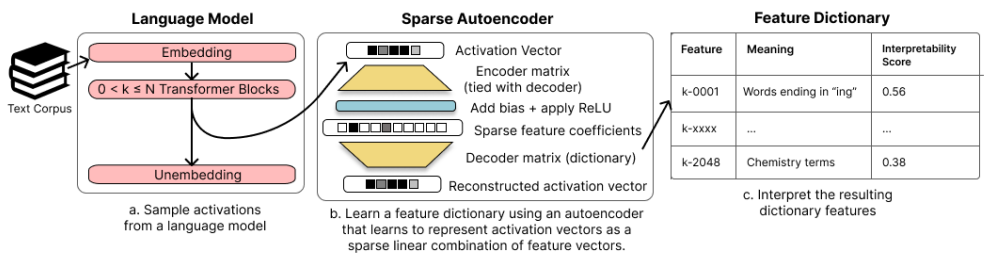
https://arxiv.org/abs/2404.16014 Improving Dictionary Learning with Gated Sparse AutoencodersRecent work has found that sparse autoencoders (SAEs) are an effective technique for unsupervised discovery of interpretable features in language models' (LMs) activations, by finding sparse, linear reconstructions of LM activations. We introduce the Gatedarxiv.org 기존 SAE에 LSTM과 같은 GATE 구조를 추가하여 필요한 항만 ..