https://arxiv.org/abs/2305.16653
AdaPlanner: Adaptive Planning from Feedback with Language Models
Large language models (LLMs) have recently demonstrated the potential in acting as autonomous agents for sequential decision-making tasks. However, most existing methods either take actions greedily without planning or rely on static plans that are not ada
arxiv.org
Planner - 작은 단위의 목표로 나누고, 각 목표를 달성하기 위해 계획을 작성, 예상되는 환경 피드백을 미리 예측
Refiner - 실제 환경 피드백을 수신하여 예상과 실제를 비교, 계획 유지 및 수정을 결정
일치할 경우 - In plan Feedback : 추가 정보를 추출해 다음 단계 실행에 활용
일치하지 않을 경우 - Out of Plan Feedback : 계획 전체를 수정
성공 경험은 누적하여 유사 작업에 사용됩니다.
| 문제 정의 | 기존 LLM 기반 계획 시스템은 환경 피드백에 유연하게 대응하지 못함. - 오픈 루프: 피드백 반영 없음 → 장기적 문제 해결에 취약 - 암시적 폐쇄 루프: 단일 액션만 수정 → 전체 계획은 고정 - 명시적 폐쇄 루프: 전체 계획 수정 가능하지만 데이터 요구량 큼 |
| 연구 목표 | LLM 기반 에이전트가 환경 피드백에 실시간으로 적응하며 계획을 지속적으로 개선할 수 있도록 하는 폐쇄 루프 시스템 개발 |
| 핵심 기여 | ✅ 인-플랜 & 아웃-오브-플랜 리파인먼트를 통한 실시간 계획 적응 ✅ 코드 기반 프롬프트로 계획의 명확성 확보 및 환각 감소 ✅ 스킬 발견 메커니즘으로 샘플 효율성 극대화 ✅ 실행 중단 없이 중간 단계에서 계획 재개 가능 |
| 모델 구성 요소 | 🔹 LLM 기반 에이전트: 계획 생성(플래너) + 계획 수정(리파이너) 🔹 스킬 메모리 모듈: 성공한 계획과 상호작용 저장 → 미래 작업에서 재사용 |
| 작동 원리 | 1️⃣ 초기 계획 생성: 작업 목표 입력 → 코드 기반 계획 작성 2️⃣ 계획 실행 & 피드백 수신: 단계별 실행 및 피드백 수신 3️⃣ 피드백 처리: - 인-플랜 리파인먼트: 예상 피드백 일치 시 정보 추출 및 다음 단계 진행 - 아웃-오브-플랜 리파인먼트: 예상과 다를 시 전체 계획 수정 및 중간 단계 재개 4️⃣ 작업 완료 시 스킬 저장: 향후 유사 작업에 사용 |
| 인-플랜 vs 아웃-오브-플랜 차이점 | 🟢 인-플랜: 예상된 피드백 처리 → 정보 추출 및 계획 보강 🔴 아웃-오브-플랜: 예상과 다른 피드백 시 전체 계획 수정 및 재개 |
| 스킬 발견 메커니즘 | ✅ 성공 계획 저장 → 새로운 작업에서 Few-shot 예시로 사용 ✅ 불필요한 스킬 제거로 장기적 성능 유지 및 샘플 절약 |
| 실험 환경 | 🔸 ALFWorld: 가상 가정 환경 (134개 작업) 🔸 MiniWoB++: 웹 UI 상호작용 환경 (53개 작업 중 9개는 피드백 제공) |
| 실험 결과 요약 | 🔥 ALFWorld (134 작업): - AdaPlanner: 91.79% 성공률 (기존 최고 대비 +3.73%) - 기존 방법보다 2배 적은 샘플로 우수 성능 달성 🔥 MiniWoB++ (53 작업): - AdaPlanner: 92.87% 성공률 (CC-Net과 유사 성능) - 샘플 사용량은 600배 감소 |
| 성분별 기여도 (Ablation Study) | 🔎 코드 기반 프롬프트 제거 시: 성능 최대 -35% 감소 🔎 스킬 발견 제거 시: 성능 최대 -26% 감소 ✅ 두 구성 요소 모두 성능 유지에 핵심적 |
| 환각 감소 효과 | ✅ 코드 기반 프롬프트 사용으로 모델 환각 현상 대폭 감소 ✅ GPT-3.5-turbo 환경에서 타 방법 대비 안정적 계획 수립 |
| 한계점 | 🚫 Few-shot 샘플 의존성: 복잡한 작업에선 여전히 소수 샘플 필요 🚫 긴 계획 수립 시 계산 비용 증가 가능성 |
| 향후 연구 방향 | ✅ Zero-shot 작업 수행 능력 강화 ✅ 멀티 에이전트 협업 및 계획 공유 연구 ✅ 더 긴 계획 수립 및 모델 경량화 연구 |
| 결론 및 의의 | 🎯 AdaPlanner는 LLM 기반 에이전트의 계획 적응성, 샘플 효율성, 안정성을 모두 개선 ✅ 샘플 사용량 절감 + 성능 유지 → 실제 적용성 높음 ✅ 자율 로봇 제어, 웹 자동화, 가상 비서 등 다양한 분야에 적용 가능 |



https://arxiv.org/abs/2304.11477
LLM+P: Empowering Large Language Models with Optimal Planning Proficiency
Large language models (LLMs) have demonstrated remarkable zero-shot generalization abilities: state-of-the-art chatbots can provide plausible answers to many common questions that arise in daily life. However, so far, LLMs cannot reliably solve long-horizo
arxiv.org
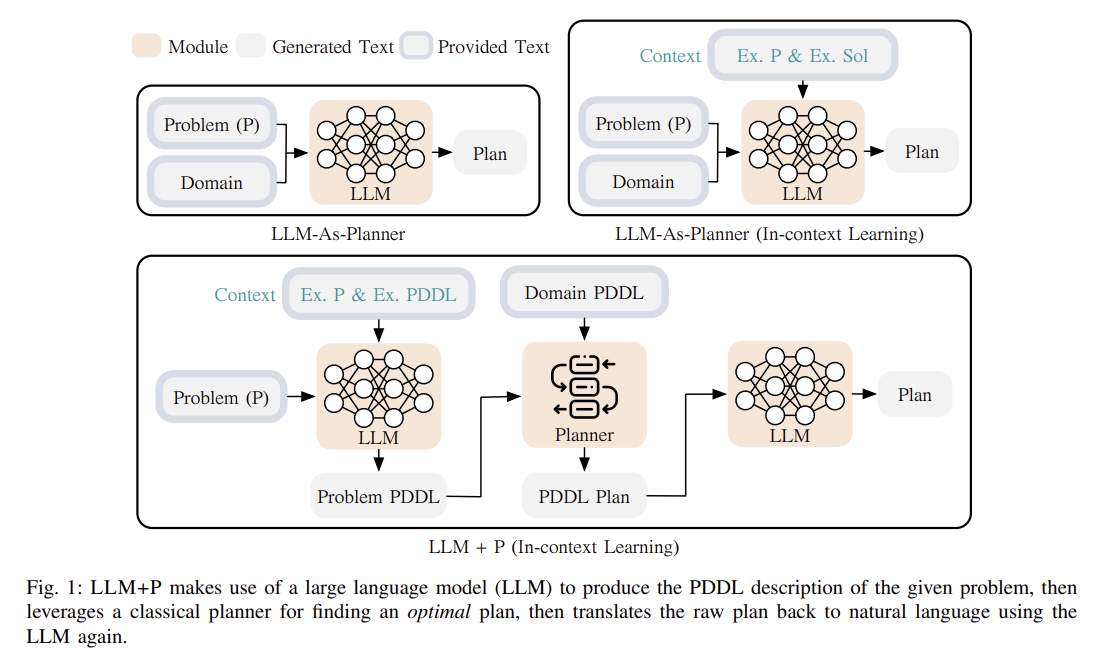

🧠 논문 전체 내용 요약
| 📌 문제 정의 | LLM은 자연어 이해에 뛰어나지만 장기 계획 문제(long-horizon planning) 해결 능력이 부족함 |
| 🚀 제안 방법 | LLM+P: LLM의 자연어 이해력 + Planner의 최적 계획 탐색 능력 결합 |
| 📝 방법론 구성 | 1️⃣ 자연어 문제 해석 (LLM) → 2️⃣ PDDL 변환 (LLM) → 3️⃣ 계획 탐색 (Planner) → 4️⃣ 자연어 결과 변환 (LLM) |
| 🧩 핵심 아이디어 | - LLM: 자연어 ↔ PDDL 번역 담당 - Planner: 탐색 최적화 및 정확한 계획 생성 - 콘텍스트 학습: 이전 문제 예시 제공 시 성능 향상 |
| 🧪 실험 도메인 | BLOCKSWORLD, BARMAN, FLOORTILE, GRIPPERS, STORAGE, TERMES, TYREWORLD (총 7개) |
| 📊 주요 결과 | - LLM 단독: 대부분 도메인에서 낮은 성공률 (20% 이하) - LLM+P: 대부분 도메인에서 90% 이상 성공률 달성 - 콘텍스트 미사용 시: 계획 탐색 실패 증가 |
| 🤖 로봇 시연 | 실세계 시연에서 최적 경로 탐색 및 실행 성공 (총 이동 비용 절감) |
| 🧩 한계 및 개선 방향 | - 문제 입력 자동 인식 기능 부재 - 인간 개입 없이 도메인 정보 생성 필요 - 실시간 환경 변화에 대한 적응성 개선 필요 |
| 🧭 향후 연구 과제 | 1️⃣ 자동 문제 유형 감지 기능 추가 2️⃣ 도메인 설명 자동화 3️⃣ 다중 에이전트 협력 계획 확장 |
🔍 LLM+P 단계별 상세 설명표
| 단계 | 설명 | LLM 역할 | Planner 역할 | 출력 예시 |
| 1 | 자연어 문제 이해 및 전처리 | 문제 해석 및 정보 추출 | - | 초기 상태 및 목표 상태 추출 |
| 2 | PDDL 문제 변환 | 자연어 → PDDL 변환 | - | 문제 및 도메인 PDDL 파일 |
| 3 | 최적 계획 탐색 | - | PDDL 기반 최적 행동 시퀀스 탐색 | PDDL 형식 행동 시퀀스 |
| 4 | 계획의 자연어 변환 | 계획 해석 및 자연어 설명 생성 | - | 사용자 친화적 자연어 계획 설명 |
| 5 | 콘텍스트 학습 적용 (선택적) | 예시 참조로 변환 정확도 개선 | - | 계획 탐색 성공률 증가 |
https://arxiv.org/abs/2308.06391
Dynamic Planning with a LLM
While Large Language Models (LLMs) can solve many NLP tasks in zero-shot settings, applications involving embodied agents remain problematic. In particular, complex plans that require multi-step reasoning become difficult and too costly as the context wind
arxiv.org

LLM, PG, AS, Domain, task, obs0
goal ← LLM(Domain, task) # 1️⃣ 목표 생성
𝒲, ℬ ← observe(goal, obs0) # 2️⃣ 초기 상태 및 신념 추출
while goal not reached do # 목표 달성 전까지 반복
plans ← ∅ # 3️⃣ 가능한 계획 초기화
for i in N do # N개의 신념 샘플링 반복
wbelief ← LLM(ℬ, 𝒲) # 4️⃣ 신념 샘플링
plans ← PG(wbelief ⋃ 𝒲) # 5️⃣ 샘플된 상태로 계획 생성
end for
action ← AS(plans) # 6️⃣ 최적 행동 선택
obs ← Env(action) # 7️⃣ 행동 실행 및 관찰
𝒲, ℬ ← observe(action, obs) # 8️⃣ 상태 및 신념 업데이트
end while여기선 LLM이 자연어 지시를 읽고 PDDL 형식의 목표 상태를 생성
목표와 관찰 정보를 통해 확실한 환경 정보와 불학실한 정보에 대한 추정 값을 출력
불확실한 정보와 확정 정보를 통해 가능한 상태를 추론
각 샘플에 대해 PDDL 문제 파일을 생성하여 계획을 생성
그 중 가장 짧은 계획 경로를 선택하여 진행
액션에 대한 관측값을 수집,
확실한 정보와 불확실한 정보 수정
| 단계 | 과정 예시 | 출력 |
| 1️⃣ 목표 생성 | 자연어 → PDDL 변환 | 감자 선반 위 & 데워짐 목표 생성 |
| 2️⃣ 초기 상태 추출 | 감자가 어디에 있는지 불확실 | ℬ: 감자 위치(냉장고/캐비닛/선반) |
| 3️⃣ 계획 초기화 | 계획 목록 비우기 | plans ← ∅ |
| 4️⃣ 신념 샘플링 | N=3 상태 샘플 | 감자 위치 샘플링 결과 (냉장고/캐비닛/선반) |
| 5️⃣ 계획 생성 | 각 상태별 계획 수립 | 냉장고 경로 (6단계), 캐비닛 경로 (8단계) 등 |
| 6️⃣ 행동 선택 | 가장 짧은 계획 선택 | 냉장고로 이동 |
| 7️⃣ 실행 및 관찰 | 냉장고 열기 → 감자 발견 | 감자 위치 확정 |
| 8️⃣ 상태 업데이트 | ℬ 제거, 𝒲 갱신 | 냉장고에 감자 추가됨 → 재계획 불필요 |
| 연구 배경 및 문제점 | - 대형 언어 모델(LLM)은 자연어 처리에 강력하지만 체화된 에이전트(embodied agents)의 동적 환경에서 멀티스텝 계획과 장기적 추론에는 한계 존재 - LLM 문제점: 긴 컨텍스트 관리 어려움, 높은 계산 비용, 계획 오류(환각) 발생 - 기호 기반 계획기 문제점: 빠른 계획 탐색은 가능하지만 완전하고 정확한 환경 기술 요구 → 현실 환경 적용 어려움 |
| 연구 목적 | LLM의 언어 이해 능력과 기호 기반 계획기의 최적화 능력을 결합하여 빠르고 정확하며 비용 효율적인 체화된 계획 시스템(LMM-DP) 개발 |
| 제안 방법 (LLM-DP) | LLM-DP (LLM Dynamic Planner): 뉴로-기호적(neuro-symbolic) 계획 프레임워크 핵심 아이디어: 자연어 지시 → PDDL 목표 변환 + 다중 상태 샘플링 + 기호 기반 계획기 사용으로 불확실성 처리 및 최적 경로 탐색 |
| 방법론 세부 구조 | 1. 목표 생성 (Goal Generation): LLM이 자연어 지시를 PDDL 목표(:goal)로 변환 2. 세계 상태 및 신념 샘플링 (World State & Belief Sampling): 불확실한 정보에 대해 LLM이 가능한 상태 N개 샘플링 3. 계획 생성기 (Plan Generator): 각 상태에 대해 BFS(f) 기반 기호 계획기 사용 → 최적 경로 탐색 4. 행동 선택기 (Action Selector): 가장 짧은 계획 경로 선택 및 실행 5. 관찰 처리 및 갱신 (Observation Processing): 실행 결과 관찰 후 세계 상태 업데이트 및 필요 시 재계획 |
| 예시 시나리오 | 자연어 지시: "감자를 데워서 선반에 올려놔." 1️⃣ LLM → PDDL 목표 변환 (감자 위치 및 상태 요구사항 생성) 2️⃣ LLM → 감자의 위치에 대한 신념 샘플링 (냉장고, 캐비닛, 선반 중 가능성 제시) 3️⃣ 계획 생성 → 가장 짧은 경로 선택 (예: 냉장고 경로: 6단계 선택) 4️⃣ 행동 실행 및 관찰 → 감자가 냉장고에 없으면 재계획 수행 |
| 실험 환경 | Alfworld: 가상 가정 환경에서 물체 조작, 이동, 검사 등 7가지 과제 수행 과제 예시: 감자 데우기, 물체 옮기기, 물체 두 개를 특정 위치에 놓기 등 |
| 성과 및 결과 | LLM-DP 성능 (ReAct 대비 개선): - 정확도: 96% (ReAct 대비 42% 향상) - 평균 에피소드 길이: 13.16 (ReAct보다 30% 단축) - LLM 토큰 사용량: 633k (ReAct보다 14배 절감) |
| 성능 비교 표 | 🔎 성능 비교: |
| 주요 기여점 | ✅ 언어 기반 지시 해석 → 최적 계획 수행 ✅ 불완전한 정보 상황에서 강건한 계획 수행 ✅ 빠른 실행, 높은 정확도, 계산 비용 절감 ✅ 다중 상태 샘플링으로 불확실성 처리 가능 ✅ 관찰에 따른 동적 계획 갱신 및 적응 |
| 한계 및 향후 연구 방향 | 🚧 남은 과제: - 이미지 기반 관찰 통합 → 시각 정보로 불확실성 전파 - 지속 학습 및 자기 반성 적용 → 계획 실패 시 신념 수정 및 인간 교사와 상호작용 - 실제 물리 환경으로 확장 → 로봇 제어 및 다양한 도메인 적용 🧭 향후 연구 제안: - 시각-언어 통합 에이전트 개발 - 환경 변화에 강한 자기 갱신형 에이전트 구축 - 모듈형 프레임워크로 다양한 과제 지원 |
| 최종 결론 | LLM-DP는 LLM의 직관적 언어 이해와 기호 기반 계획의 수학적 최적화를 결합하여 정확성, 속도, 비용 효율성에서 뛰어난 성능을 달성. 복잡한 체화된 작업에서 안정적인 계획 수립 가능 → 미래의 자율적 AI 에이전트 설계에 기여. ✅ |
| LLM-DP (Dynamic Planning with a LLM) | LLM+P (Empowering LLMs with Optimal Planning) | |
| 목적 | LLM과 기호 기반 계획기의 협력을 통해 동적 환경에서 계획 수립 | LLM을 통해 자연어 문제를 PDDL로 변환 후, 기호 계획기로 최적 계획 생성 |
| 핵심 접근법 | - LLM + 기호 기반 계획기의 뉴로-기호적(neuro-symbolic) 통합 - LLM이 목표 생성 및 세계 상태 추론 - 다중 샘플링으로 불확실성 처리 |
- LLM을 기호 계획기의 입력 생성 도구로 사용 - LLM은 자연어 → PDDL 변환 전담 - 기호 계획기에서 최적 경로 탐색 및 생성 |
| 방법론 흐름 | 1. 자연어 지시 → LLM이 PDDL 목표 생성 2. 세계 상태 및 신념 샘플링 → 가능한 세계 상태 N개 생성 3. BFS(f) 기반 계획기로 각 상태에 대해 계획 생성 4. 가장 짧은 경로 선택 및 실행 5. 행동 결과 관찰 → 상태 갱신 및 재계획 |
1. 자연어 지시 → LLM이 PDDL 문제 파일 생성 2. PDDL 파일 → 기호 기반 계획기 입력 3. 계획기 → 최적 경로 탐색 (예: FAST-DOWNWARD 사용) 4. 계획 결과를 LLM이 자연어로 재변환 및 출력 |
| 불확실성 처리 | ✅ 다중 샘플링으로 미지의 객체 위치나 상태 추론 ✅ 관찰 시 새로운 정보 반영 → 계속 상태 업데이트 |
❌ 불확실성 직접 처리 없음 ✅ 정확한 PDDL 생성에 집중 → 계획기의 최적 탐색에 의존 |
| 계획 생성 방식 | - 여러 가능한 상태에 대한 계획 생성 후 최적 선택 - 계획 실패 시 다시 샘플링 및 재계획 |
- 단일 PDDL 문제 파일 기반 최적 계획 생성 - 계획기 성능에 전적으로 의존 (LLM은 계획 직접 생성 X) |
| 예시 시나리오 (감자 데우기) | 1️⃣ 감자 위치 불확실 시: 냉장고, 캐비닛, 선반 위치 샘플링 2️⃣ 각 위치별 계획 생성 후 가장 짧은 경로 선택 |
1️⃣ 감자 위치와 목표를 LLM이 PDDL로 작성 2️⃣ 계획기가 최적 경로 탐색 (불확실성 고려 없음) |
| 장점 | ✅ 불완전한 정보 환경에서도 강건성 확보 ✅ 다양한 상황에 적응력 우수 ✅ 관찰 및 샘플링을 통한 지속적 계획 수정 가능 |
✅ 최적 계획 탐색 보장 (계획기 활용) ✅ LLM 계산 비용 절감 (계획 탐색 부담 없음) ✅ 계획의 정확성 및 최적성 보장 |
| 단점 | ❌ 다중 샘플링으로 인한 계산 비용 증가 가능 ❌ 샘플링 오류 발생 시 잘못된 계획 선택 우려 |
❌ LLM이 부정확한 PDDL 생성 시 계획 실패 ❌ 불확실성 처리 부족 ❌ 관찰 기반 상태 갱신 기능 없음 |
| 실험 환경 | Alfworld (가상 가정 환경 과제 수행) | 7개 로봇 계획 도메인 (BLOCKSWORLD, BARMAN 등) |
| 성과 비교 | 🔥 정확도: 96% (ReAct 대비 +42%) ⏱️ 평균 에피소드 길이: 13.16 (ReAct 대비 -30%) 💵 LLM 토큰 사용량: 633k (ReAct 대비 14배 절감) |
🏆 BLOCKSWORLD: 90% 정확도 🏆 GRIPPERS: 95% 정확도 ⚠️ FLOORTILE, TERMES: 실패 사례 발생 (LLM의 잘못된 PDDL 생성 때문) |
| 차이점으로 인한 결과 차이 | - 불확실성 샘플링으로 미지 환경 탐색 시 우수 - 관찰 기반 계획 재설정 기능 → 환경 변화 적응력 강함 |
- 정확하고 최적의 계획 생성 우수 - 불확실성 상황에서 계획 실패 확률 증가 - 잘못된 PDDL 생성 시 전체 실패 가능성 존재 |
| 적용 시나리오 추천 | - 동적 환경이나 미지의 상황에서 빠르게 적응해야 할 때 추천 - 관찰 기반 상태 추적 필요 시 유리 |
- 확실한 환경 정보가 주어질 때 추천 - 최적 경로 탐색이 핵심인 과제에 적합 |
