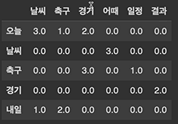
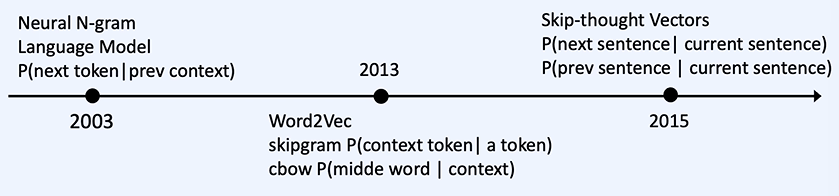
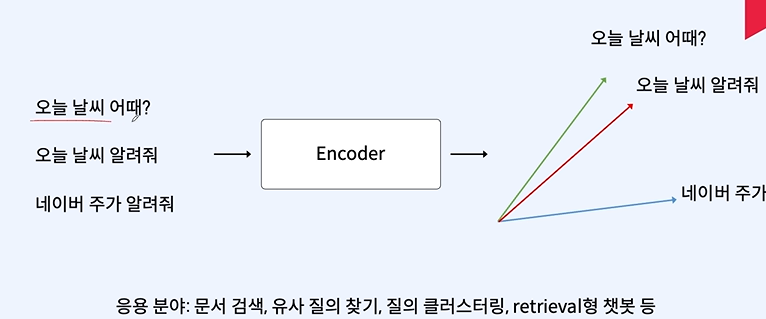
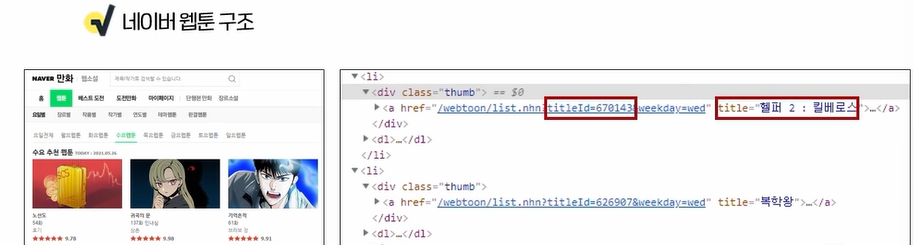
목표 - 자연어 처리 Task를 수행하는 절차 중 모델링, 모델 학습 및 평가 과정에 대해 이해할 수 있다. 기계번역 - 한국어 소스 -> 영어소스 = 영어 토큰으로 변환 최대 확률을 가지는 토큰을 가져온다! 문장 구조 상, 의미 상 가장 높은 확률을 가지는 토큰을 선택한다. 어순이 바른 것이 높은 확률을 가진다. SOTA = 그 분야에서 제일 적합한 모델 상황에 따른 결정들이 많이 다르다! 내가 사용할 수 있는 리소스의 한계를 알아두기 모델 평가 시점도 중요하다! 모델 학습이 끝난 후 평가를 진행하면 재학습을 처음부터 다시해야 하는 경우가 있을 수 있다. validation 데이터 셋을 사용하여 학습을 잘 체크한다! 오버 피팅에 대한 값은 validation과 train의 오차를 통해 확인 8/2로 나..