ESC와 ESConV는 감성 인식 및 감성 대화와 관련된 자연어 처리(NLP) 분야에서 중요한 개념입니다. 특히 감성(감정)을 인식하고 이를 기반으로 대화하는 모델을 만들려는 목적이라면 유용한 도구들이 될 수 있습니다. 각 개념에 대해 간단히 설명하겠습니다.
1. ESC Task (Emotion Sentence Classification Task)
ESC는 감정 문장 분류 작업을 의미합니다. 이 작업은 문장을 입력으로 받아 그 문장에서 나타나는 감정을 분류하는 것을 목표로 합니다. 감정 범주는 주로 긍정, 부정, 중립 등의 기본적인 분류부터 기쁨, 슬픔, 분노, 공포 등 세부적인 감정 상태까지 다양할 수 있습니다.
ESC Task는 감정 분석 모델을 만들 때 핵심적인 작업 중 하나입니다. 감정 문장 분류는 특히 감성적인 대화를 다루거나 감정 인식을 기반으로 한 응용 프로그램에서 중요하게 사용됩니다.
2. ESConV (Emotion-Sensitive Conversation Task)
ESConV는 감정에 민감한 대화를 의미합니다. 즉, 이 작업은 대화 도중 감정 상태를 분석하고, 그 감정에 적절히 반응하는 대화를 생성하는 것이 목표입니다. 감정 상태는 대화의 흐름에 따라 변화할 수 있으며, 모델은 이러한 변화를 지속적으로 추적하면서 사용자와의 감정적인 연결을 형성하는 것이 중요합니다.
ESConV에서는 모델이 문맥과 감정 상태를 동시에 고려하여 응답을 생성합니다. 단순히 감정을 인식하는 것에서 나아가, 감정에 공감하고 적절한 감성적 대응을 하는 것이 핵심입니다.
이 작업들을 통해 감정 인식 및 감성 대화 모델을 개발할 때, ESC Task는 감정 인식을 위한 데이터 준비나 학습에 필수적이고, ESConV는 실시간 대화에서 감정적으로 적절한 반응을 생성하는 기술을 다룹니다.
만약 감성적인 대화에 중점을 둔 모델을 개발하려면 ESC와 ESConV에 대한 이해와 이를 적용한 학습이 매우 중요할 거예요.
Towards Emotional Support Dialog Systems
https://arxiv.org/abs/2106.01144
Towards Emotional Support Dialog Systems
Emotional support is a crucial ability for many conversation scenarios, including social interactions, mental health support, and customer service chats. Following reasonable procedures and using various support skills can help to effectively provide suppo
arxiv.org
이 논문은 "Towards Emotional Support Dialog Systems"이라는 제목으로, 감정적 지원을 제공하는 대화 시스템을 개발하는 데 초점을 맞추고 있습니다. 이를 요약하고 단계별로 설명하겠습니다.
문제 정의 (Problem Definition)
이 논문은 감정적 지원을 제공하는 대화 시스템을 구축하는 문제를 다룹니다. 기존의 대화 시스템은 감정적 대화나 공감 표현에 한정되어 있으며, 효과적인 감정적 지원을 제공하는 데 필요한 다양한 기술을 포괄하지 못하고 있다는 한계를 지적합니다. 따라서 저자들은 감정적 지원 대화(Emotional Support Conversation, ESC)를 정의하고, 이 문제를 해결하는 데 필요한 대화 시스템을 개발하는 것을 목표로 합니다.
해결하고자 하는 문제
기존의 대화 시스템은 감정적 지원을 충분히 제공하지 못하며, 특히 대화에서 감정적 고통을 경감시키고 문제를 해결하는 데 도움을 주는 대화 기술이 부족하다는 문제를 해결하고자 합니다. ESC는 사용자의 감정적 고통을 줄이고, 문제를 해결할 수 있는 방향을 제시하는 것을 목표로 합니다.
방법론 (Approach)
저자들은 "도움 기술 이론"(Helping Skills Theory)에 기반한 감정 지원 대화 프레임워크(ESC Framework)를 제안합니다. 이 프레임워크는 세 가지 단계로 구성됩니다:
- 탐색 단계: 사용자의 문제를 파악하고 탐구하는 단계입니다.
- 위로 단계: 사용자의 감정을 이해하고 공감하며 위로를 제공하는 단계입니다.
- 행동 단계: 문제 해결을 위한 구체적인 조언이나 정보를 제공하는 단계입니다.
이를 구현하기 위해 저자들은 감정 지원 대화 데이터셋(ESConv)을 구축하고, 서포터와 도움을 요청하는 사람 간의 대화를 수집하였습니다. 이 데이터셋에는 다양한 지원 전략이 포함된 대화가 담겨 있으며, 이를 통해 대화 시스템이 효과적인 감정적 지원을 학습할 수 있도록 설계되었습니다.
실험 및 결과 (Experiments and Results)
논문에서는 최신 대화 모델들을 평가하고, 감정적 지원을 제공하는 능력을 측정했습니다. 실험 결과, 다양한 지원 전략을 활용했을 때 감정적 지원의 효과가 크게 향상된다는 것을 확인했습니다. 특히, 특정 전략을 사용할 때 사용자의 감정적 고통이 더 효과적으로 경감된다는 결과를 도출했습니다.
한계점 (Limitations)
이 연구의 한계점으로는 데이터셋의 한정성과 대화 시스템의 정교함 부족이 있습니다. 예를 들어, 감정적 지원 대화는 특정 상황에 맞춰져야 하며, 모든 사용자에게 동일하게 적용될 수 없다는 점이 지적되었습니다. 또한, 더 복잡한 감정 상태를 처리하기 위한 추가적인 연구가 필요합니다.
이를 종합하면, 이 논문은 감정적 지원 대화 시스템의 필요성을 강조하고, 이를 효과적으로 구현하기 위한 방법론을 제시하며, 실험을 통해 그 가능성을 입증한 연구입니다.
https://github.com/thu-coai/Emotional-Support-Conversation
GitHub - thu-coai/Emotional-Support-Conversation: Data and codes for ACL 2021 paper: Towards Emotional Support Dialog Systems
Data and codes for ACL 2021 paper: Towards Emotional Support Dialog Systems - thu-coai/Emotional-Support-Conversation
github.com
평가 방식
Fluency : 얼마나 유창한지
Identification : 문제를 식별하는데 도움이 되었는지
Comforting : 위로
Suggestion : 유용한 제안
Overall : 정서적 지원
Evaluating LLM systems: Metrics, challenges, and best practices
A detailed consideration of approaches to evaluation and selection
medium.com
----------------------Prompt---------------------------------------------
You are a professional evaluator, and your task is to assess the accuracy of entity extraction as a Score in a given text. You will be given a text, an entity, and the entity value.
Please provide a numeric score on a scale from 0 to 1, where 1 being the best score and 0 being the worst score. Strictly use numeric values for scoring.
Here are the examples:
Text: Where is Barnes & Noble in downtown Seattle?
Entity: People’s name
Value: Barns, Noble
Score:0
Text: The phone number of Pro Club is (425) 895-6535
Entity: phone number
value: (425) 895-6535
Score: 1
Text: In the past 2 years, I have travelled to Canada, China, India, and Japan
Entity: country name
Value: Canada
Score: 0.25
Text: We are hiring both data scientists and software engineers.
Entity: job title
Value: software engineer
Score: 0.5
Text = I went hiking with my friend Lily and Lucy
Entity: People’s Name
Value: Lily
----------------Output------------------------------------------
Score:프롬프트를 통해 GPT가 평가를 진행한다!
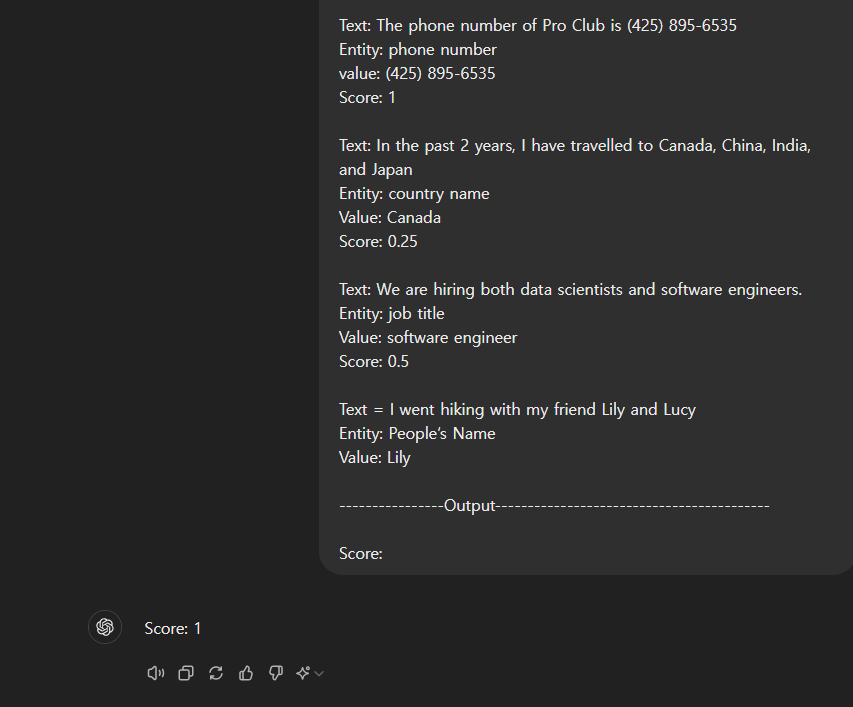
뭔가 아쉽다.
https://arxiv.org/abs/1811.00207
Towards Empathetic Open-domain Conversation Models: a New Benchmark and Dataset
One challenge for dialogue agents is recognizing feelings in the conversation partner and replying accordingly, a key communicative skill. While it is straightforward for humans to recognize and acknowledge others' feelings in a conversation, this is a sig
arxiv.org
https://aclanthology.org/2024.lrec-main.509.pdf
https://docs.smith.langchain.com/how_to_guides/evaluation/evaluate_llm_application
Evaluate an LLM Application | 🦜️🛠️ LangSmith
Before diving into this content, it might be helpful to read the following:
docs.smith.langchain.com
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
https://arxiv.org/abs/2306.05685
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Evaluating large language model (LLM) based chat assistants is challenging due to their broad capabilities and the inadequacy of existing benchmarks in measuring human preferences. To address this, we explore using strong LLMs as judges to evaluate these m
arxiv.org
논문 "Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena"는 대규모 언어 모델(LLM)을 평가하기 위한 새로운 방법을 제안하고 있습니다. 이 논문의 목적은 LLM을 인간의 선호도에 더 잘 맞추기 위해 기존의 평가 지표가 부족하다는 문제를 해결하는 것입니다.
문제 정의
기존의 LLM 평가 기준은 인간의 선호를 잘 반영하지 못하는 경우가 많습니다. 기존 벤치마크들은 LLM의 핵심 능력만을 평가하며, 복잡한 상호작용에서 인간이 더 선호하는 모델을 구분하는 데 한계가 있습니다. 인간의 선호도를 반영한 평가가 필요하지만, 인간 평가를 확장하는 것은 비용이 많이 들고 시간이 오래 걸리는 문제점이 있습니다.
시도한 방법
연구진은 이를 해결하기 위해 LLM-as-a-judge라는 접근 방식을 제안하였습니다. 이 방식에서는 강력한 LLM, 예를 들어 GPT-4를 심판으로 사용하여 다른 LLM들의 성능을 평가합니다. 이를 통해 인간의 선호도를 대규모로 자동 평가할 수 있는 방법을 개발하고자 했습니다.
사용된 방법
논문에서 제안된 두 가지 주요 평가 도구는 MT-bench와 Chatbot Arena입니다.
- MT-bench는 멀티 턴 대화와 지시 수행 능력을 평가하는 80개의 고품질 질문으로 구성된 벤치마크입니다. 이는 LLM의 핵심 능력과 더불어, 인간의 선호와 일치하는 응답을 도출하는지를 평가합니다.
- Chatbot Arena는 사용자가 두 개의 익명 챗봇과 동시에 상호작용하고 그 응답을 평가하는 크라우드소싱 플랫폼입니다. 이 과정에서 사용자는 더 선호하는 챗봇을 선택하게 되며, 이를 통해 LLM의 실제 사용 시 성능을 평가할 수 있습니다.
또한, LLM-as-a-judge는 세 가지 평가 방식을 사용합니다:
- 쌍 비교(pairwise comparison): 두 응답을 비교하여 더 나은 답변을 선택하는 방식.
- 단일 응답 평가(single answer grading): 하나의 응답에 점수를 매기는 방식.
- 참고 답안을 활용한 평가(reference-guided grading): 수학 문제 등에서는 정답을 참고하여 평가합니다.
결과
- GPT-4는 인간 평가와 높은 일치도를 보임: GPT-4는 인간 평가자와 약 80% 이상의 일치율을 보였으며, 이는 인간끼리의 평가 일치율과 유사합니다.
- MT-bench와 Chatbot Arena의 평가 결과는 기존의 벤치마크를 보완: 기존 벤치마크(MMLU 등)와 함께 사용함으로써, 모델의 핵심 능력과 인간과의 정렬된 성능을 모두 평가할 수 있었습니다.
- 모델의 성능 차이를 명확히 구분: GPT-4는 다양한 카테고리에서 가장 우수한 성과를 보였으며, Vicuna-13B는 특정 영역에서 성능이 저하됨을 확인했습니다.
한계점
- 편향 문제: LLM-as-a-judge 방식은 몇 가지 편향을 보였습니다. 예를 들어, 위치 편향(position bias), 장황함에 대한 편향(verbosity bias), 자기 강화 편향(self-enhancement bias)이 나타났으며, 일부 수학 문제나 추론에서의 한계도 드러났습니다.
- 수학 및 추론 능력: LLM이 수학 문제나 논리적 추론을 평가하는 데 있어서는 제한된 능력을 보였으며, 참조 답안을 제공함으로써 이를 어느 정도 완화할 수 있었습니다.
- 편향 완화 방법: 위치 편향을 줄이기 위해서는 응답의 순서를 바꾸어 평가하는 방법이 제안되었습니다.
결론
이 연구는 LLM-as-a-judge가 인간 평가를 대체하거나 보완할 수 있는 효율적인 방법임을 보여줍니다. 이를 통해 인간 평가를 확장하는 데 필요한 시간과 비용을 절감할 수 있으며, 앞으로 더 발전된 LLM 평가 시스템을 구축하는 데 기여할 수 있습니다.
계산식이나 알고리즘에 대한 내용은 주로 GPT-4의 편향 해결 방법과 관련이 있으며, 수학 문제에 대한 평가에서 잘못된 답안을 참고하는 오류를 줄이기 위해 참조 답안을 제시하여 GPT-4가 스스로 해결한 후 이를 기준으로 평가하는 방법을 제안합니다.
우리 모델을 하나씩 평가하는 것도 좋지만 두 모델을 승패 판단하여 경쟁하는 것도 하나의 좋은 방법이 된다.
Enhancing Emotional Generation Capability of Large Language Models via Emotional Chain-of-Thought
https://arxiv.org/abs/2401.06836
Enhancing Emotional Generation Capability of Large Language Models via Emotional Chain-of-Thought
Large Language Models (LLMs) have shown remarkable performance in various emotion recognition tasks, thereby piquing the research community's curiosity for exploring their potential in emotional intelligence. However, several issues in the field of emotion
arxiv.org
1. 해결하려는 문제
대형 언어 모델(LLMs)은 다양한 감정 인식 작업에서 탁월한 성능을 보여왔으나, 감정 생성 작업에서는 몇 가지 문제가 존재합니다. 특히, 인간 선호도 정렬 문제와 감정 생성 평가 문제가 주요 도전 과제로 남아 있습니다.
- 인간 선호도 정렬 문제: 모델이 생성한 감정적 응답이 인간의 감정적 기대와 일치하지 않거나, 사용자에게 부정적인 영향을 미칠 수 있습니다. 예를 들어, 유머를 포함한 응답을 요구했을 때, 모델이 불쾌하거나 부정적인 감정을 유발할 수 있는 답변을 생성하는 경우가 있습니다.
- 감정 생성 평가 문제: 감정 생성은 매우 주관적인 작업으로, 명확한 평가 기준이 부족합니다. 기존의 평가 방법은 인간 전문가의 평가에 의존하며, 이에 대한 자동화된 평가 지표가 필요합니다.
2. 시도한 해결 방법
이를 해결하기 위해, 논문은 두 가지 주요 방법을 제안합니다.
- Emotional Chain-of-Thought (ECoT): 인간의 감정 지능 이론을 기반으로 감정 인식을 단계별로 수행하는 일종의 플러그 앤 플레이 방식의 프롬프트 기법입니다. 이를 통해 LLMs가 감정 생성 작업에서 더 나은 성능을 발휘하도록 유도합니다. 감정 생성 과정은 다음과 같은 단계로 나뉩니다:
- 문맥 이해: 주어진 대화나 상황의 맥락을 이해합니다.
- 타인의 감정 인식: 대화 상대방의 감정을 인식하고 그 이유를 설명합니다.
- 자신의 감정 인식: 화자의 감정을 인식하고 그 이유를 설명합니다.
- 자신의 감정 조절: 공감을 바탕으로 적절한 대응 방법을 고려합니다.
- 타인의 감정에 영향 미치기: 응답이 상대방에게 미칠 영향을 고려하여 감정적인 응답을 생성합니다.
- Emotional Generation Score (EGS): 기존의 전문가 평가 대신 자동화된 평가 지표로, 감정 생성 작업에서 모델의 성능을 다양한 감정 지능의 차원에서 평가할 수 있도록 설계된 메트릭입니다. Goleman의 감정 지능 이론을 기반으로 하며, 인간 전문가의 평가와 높은 일관성을 보입니다.
3. 사용한 방법
- ECoT는 Goleman의 감정 지능 이론을 기반으로 설계된 프롬프트 기법으로, 모델이 감정 생성 작업을 수행할 때 체계적인 사고 과정을 거치도록 유도합니다. 예를 들어, 대화 응답을 생성할 때 모델이 상대방의 감정을 먼저 인식하고 그에 맞춰 응답을 생성하는 방식입니다.
- EGS는 모델의 감정 생성 능력을 평가하기 위한 자동화된 평가 방법으로, 여러 감정 지능의 차원에서 모델의 응답을 점수화하여 최종 평가 점수를 도출합니다. 이를 통해 수작업 없이도 모델의 성능을 평가할 수 있습니다.
4. 결과
논문은 여러 데이터셋(IEMOCAP, DailyDialog, EmpatheticDialogues 등)에서 ECoT가 적용된 모델이 기존 모델에 비해 감정 생성 작업에서 더 나은 성능을 발휘함을 입증했습니다. ECoT를 적용한 모델은 감정 인식 및 생성에서 더 높은 평가를 받았으며, 특히 인간 선호도에 맞는 응답을 생성하는 데 유리한 것으로 나타났습니다. 예를 들어, IEMOCAP 데이터셋에서 모델의 성능은 ECoT를 적용한 후 평균적으로 4~12점 정도 상승했습니다.
5. 한계점
- 주관성의 문제: 감정 생성 작업은 본질적으로 주관적이기 때문에, 인간 선호도와 모델의 응답이 항상 일치하지 않을 수 있습니다. 다양한 문화적, 개인적 차이를 감안한 더 정교한 평가 기준이 필요합니다.
- 인간 전문가 평가: 자동화된 평가 지표(EGS)는 인간 전문가 평가와 높은 상관성을 보였지만, 여전히 전적으로 인간 전문가의 판단을 대체하기는 어려울 수 있습니다.
결론
이 논문은 LLMs의 감정 생성 능력을 향상시키기 위해 ECoT와 EGS를 제안하고, 이를 통해 모델이 감정적 응답을 보다 인간 중심적으로 생성할 수 있음을 입증했습니다. 그러나 감정 생성의 주관성 문제와 평가의 한계점이 남아 있으며, 이러한 부분에서 추가적인 연구가 필요합니다.
EGS - 감성 영역에서 새로운 평가 지표, 인간의 감성 지능에 대한 다양한 관점에서 LLM의 감성 생성 능력 측정
GPT 3.5가 각 메트릭을 1~10점으로 점수를 매겨 합산 점수를 평가 지표로 사용
동일한 입력에 대한 여러 응답을 동시에 평가하는 것이 좋다!
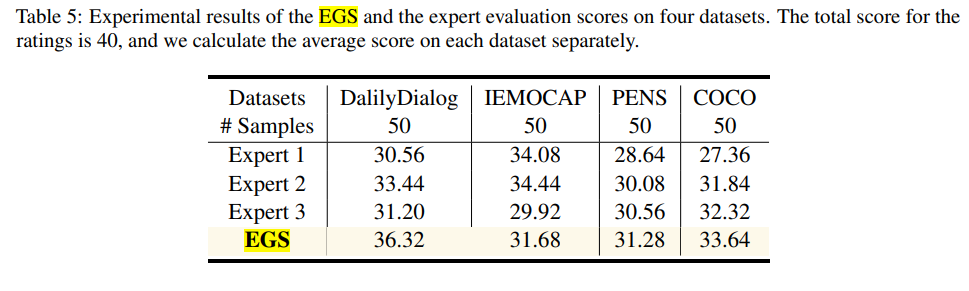
전문가가 평가한 점수와 비슷하다 == 신뢰할 수 있는 자동 평가 방법으로 활용될 수 있다.

이것이 저희가 사용하게 될 탬플릿 이네요
'인공지능 > 자연어 처리' 카테고리의 다른 글
| chat bot을 통한 inference 후 chat gpt API를 사용하여 평가하기 (0) | 2024.09.20 |
|---|---|
| 모델 추론 코드 작성하기 - Transformer, peft, inference (1) | 2024.09.19 |
| Model의 파라미터를 줄이는 방법 - Pruning with LLM 1 (1) | 2024.09.05 |
| 자연어 처리 복습 5 - 사전 학습, 전이 학습, 미세 조정 (4) | 2024.09.03 |
| 자연어 처리 복습 4 - seq2seq, ELMo, Transformer, GPT, BERT (0) | 2024.09.03 |