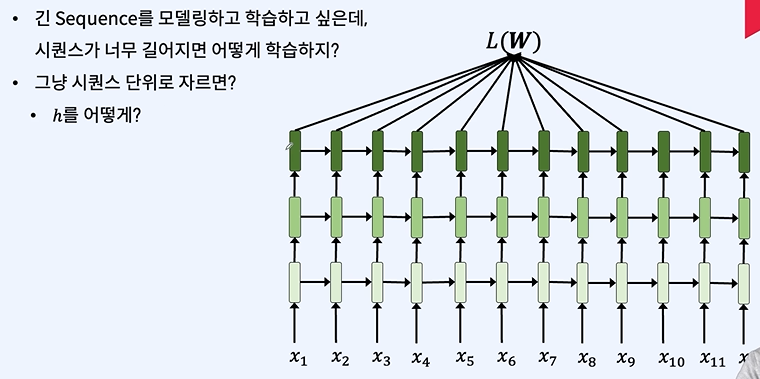
스퀸스 단위로 자르게 된다면 첫번째 h가 애매해지게 된다.
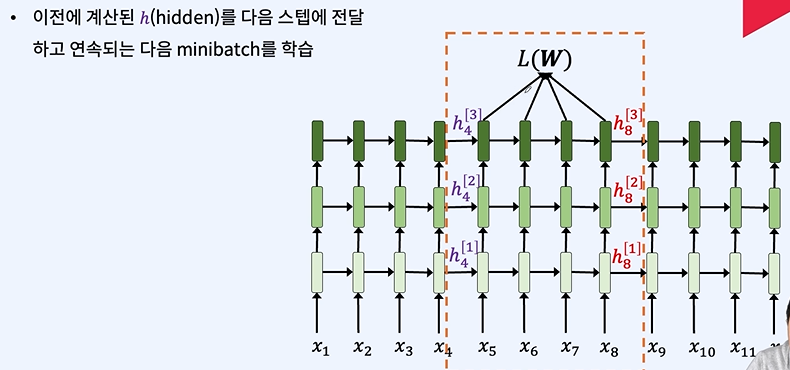
h를 기억하여 다음 스텝에 사용한다.




2023.12.15 - [인공지능/공부] - 시계열 데이터(주가, imu data) 예측 인공지능 - RNN, LSTM
시계열 데이터(주가, imu data) 예측 인공지능 - RNN, LSTM
RNN은 시간에 따라 변화하는 데이터를 얘측할 때 사용된다. stationary( 변화없는 )데이터 NON - stationary 데이터 둘 중에 무엇이든 이러한 데이터들은 이전의 값들이 필요하다. 그러나 CNN, FCN을 사용하
yoonschallenge.tistory.com
LSTM



이전에 나왔던 gradient vanishing과 비슷하다.



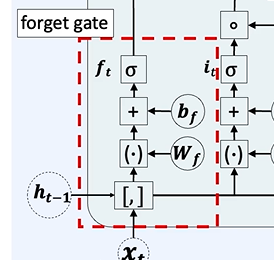
시그모이드 연산을 통해 0과 1로 나뉘므로 곱하기를 통해 잊을 것은 적절하게 사라진다.
여기서 어떤 것을 잊었는지 정보를 넘겨주는 구조도 있었다.

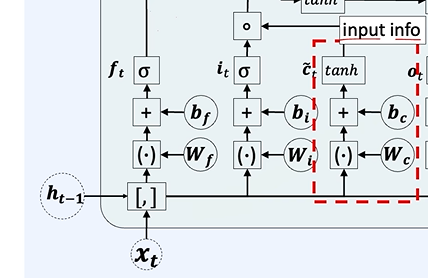
단기 정보를 만듭니다.
input gate랑 곱해져서 장기 기억을 업데이트한다.

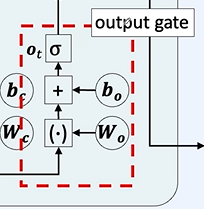
이제 단기 기억을 만듭시다!


'인공지능 > 자연어 처리' 카테고리의 다른 글
| 자연어 처리 - Multi task learning (0) | 2024.01.25 |
|---|---|
| 자연어 처리 - Transformer (1) | 2024.01.21 |
| 자연어 처리 - auto encoder, CNN (0) | 2024.01.17 |
| 자연어 처리 - Loss function (0) | 2024.01.17 |
| 자연어 처리 - 모델 학습 (0) | 2024.01.17 |