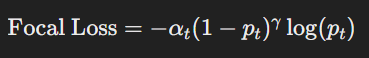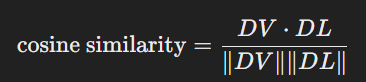간단하게는 차량의 효율적 운행을 위해 클라우드에서 파라미터를 보내주면 차량은 그 파라미터에 맞게 운행 방식을 변경하는 것이네요EMS(Energy management system)은 플러그인 하이브리드 자동차에서 전기와 연료를 어떻게 배분하여 사용할 지 결정하는 시스탬이다. 실시간으로 에너지를 관리하고 배분한다.CD-CS전략 - SOC(배터리 충전이 필요한 상태)가 최소 한계에 도달할 때 까지 전기 모드(CD)로 운행SOC는 한계를 유지하며 연료를 사용하여 운행하는 CS단계가 있다.이 방식은 최적 방식이 아니다.SDP(확률 동적 프로그래밍)을 통해 확인하자! -> 계산 리소스는 많이 필요하나 오프라인에서 이용할 수 있다.BUT 새로운 데이터에 대해선 다시 학습해야 한다. SMPC(확률 모델 예측 제어)은 ..