https://arxiv.org/abs/2502.09992
Large Language Diffusion Models
Autoregressive models (ARMs) are widely regarded as the cornerstone of large language models (LLMs). We challenge this notion by introducing LLaDA, a diffusion model trained from scratch under the pre-training and supervised fine-tuning (SFT) paradigm. LLa
arxiv.org

이 식이 기존 언어 모델이 예측을 진행하는 순서입니다.

이 식은 기존 생성형 모델이 사용하던 식으로 Diffusion의 식이 들어가 있습니다.
데이터와 최대한 유사하게 파라미터를 조종하고 또한 기존 데이터와 KL발산이 최소화되도록 파라미터가 움직입니다.
2 번식인 ARMs 방식은 현재 LLM의 기초가 되었으나 생성 모델링 원칙인 1번이 간과되었다.
또한 성능은 좋지만 손차적으로 토큰을 생성하기에 높은 계산 비용, 역전 추론 task에서 성능이 좋지 않다.
=> 그리하여 LLaDA(Large Language Diffusion with mAsking)에서는 MDM(Masked Diffusion Model)을 사용한다.

(a)로 Pre-training을 진행한다. (b) SFT, (c) Sampling
(a)처럼 t는 0(원문) ~ 1(전체 마스킹)로 정해지면 랜덤하게 마스킹되고, 그것을 맞추는 Mask Predictor를 진행한다.

이러한 Loss Function을 통해 학습을 진행하며, Masking 된 토큰에 한해서만 Loss function이 작동되도록 구성되어 있다.
여기선 1B, 8B 모델을 만들었습니다.
그리고 첫 번째 모델이라 그런지 단순성을 위해 Attention 구조도 바닐라 구조를 사용하고, 이러한 parameter 증가는 FFN의 parameter 감소로 맞춰주었습니다.
Pre-Train 진행 시 온라인 코퍼스에서 파생되며 낮은 품질의 콘텐츠를 필터링한 2조 3천억 토큰을 사용했습니다.
여기엔 일반 텍스트 외에도 코드, 수학, 다국어 데이터를 포함하여 4096 max token으로 0.13백만 H800 GPU 시간이 들었다고 합니다. 이 것은 ARM과도 비슷하다고 하네요
이제 준비된 Prompt와 Response를 통해 SFT를 진행합니다.

여기서 p_0인 것을 보면 Prompt는 항상 전체를 주고, Response만 masking하는 것을 볼 수 있습니다.
450만쌍으로 구성된 데이터 셋에서 SFT를 진행되고, 기존 LLM에서 사용되는 SFT 프로토콜을 따라 학습된다고 합니다.
또한 EOS 토큰을 통해 길이를 맞춰주고, inference 시에는 출력이 종료되도록 만들어 과도한 출력도 방지합니다.

추론 시 완전하게 마스킹 된 응답에서 시작합니다. 여기서 step도 하이퍼 파라미터로 정할 수 있다.
appendix에서 자세한 파라미터, 학습 방법들을 볼 수 있다.


사전 학습만 진행한 것과, SFT까지 진행한 모델들의 성능표입니다.
첫 번째 Diffusion 모델로 Qwen2와 비교하면 그렇게 높은 성능은 아니지만 그래도 Diffusion 모델이 이정도의 성능을?! 하고 볼 수 있었습니다.
추후 모델을 고급화하기 시작하면 또 엄청난 성능을 보여줄 것 같기도 합니다.
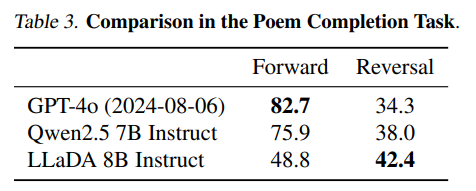
이건 Qwen이 GPT를 이기는 것을 봐서는 학습 데이터 상에도 중국어가 많아서 그렇지 않나 싶기도 합니다.

순서가 뭔가 지맘대로인 것 같아서 일단 후속 연구도 지켜봐야 겠네요
1. 문제 인식 및 해결하려는 문제점
기존의 대규모 언어 모델(LLMs)은 대부분 오토레그레시브 모델(Autoregressive Models, ARMs)에 기반하여 훈련됩니다. 이러한 방식은 다음과 같은 문제를 가지고 있습니다:
- 높은 연산 비용: 토큰을 순차적으로 생성하므로 긴 시퀀스일수록 연산이 비효율적입니다.
- 역방향 추론의 한계: 좌에서 우로만 시퀀스를 모델링하기 때문에 역방향 추론이나 중간 삽입(in-filling) 작업에서 성능이 떨어집니다.
- 스케일링의 한계: 모델 크기와 데이터 양을 늘려도 ARMs의 구조적 한계로 인해 성능 증가에 한계가 있습니다.
이에 대해 저자들은 오토레그레시브 모델이 아닌 새로운 접근법으로, 확산 모델(Diffusion Models)을 기반으로 한 LLaDA (Large Language Diffusion with mAsking)를 제안합니다.
2. 제안 방법: LLaDA
2.1 핵심 아이디어
LLaDA는 Masked Diffusion Model (MDM)을 기반으로 하여, 전통적인 ARMs와 달리 양방향 의존성(Bidirectional Dependencies)을 자연스럽게 모델링합니다. 주요 아이디어는 다음과 같습니다:
- 순방향 과정(Forward Process):
입력 시퀀스의 토큰을 점진적으로 마스킹합니다. - 역방향 과정(Reverse Process):
완전히 마스킹된 시퀀스에서 원래 시퀀스를 복원합니다.
이 과정에서 LLaDA는 마스크 예측기(Mask Predictor)를 사용하여 한 번에 모든 마스킹된 토큰을 예측합니다.
2.2 모델 구조
- 모델 아키텍처:
- Transformer 기반 마스크 예측기 사용
- 양방향 Attention 사용 (ARMs와 달리 causal mask 제거)
- 모델 크기: 1B 및 8B 파라미터 모델 구축
- 데이터 및 훈련:
- 사전 학습: 2.3T 토큰 사용 (0.13M H800 GPU 시간)
- 지도 미세조정(SFT): 4.5M 쌍의 데이터로 후처리
- 시퀀스 길이: 4096 토큰 사용
3. 실험 결과 및 분석
3.1 확장성 및 성능 평가
LLaDA는 다양한 벤치마크에서 ARMs과 경쟁력 있는 성능을 보였습니다.
벤치마크 성능 (Zero/Few-Shot Tasks)
- MMLU (일반 지식): LLaDA 8B → 65.9% (LLaMA3 8B와 유사)
- GSM8K (수학): LLaDA 8B → 70.7% (LLaMA2 7B보다 우수)
- HumanEval (코드 생성): LLaDA 8B → 33.5%
3.2 주요 장점 및 발견사항
✅ 스케일링 능력:
모델 크기 및 데이터 증가에 따라 성능이 선형적으로 증가하며, ARMs와 유사한 확장성을 보임.
✅ 역방향 추론 능력(Reversal Reasoning):
- LLaDA는 "reversal curse" 문제를 극복하여 GPT-4o보다 역방향 시퀀스 생성에서 우수한 성능을 보여줌.
- 예시: 중국 시문 역방향 생성 작업에서 GPT-4o 대비 8.1% 성능 향상.
✅ 지침 따르기 능력(Instruction Following):
- SFT 후, 멀티턴 대화(multi-turn dialogue)에서 자연스러운 응답 생성.
- 다중 언어 번역 및 시적 생성에서도 경쟁력 확보.
✅ 효율적인 샘플링:
- 로우-컨피던스 리마스킹(Low-Confidence Remasking) 전략을 사용하여 샘플링 속도와 품질 모두 개선.
- Semi-autoregressive remasking을 통해 더 자연스러운 텍스트 생성 가능.
4. 결론 및 향후 과제
4.1 결론
LLaDA는 기존 ARMs 기반 LLM의 한계를 극복할 수 있는 대안적 접근법을 제시합니다.
- 강력한 확장성: 대규모 모델로 확장 시 기존 ARMs 대비 비슷하거나 더 우수한 성능 확보.
- 효율성 확보: 토큰 예측을 병렬적으로 수행하여 연산 효율성 증가.
- 양방향 추론: 기존 LLM에서 어려웠던 역방향 및 중간 삽입 문제 해결.
4.2 향후 연구 방향
- 멀티모달 학습: LLaDA를 비언어적 데이터(예: 이미지, 오디오)로 확장.
- 강화학습 기반 정렬(RLHF): 모델의 사용자 의도 이해력 향상을 위한 후처리 탐색.
- 샘플링 최적화: 샘플링 단계에서의 리마스킹 전략 및 하이퍼파라미터 최적화 연구.
- 모델 크기 확장: 8B 이상의 모델로 실험하여 궁극적인 성능 한계 탐색.
🧩 핵심 개념 요약
LLaDA는 기존 언어 모델의 오토레그레시브 모델링(Autoregressive Modeling) 방식을 대체하여, 확산 모델(Diffusion Model)을 언어 생성에 적용한 새로운 접근법입니다.
기존의 LLM은 왼쪽에서 오른쪽으로 순차적(next-token prediction)으로 텍스트를 생성하지만, LLaDA는 시퀀스 전체를 마스킹한 후 역방향으로 복원(reverse diffusion)합니다.
👉 중요한 차이:
- ARMs: "앞 단어"만 보고 "다음 단어"를 예측.
- LLaDA: "문장 전체"를 보고 "모든 마스킹된 단어"를 동시에 예측.
🛠️ LLaDA의 작동 원리 단계별 설명
LLaDA는 Forward Process (순방향)와 Reverse Process (역방향)의 두 단계를 통해 텍스트를 생성합니다.
🌱 1. Forward Process (순방향 마스킹)
✅ 목표: 원문 시퀀스를 점진적으로 "노이즈"로 변환
✅ 방법: 각 토큰을 일정 확률로 마스킹
📘 예시: 원문 문장:
"The cat sits on the mat."
- 0단계 (t=0): "The cat sits on the mat." (마스킹 없음)
- 중간 단계 (t=0.5): "The [MASK] sits on [MASK] mat."
- 최종 단계 (t=1): "[MASK] [MASK] [MASK] [MASK] [MASK] [MASK]" (모든 토큰 마스킹)
👉 이 과정은 이미지를 점점 흐리게 만드는 확산 과정과 유사합니다.
🌿 2. Reverse Process (역방향 복원)
✅ 목표: 완전히 마스킹된 시퀀스에서 원문 복원
✅ 방법: 마스크 예측기(Mask Predictor)가 모든 마스킹된 토큰을 동시에 예측
📘 예시 계속:
입력: "[MASK] [MASK] [MASK] [MASK] [MASK] [MASK]"
- 1단계 (t=0.9): "The [MASK] [MASK] on [MASK] mat."
- 2단계 (t=0.7): "The cat [MASK] on the mat."
- 3단계 (t=0.5): "The cat sits on the mat." (완벽 복원)
👉 차이점: 기존 모델은 "The cat sits..."에서 "on"만 예측하지만, LLaDA는 "The cat [MASK] on the mat"에서 모든 마스크를 한 번에 예측합니다.
🧠 왜 이 접근법이 중요한가?
- 🔄 양방향 정보 활용:
- ARMs는 앞 단어만 참고하지만, LLaDA는 문장의 앞뒤 단어 모두 활용
- 예시:
- ARMs: "The cat sits on [MASK]" → "the" 예측 시 앞의 단어만 참조
- LLaDA: 앞뒤 문맥 "The cat sits on [MASK] mat."에서 "[MASK]"에 "the" 삽입
- ⚡ 병렬 예측 가능:
- ARMs: 토큰을 순차적으로 예측 (느림)
- LLaDA: 모든 마스킹된 토큰을 동시에 예측 (빠름)
- 🧩 중간 삽입 및 역방향 추론 개선:
- 예시: "She [MASK] the ball."에서 "[MASK]"가 "kicked"일 때, ARMs보다 자연스러운 문맥 생성 가능
🧪 전통적 LLM과의 비교 예시
| 상황 | ARMs 방식(기존) | LLaDA 방식 |
| 단어 예측 | "The cat sits on the ..." → "mat" 예측 | 전체 문장 마스킹 후 "mat"과 "sits" 동시에 예측 |
| 중간 단어 삽입 | 어려움 (좌측 문맥만 이용) | 좌우 문맥 활용하여 자연스러운 삽입 가능 |
| 속도 | 순차적 예측 → 느림 | 병렬 예측 → 빠름 |
| 역방향 생성 | 어려움 | 문장 뒤에서 앞 방향 추론 가능 |
🌟 결론
✅ LLaDA의 핵심: "문장을 흐리게 했다가 선명하게 복원하는" 이미지 확산 개념을 언어 모델링에 적용
✅ 장점:
- 양방향 문맥 활용 → 더 자연스러운 문장 생성
- 병렬 처리 → 빠른 텍스트 생성
- 역방향 및 중간 삽입 능력 → 기존 모델 한계 극복
🔥 요약:
"LLaDA는 문장을 흐리게 만든 후, 마법처럼 원래 모습으로 복원하는 AI 기술입니다."
1. 실험 결과 요약
논문에서는 LLaDA의 성능을 다양한 벤치마크와 비교하여 기존 오토레그레시브 모델(ARMs)과의 차별점을 검증하였습니다.
🎯 1.1 주요 실험 결과
✅ (1) 확장성 및 스케일링 능력
- 모델 크기 증가에 따른 성능 향상:
- LLaDA는 모델 크기와 데이터 크기에 비례하여 성능이 선형적으로 증가
- FLOPs (부동 소수점 연산 수)가 증가함에 따라 ARMs와 동등하거나 더 우수한 확장성 확보
📊 대표 결과:
- MMLU (일반 지식 평가): LLaDA 8B → 65.9% (LLaMA3 8B와 유사)
- GSM8K (수학 문제 해결): LLaDA 8B → 70.7% (LLaMA2 7B보다 17.6%p 향상)
✅ (2) 역방향 추론 및 리버설 테스트 성능
- 기존 LLM이 역방향 시퀀스 생성에 취약한 반면, LLaDA는 reversal curse 문제를 효과적으로 해결
- GPT-4o 대비 역방향 생성 작업에서 더 우수한 성능 달성
📘 역방향 시 문제 예시:
- 입력: "夜静春山空" (밤이 고요한 봄 산은 비어 있다)
- 목표: 앞 구절 "人闲桂花落" 복원
- GPT-4o 실패, LLaDA 성공적으로 복원
✅ (3) 지침 따르기 및 멀티턴 대화 성능 (Instruction Following & Dialogue)
- SFT(지도 미세조정) 후, LLaDA의 지침 따르기 능력과 멀티턴 대화 성능이 대폭 향상
- 다중 언어 번역 및 시적 생성에서도 강력한 성능
🗨️ 멀티턴 대화 예시:
- 사용자: "The Road Not Taken 첫 두 줄 알려줘."
- LLaDA: "Two roads diverged in a yellow wood, And sorry I could not travel both."
- 사용자: "중국어로 번역해줘." → "两条路分岔在黄色的树林中,遗憾我不能同时走"
- 사용자: "독일어로도 번역해줘." → "Zwei Wege trennten sich im gelben Wald..."
✅ (4) 코드 생성 및 수학 문제 해결
- HumanEval (코드 생성): LLaDA → 33.5% (기존 모델과 유사한 성능)
- 수학 및 과학 문제(GSM8K, GPQA 등): 기존 LLaMA2 7B 대비 우수한 성능 확보
📈 1.2 성능 정리 표 (LLaDA 8B 기준)
| 벤치마크 | LLaDA 8B 성능 | 비교 모델 (LLaMA3 8B) | 비고 |
| MMLU (일반 지식) | 65.9% | 65.4% | 거의 동일한 성능 |
| GSM8K (수학 문제) | 70.7% | 53.1% | 17.6%p 우위 |
| HumanEval (코드 생성) | 33.5% | 34.2% | 유사 성능 |
| Reversal Reasoning (역방향 추론) | 42.4% | GPT-4o → 34.3% | 8.1%p 개선 |
| CMMLU (중국어 이해) | 69.9% | 50.7% | 다국어 처리에 강점 |
🧩 2. 결론 및 기여
🌟 2.1 주요 결론
- ✅ 확산 모델 기반의 언어 모델도 LLM에서 경쟁력 있는 성능을 발휘할 수 있음을 입증
- ✅ 양방향 추론 및 마스킹 기반 생성으로 중간 삽입, 역방향 생성에서 ARMs보다 우수한 성능
- ✅ 병렬적 토큰 예측으로 인해 연산 효율성이 대폭 향상
- ✅ 지도 미세조정 후 강력한 지침 따르기 및 대화 능력 확보
- ✅ 특히 수학, 중국어 등 특정 작업에서 현존 모델보다 더 우수한 성능
🔥 2.2 LLaDA의 차별점
| ARMs (기존 모델) | LLaDA (제안 모델) | |
| 토큰 예측 방식 | 순차적(next-token prediction) | 병렬적(all masked tokens at once) |
| 문맥 활용 | 좌측 문맥만 사용 | 양방향 문맥 활용 |
| 역방향 추론 | 취약 | 우수 (reversal curse 극복) |
| 연산 비용 | 높음 | 낮음 (빠른 샘플링) |
| 멀티턴 대화 | 제한적 | 자연스러운 대화 가능 |
🚀 3. 마무리 및 향후 연구 방향
🧭 3.1 한계 및 개선점
- 🔄 샘플링 단계의 리마스킹 전략 최적화 필요
- 🧮 계산 비용 최적화 및 추가 모델 크기 확장 연구 필요
- 🧪 멀티모달 데이터 적용 및 학습 탐색 미완료
- 🧷 RLHF 기반 사용자 정렬 개선 필요
💡 3.2 향후 연구 제안
- 🧬 멀티모달 확장: 이미지, 오디오 등 다양한 데이터 통합
- 🏗️ 모델 크기 8B 이상으로 확대하여 스케일링 한계 분석
- 🧠 Sparse Autoencoder와 결합하여 모델 해석력 강화
- 🧩 MoE 구조와 결합:
- 전문가 네트워크가 마스킹 패턴별로 복원 담당
- 게이트 네트워크 최적 전문가 선택
🏆 최종 요약
✅ LLaDA는 확산 모델을 언어 생성에 적용하여 ARMs의 한계를 극복한 혁신적 모델입니다.
✅ 양방향 문맥 활용, 병렬 처리 및 빠른 샘플링으로 기존 LLM 대비 강력한 성능 확보
- 식 (1): 생성 모델링 원칙
- 식 (2): 오토레그레시브 모델링(Autoregressive Modeling, ARM)
이 두 식은 LLM이 어떻게 데이터 분포를 학습하며, 이를 구현하기 위해 어떤 모델링 접근 방식을 사용하는지를 보여줍니다.
🔢 식 (1): 생성 모델링 원칙 (Generative Modeling Principles)

🔄 결론:
모델 학습의 핵심 목적: 실제 데이터 분포를 모델이 최대한 정확히 모방하도록 만드는 것.
로그 가능도 최대화와 KL 발산 최소화는 동일한 목표를 다른 관점에서 표현한 것입니다.
🔢 식 (2): 오토레그레시브 모델링 (Autoregressive Formulation)

- 첫 번째 단어 "The"의 확률 계산
- 두 번째 단어 "cat"은 "The"를 조건으로 예측
- 세 번째 단어 "sits"는 "The cat"을 조건으로 예측
🆚 식 (1)과 (2)의 관계 및 차이점
| Gen Modeling (1) | ARMs (2) | |
| 목적 | 모델이 실제 데이터 분포를 정확히 추정하도록 학습 | 시퀀스의 확률을 조건부 확률의 곱으로 모델링 |
| 핵심 개념 | 로그 가능도 최대화 ↔ KL 발산 최소화 | 다음 토큰을 예측하기 위해 이전 토큰 사용 |
| 적용 대상 | 모든 생성 모델 (GAN, VAE, Diffusion 등) | 주로 언어 모델 (GPT, LLaMA 등) |
| 모델링 방식 | 전체 데이터 분포 차이 최소화 | 시퀀스의 순차적 조건부 확률 예측 |
| 제한점 | 모델링 방식에 대한 구체적 방법 미제시 | 순차적 예측 → 병렬성 부족 및 느림 |
💡 직관적 이해를 위한 예시
📝 문장: "The cat sits on the mat."
🧮 식 (1) 관점:

🔄 식 (2) 관점 (ARMs 방식):
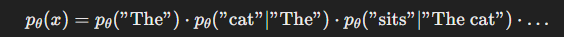
- "The" 생성 → "cat" 예측 → "sits" 예측... 순차적 생성
- 문제점: 토큰을 하나씩 예측해야 하므로 병렬 예측이 불가능
🔎 LLaDA와의 관계
- 식 (1)은 LLaDA를 포함한 모든 생성 모델의 기본 학습 원칙을 설명합니다.
- 식 (2)는 기존 LLM (GPT, LLaMA 등)이 사용하는 오토레그레시브 모델링 방식을 구체화합니다.
🆕 LLaDA의 차별점:
- ARMs(식 2)의 단점 극복:
- 기존 방식은 순차적(next-token prediction) → 느림
- LLaDA: 마스킹된 토큰을 동시에 병렬적으로 예측
- 식 (1)의 목표 달성 방식 개선:
- LLaDA는 마스킹 기반 확산 모델링으로 식 (1)의 목적을 더 효율적으로 달성
🏆 결론
✅ 식 (1)은 LLM의 학습 목표를 설명합니다. (데이터 분포와 모델 분포의 차이 최소화)
✅ 식 (2)는 그 목표를 구현하는 전통적 방법(오토레그레시브 모델링)을 보여줍니다.
✅ LLaDA는 식 (2)의 한계를 극복하며 식 (1)의 목표를 더 빠르고 정확하게 달성할 수 있는 대안입니다! 🚀
🧮 기대값 E의 의미와 역할 설명
🔎 1. 기대값 E란 무엇인가?
✅ 기대값(Expected Value)은 확률 이론에서 어떤 확률 분포에서 랜덤 변수의 평균적인 값을 나타냅니다.
즉, "랜덤 변수의 평균적인 결과가 무엇일까?"를 알려줍니다.
📝 기대값의 수학적 정의
이산 확률 변수 X의 경우:

연속 확률 변수 X의 경우:
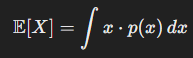
✅ 해석: 각 값 x에 해당 확률 p(x)을 곱한 뒤 모두 더한 값입니다.
🎲 비유:
E[X]=1×0.5+0×0.5=0.5
- 동전 던질 때, 앞면(1)과 뒷면(0)이 나올 확률이 각각 0.5일 때:
→ 기대값 = 평균적으로 앞면이 절반 확률로 나온다.
🧩 2. 식 (3)에서 E의 역할
📘 식 (3) 다시 보기:

🔎 여기서 E_{t, x_0, x_t} 의미:
- 확률 변수: t, x_0, x_t
- t: 마스킹 강도 (랜덤 샘플링됨)
- x_0: 원본 시퀀스 (데이터셋에서 랜덤 선택)
- x_t: t를 기반으로 생성된 마스킹 시퀀스
- E _{t, x_0, x_t} [⋅]는 이 모든 랜덤 변수에 대한 평균 손실을 의미합니다.
👉 즉, 모델은 특정 샘플이 아닌 전체 데이터와 다양한 마스킹 상황에서 평균적으로 잘 작동하도록 학습합니다.
🛠️ 3. 수식 내 기대값의 구체적 계산 흐름

🔢 4. 몬테카를로 추정을 통한 기대값 근사

🛠️ 실제 계산 흐름 예시:
| 단계 | t | x_0 | 마스킹 된 x_t | 손실 계산 |
| 1 | 0.3 | "The cat sits" | "The [MASK] sits" | -0.2 |
| 2 | 0.6 | "She loves music" | "[MASK] loves [MASK]" | -0.4 |
| 3 | 0.1 | "I am happy" | "[MASK] am happy" | -0.1 |
| ... | ... | ... | ... | ... |
| N | 0.5 | "Hello world" | "Hello [MASK]" | -0.3 |
👉 기대값 추정:

🧠 5. 기대값을 사용하는 이유와 효과
✅ 왜 기대값을 사용하나요?
- 모델이 특정 샘플이나 마스킹 강도에 과적합하지 않게 하기 위함
- 모든 데이터와 다양한 상황에서 평균적으로 잘 작동하도록 보장
✅ 기대값 사용의 장점:
- 일반화 능력 향상: 여러 샘플 평균으로 모든 경우에 안정적 성능 확보
- 다양성 고려: 다양한 마스킹 강도 및 시퀀스에 대해 일관된 복원 능력 학습
- 편향 감소: 단일 샘플 손실보다 더 신뢰할 수 있는 손실 추정
🏆 최종 요약
✅ E 역할: 랜덤 변수 (t, x_0, x_t)에 대한 평균적인 손실을 계산합니다.
✅ 왜 필요? 모델이 모든 상황에서 일관된 성능을 발휘하도록 합니다.
✅ 몬테카를로 추정: 다양한 샘플의 손실을 평균 내어 기대값을 효율적으로 계산합니다.
✅ 결과적으로: 모델은 다양한 마스킹 패턴과 강도에서도 견고한 복원 능력을 가집니다! 🚀
🧩 1. 몬테카를로 방법(Monte Carlo Method) 기초 이해
✅ 기본 개념
- 몬테카를로 방법은 확률적 시뮬레이션을 통해 복잡한 수학적 문제를 근사적으로 해결하는 방법입니다.
- 주로 적분 계산, 기대값 추정, 확률 분포 샘플링에 사용됩니다.
📝 기대값 계산 예시 (일반적 형태):
어떤 확률 분포 p(x)가 주어질 때, 함수 f(x)의 기대값은 다음과 같습니다:

👉 몬테카를로 추정:
이 적분을 직접 계산하기 어렵다면, 분포 p(x)에서 샘플 x^(1), x^(2), .... , x^(N)을 추출한 뒤,

즉, 샘플의 평균을 통해 기대값을 근사할 수 있습니다.
🎲 비유: 동전을 무한히 던질 수 없으니, 많이 던져본 평균으로 실제 확률을 추정하는 것과 같습니다.
🔢 2. 식 (3) 해석 및 몬테카를로 적용 과정
📝 식 (3): 손실 함수 정의
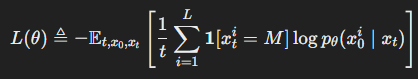
✅ 용어 설명:

🔍 몬테카를로 방법 적용 과정
🛠️ 식 (3)은 원래 기대값 형태:

👉 이 기대값을 직접 계산하기 어렵기 때문에 몬테카를로 추정을 사용합니다.
📈 몬테카를로 추정 단계:
- tt 샘플링:
- 확률적 마스킹 강도 t를 [0,1]에서 랜덤으로 샘플링
- 예시: t = 0.3이면, 각 토큰이 30% 확률로 마스킹됩니다.
- 시퀀스 샘플링:
- 데이터셋에서 원본 시퀀스 x_0 선택
- 마스킹 적용 → x_t 생성
- 예시:
- 원본 x_0: "The cat sits"
- 마스킹 x_t: "The [MASK] sits" (마스킹 확률 0.3 적용 결과)
- 손실 계산:

4. 여러 샘플 평균화 (몬테카를로 추정):

🔧 3. 모델 업데이트 및 변경 과정
🚀 몬테카를로 추정을 통한 모델 업데이트 흐름:

🎯 4. 모델 변경 결과 및 효과
| 변경 전 (초기) | 변경 후 (학습 완료) |
| 마스킹 강도 높을 때 복원 어려움 | 높은 마스킹 강도에서도 정확한 복원 가능 |
| 특정 마스킹 패턴에 과적합 | 다양한 패턴에 대한 일반화 능력 향상 |
| 병렬성 부족 | 마스킹된 토큰 동시 예측 가능 → 빠른 생성 |
| 단순 순차적 예측 | 양방향 문맥 활용으로 자연스러운 생성 |
✅ 결과적으로:
- 모델은 다양한 마스킹 강도와 위치에서 원래 시퀀스를 잘 복원하게 됩니다.
- 이는 중간 삽입, 역방향 추론 등 다양한 생성 작업에서 우수한 성능을 보장합니다.
🏆 최종 요약
🔑 식 (3)은 마스킹된 시퀀스 복원 과정에서 모델의 손실 함수를 정의합니다.
🎲 몬테카를로 방법은 샘플링을 통해 기대값(손실)을 효율적으로 추정합니다.
🚀 결과적으로: 모델은 다양한 마스킹 패턴을 복원할 수 있는 능력을 학습하여 빠르고 자연스러운 텍스트 생성이 가능합니다! 😊
🧩 EOS 토큰의 역할과 모델 출력 제어 메커니즘 설명
📝 1. EOS란 무엇인가?
✅ EOS(End Of Sequence) 토큰은 시퀀스의 끝을 나타내는 특별한 토큰입니다.
- 일반적으로 텍스트 생성 모델이 언제 출력을 멈출지 판단하는 기준으로 사용됩니다.
- 예시: 문장 "Hello world" → 시퀀스 표현: ["Hello", "world", "|EOS|"]
🔑 EOS의 핵심 기능:
- 출력 종료 신호 제공: 모델이 EOS를 생성하면 생성이 중단됩니다.
- 학습 중 시퀀스 정렬: 서로 다른 길이의 시퀀스를 같은 길이로 맞추기 위해 사용됩니다.
🛠️ 2. LLaDA에서 EOS의 사용 방식
📘 본문 내용 정리:
- 학습 시 짧은 시퀀스의 끝에 EOS를 추가하여 모든 시퀀스 길이를 동일하게 맞춤
- 학습 시: EOS를 일반 토큰처럼 처리
- 샘플링(생성) 시: EOS가 생성되면 출력을 멈춤
🚀 3. 왜 EOS를 추가하는가?
✅ (1) 학습 시 이유: 시퀀스 길이 맞춤
- 문제점: 시퀀스 길이가 다르면 배치 처리 시 패딩 필요 → 연산 비효율
- 해결: EOS를 추가하여 모든 시퀀스를 동일한 길이로 설정
🔎 예시:
| 원래 시퀸스 | 길이 | EOS 추가 시 |
| "Hello" | 1 | "Hello |
| "How are you" | 3 | "How are you |
👉 이렇게 하면 모든 시퀀스 길이가 통일되어 효율적인 배치 처리가 가능합니다.
✅ (2) 생성 시 이유: 자동 길이 제어
- 일반 문제: 일부 모델은 출력이 너무 길거나 짧을 수 있음
- EOS 사용 시:
- 모델이 스스로 "언제 멈춰야 할지" 결정 가능
- 출력 중 EOS가 생성되면 자동 종료 → 과도한 출력 방지
🔎 예시 (생성 과정):
1️⃣ 입력: "Translate: Hello"
2️⃣ 생성 토큰: "안녕하세요" → 아직 계속
3️⃣ 생성 토큰: "|EOS|" → 출력 즉시 중단
✅ 결과: "안녕하세요" 출력 완료, 추가 단어 생성 없음
🔢 4. EOS 사용의 효과와 모델 변화
측면 EOS 미사용 시 EOS 사용 시 (LLaDA 적용)
| EOS 미 사용시 | EOS 사용 시 | |
| 출력 길이 제어 | 길거나 짧은 출력 발생 가능 | 적절한 길이 유지 |
| 학습 효율성 | 패딩 필요, 연산 낭비 | 배치 처리 최적화 |
| 모델 해석력 | 종료 시점 예측 어려움 | 명확한 종료 신호로 예측 안정성↑ |
✅ 결론: EOS 사용으로 출력 품질과 학습 효율이 동시에 향상됩니다!
🏆 최종 요약
✅ 학습 시: EOS를 사용하여 시퀀스 길이 통일 및 배치 효율화
✅ 생성 시: 모델이 적절한 시점에 출력 종료 → 과도한 출력 방지
✅ 결과적으로: LLaDA는 더 자연스럽고 효율적인 출력 생성이 가능합니다! 🚀
"EOS는 모델에게 '여기서 멈춰!'라는 신호를 주는 마침표 같은 역할입니다." 😊
🧩 LLaDA에서 EOS의 사용 방식과 출력에 미치는 영향
📝 1. EOS와 패딩(PAD)의 차이 및 유사점
✅ 유사점:
- EOS와 PAD 모두 시퀀스 길이 맞춤에 사용됩니다.
- 배치 학습 시 모든 입력 시퀀스를 동일 길이로 맞추기 위해 사용됩니다.
✅ 차이점:
특징 PAD 토큰 EOS 토큰
| 특징 | PAD 토큰 | EOS 토큰 |
| 목적 | 단순 시퀀스 길이 정렬 | 시퀀스의 끝을 명시적으로 나타냄 |
| 학습 시 처리 | 모델이 무시하거나 별도로 처리 | 일반 토큰처럼 학습 |
| 생성 시 역할 | 생성 과정에서 사용되지 않음 | EOS 생성 시 출력 중단 |
| 출력에 영향 | 없음 | 출력 길이 제어 가능 |
🔑 핵심: EOS는 PAD처럼 길이 정렬용으로 사용되지만, 출력 제어 기능을 추가로 가집니다.
🚀 2. LLaDA에서 EOS의 학습 및 출력 방식
✅ (1) 학습 시:
- EOS는 일반 토큰처럼 처리됩니다.
- 모든 시퀀스의 끝에 EOS를 추가하여 길이 통일 및 종료 시점 정보 제공
🔎 예시 (학습 시 시퀀스):
원본: "Translate: Hello" → ["Translate", ":", "Hello", "|EOS|"]
모델 목표: 마지막에 EOS를 예측하도록 학습
👉 이 과정을 통해 모델은 언제 시퀀스가 끝나야 하는지 학습합니다.
✅ (2) 생성(샘플링) 시:
- EOS가 생성되면 출력 중단 → 출력 길이 자동 제어
- EOS가 나오지 않으면 최대 길이까지 생성 지속
🔎 생성 예시:
입력: "Write a poem:"
| 단계 | 생성된 시퀸스 | EOS 등장 여부 | 출력 중단 여부 |
| 1 | "Roses are red" | ❌ | 계속 |
| 2 | "Roses are red, violets are blue" | ❌ | 계속 |
| 3 | "Roses are red, violets are blue, | EOS | " |
✅ 결과: "Roses are red, violets are blue" 출력 완료
🔄 3. LLaDA의 모든 출력 사용 vs EOS의 역할
🔔 질문:
LLaDA는 모든 출력을 동시에 예측하는데, EOS가 나온다고 해서 출력에 변화가 있나요?
✅ 답변:
- 학습 시:
- EOS는 시퀀스 끝을 알리는 정보 토큰으로 사용
- 모든 토큰이 동시에 예측되지만, EOS는 출력 종료 위치를 알려줌
- 생성 시:
- 출력 전체에서 EOS가 등장한 위치까지 사용
- EOS 이후의 토큰은 출력에서 잘라냄 (사용되지 않음)
🔎 출력 예시 (동시 예측 + EOS 처리):
모델이 시퀀스 전체 예측 결과를 동시에 출력:
["Hello", "my", "friend", "|EOS|", "extra", "words"]
- 동시 예측은 모든 토큰에 대해 수행
- 출력 단계에서 EOS 발견 시:
→ "Hello my friend"만 출력하고 나머지는 무시
✅ 즉: EOS가 출력에 직접적인 변화는 주지 않지만, 출력에서 어떤 부분까지 사용할지 결정합니다.
🧠 4. 왜 EOS를 사용할까?
| EOS 미 사용 | EOS 사용 시 |
| 출력이 지나치게 길어질 수 있음 | 적절한 길이에서 자동 종료 |
| 모델이 언제 멈춰야 할지 불확실 | EOS로 명확한 종료 신호 제공 |
| 출력 길이 통제 어려움 | 문장 단위 생성 안정성 확보 |
🏆 최종 요약
✅ 학습 시: EOS를 일반 토큰처럼 처리하여 모델이 출력 종료 시점을 학습합니다.
✅ 생성 시: EOS가 생성되면 해당 위치에서 출력 중단 → 출력 길이 제어 가능
✅ 모든 출력이 동시에 예측되더라도: EOS는 출력 사용 범위를 결정하는 신호 역할을 합니다! 🚀
"EOS는 생성된 시퀀스의 '마침표' 역할을 하여, 출력이 필요한 만큼만 사용하게 도와줍니다." 😊