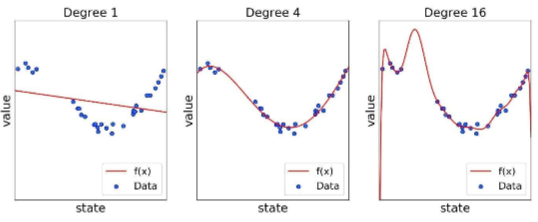
가치 기반 에이전트는 V와 Q를 만든다. V, Q 계산을 잘해야 최적의 정책을 찾을 수 있다. 가치 기반 : 가치 함수에 기반하여 액션 선택모델 프리상황(v를 사용하기 힘들다)에서는 v를 보고 알 수 없기 때문에 q를 사용한다.정책 기반 : 정책 함수에 기반하여 액션 선택액터 크리틱 : 가치 함수와 정책 함수를 모두 사용한다.액터 : 정책크리틱 : v,q 벨류네트워크는 정책이 고정되어 있을 때 뉴럴넷을 이용하여 학습한다.이렇게 만든 네트워크는 테이블 필요없이 input인 state만 주면 값이 튀어나온다. 업데이트 진행은 MSE를 활용한 경사 하강법과 동일하다. 그러나 강화학습에는 라벨이 없기 때문에 TD나 MC를 활용하여 True 값을 만들어 준다. 딥 Q 러닝가치 기반 에이전트는 명시된 정책이 ..