https://arxiv.org/abs/2405.17428
NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models
Decoder-only large language model (LLM)-based embedding models are beginning to outperform BERT or T5-based embedding models in general-purpose text embedding tasks, including dense vector-based retrieval. In this work, we introduce the NV-Embed model, inc
arxiv.org
이 논문에서도 단방향 Attention에 대해 성능이 좋지 않다고 말하고, Latent Attention을 제안합니다.

단계 자체는 엄청 쉽게 표현을 잘 해 놨습니다.

평상시의 Attention연산에 dk로 나눈 것 빼고 거의 그대로 입니다.
검색 작업과 분류, 클러스터링과 같은 비검색 작업을 잘 할 수 있게 하기 위해 2단계 튜닝을 거칩니다.
여기선 PEFT를 활용해 LoRA로 Fine-tuning 작업을 진행했습니다.

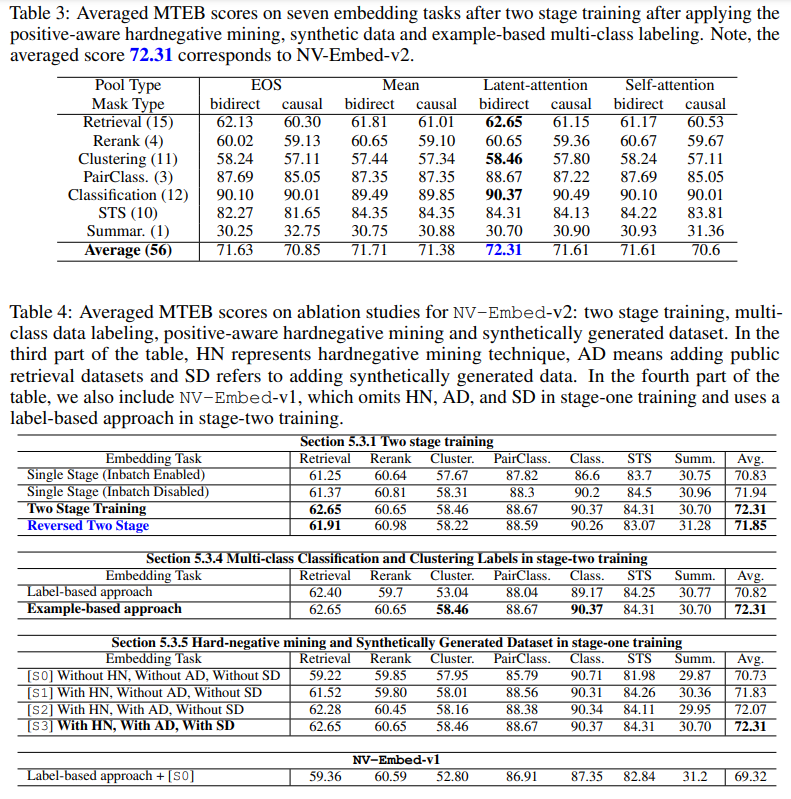
Latent-Attention이 평균에서 1등을 차지하게 되었습니다.
Ablation Study에서도 모든 단계가 중요함을 보여줍니다.
항목내용
| 모델의 주요 목적 | 디코더-only LLM을 텍스트 임베딩 및 검색 작업에 최적화하여 성능을 향상시키는 모델 |
| 핵심 기법 | 1. 잠재 주의 레이어(latent attention): 더 나은 시퀀스 임베딩을 생성 |
| 2. 두 단계 대조적 훈련(two-stage contrastive training): 검색과 비검색 작업을 단계별로 훈련 | |
| 3. 하드 네거티브 샘플링(hard-negative mining): 어려운 부정 샘플을 통해 모델 학습 강화 | |
| 모델 구조 | 디코더-only LLM 기반, 잠재 주의 레이어를 추가하여 평균 풀링보다 성능 향상 |
| 훈련 방법 | - 첫 번째 단계: 검색 관련 데이터셋을 이용한 대조적 훈련 (인배치 네거티브 사용) |
| - 두 번째 단계: 검색 및 비검색 작업을 혼합하여 명령어 튜닝을 통해 학습 (인배치 네거티브 미사용) | |
| 데이터셋 | - 검색 데이터셋: MSMARCO, HotpotQA, SQuAD, PAQ 등 |
| - 비검색 데이터셋: Amazon Reviews, IMDb, Emotion, TweetSentimentExtraction 등 | |
| - 합성 데이터: Mixtral-8x22B-Instruct 모델을 사용하여 생성된 합성 데이터로 작업 확장 | |
| 성능 | - MTEB에서 1위 달성 (NV-Embed-v2: 72.31점) |
| - 검색 작업과 긴 문서 처리에서 뛰어난 성과 | |
| - AIR-Benchmark에서 Long Doc 최고 성과, QA 두 번째 성과 | |
| 장점 | 1. 검색 성능 향상 (특히 BEIR과 MTEB에서) |
| 2. 효율적 훈련: 두 단계 훈련 방식으로 더 나은 성능을 발휘, 다양한 작업을 잘 처리 | |
| 3. 일반화 능력 향상: 하드 네거티브 샘플링과 합성 데이터로 다양한 작업을 잘 처리 | |
| 단점 | 1. 모델 크기: Mistral 7B와 같은 큰 모델을 사용하여 자원 소모가 큼 |
| 2. 재현성 문제: 합성 데이터나 하드 네거티브 샘플링 설정을 재현하기 어려움 | |
| 훈련 전략 | - 두 단계 훈련: 검색 특화 후 비검색 작업을 혼합하여 일반화 |
| 핵심 차별화 요소 | - 디코더-only LLM을 사용한 검색 및 임베딩 성능 향상 |
| - 잠재 주의 레이어를 통한 더 정확한 임베딩 생성 | |
| - 하드 네거티브 샘플링과 합성 데이터를 통한 데이터 확장 및 강력한 임베딩 학습 |
이 논문에서는 NV-Embed라는 모델을 소개하며, 대형 언어 모델(LLM)을 텍스트 임베딩 및 검색 작업에서 뛰어난 성능을 발휘할 수 있도록 훈련하는 방법에 대해 설명합니다. 이 모델은 기존의 양방향 임베딩 모델과 달리 디코더 기반의 LLM을 사용하여 성능을 크게 향상시키는 다양한 기술을 적용하였습니다.
1. 문제 정의 및 목적
- 기존의 양방향 임베딩 모델들은 텍스트 임베딩 작업에서 우수한 성능을 보여왔지만, 최근 디코더 기반 LLM들이 점차 더 나은 성과를 보이며 관심을 끌고 있습니다. 이 논문에서는 이러한 디코더-only LLM을 텍스트 임베딩 모델로 최적화하는 방법을 제시하고, 그 성능을 기존 모델들과 비교합니다.
2. 사용된 기술
- 모델 아키텍처: NV-Embed는 '잠재 주의(latent attention)' 레이어를 도입하여 시퀀스의 임베딩을 더욱 정교하게 추출합니다. 기존의 평균 풀링(mean pooling) 방식이나 마지막 토큰(EOS)의 임베딩을 사용하는 방식보다 훨씬 더 우수한 성능을 보입니다.
- 훈련 방법: 두 단계로 진행되는 대조적 훈련(constrastive training) 방법을 사용합니다. 첫 번째 단계에서는 검색 데이터셋을 사용하여 모델을 훈련하고, 두 번째 단계에서는 다양한 비검색 데이터셋을 결합하여 모델을 개선합니다.
- 데이터셋: 공개된 검색 및 비검색 데이터셋을 사용하고, 데이터셋을 커스터마이즈하여 모델의 성능을 높이는 '하드 네거티브 샘플링(hard-negative mining)'과 같은 기법을 사용합니다.
3. 주요 성과
- NV-Embed-v1은 MTEB(Massive Text Embedding Benchmark)에서 56개 임베딩 작업에서 최고 점수를 기록했으며, NV-Embed-v2는 이를 개선하여 72.31점으로 새 기록을 세웠습니다.
- 또한, AIR-Benchmark에서도 Long Doc 섹션에서 최고의 성과를 거두었고, QA 섹션에서 두 번째로 높은 성과를 보였습니다.
4. 구체적인 기술적 기여
- 두 단계 훈련: 첫 번째 단계에서 검색 작업에 집중한 대조 훈련을 진행하고, 두 번째 단계에서는 검색과 비검색 작업을 혼합하여 성능을 전반적으로 개선합니다.
- 잠재 주의 레이어: 기존의 평균 풀링 방식을 대체하여, 더 표현력이 강한 시퀀스 임베딩을 생성합니다. 이는 검색 작업에서 특히 중요한 성능 향상으로 이어졌습니다.
- 하드 네거티브 샘플링: 기존의 텍스트 데이터셋에서 하드 네거티브 샘플을 찾아내어 모델이 보다 강력한 학습을 할 수 있도록 도와줍니다.
5. 결과
- NV-Embed 모델은 MTEB에서 56개 임베딩 작업에 대해 최고 성과를 달성했으며, AIR-Benchmark에서도 다른 모델들을 능가하는 성능을 보여주었습니다. 이 모델은 특히 검색 및 긴 문서 관련 작업에서 뛰어난 성과를 보였습니다.
6. 결론
- NV-Embed는 LLM 기반 임베딩 모델에서 획기적인 성과를 달성하며, 기존의 모델들에 비해 우수한 성능을 보입니다. 또한, 제시된 방법은 간단하면서도 재현 가능하고, 다른 연구자들이 쉽게 따라 할 수 있도록 공개되어 있습니다.
이 논문은 특히 LLM을 활용한 텍스트 임베딩 작업에서 성능을 극대화하는 새로운 방법론을 제시하며, 향후 RAG(검색 기반 생성 모델)과 같은 응용 분야에서 매우 중요한 기여를 할 수 있을 것으로 보입니다.
NV-Embed: 방법론
이 논문에서는 NV-Embed라는 모델을 제안하며, 이를 통해 디코더-only 대형 언어 모델(LLM)을 텍스트 임베딩 및 검색 작업에서 더 우수하게 훈련하는 방법을 제시합니다. 특히, 모델 구조, 훈련 방법, 데이터셋에 대한 혁신적인 접근 방식을 다루고 있습니다.
1. 모델 구조의 변경
기존 구조와 문제점
기존의 임베딩 모델들은 주로 양방향(BERT 또는 T5) 언어 모델을 기반으로 하여 텍스트를 임베딩합니다. 양방향 모델은 입력의 양쪽 문맥을 모두 고려할 수 있어 강력한 성능을 보입니다. 그러나 최근 디코더-only LLM(예: GPT 계열 모델)을 텍스트 임베딩에 적용한 연구들이 그 성능을 능가하기 시작했습니다. 하지만 기존 디코더-only LLM은 몇 가지 한계가 있습니다.
- 한정된 표현력: 디코더-only 모델은 단방향 주의(causal attention) 방식을 사용하기 때문에, 문맥을 더 넓게 이해하는 데 한계가 있었습니다.
- 풀링 방식: 임베딩을 생성할 때 토큰의 임베딩을 사용하거나 평균 풀링을 사용하여 임베딩을 생성하는 방식이 많이 사용되었습니다. 이 방식들은 중요한 정보가 손실될 수 있습니다.
NV-Embed 모델의 변경점
NV-Embed는 이 한계를 극복하고자 다음과 같은 구조적 개선을 도입했습니다.
- 잠재 주의(latent attention) 레이어: 기존의 평균 풀링 방식 또는 토큰 임베딩 방식에 비해 더 표현력이 강한 시퀀스 임베딩을 생성하기 위해, 잠재 주의 레이어(latent attention layer)를 도입했습니다. 이 레이어는 시퀀스에서 중요한 토큰들의 정보를 더 잘 반영할 수 있도록 도와줍니다. 이를 통해 문장 내 중요한 구절들이 덜 희석되도록 하고, 문장의 의미를 더 잘 캡처합니다.
- 구조: 디코더의 마지막 레이어에서 나온 출력(Q - 쿼리)을 latent 배열(K, V)과 크로스 어텐션하여 더 나은 표현을 얻습니다. 이 후, 출력은 MLP(다층 퍼셉트론)를 통해 최종 임베딩을 생성합니다.
- 주목할 점: 자기 어텐션(self-attention)과 잠재 주의(latent attention)를 비교한 실험에서, 잠재 주의가 대부분의 임베딩 작업에서 뛰어난 성과를 보였다는 것을 확인할 수 있습니다. 특히, 검색(retrieval) 작업에서 nDCG@10 등의 성능이 향상되었습니다.
2. 훈련 방법의 변경
NV-Embed의 훈련 방법은 두 단계 대조적 훈련(two-stage contrastive training)이라는 새로운 방식으로 개선되었습니다. 이 방식은 두 가지 주요 훈련 단계로 나뉩니다.
두 단계 대조적 훈련
- 첫 번째 단계 (Retrieval-focused contrastive training):
- 이 단계에서는 검색(retrieval) 관련 데이터셋을 사용하여 모델을 훈련시킵니다.
- 대조적 훈련(contrastive learning)을 통해, 질문과 관련된 긍정적 문서(positive documents)와 관련 없는 부정적 문서(negative documents)를 구분하는 방법을 학습합니다.
- 인배치 네거티브 샘플(in-batch negatives): 훈련 데이터 내에서 각 배치에 대해 부정적인 샘플을 생성하여, 모델이 긍정적인 예와 부정적인 예를 명확하게 구분할 수 있도록 합니다.
- 두 번째 단계 (Non-retrieval task blending):
- 두 번째 단계에서는 검색 외의 다양한 작업들(분류, 클러스터링 등)을 함께 훈련시킵니다.
- 이 단계에서는 인배치 네거티브 샘플을 비활성화하여, 검색 외의 작업에서 부정적인 예시들이 검색 작업에 방해가 되지 않도록 합니다.
- 훈련 데이터: 다양한 비검색 데이터셋을 추가하여 모델이 다양한 작업을 잘 처리할 수 있도록 합니다. 이를 통해 검색 성능뿐만 아니라 분류(classification), 클러스터링(clustering), 문서 유사도 등 다양한 작업에서도 높은 성능을 얻을 수 있었습니다.
3. 학습 데이터
훈련에 사용된 데이터셋은 크게 검색 데이터셋과 비검색 데이터셋으로 나눠집니다.
검색 데이터셋 (Public retrieval datasets)
- 모델이 임베딩을 잘 학습할 수 있도록 여러 검색 관련 데이터셋을 사용합니다. 주요 데이터셋은 다음과 같습니다:
- MS MARCO: 대규모 질의응답 데이터셋.
- HotpotQA: 다중 홉 질문 답변 데이터셋.
- PAQ, SQuAD, Stack Exchange 등: 다양한 질의응답 데이터셋들이 포함됩니다.
비검색 데이터셋 (Public non-retrieval datasets)
- 분류, 클러스터링, 문서 유사도 등의 비검색 작업을 수행하기 위한 데이터셋이 사용됩니다. 예를 들어, Amazon 리뷰, IMDb 영화 리뷰, Emotion 데이터셋 등이 사용됩니다.
하드 네거티브 샘플링 (Hard-negative mining)
- 하드 네거티브 샘플링 기술을 통해, 긍정적인 문서와 잘못된 문서들을 구분하는 작업을 더욱 정교하게 만듭니다. 이를 통해 훈련된 모델은 잘못된 부정적 샘플을 잘 거르며, 학습 성능을 극대화합니다.
합성 데이터 (Synthetic data)
- 기존의 데이터셋에 추가하여 합성 데이터를 생성하여 다양성과 일반화 능력을 높입니다. 예를 들어, Mixtral-8x22B 모델을 사용하여 약 120,000개의 합성 샘플을 생성했습니다. 이 데이터는 훈련에서 중요한 역할을 합니다.
4. 훈련 결과
NV-Embed는 MTEB(Massive Text Embedding Benchmark)와 같은 벤치마크에서 뛰어난 성과를 보였으며, 특히 검색 및 긴 문서 처리 작업에서 우수한 결과를 달성했습니다.
- MTEB 벤치마크에서 NV-Embed-v2는 72.31점을 기록하며 No.1을 달성했습니다.
- AIR-Benchmark에서도 Long Doc과 QA 섹션에서 높은 성과를 보여주었습니다.
결론
NV-Embed는 디코더-only LLM을 임베딩 작업에 최적화하는 혁신적인 접근 방식을 제시했습니다. 이 모델은 잠재 주의 레이어, 두 단계 대조적 훈련 및 하드 네거티브 샘플링과 같은 기법을 통해 성능을 획기적으로 향상시켰습니다. 특히, 검색 작업에서의 성능 개선은 LLM 기반 임베딩 모델이 실용적인 텍스트 검색 시스템으로 변모할 수 있음을 시사합니다.
관련 연구와 논문
NV-Embed는 기존의 양방향 임베딩 모델(BERT, T5 등) 및 디코더-only LLM(GPT 계열 모델)을 텍스트 임베딩 및 검색 작업에 활용한 최근 연구들과 비교하여 우수한 성과를 보입니다. 이 모델은 특히 검색 및 일반화 성능을 향상시키는 방법론을 제시하고 있습니다. 관련된 연구들은 대부분 텍스트 임베딩 성능을 향상시키기 위한 다양한 방법론을 제시하고 있으며, NV-Embed가 기존 연구들과 어떻게 차별화되는지, 그 장단점을 구체적으로 설명하겠습니다.
1. 관련 연구
(1) BERT 기반 모델
- BERT(Bidirectional Encoder Representations from Transformers, Devlin et al., 2018)은 양방향 트랜스포머를 기반으로 하여 텍스트 이해 작업에서 뛰어난 성능을 보였으며, 텍스트 임베딩 모델로 널리 사용되었습니다. Sentence-BERT(Reimers & Gurevych, 2019)나 SimCSE(Gao et al., 2021)와 같은 모델들은 BERT를 기반으로 대조적 학습을 통해 텍스트 임베딩 성능을 개선했습니다.
- 장점: 양방향 트랜스포머 구조로 문맥을 더 잘 이해하고, 다양한 다운스트림 작업에 잘 일반화됩니다.
- 단점: 계산 비용이 매우 크고, 속도나 효율성에서 제한적입니다. 특히 검색 작업에서는 비교적 느리고 비효율적일 수 있습니다.
(2) T5 기반 모델
- T5(Text-to-Text Transfer Transformer, Raffel et al., 2020)는 텍스트를 입력-출력 변환 문제로 처리하여 다양한 자연어 처리 작업을 처리할 수 있는 범용 모델로 설계되었습니다. 대조적 학습을 적용한 T5 기반 임베딩 모델들이 많습니다.
- 장점: 다양한 텍스트 작업을 통합적으로 처리할 수 있는 유연성이 있습니다.
- 단점: 속도와 효율성에 있어서 BERT와 유사한 단점이 존재하며, 특정 작업에서 세부적인 성능이 부족할 수 있습니다.
(3) E5-Mistral
- E5-Mistral(Wang et al., 2023b)은 대규모 디코더-only LLM을 사용하여 텍스트 임베딩을 학습하는 모델입니다. 이 모델은 대조적 학습을 통해 텍스트 임베딩을 생성하며, 기존의 BERT 및 T5 모델들보다 더 나은 성능을 보였습니다.
- 장점: 디코더-only LLM을 사용하여 더 효율적인 텍스트 임베딩을 생성할 수 있으며, 검색 작업에서 우수한 성과를 보여줍니다.
- 단점: 모델 크기가 커지면 계산 자원 소모가 크며, 합성 데이터와 비공개 데이터에 의존하는 경우가 많아 재현성에 제약이 있을 수 있습니다.
(4) LLM2Vec
- LLM2Vec(BehnamGhader et al., 2024)은 대형 언어 모델을 임베딩 생성기로 변환하는 접근 방식입니다. 이 방법은 자체 훈련을 통해 강력한 임베딩을 생성합니다.
- 장점: 공개된 데이터만을 사용하여도 강력한 임베딩을 학습할 수 있습니다.
- 단점: 디코더-only 모델의 한계인 단방향 어텐션 문제와 고차원 임베딩에 따른 차원의 저주 문제에 직면할 수 있습니다.
2. NV-Embed와 기존 연구의 차이점
(1) 모델 아키텍처의 차이점
- 기존의 양방향 임베딩 모델(BERT, T5)은 양방향 트랜스포머 구조를 사용하지만, NV-Embed는 디코더-only LLM을 사용하며, 잠재 주의 레이어(latent attention)를 도입하여 더 우수한 임베딩 성능을 보입니다. 이 잠재 주의 레이어는 평균 풀링 방식이나 토큰 임베딩 방식보다 중요한 정보를 더 잘 반영합니다.
- 기존 모델: 평균 풀링이나 토큰을 기반으로 하는 임베딩은 중요한 구절의 의미를 희석시킬 수 있습니다.
- NV-Embed: 잠재 주의 레이어를 통해, 문장의 중요한 구절들을 보다 잘 반영할 수 있어 정확한 임베딩을 생성합니다.
(2) 훈련 방법의 차이점
- 기존 모델들은 대부분 단일 훈련 단계에서 대조적 학습을 진행하며, 검색 데이터셋만을 사용하여 학습합니다. 반면, NV-Embed는 두 단계 훈련을 사용합니다. 첫 번째 단계에서는 검색 관련 데이터셋을 이용해 대조적 훈련을 진행하고, 두 번째 단계에서는 다양한 비검색 데이터셋을 추가하여 비검색 작업(분류, 클러스터링 등)까지 잘 처리할 수 있도록 합니다.
- 기존 모델: 검색과 비검색 작업을 동일한 방식으로 훈련하며, 특정 작업에 특화된 성능을 내지 못할 수 있습니다.
- NV-Embed: 검색에 특화된 훈련을 먼저 진행하고, 그 후 다양한 비검색 작업을 혼합하여 더 범용적인 성능을 발휘합니다.
(3) 데이터셋 사용의 차이점
- 기존의 모델들은 대부분 공개된 검색 데이터셋을 사용하여 훈련되며, 하드 네거티브 샘플링이나 합성 데이터를 사용하지 않는 경우가 많습니다. NV-Embed는 하드 네거티브 샘플링 및 합성 데이터 생성 기법을 활용하여 훈련 데이터를 개선하고, 다양한 작업에서 고른 성능을 보여줍니다.
- 기존 모델: 주로 공개된 데이터셋을 기반으로 훈련하며, 추가적인 데이터 생성 방법을 활용하지 않음.
- NV-Embed: 하드 네거티브 샘플링, 합성 데이터 생성 등을 통해 훈련 데이터를 개선하여, 보다 강력한 일반화 능력을 발휘합니다.
3. NV-Embed의 장점과 단점
장점
- 성능 향상:
- NV-Embed는 검색 작업 및 다양한 다운스트림 작업에서 상위 성능을 기록하였습니다. 특히 대규모 벤치마크에서 우수한 결과를 보였으며, Long Doc 및 QA 작업에서도 뛰어난 성과를 보였습니다.
- 효율성:
- 디코더-only LLM을 활용함으로써 계산 효율성이 향상됩니다. 기존의 양방향 모델들보다 더 효율적인 학습과 추론을 가능하게 합니다.
- 일반화 능력:
- 두 단계 훈련 방식을 통해, 검색뿐만 아니라 비검색 작업에서도 강력한 성능을 보입니다. 하드 네거티브 샘플링과 합성 데이터를 통해 일반화 능력을 더욱 향상시킬 수 있습니다.
단점
- 모델 크기:
- Mistral 7B와 같은 대형 모델을 기반으로 하기 때문에, 훈련 및 추론 과정에서 모델 크기로 인한 자원 소모가 큽니다. 이는 비용과 시간이 많이 들 수 있습니다.
- 재현성 문제:
- 합성 데이터나 하드 네거티브 샘플링을 사용할 때, 그 정확한 설정이나 데이터셋을 재현하기 어려울 수 있습니다. 이로 인해 다른 연구자들이 모델을 재현하기 어렵거나 성능이 달라질 수 있습니다.
결론
NV-Embed는 디코더-only LLM을 임베딩 모델로 효과적으로 활용하는 혁신적인 방법론을 제시합니다. 기존의 양방향 모델들과 비교하여 효율성, 성능, 일반화 능력 등에서 우수한 결과를 보였으며, 특히 검색 작업에서 뛰어난 성능을 보입니다. 그러나, 모델 크기나 재현성 문제 등에서 개선이 필요할 수 있습니다.
결과
NV-Embed 모델은 다양한 텍스트 임베딩 작업에서 뛰어난 성과를 보였으며, 특히 검색(retrieval)과 긴 문서 처리(long document) 작업에서 탁월한 성능을 발휘했습니다. 주요 실험 결과는 다음과 같습니다:
- MTEB(Massive Text Embedding Benchmark):
- NV-Embed-v1은 56개 임베딩 작업에서 1위를 차지했으며, NV-Embed-v2는 이를 개선하여 72.31점으로 No.1 자리를 유지하였습니다.
- 검색 작업(retrieval)에서는 15개 과제 중 최고 성과를 기록했으며, 클러스터링, 분류, STS(semantic textual similarity) 작업에서도 우수한 성과를 보였습니다.
- AIR Benchmark:
- Long Doc 섹션에서 최고 점수를 기록했으며, QA(질문 응답) 섹션에서는 두 번째로 높은 점수를 달성했습니다. 이는 NV-Embed 모델이 다양한 도메인에서 뛰어난 일반화 성능을 가지고 있음을 보여줍니다.
- AIR Benchmark에서 출판, 법률, 의료와 같은 특수한 도메인에 대해 모델이 강력한 성능을 보였으며, MTEB와의 비교에서 일관되게 높은 점수를 기록했습니다.
결론
NV-Embed 모델은 디코더-only LLM을 텍스트 임베딩 모델로 활용하는 혁신적인 접근 방식을 제시합니다. 이 모델은 기존의 양방향 임베딩 모델들과 디코더-only LLM 기반 모델들 간의 격차를 메우고, 검색 및 일반화 능력에서 우수한 성과를 보였습니다. 구체적인 기여는 다음과 같습니다:
- 모델 아키텍처:
- 잠재 주의 레이어(latent attention)를 도입하여, 기존의 평균 풀링(mean pooling) 방식이나 토큰 임베딩보다 더 나은 시퀀스 임베딩을 생성합니다.
- 단방향 어텐션의 한계를 극복하고, 더 나은 표현력을 얻을 수 있었습니다.
- 훈련 방법:
- 두 단계 대조적 훈련(two-stage contrastive training)을 통해 검색 관련 데이터셋에 집중하여 훈련하고, 그 후 비검색 작업을 혼합하여 처리함으로써 더 일반화된 성능을 얻었습니다.
- 하드 네거티브 샘플링과 합성 데이터를 사용하여 훈련 데이터를 강화하고, 강력한 임베딩을 생성할 수 있었습니다.
- 데이터셋:
- 공개된 다양한 검색 및 비검색 데이터셋을 활용하여 모델을 훈련시켰으며, 데이터셋의 커스터마이징을 통해 더 효율적인 학습이 이루어졌습니다.
이 결과로 NV-Embed는 텍스트 임베딩 및 검색 기반 생성 모델(RAG)와 같은 응용 분야에서 실용적인 모델로 자리 잡을 수 있는 가능성을 보여주었습니다.
마무리
NV-Embed는 디코더-only LLM을 일반화된 임베딩 모델로 성공적으로 적용한 첫 번째 모델 중 하나로, 기존의 양방향 모델들보다 효율적이고 성능이 우수한 모델을 제시합니다. 특히 검색 및 다양한 임베딩 작업에서 높은 성과를 보이며, 검색 기반 생성(RAG) 및 정보 검색 시스템에서 중요한 발전을 가져올 수 있을 것입니다.
다만, 모델 크기와 재현성 문제 등의 과제가 남아 있으며, 이를 해결하기 위한 후속 연구가 필요합니다. 특히, 모델 크기에 따른 자원 소모를 줄이기 위한 방법론이나 효율적인 훈련 방법에 대한 연구가 지속적으로 이루어져야 할 것입니다.
이 연구는 텍스트 임베딩의 새로운 가능성을 제시하며, 향후 다양한 자연어 처리 작업에 대한 확장성과 효율성을 동시에 고려한 연구 방향을 제시합니다.
2단계 대조적 훈련(Contrastive Training) 및 Instruction-Tuning
NV-Embed 모델의 두 단계 훈련에서 중요한 부분은 바로 대조적 훈련(contrastive training)입니다. 이 훈련 기법은 모델이 양의 예시와 음의 예시를 구분할 수 있도록 훈련시키는 방법으로, 주로 검색 임베딩 모델에서 사용됩니다. 두 번째 단계는 이러한 대조적 훈련을 명령어 튜닝(instruction-tuning)과 결합하여 모델이 다양한 작업에서 잘 일반화될 수 있도록 합니다.
대조적 훈련의 개념
대조적 훈련은 양의 샘플과 음의 샘플 간의 유사성을 학습하는 방식입니다. 예를 들어, 질문-문서 쌍에서 질문과 관련된 문서(양의 샘플)의 임베딩은 비슷하게 나오도록 하고, 질문과 관련이 없는 문서(음의 샘플)는 서로 다르게 나오도록 학습합니다. 이를 통해 모델은 텍스트 임베딩을 생성할 때 각 문서가 질문과 얼마나 관련 있는지를 효과적으로 판단할 수 있습니다.
- 첫 번째 단계 (검색 중심 대조적 훈련):
- 이 단계에서는 검색 관련 데이터셋을 사용하여 모델을 훈련시킵니다.
- 대조적 훈련을 사용하여 각 배치에서 질문-문서 쌍을 학습하고, 음의 샘플(관련 없는 문서)을 통해 모델이 정확한 임베딩을 생성하도록 합니다.
- 이때 인배치 네거티브 샘플(in-batch negatives)을 활용하여 훈련을 진행합니다. 인배치 네거티브 샘플은 각 배치 내에서 생성된 부정적인 샘플들로, 계산을 재사용할 수 있어 효율적인 학습을 가능하게 합니다.
- 두 번째 단계 (명령어 튜닝과 비검색 작업 통합):
- 두 번째 단계에서는 검색과 비검색 작업(예: 분류, 클러스터링 등)을 결합하여 훈련합니다.
- 이 단계에서는 검색 작업에 대한 훈련이 먼저 이루어진 후, 비검색 작업을 추가하여 모델이 다양한 작업을 처리할 수 있도록 합니다.
- 중요한 점은, 이 단계에서 인배치 네거티브 샘플을 사용하지 않는다는 것입니다. 이유는, 비검색 작업(분류, 클러스터링 등)에서는 부정적인 샘플이 클래스 내의 샘플로 올 수 있기 때문에, 이 경우 부정적인 샘플이 잘못된 학습을 유도할 수 있기 때문입니다.
- 비검색 작업에서 이 기법을 사용하지 않음으로써, 클러스터링, 분류 등의 작업에서 성능을 더욱 향상시킬 수 있습니다.
하드 네거티브 샘플링 (Hard-negative mining)
대조적 훈련에서 중요한 요소 중 하나는 하드 네거티브 샘플링입니다. 하드 네거티브는 모델이 어려운 부정 샘플을 구별할 수 있도록 도와주는 기법입니다. 이 기법은 양의 샘플과 비슷하지만 부정적인 샘플을 선택하여 모델이 더 강력하게 학습할 수 있도록 합니다.
- 예를 들어, MS MARCO와 같은 데이터셋에서는 질문-문서 쌍에 대해 부정적인 문서들을 미리 정의하기 어려운 경우가 많습니다. 따라서, 하드 네거티브 샘플링 기법을 사용하여 모델이 더 어려운 부정 샘플을 찾아내도록 유도합니다.
- 이를 통해 잘못된 부정 샘플을 필터링하고, 모델이 정확한 유사성을 학습할 수 있도록 돕습니다.
Instruction-Tuning
Instruction-Tuning은 명령어 기반 훈련 방법으로, 모델이 주어진 **작업(Task)**을 잘 수행할 수 있도록 학습시키는 방법입니다. 이 방법은 대형 언어 모델이 특정 작업에 대해 지침을 따라 수행하는 능력을 향상시키기 위해 사용됩니다.
- 검색 및 비검색 작업의 조합:
- 첫 번째 단계에서 주로 검색 관련 작업을 다룬 후, 두 번째 단계에서는 분류, 클러스터링과 같은 비검색 작업을 명령어를 통해 조정하여 훈련합니다.
- 예를 들어, 문서 분류 작업에서는 "이 문서가 어떤 카테고리에 속하는지"라는 명령어가 주어지고, 모델은 그 명령어를 따라 문서를 분류합니다.
- 이 훈련은 모델이 다양한 작업에 적응할 수 있게 도와주며, 제시된 작업에 맞춰 결과를 생성하도록 합니다.
- 하드 네거티브 샘플링과 명령어:
- 훈련 데이터셋에서 하드 네거티브 샘플링과 명령어 튜닝을 결합하여, 모델이 더 어려운 부정 샘플을 처리하고, 작업 지침에 맞게 적응할 수 있도록 합니다.
- 합성 데이터와 작업 예시:
- 합성 데이터(Synthetic data)는 다양한 작업 예시를 생성하여 모델이 더 많은 작업을 처리할 수 있도록 돕습니다. 이 데이터는 Mixtral-8x22B-Instruct-v0.1 모델을 사용하여 생성되며, 모델이 다양한 작업을 잘 학습할 수 있도록 합니다.
- 예를 들어, 단기-장기 형태의 문서 쌍을 생성하여 모델이 다양한 문서 길이에 대해 잘 처리하도록 유도합니다.
결론
NV-Embed 모델은 두 단계 대조적 훈련을 통해, 검색 및 비검색 작업에서 높은 성능을 발휘합니다. 첫 번째 단계에서는 검색에 특화된 훈련을 집중적으로 수행하고, 두 번째 단계에서는 다양한 작업을 처리할 수 있도록 모델을 명령어 튜닝과 결합하여 일반화 능력을 향상시킵니다. 하드 네거티브 샘플링 기법과 합성 데이터를 활용하여 모델이 더 강력한 임베딩을 생성하도록 돕습니다.