
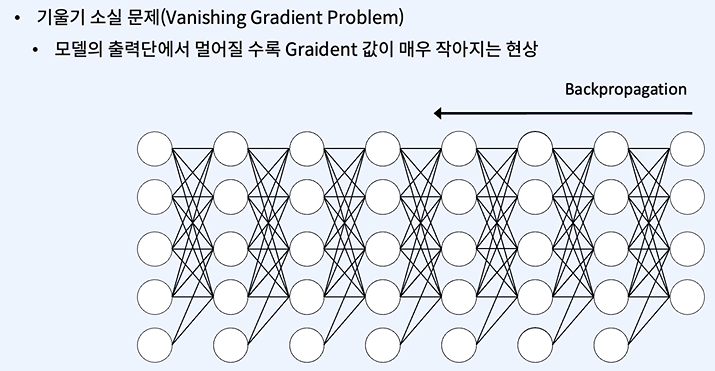
시그모이드 때문에 소실이 커진다!

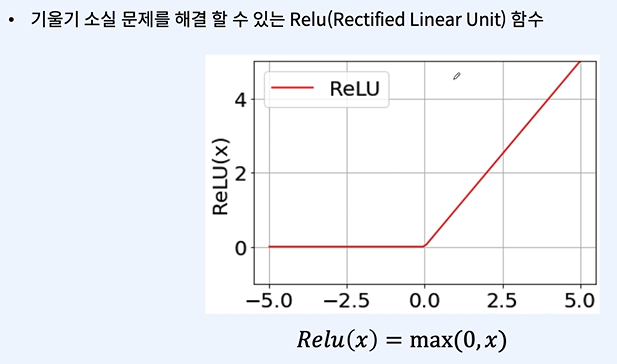
0보다 작은 값에선 미분값이 0이라는 문제가 생겨서 리키렐루가 나오는데 일단 넘어가네유


여기서 리키렐루가 나오네요
가중치 초기화는 0이거나 똑같은 값으로 하지 말라고 했었습니다!


이제 어떻게 하는게 좋은지 봅시다!
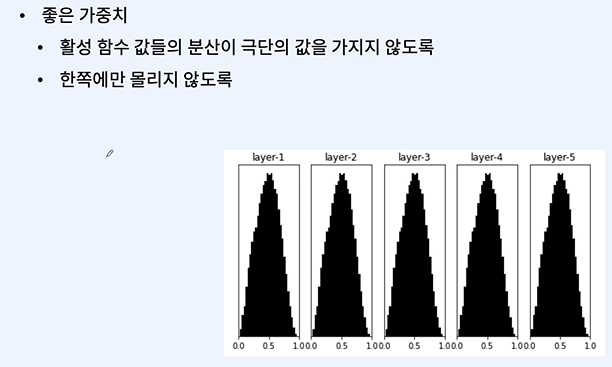
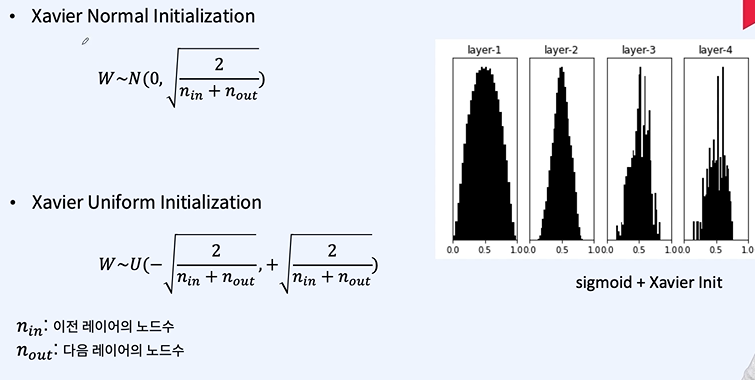
분산을 적당히 조절하는 것이 중요하다.
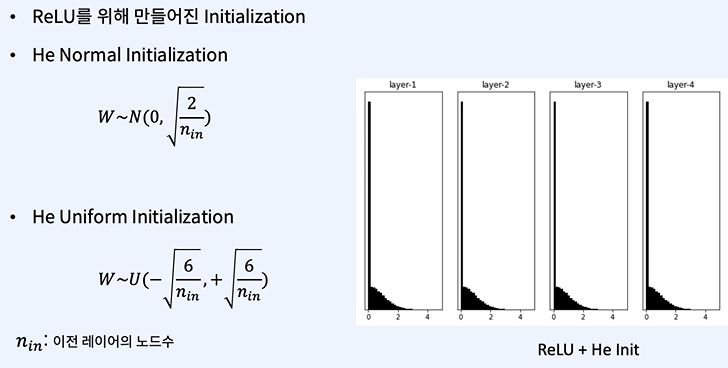
이거하면 바이어스가 필요없다고 했던것 같기도 하고...



이것만 가지고는 뭔가 batch와 layer를 이해하기 어려울것 같아서 gpt 센세를 활용하겠습니다.
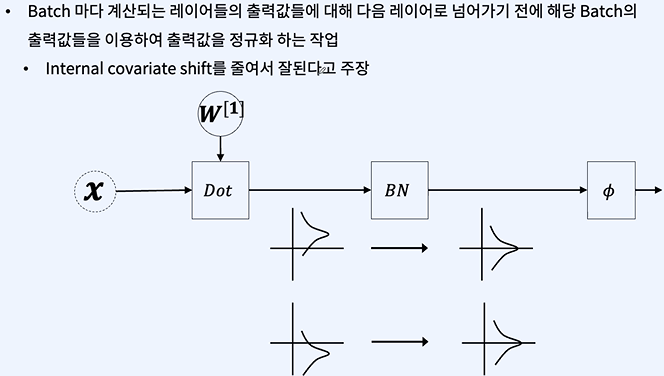
Batch Normalization과 Layer Normalization은 둘 다 신경망의 학습을 안정화하고 가속화하는 데 사용되는 기술입니다. 두 기술 모두 데이터의 평균과 분산을 정규화하는 과정을 통해 내부 공변량 변화(internal covariate shift) 문제를 완화하려고 합니다. 내부 공변량 변화란 학습 과정에서 네트워크의 파라미터가 변함에 따라 레이어의 입력 분포가 변하는 현상을 말합니다.
Batch Normalization (배치 정규화):
배치 정규화는 각 레이어의 입력을 미니배치 단위로 정규화합니다. 즉, 미니배치의 모든 샘플에 대해 평균과 분산을 계산하고 이를 사용하여 정규화합니다.
이는 미니배치의 크기에 영향을 받으므로, 매우 작은 배치 크기에서는 잘 작동하지 않을 수 있습니다.
학습 단계와 추론 단계에서 다른 계산 방식을 사용합니다. 학습 단계에서는 현재 미니배치의 평균과 분산을 사용하고, 추론 단계에서는 전체 학습 과정에서 계산된 평균과 분산의 이동 평균을 사용합니다.
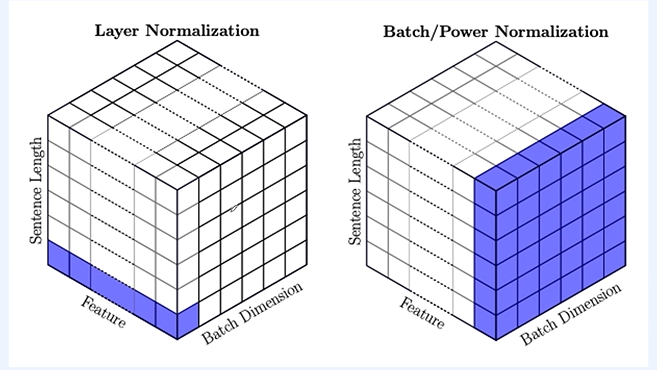
Layer Normalization (레이어 정규화):
레이어 정규화는 배치 내의 각 샘플에 대해 개별적으로 평균과 분산을 계산합니다. 즉, 한 샘플 내의 모든 활성화에 대해 평균과 분산을 계산하여 정규화합니다.
이는 배치 크기에 의존하지 않으므로, 배치 크기에 관계없이 일관된 성능을 보입니다.
모든 훈련 단계와 추론 단계에서 동일하게 적용됩니다.
차이점:
계산 축: 배치 정규화는 배치의 차원(즉, 다른 샘플들 간)에 대해 평균과 분산을 계산합니다. 레이어 정규화는 샘플 내의 특징 차원에 대해 평균과 분산을 계산합니다.
배치 크기 의존성: 배치 정규화는 미니배치의 크기에 영향을 받지만, 레이어 정규화는 그렇지 않습니다.
학습과 추론의 일관성: 배치 정규화는 학습 시와 추론 시 다르게 동작하지만, 레이어 정규화는 동일합니다.
두 정규화 기법은 서로 다른 상황에 적합할 수 있습니다. 예를 들어, 시퀀스 데이터를 다루는 경우(예: RNN)에는 레이어 정규화가 더 적합할 수 있으며, 컨볼루셔널 네트워크에서는 배치 정규화가 널리 사용됩니다.


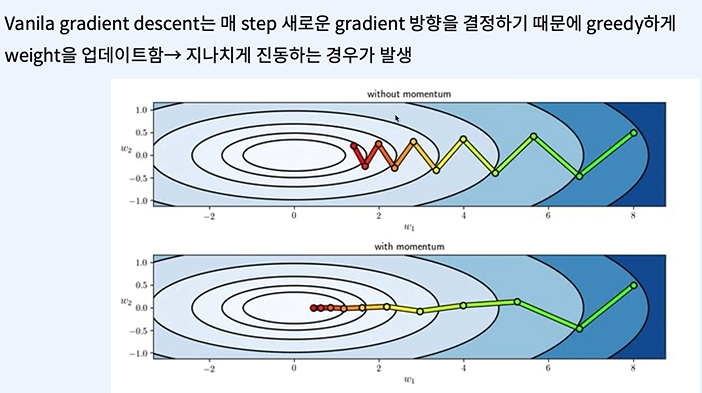

알파 = 학습률 = learning rate


2023.12.16 - [인공지능/공부] - 인공지능 backpropagation, optimization- 개념
인공지능 backpropagation, optimization- 개념
backpropagation backpropagation은 대부분의 인공지능의 파라미터 업데이트 방식이다. 우린 경사하강법을 통해 loss를 최소화 시키는 방향으로 학습한다. 기본적인 gradient 계산 방법이다. 이제 activation fun
yoonschallenge.tistory.com
여기에서도 나왔던 optimization이다.
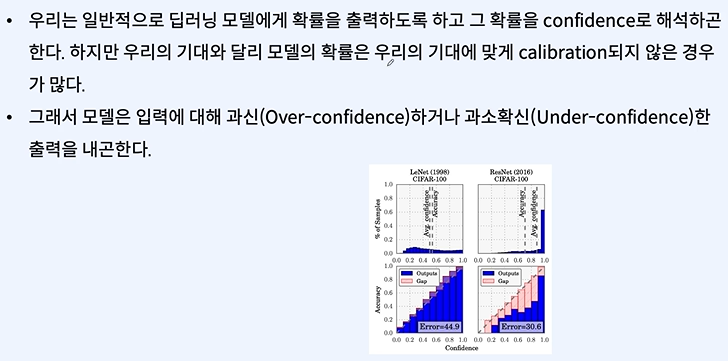

여기선 정확히 모르겠다... 다시 선생님...
Over-confidence와 Under-confidence는 머신 러닝에서 모델의 예측에 관련된 문제입니다.
Over-confidence:
이는 모델이 실제 정확도보다 훨씬 높은 확신을 가지고 예측할 때 발생합니다.
예를 들어, 모델이 특정 클래스에 속한다고 95%의 확신을 가지고 예측했는데, 실제로 해당 예측이 정확한 경우의 비율이 훨씬 낮은 경우에 해당합니다.
Over-confidence는 모델이 특정 패턴을 너무 강하게 학습했거나 (즉, overfitting), 데이터에 존재하지 않는 패턴을 학습했을 때 발생할 수 있습니다.
이 문제를 해결하기 위해 모델의 정규화를 강화하거나, 데이터를 더 다양하게 제공하거나, 모델의 예측 확률을 조정하는 보정(calibration) 기술을 사용할 수 있습니다.
Under-confidence:
반대로, 모델이 실제 정확도보다 낮은 확신을 가지고 예측할 때 발생합니다.
예를 들어, 모델이 어떤 클래스에 속한다고 50%만 확신하는데 실제로는 이 예측이 훨씬 더 높은 확률로 맞는 경우입니다.
이는 모델이 충분히 훈련되지 않았거나 (즉, underfitting), 데이터에 존재하는 패턴을 충분히 학습하지 못했을 때 발생할 수 있습니다.
Under-confidence를 해결하기 위해 더 많은 데이터를 수집하거나, 모델의 복잡성을 증가시키거나, 훈련 시간을 늘리는 등의 방법을 사용할 수 있습니다.
두 문제 모두 모델의 불확실성을 적절히 추정하고 이를 예측에 반영하는 것이 중요합니다. 예측의 불확실성을 측정하고 이를 통해 모델의 예측을 더 잘 이해할 수 있도록 하는 연구가 진행되고 있습니다. 이는 실제 응용에서 모델의 결정을 신뢰할 수 있는지 여부를 판단하는 데 매우 중요합니다.




데이터 증강의 필요성!



데이터마다 증강 방법이 다르다!
'인공지능 > 자연어 처리' 카테고리의 다른 글
| 자연어 처리 - auto encoder, CNN (0) | 2024.01.17 |
|---|---|
| 자연어 처리 - Loss function (0) | 2024.01.17 |
| 자연어 처리 - 과적합 방지 (0) | 2024.01.17 |
| 자연어 처리 - multi classification, soft max (0) | 2024.01.17 |
| 자연어 처리 - MLP, 최적화, Gradient Descent (0) | 2024.01.17 |