LLM을 설명할 방법이 없을까 생각하면서 웹을 뒤적거리다가 파라미터가 전부 활성화 되어있는 것이 아닌 일부분만 활성화 되어있는 것을 볼 수 있었습니다.
그럼 이런 파라미터를 버리면 되는거 아닌가? 하고 찾아보니 pruning이라는 방법이 있었습니다. ㅎㅎ
https://simpling.tistory.com/50
Neural Network Pruning - 모델 경량화
Intro Pruning은 neural network를 경량화하고자 할 때 사용하는 방법입니다. Figure 1은 pruning을 잘 보여주는 그림입니다. 모든 node가 연결이 되어있던 왼쪽 그림으로 오른쪽과 같이 synapse(혹은 edge)와 neuro
simpling.tistory.com
이 부분에 대한 정리는 이 분 블로그에서 보고 배웠습니다.
이제 논문을 읽어보면서 이 방법에 대해 정리해보려 합니다.
To prune, or not to prune: exploring the efficacy of pruning for model compression
https://arxiv.org/abs/1710.01878
To prune, or not to prune: exploring the efficacy of pruning for model compression
Model pruning seeks to induce sparsity in a deep neural network's various connection matrices, thereby reducing the number of nonzero-valued parameters in the model. Recent reports (Han et al., 2015; Narang et al., 2017) prune deep networks at the cost of
arxiv.org
1. 해결하려는 문제
딥러닝 모델은 높은 성능을 제공하지만, 모델이 크고 복잡하여 메모리 사용량이 많고 계산 비용이 큽니다. 특히 모바일 기기와 같은 자원이 제한된 환경에서 이러한 모델을 배포할 때, 모델의 크기와 연산 비용을 줄이기 위한 방법이 필요합니다. 이 논문은 딥러닝 모델의 파라미터 수를 줄여 모델을 압축함으로써 메모리 사용을 줄이고, 에너지 효율적인 추론을 가능하게 하기 위한 가지치기 기법을 탐구합니다.
2. 시도한 방법
논문은 크게 두 가지 모델 압축 방법을 비교합니다:
- Large-Sparse Model: 큰 모델을 훈련한 후 불필요한 연결(파라미터)을 가지치기하여 희소한 모델을 생성.
- Small-Dense Model: 처음부터 작은 모델을 훈련하여 밀집된 구조를 유지.
이 두 방법은 메모리 사용량과 모델 정확도 간의 트레이드오프를 제공하며, 논문에서는 특히 에너지 효율적 추론을 위한 희소 모델의 성능을 중점적으로 살펴봅니다.
3. 사용한 방법
논문에서 제안한 가지치기 기법은 점진적 가지치기(gradual pruning)입니다. 이는 훈련 과정 중에 점진적으로 모델의 연결을 가지치기하는 방식입니다. 구체적으로, 아래와 같은 수식을 사용하여 가지치기 정도를 조절합니다:
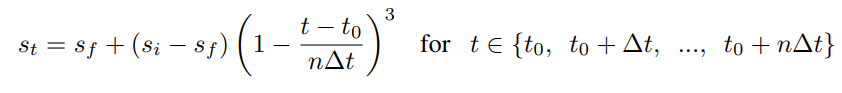
- st: 가지치기 단계에서의 희소성
- si: 초기 희소성
- sf: 최종 희소성
- t0: 가지치기 시작 단계
- Δt: 가지치기 주기
- n: 가지치기 단계 수
이 방법은 네트워크의 희소성을 천천히 증가시키면서 네트워크가 가지치기에 의해 발생한 손실을 회복할 수 있도록 하며, 다양한 모델 아키텍처에서 효과적으로 동작함을 실험을 통해 증명합니다.
4. 결과
논문에서는 다양한 모델 아키텍처에서 Large-Sparse 모델과 Small-Dense 모델을 비교하였으며, Large-Sparse 모델이 일관되게 더 나은 성능을 보였습니다. 예를 들어, MobileNet과 같은 모델에서, 가지치기를 통해 75% 희소성을 적용한 모델이 작은 밀집 모델보다 더 적은 파라미터로 더 높은 정확도를 기록했습니다.
- MobileNet의 경우 75% 가지치기를 통해 1.09M 파라미터를 가진 모델이, 0.5 MobileNet (1.32M 파라미터)보다 4% 더 높은 Top-1 정확도를 보였습니다.
또한, Penn Tree Bank (PTB) 언어 모델에서는 Large-Sparse 모델이 Small-Dense 모델보다 파라미터 수가 적음에도 더 나은 성능을 보였습니다.
5. 한계점
희소성을 적용한 모델의 경우, 가지치기를 적용한 후에도 희소 행렬을 저장하기 위한 추가적인 저장 공간이 필요할 수 있습니다. 이는 압축 비율을 감소시키는 요인이 될 수 있으며, 더 높은 압축 비율을 얻기 위해서는 추가적인 최적화가 필요합니다. 또한, 논문에서는 32비트 부동소수점(floating-point) 연산을 사용하여 실험하였지만, 8비트 정수 연산을 통한 양자화(quantization) 기법과 가지치기를 함께 적용할 때의 성능에 대한 추가적인 연구가 필요합니다.
결론
이 연구는 다양한 신경망 아키텍처에서 Large-Sparse 모델이 Small-Dense 모델보다 더 나은 성능을 보인다는 것을 보여주었으며, 자원 제한 환경에서 딥러닝 모델의 압축을 위한 가지치기 기법의 가능성을 입증했습니다.
큰 pruning model과 작은 dense model을 비교하여 pruning의 중요성, 필요성 확인
-> 큰 모델이 작은 모델에 비해 높은 정확도를 가지고 가면서 매개 변수를 최대 10배로 줄일 수 있게 됨
Structured Pruning of Large Language Models
https://arxiv.org/abs/1910.04732
Structured Pruning of Large Language Models
Large language models have recently achieved state of the art performance across a wide variety of natural language tasks. Meanwhile, the size of these models and their latency have significantly increased, which makes their usage costly, and raises an int
arxiv.org
이 논문은 대형 언어 모델(LLM)의 크기와 속도를 줄여 비용을 절감하고 성능을 유지하면서도 처리 속도를 높이기 위한 압축 방법을 연구한다. 주로 구조적 가중치 제거(pruning) 방법을 제안하며, 각 가중치 행렬을 저차원 행렬로 분해하고, 훈련 중에 적응적으로 불필요한 랭크-1(ranking) 성분을 제거한다.
해결하고자 하는 문제:
대형 언어 모델은 자연어 처리에서 뛰어난 성능을 보이지만, 모델의 크기와 연산량이 증가하여 실제 응용에서 사용하기 어렵다. 이러한 문제는 높은 비용과 속도 저하를 초래하며, 이를 해결하기 위해 모델 압축이 필요하다.
시도한 방법:
- 저차원 행렬 분해: 가중치 행렬을 저차원으로 분해하고 불필요한 성분을 제거함으로써 성능을 유지하면서도 모델 크기를 줄이는 방법을 적용했다.
- 적응적 제거: 훈련 중에 저차원 성분 중 성능에 크게 영향을 주지 않는 부분을 자동으로 찾아 제거하는 방식으로, 일반적인 구조적 제거보다 성능을 개선할 수 있었다.
- l0 정규화: 최종 압축 수준을 직접 제어하기 위해 l0 정규화를 개선하여 적용하였다.
사용한 방법:
- FLOP(Factorized Low-rank Pruning): 저차원 행렬 분해 기반의 구조적 가중치 제거 방법을 사용하여 성능과 압축 간의 최적 균형을 맞춘다. 이 방법은 가중치 행렬을 두 개의 더 작은 행렬로 분해하고 훈련 중에 저차원 성분을 제거하는 방식으로 이루어진다.
- 강화된 l0 정규화: 모델 크기를 원하는 만큼 조절하기 위해 Augmented Lagrangian 방법을 사용해 l0 정규화를 적용한다.
- 적응적 임베딩 및 소프트맥스 계층: 대형 언어 모델에서 중요한 역할을 하는 임베딩 계층을 최적화하기 위해 임베딩 차원을 동적으로 학습하여, 자주 사용되지 않는 단어는 더 작은 차원으로 축소하는 방식을 적용했다.
결과:
- 성능 유지 및 모델 압축: FLOP 방법을 적용한 결과, 모델 크기를 50% 줄이면서도 성능은 0.8 perplexity 정도만 감소하였다.
- 속도 개선: 훈련과 추론 모두에서 약 2배 이상의 속도 향상을 얻을 수 있었다.
- 범용성: FLOP 방법은 다양한 자연어 처리 모델과 함께 사용할 수 있으며, 추가 하드웨어나 소프트웨어가 필요하지 않았다.
한계점:
- 특정 하드웨어 의존성: 저차원 행렬 분해 기반 방법은 일반적인 하드웨어에서 효과적으로 작동하지만, 일부 모델에서는 추가적인 최적화가 필요할 수 있다.
- 압축 성능 한계: 더 높은 압축 수준에서 성능 저하가 발생할 수 있으며, 이때 l0 정규화의 효과가 제한적일 수 있다.
Language model은 크기와 대기시간이 크기 때문에 모델이 꼭 커야하는지 의문이 제기된다.
pruning - sparse matrix 연산을 위한 특별한 하드웨어가 필요하며, 속도에 대한 향상은 어려웠다.
improved structed pruning - low rank factorization과 adaptively removing rank-1를 진행
모델 압축 기술은 3가지로 분류된다
1. weight pruning
2. kmowledge distillation
3. quantization
multi-head attention pruning, adaptive embedding과 softmax layers, distillation을 통한 발전이 있었다.
이 논문의 pruning 방식은 양자화와 distillation 모두 적용될 수 있다.
z가 0,1로 나뉘며 파라미터를 죽이거나 그대로 살린다. 그리고 z의 총 합이 파라미터가 살아있는 수 이므로 이것을 통해 모델의 유효 크기를 확인할 수 있다.


weight W를 PQ로 표현하고, G가 z를 표현해준다.
Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned
Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned
Elena Voita, David Talbot, Fedor Moiseev, Rico Sennrich, Ivan Titov. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019.
aclanthology.org
논문 제목은 "Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned"로, Transformer 모델의 multi-head self-attention 메커니즘을 분석하고, 이를 통해 성능 최적화를 목표로 하고 있습니다. Transformer는 주로 기계 번역에 사용되는 최첨단 모델로, multi-head attention 메커니즘을 통해 다양한 정보 표현을 동시에 학습할 수 있습니다.
1. 문제 정의
이 논문은 Transformer 모델의 multi-head self-attention 메커니즘에서 각 head의 기여도와 역할을 평가하는 것을 목표로 합니다. 특히, 각 attention head가 모델 성능에 얼마나 기여하는지, 특정 head들이 어떤 특화된 역할을 수행하는지, 그리고 불필요한 head를 제거했을 때 성능 저하가 얼마나 일어나는지를 연구합니다. 이를 통해 Transformer 모델에서 과도한 head 수를 줄여 계산 효율성을 높이는 방법을 제안하고자 했습니다.
2. 시도된 방법
연구진은 attention head의 기여도를 평가하기 위해 두 가지 주요 방법을 사용했습니다.
- Layer-wise Relevance Propagation(LRP): 이 방법을 사용하여 각 head가 모델 예측에 얼마나 기여하는지를 평가하였습니다. LRP를 통해 특정 head가 다른 head들에 비해 얼마나 중요한 역할을 하는지, 그 중요도를 계산했습니다.
- Pruning 방법: 불필요한 head를 제거하기 위해 L0 정규화의 연속적인 완화를 적용한 pruning 기법을 사용했습니다. 각 head의 활성화 정도를 제어할 수 있는 확률적 게이트를 사용하여 모델 성능에 큰 영향을 미치지 않는 head들을 점진적으로 제거했습니다.
3. 사용된 방법
논문에서 Transformer 모델의 구조를 간략히 설명하며, attention head의 역할을 다음과 같이 세 가지로 분류했습니다.
- Positional heads (위치적 역할): 주로 인접한 토큰에 주의를 기울이며, 문장에서 토큰 간의 위치적 관계를 학습하는 head.
- Syntactic heads (구문적 역할): 구문 구조에 따라 특정 문법적 관계를 학습하는 head (예: 주어와 동사, 목적어와 동사 간의 관계).
- Rare word heads (희귀 단어에 대한 주의): 문장에서 자주 등장하지 않는 희귀한 단어에 주목하는 head.
4. 결과
논문에서 도출된 주요 결과는 다음과 같습니다.
- 소수의 중요한 head만이 모델 성능에 크게 기여한다는 점을 발견했습니다. 예를 들어, 48개의 encoder head 중에서 38개를 제거해도 BLEU 점수에서 0.15 정도만 감소했습니다.
- 중요한 head들은 대부분 해석 가능한 역할을 수행했습니다. 특히, 인접한 단어에 주의를 기울이거나 특정 구문적 관계에 따라 작동하는 head들이 마지막까지 유지되는 경향이 있었습니다.
- Pruning 실험을 통해 성능 저하 없이 다수의 head를 제거할 수 있음을 입증하였으며, 이는 모델의 계산 효율성을 크게 향상시킬 수 있음을 시사합니다.
5. 한계점
- 학습 도메인과 데이터의 영향: 모델이 사용하는 도메인에 따라 pruning의 성능이 다를 수 있으며, 특정 도메인에서는 더 많은 head가 필요할 수 있다는 점을 지적했습니다.
- Pruning된 모델의 학습 초기 성능: 학습이 완료된 모델에서 head를 제거하는 것은 성능 유지가 가능하지만, 처음부터 적은 수의 head로 모델을 학습할 경우 성능 저하가 발생할 수 있음을 발견했습니다.
주요 계산식
Transformer의 multi-head attention 메커니즘은 다음과 같은 수식을 통해 표현됩니다:

여기서 , , V는 Query, Key, Value 매트릭스를 의미하고, dk는 key의 차원입니다.
Pruning 과정에서는 각 head i의 출력을 scalar gate gi로 곱하여 다음과 같이 수정된 attention 메커니즘을 적용했습니다:

이 gate gi는 head의 중요도에 따라 활성화 여부를 결정하는 파라미터입니다.
이 논문은 Transformer 모델의 효율성을 높이기 위해 각 head의 역할을 분석하고 불필요한 head를 효과적으로 제거하는 방법을 제안함으로써, 향후 더 가볍고 효율적인 모델 설계에 기여할 수 있습니다.
Multi-head attention을 진행할 때 모든 head가 영향을 끼치는 것이 아니다.
48개 중 10개만 남겨도 성능이 거의 보존되었다!
From Dense to Sparse: Contrastive Pruning for Better Pre-trained Language Model Compression
https://arxiv.org/abs/2112.07198
From Dense to Sparse: Contrastive Pruning for Better Pre-trained Language Model Compression
Pre-trained Language Models (PLMs) have achieved great success in various Natural Language Processing (NLP) tasks under the pre-training and fine-tuning paradigm. With large quantities of parameters, PLMs are computation-intensive and resource-hungry. Henc
arxiv.org
논문의 요약: "Contrastive Pruning for Better Pre-trained Language Model Compression"
- 문제가 무엇인가?
- 사전 학습된 언어 모델(Pre-trained Language Models, PLMs)은 자연어 처리(NLP) 작업에서 성공을 거두었지만, 매우 많은 수의 파라미터로 인해 계산량이 크고 자원이 많이 소모됩니다. 기존의 모델 압축 기법들은 대부분 특정 작업에 특화된(task-specific) 지식만을 고려하여 모델을 축소하는데, 이로 인해 중요한 일반적인(task-agnostic) 지식이 손실될 수 있습니다. 이러한 손실은 "카타스트로피 망각(catasrophic forgetting)" 현상을 초래하여 모델의 일반화 능력을 저하시킵니다.
- 어떤 방법을 시도했는가?
- 대조 학습(Contrastive Learning)을 이용한 새로운 대조적 프루닝(Contrastive Pruning, CAP) 프레임워크를 제안했습니다. 이 프레임워크는 사전 학습된 모델의 일반적인 지식과 미세 조정된(fine-tuned) 모델의 특정 작업 지식을 모두 보존하도록 설계되었습니다. CAP는 프루닝 과정에서 생성된 중간 스냅샷 모델도 활용하여 다양한 지식을 유지하고 성능을 보장합니다.
- 어떤 방법을 사용했는가?
- CAP는 세 가지 주요 모듈로 구성됩니다:
- PrC (Pre-trained Contrastive Learning): 사전 학습된 모델과 대조 학습을 통해 일반적인 언어 지식을 보존.
- SnC (Snapshot Contrastive Learning): 프루닝 과정 중 생성된 중간 모델 스냅샷과 대조 학습을 통해 다각적이고 다양한 지식을 학습.
- FiC (Fine-tuned Contrastive Learning): 미세 조정된 모델과 대조 학습을 통해 특정 작업에 대한 지식을 학습.
- 대조 학습의 목표는 비슷한 문장 표현을 가깝게 하고, 다른 표현은 멀어지게 하는 방식으로 학습을 진행하며, 이는 다음 수식으로 나타낼 수 있습니다:

여기서 sim(zi,zj)는 두 벡터의 코사인 유사도를 나타내고, τ는 온도 매개변수입니다.
- CAP는 세 가지 주요 모듈로 구성됩니다:
- 결과는 어떻게 되었는가?
- CAP는 다양한 프루닝 기준에서 일관되게 성능을 향상시켰으며, 특히 높은 희소성 상황(97%의 희소성, 즉 3%의 파라미터만 남는 경우)에서도 큰 성능 저하 없이 거의 원래의 모델 성능에 도달했습니다. 예를 들어, BERT 모델의 97%를 프루닝한 후에도 QQP(Quora Question Pairs) 작업에서 99.2%의 성능, MNLI(Multi-Genre Natural Language Inference) 작업에서 96.3%의 성능을 유지했습니다.
- 한계점은 무엇인가?
- CAP는 프루닝 과정에서 여러 모델을 참조하는 방식이므로, 메모리 사용량이 늘어날 수 있으며, 이는 매우 자원이 제한된 환경에서는 제약이 될 수 있습니다. 다만 CAP는 필요시 미리 계산된 문장 표현만을 참조하도록 설계하여 메모리 사용량을 최소화했습니다.
Chain-of-Thought 분석:
- 문제 정의: 큰 사전 학습된 언어 모델의 파라미터 수가 너무 많아 실질적인 적용에 어려움이 있음.
- 기존 접근법의 한계: 기존 프루닝 방법들은 특정 작업에 특화된 지식만을 보존하려 하여, 일반적인 지식이 손실되고 이로 인해 모델의 전반적인 성능이 저하되는 문제가 발생.
- 해결 방안 제안: CAP 프레임워크를 통해 일반적인 지식과 특정 작업 지식을 모두 보존하는 방식으로 문제 해결을 시도.
- 결과: 다양한 작업에서 성능을 크게 향상시켰으며, 특히 높은 희소성 상황에서도 우수한 성능을 유지함.
- 한계점: 메모리 사용량이 증가할 수 있으나, 이를 완화하기 위한 설계가 포함됨.
이 논문은 모델 프루닝 과정에서 일반적인 지식과 특정 작업 지식을 동시에 보존하기 위한 체계적인 접근을 제시했으며, 높은 희소성에서도 좋은 성능을 유지하는 성과를 달성했습니다.
CAP(ContrAstive Purning) - 파인튜닝, pruning해도 이전의 일을 잊지 않는다. -> 3%의 parameters만 가지고 성능을 보존했다?!
Contrastive learning - representation learning을 위한 효과적인 메커니즘
갑자기 일정이 생겨서 이 이후는 다음에 ....
Compact Language Models via Pruning and Knowledge Distillation
A SIMPLE AND EFFECTIVE PRUNING APPROACH FOR LARGE LANGUAGE MODELS
Shortened LLaMA: Depth Pruning for Large Language Models with Comparison of Retraining Methods
Towards Lossless Head Pruning through Automatic Peer Distillation for Language Models
ZipLM: Inference-Aware Structured Pruning of Language Models
LaCo: Large Language Model Pruning via Layer Collapse
LLM-Pruner: On the Structural Pruning of Large Language Models
LANGUAGE MODEL SIZE REDUCTION BY PRUNING AND CLUSTERING
Pruning Pre-trained Language Models Without Fine-Tuning
https://github.com/locuslab/wanda
GitHub - locuslab/wanda: A simple and effective LLM pruning approach.
A simple and effective LLM pruning approach. Contribute to locuslab/wanda development by creating an account on GitHub.
github.com
'인공지능 > 자연어 처리' 카테고리의 다른 글
| 모델 추론 코드 작성하기 - Transformer, peft, inference (1) | 2024.09.19 |
|---|---|
| ESC Task, ESConV 평가 방식 (3) | 2024.09.05 |
| 자연어 처리 복습 5 - 사전 학습, 전이 학습, 미세 조정 (4) | 2024.09.03 |
| 자연어 처리 복습 4 - seq2seq, ELMo, Transformer, GPT, BERT (0) | 2024.09.03 |
| 자연어 처리 복습 3 - 토큰화, 임베딩, 언어 모델 (2) | 2024.09.03 |