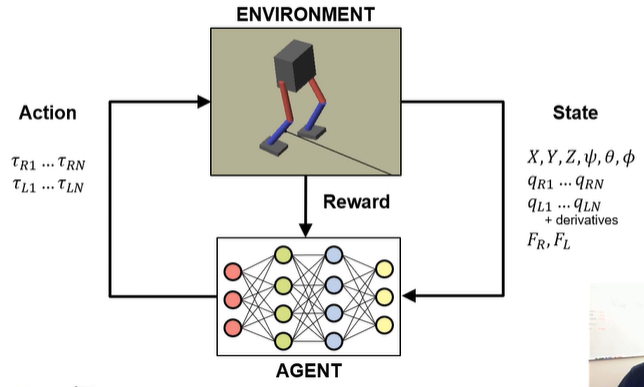
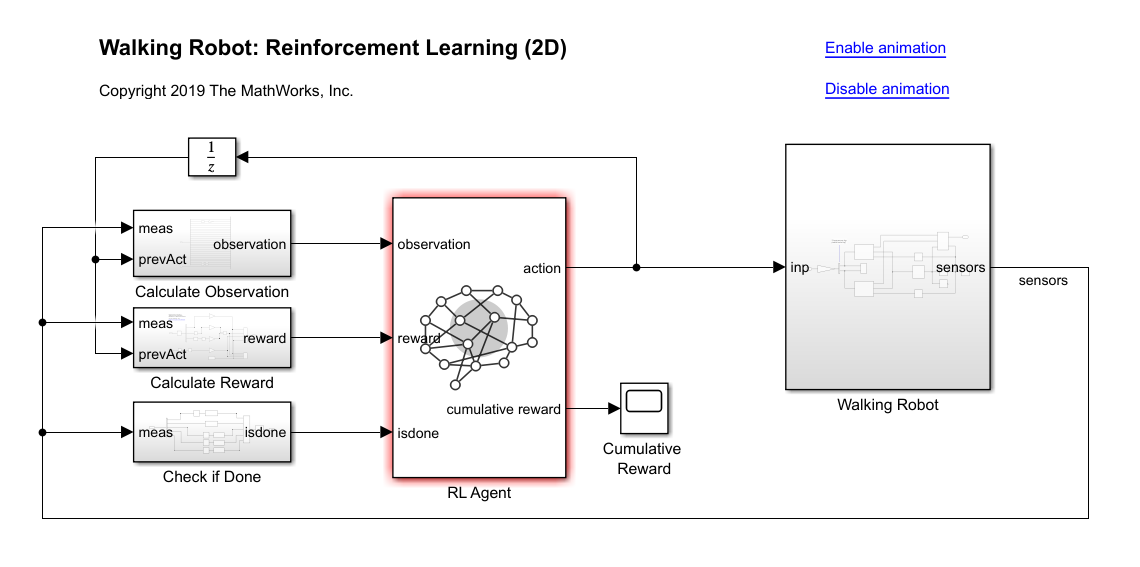
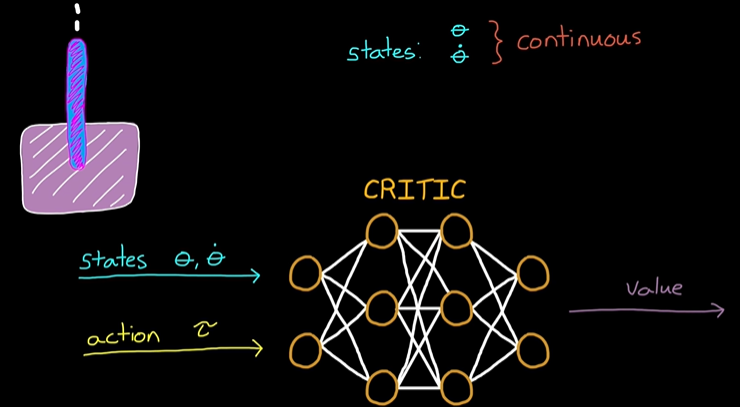
시뮬링크를 활용한 선반 사이를 지나가는 로봇을 만든다.더보기에이전트를 훈련시켰으면 에이전트가 어떻게 동작하는지 확인할 수 있습니다. sim 함수를 사용하여 시뮬레이션을 실행할 수 있습니다. out = sim(agent,environment) MAT 파일 robotmodel.mat에는 변수 agent와 env가 포함되어 있으며, 이 두 변수는 각각 사전 훈련된 RL 에이전트와 모델 whrobot.slx를 사용하는 시뮬레이션 환경을 나타냅니다. 작업 sim 함수에서 RL 에이전트 agent를 제어기로 사용하여 env에 저장된 로봇 모델의 시뮬레이션을 실행하세요. 시뮬레이션 결과를 simout이라는 변수에 저장하세요. 출력 패널에서 코드 실행 중에 시뮬레이션이 어떻게 애니메이션되는지 살펴보세요.simout =..