https://arxiv.org/abs/2312.03656
Interpretability Illusions in the Generalization of Simplified Models
A common method to study deep learning systems is to use simplified model representations--for example, using singular value decomposition to visualize the model's hidden states in a lower dimensional space. This approach assumes that the results of these
arxiv.org
모델을 단순화하여 시각화하면 왜 이러한 출력을 하는지 보일 순 있겠지만 그 것이 전체적인 모델을 해석하는 것과는 다르다.
모델의 복잡한 행동을 충분히 반영하지 못하고, 모델의 출력 또한 따라가지 못한다!


1. 문제 정의 (What Problem Does It Aim to Solve?)
이 논문은 심층 학습 모델을 해석하기 위한 모델 간소화 방법에 대한 신뢰성 문제를 다루고 있습니다. 연구자들은 차원 축소 및 클러스터링과 같은 기법을 사용해 모델의 복잡한 표현을 단순화하고 이를 통해 모델의 동작을 이해하려고 합니다. 그러나 이러한 단순화된 모델이 원래 모델의 행동을 훈련 데이터 이외의 분포에서도 충실히 나타내는지 의문을 제기하고 있습니다. 특히, 이 연구는 모델의 체계적인 일반화 능력을 평가할 때, 단순화된 모델이 원래 모델의 동작을 적절히 설명할 수 있는지에 대한 신뢰성에 대해 문제를 제기합니다.
2. 연구 방법 및 시도 (What Methods Were Tried?)
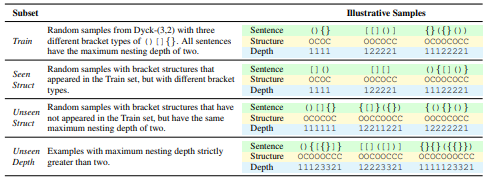
연구자들은 Transformer 모델을 사용하여 시스템 일반화(split-based generalization) 설정에서 실험을 진행했습니다. 주로 두 가지 데이터셋을 활용했습니다.
- Dyck 균형 괄호 언어(Dyck balanced-parenthesis languages): 이 언어는 프로그래밍 언어와 유사한 구조적 특성을 가지고 있어, Transformer의 계층적 구조 처리 능력을 테스트하기에 적합합니다. 여기서 모델은 괄호의 중첩 구조를 학습하여 올바른 괄호를 예측하는 과제를 수행합니다.
- 코드 자동완성(code completion): 다양한 프로그래밍 언어에서 코드를 예측하는 과제입니다. 이 과제는 알고리즘적 추론과 더불어 자연 언어 처리 작업도 포함되어, 모델의 전반적인 일반화 능력을 평가합니다.
3. 사용된 방법 (What Methods Were Used?)
논문에서는 다음과 같은 방법을 사용하여 모델을 단순화했습니다.
- 차원 축소(Dimensionality Reduction): SVD(특이값 분해)를 사용하여 키(key)와 쿼리(query) 표현을 상위 몇 개의 주성분으로 투영하였습니다.
- 클러스터링(Clustering): K-means 클러스터링을 사용하여 키와 쿼리를 군집화하고, 그 군집 중심값을 사용해 모델의 주의를 계산했습니다.
- 주의 패턴 간소화(Attention Simplification): 원래의 소프트맥스 주의 메커니즘을 하드 주의(one-hot attention)로 변경하여 모델을 단순화하였습니다.
4. 결과 (What Were the Results?)
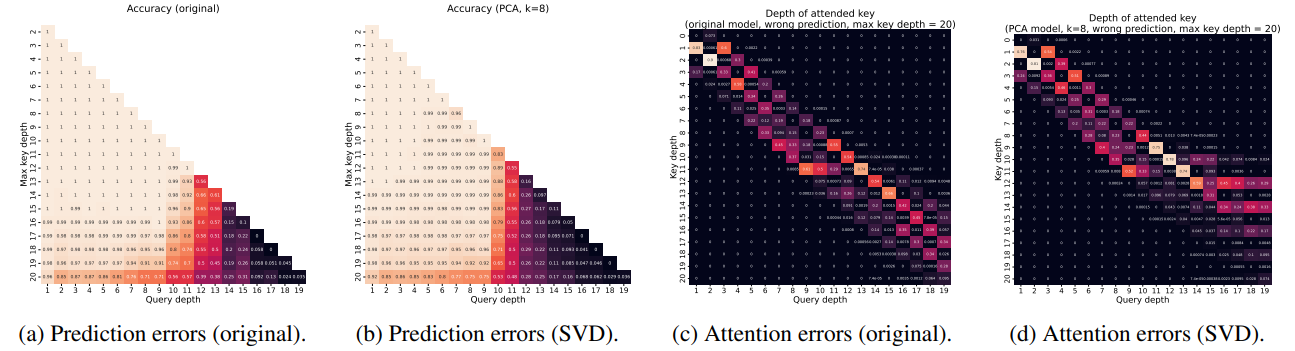
이 연구의 결과, 단순화된 모델이 훈련 데이터 내에서는 원래 모델과 유사한 성능을 보였으나, 훈련 데이터 이외의 분포에서는 원래 모델의 동작을 충실히 반영하지 못하는 경우가 발생했습니다. 특히, 차원 축소 및 클러스터링과 같은 데이터 의존적인 간소화 방법이 훈련 데이터에서는 좋은 성능을 보였지만, 분포 외 일반화 테스트에서는 원래 모델보다 성능이 떨어지는 현상이 발견되었습니다. 예를 들어, Dyck 언어에 대한 테스트에서 원래 모델은 거의 완벽하게 일반화했으나, 단순화된 모델은 일반화에서 큰 성능 저하를 보였습니다.
5. 한계점 (What Were the Limitations?)
이 연구의 주요 한계점은 간소화된 모델이 훈련 데이터 이외의 분포에서는 원래 모델을 충실히 대체하지 못한다는 점입니다. 또한, 단순화가 이루어진 방식에 따라 서로 다른 일반화 간극(generalization gaps)이 발생했습니다. 어떤 경우에는 단순화된 모델이 원래 모델보다 성능이 나빠졌고, 반대로 특정 데이터 비의존적 간소화(예: 하드 주의)의 경우는 오히려 일반화 성능이 향상되는 경우도 있었습니다. 이는 단순화 방법이 원래 모델의 모든 중요한 특성을 반영하지 못한다는 문제를 시사합니다.
결론 및 제안 (Conclusion & Suggestions)
이 논문은 모델 해석을 위한 간소화 방법들이 훈련 데이터 분포 내에서는 유용할 수 있으나, 데이터 분포가 바뀌었을 때 그 신뢰성이 떨어질 수 있음을 보여줍니다. 따라서 AI 연구자들은 단순화된 모델을 해석할 때, 이러한 일반화 간극을 염두에 두어야 하며, 특히 훈련 데이터 이외의 환경에서 모델을 평가하는 것이 중요하다는 점을 강조하고 있습니다.
방법론을 좀 더 자세하게 설명해줘
원래 모델을 더 단순화해서 몇개의 차원으로 줄이고, 그것을 또 간소화한 one hot attention을 통해 왜 이러한 결과를 보이는지 시각화 하려고 한거야?
결국 큰 모델을 직접 확인해야지 단순화하면 제대로 해석할 수 없다는 것이네?
논문에서 사용된 방법론을 좀 더 자세하게 설명하자면, 연구자들은 Transformer 모델을 해석하기 위해 다양한 모델 간소화 방법을 시도했습니다. 이 과정에서 모델이 복잡한 데이터를 어떻게 처리하고 일반화하는지 이해하려고 했으며, 특히 모델을 차원 축소하거나 주의 메커니즘을 간소화함으로써 단순화된 모델이 원래 모델의 성능을 어떻게 재현하는지 평가했습니다.
1. 차원 축소 (Dimensionality Reduction)
연구자들은 SVD(특이값 분해, Singular Value Decomposition)를 사용해 모델의 키(Key)와 쿼리(Query) 임베딩을 몇 개의 주성분으로 축소했습니다. 이 과정에서 각 임베딩을 상위 k개의 주요 성분으로 투영함으로써, 원래 복잡한 고차원 표현을 더 단순한 저차원 공간에서 표현했습니다. 이는 모델이 원래 데이터를 처리하는 방식에서 중요한 정보를 유지하면서도, 이해하기 쉽게 표현하려는 시도였습니다. SVD를 통해 차원을 줄이면서, 일반화 성능에 미치는 영향을 관찰하고, 이를 통해 간소화된 모델의 한계를 평가했습니다.
2. 클러스터링 (Clustering)
차원 축소 외에도 K-means 클러스터링을 사용하여 키와 쿼리 표현을 군집화했습니다. 군집화는 임베딩을 여러 그룹으로 나누고, 각 그룹의 중심을 대표로 사용해 모델이 입력을 처리하도록 했습니다. 이를 통해 모델의 주의(attention) 메커니즘을 간소화했고, 원래 모델과의 성능 차이를 비교했습니다. 특히, 이렇게 클러스터링된 간소화된 모델이 훈련 데이터에서 어떤 패턴을 학습했는지 분석하려 했습니다.
3. 주의 패턴 간소화 (Attention Simplification)
세 번째 방법은 주의 메커니즘을 단순화하는 방식이었습니다. 원래의 소프트맥스(softmax) 기반의 주의 패턴을 "하드 주의(one-hot attention)"로 변경했습니다. 이는 모델이 각 입력에 대해 가장 높은 주의를 주는 키 하나에만 집중하도록 하는 방식입니다. 이 방법은 데이터 의존적이지 않은 간소화 방법으로, 주의 메커니즘을 최대한 단순화하여도 모델이 얼마나 일반화할 수 있는지를 평가하려 했습니다. 하드 주의는 특성상 더 간단한 방식이지만, 모델이 여전히 복잡한 구조적 데이터를 처리할 수 있는지 확인하기 위한 실험이었습니다.
4. 결과와 시각화
실험 결과, 간소화된 모델들은 훈련 데이터에서는 원래 모델과 유사한 성능을 보였지만, 훈련 데이터 외의 분포에서는 성능이 크게 저하되었습니다. 특히 차원 축소와 클러스터링을 통한 간소화된 모델들은 비슷한 성능을 보이는 듯 했지만, 실제로는 원래 모델의 중요한 정보나 패턴을 놓치는 경우가 많았습니다. 예를 들어, SVD로 차원을 축소한 모델이 훈련 데이터에서는 거의 100% 유사한 예측을 보였지만, 훈련 데이터와 다른 구조나 깊이를 가진 데이터에서는 크게 빗나갔습니다.
5. 시각화와 해석
이러한 결과는 시각화 도구를 통해 명확히 드러났습니다. 연구자들은 SVD를 적용한 후 주의 임베딩을 저차원 공간에서 시각화하며, 각 위치에서 주의 메커니즘이 어떻게 작동하는지를 확인했습니다. 이 시각화를 통해 단순화된 모델이 어떤 정보를 유지하고 놓치고 있는지를 명확하게 보여주었으며, 주의 메커니즘의 복잡한 상호작용이 간소화 과정에서 어떻게 손실되는지 확인할 수 있었습니다.
결론
결국, 단순화된 모델은 원래 모델의 복잡한 행동을 충분히 반영하지 못하는 경우가 많았으며, 특히 훈련 데이터 외의 일반화 성능에서 큰 간극이 발생했습니다. 이는 단순화된 모델을 사용해 원래 모델을 해석할 때, 중요한 정보가 사라질 수 있다는 한계를 보여주며, 큰 모델의 복잡한 상호작용을 직접 확인하지 않으면 제대로 된 해석이 어렵다는 결론을 뒷받침합니다.
그럼 이 방식이 타당하다고 생각해?
좀 더 발전시킬 수 있는 방법이 없을까?
현재 논문에서 사용된 방법론은 모델 해석을 위한 간소화 과정의 한계를 분명히 보여줍니다. 특히, 모델을 단순화함으로써 해석이 더 쉬워지는 반면, 중요한 정보가 손실되어 원래 모델이 복잡한 데이터에서 보여주는 능력을 충분히 재현하지 못하는 경우가 발생합니다. 이 방식은 심층 학습 모델의 복잡성을 이해하는 데 있어 중요한 시도이지만, 그 자체로는 완전하지 않습니다. 몇 가지 한계와 발전 가능성을 고려할 수 있습니다.
1. 타당성에 대한 평가
이 방식은 분명히 의미가 있습니다. 차원 축소나 클러스터링 같은 방법은 고차원 데이터나 모델을 해석하는 데 자주 사용되는 기법으로, 모델 내부에서 어떤 특성이 중요한지 추론할 수 있습니다. 또한, 주의 메커니즘을 단순화하여 모델이 어떻게 특정 정보에 집중하는지를 이해하려는 시도도 타당합니다.
하지만 논문의 결과에서도 드러났듯이, 단순화된 모델은 훈련 데이터 내에서만 잘 작동하고, 훈련 데이터 외의 분포에서는 일반화 성능이 떨어집니다. 이는 모델의 중요한 정보나 패턴이 간소화 과정에서 손실되었기 때문입니다. 이 방식이 충분히 타당하지만, 완전한 해석 도구로서는 한계가 있다는 것이 명확히 드러난 셈입니다.
2. 발전 가능성
이 문제를 해결하기 위해 몇 가지 발전 가능성을 제안할 수 있습니다.
(1) 다양한 데이터 분포를 반영한 간소화
현재 사용된 차원 축소나 클러스터링 방법은 훈련 데이터의 분포에만 의존하고 있습니다. 하지만, 이 과정에서 훈련 데이터 외의 분포에서는 모델의 중요한 패턴이 사라질 수 있음을 확인했습니다. 이를 해결하기 위해, 다양한 데이터 분포를 반영한 간소화 기법을 시도할 수 있습니다. 예를 들어, 훈련 데이터뿐만 아니라 테스트 데이터와 유사한 분포를 추가적으로 고려하거나, 다양한 분포에 맞춰 적응적으로 차원을 축소하는 방식이 있을 수 있습니다.
(2) 비선형 차원 축소 방법의 도입
SVD는 선형 차원 축소 기법입니다. 하지만 딥러닝 모델의 내부 표현은 비선형 구조를 가지고 있을 가능성이 큽니다. 따라서 비선형 차원 축소 기법인 t-SNE나 UMAP 같은 방법을 도입해 모델의 복잡한 구조를 더 잘 표현할 수 있습니다. 이러한 방법들은 고차원 공간에서의 복잡한 패턴을 비선형 방식으로 유지하면서 축소할 수 있기 때문에, 단순화된 모델이 훈련 데이터 외에도 더 나은 성능을 보여줄 수 있을 것입니다.
(3) 다중 컴포넌트 해석 방법
현재 연구에서는 단일 차원 축소 방식을 사용했습니다. 하지만 모델이 복잡한 다중 컴포넌트로 구성된다는 점을 고려하면, 다중 단계의 간소화 또는 다중 컴포넌트 분석을 도입할 수 있습니다. 예를 들어, 개별 컴포넌트(예: 여러 주의 헤드)에 대한 독립적인 해석 후 이를 결합하는 방식으로, 특정 컴포넌트가 일반화에 어떤 역할을 하는지 더 잘 이해할 수 있습니다. 이 방법은 단순화 과정에서 복잡한 상호작용을 놓치지 않도록 도울 수 있습니다.
(4) 순차적 및 단계별 학습에 대한 적응
모델이 훈련되는 방식은 단계적으로 더 복잡한 구조를 학습합니다. 따라서 단순화된 해석을 진행할 때, 각 학습 단계에 맞춰 해석 기법을 적응적으로 조정할 수 있습니다. 예를 들어, 초기 학습 단계에서는 단순한 차원 축소 방법이 유용할 수 있지만, 이후 더 복잡한 계층 구조를 학습할 때는 더 정교한 해석 방법이 필요할 수 있습니다.
3. 결론
결국, 논문에서 제안된 방법론은 모델을 해석하는 데 타당한 방식이지만, 여러 한계로 인해 완전한 해석 도구로 사용되기에는 부족한 면이 있습니다. 이를 개선하기 위해서는 다양한 데이터 분포를 고려한 차원 축소, 비선형 차원 축소 방법의 도입, 다중 컴포넌트 해석 및 순차적 학습 단계에 맞춘 해석 방법을 추가로 연구하는 것이 필요합니다.
이러한 발전 방향을 통해, 단순화된 모델이 훈련 데이터뿐 아니라 훈련 데이터 외의 분포에서도 더 나은 일반화 성능을 보이고, 원래 모델의 복잡한 행동을 더 잘 반영할 수 있도록 할 수 있을 것입니다.