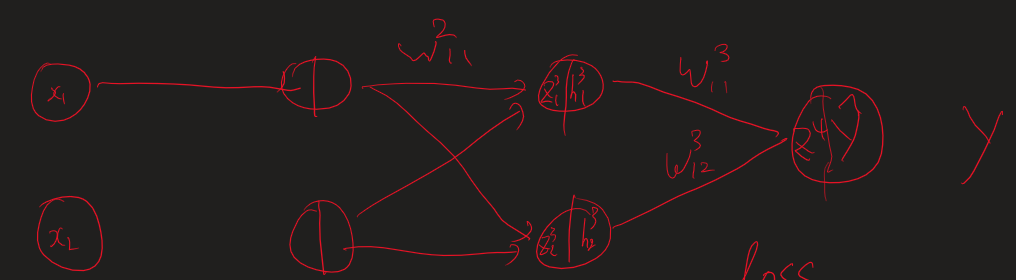
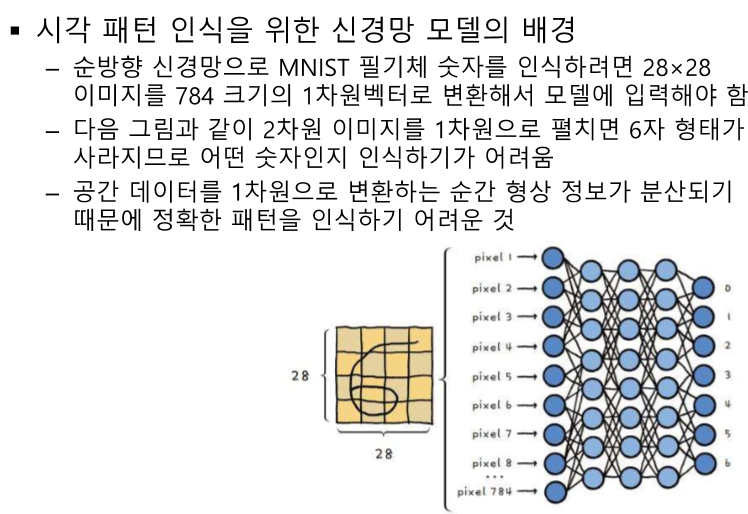
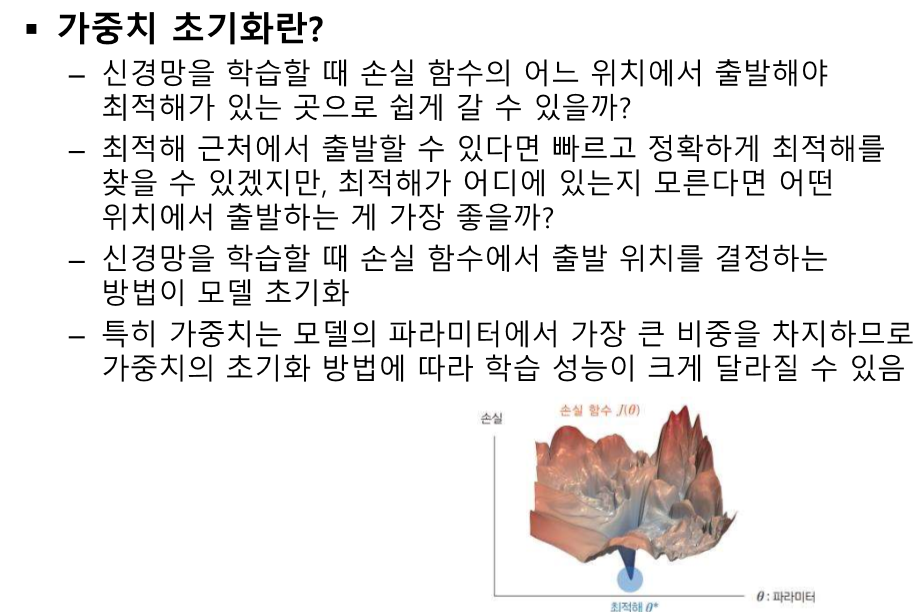
단순하게 이렇게 이어진 네트워크가 있다고 가정하겠습니다. 입력은 x, 가중치와 곱해진 값들은 z, activation함수를 통과하면 h, 출력값은 y_hat입니다. 일단 이 경우에는 loss function으로 binary Cross entropy와 MSE를 사용하는 2가지 경우로 볼 수 있죠 그럼 가장 가까운 가중치인 3번째 layer의 첫번째 node에서 나오는 weight를 업데이트 해봅시다. 일단 loss function을 미분해야죠 벌써 지저분.. 그리고 Prediction y (y hat)를 미분합니다. 이것은 z값에 sigmoid를 씌운 값으로 sigmoid 미분을 진행합니다. sigmoid 미분은 하려고하면 귀찮지만 외우면 단순합니다.. 그럼 이제 마지막으로 파라미터로 미분을 때려주면 이전..