728x90
728x90
어제 inference만 했다면 오늘은 평가까지 진행해보겠습니다.
import json
import os
import torch
from setproctitle import setproctitle
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
from peft import PeftModel, PeftConfig
from openai import OpenAI
client = OpenAI(api_key="")여기에 api 키를 넣어줍니다.
연구실 API가 있으니 너무 편하네요....
setproctitle("")
os.environ["CUDA_VISIBLE_DEVICES"] = "7"
# 테스트 데이터 경로 및 저장 경로 설정
test_data_path = "ESConv_trans_test.json"
output_file = "inference_results.txt"
based_model = "KULLM3"
base_model = "kor_esc_kullmv3"
device = "cuda"어제처럼 경로도 다 설정해줍니다.
Cuda GPU도 다 설정해주고요
pre_prompt_template = """**[System]**
You are an expert in emotional intelligence based on Goleman’s model, and your task is to evaluate how well a assistant’s response aligns with emotional intelligence principles. You will assess the “assistant’s” self-awareness, self-regulation, motivation, empathy, and social skills based on their response. Print out only each score without including any words or characters, just the numeric values.
**[Context]**
{content}
**[Prompt]**
The above is a conversation between the "assistant" and the "user". Now the "assistant" needs to make an appropriate response to the "user". Below is a possible response from the "assistant". Please evaluate the quality of the response based on the following criteria. Assign a score from 1 to 10 for each criterion, with higher scores indicating better alignment with the criteria.
**[Response]**
assistant: {response}
**[Criteria]**
Self-Awareness (C1): The assistant demonstrates an awareness of their emotions and how their emotions or words may affect the user. The response reflects self-confidence and emotional understanding.
Self-Regulation (C2): The assistant manages their emotions well, avoiding impulsivity or negative expressions like anger, frustration, or resentment. The response maintains composure and offers a balanced approach.
Motivation (C3): The assistant's response reflects optimism and a drive to achieve positive outcomes. There is a clear effort to inspire or encourage action towards constructive goals.
Empathy (C4): The assistant shows an understanding of the user’s feelings and perspective, offering a compassionate and supportive response that avoids stereotyping or judgment.
Social Skills (C5): The assistant effectively uses communication skills to resolve conflicts, enhance collaboration, or provide leadership in the conversation. The response should foster a productive and positive dialogue between the assistant and user."""프롬포트도 미리 지정해둡니다.
나중에 content와 response만 싹 넣으면 됩니다.
def load_test_data(test_data_path):
# JSON 파일에서 테스트 데이터를 로드
with open(test_data_path, 'r') as f:
test_data = json.load(f)
return test_data데이터 셋 읽는 함수도 만들어 줍니다.
test_data = load_test_data(test_data_path)
base__model = AutoModelForCausalLM.from_pretrained(based_model)
tokenizer = AutoTokenizer.from_pretrained("kor_esc_kullmv3")
model = PeftModel.from_pretrained(base__model, "kor_esc_kullmv3")베이스 모델, 토크나이저, 모델 다 불러옵니다.
여기서 왜 경로를 직접 줬는지는 기억이 안나네요 ㅎㅎ..
chat_pipeline = pipeline(
"text-generation",
model = model,
eos_token_id = tokenizer.eos_token_id,
tokenizer = tokenizer,
max_new_tokens = 400,
do_sample = False,
use_cache = True,
device = "cuda:0"
)파이프 라인 지정해주기!
def split_score_string(score_string):
score_string = score_string.replace("\n", " ").replace("\r", " ").replace("\t", " ")
if " " in score_string:
# 공백이 있으면 공백을 기준으로 나눈다.
score = score_string.split()
else:
# 공백이 없으면, 숫자를 정확히 5개로 나누어야 한다.
score = []
i = 0
while i < len(score_string):
# 남은 숫자가 5 - len(score)일 때, 남은 길이에 맞춰 한 자리씩 나눈다.
if len(score_string) - i == 5 - len(score):
score.extend([int(char) for char in score_string[i:]])
break
elif score_string[i:i+2] == "10":
# '10'을 만나면 두 자리 숫자로 처리
score.append(10)
i += 2
else:
# 한 자리 숫자를 처리
score.append(int(score_string[i]))
i += 1
return scoreGPT한테 아무리 숫자만 뱉으라고 해도 가끔씩 이상하게 뱉을 때가 있어서 오류 처리용으로 함수 만들었습니다.
c1=457
c2=522
c3=469
c4=471
c5=468
total_count = 72
with open("inference_resultspeft.txt", 'a') as f:
responses = []
f.write(f"KuLLM3peft inference evaluate\n")
for i, item in enumerate(test_data):
if i < 6:
continue
f.write(f"Dialog: {i}\n")
dialog_score = 0
dialog_c4 = 0
dialog = item['dialog']
chat = []
context = ""
# 롤 매핑 설정 (user는 고정, assistant는 모델이 생성)
response = ""
count = 0
for j, turn in enumerate(dialog):
if turn['speaker'] == 'usr':
if j > 0 and chat and chat[-1]['role'] == 'user':
# 이전 발화가 'user'인 경우 현재 내용을 이어붙임
chat[-1]['content'] += ' ' + turn['trans_text']
context = context + " " + turn['trans_text']
#f.write(f"user (updated): {turn['trans_text']}\n\n")
else:
# 새로운 'user' 발화를 추가
chat.append({"role": "user", "content": turn['trans_text']})
context = context + "\n\nuser: " + chat[-1]['content']
#f.write(f"user: {turn['trans_text']}\n\n")
elif turn['speaker'] == 'sys':
if not chat:
continue
if chat and chat[-1]['role'] == 'assistant':
continue
# 여기서는 모델이 assistant 발화 부분을 생성
#print("input: " + str(chat))
#f.write(f"input: {context}\n---------------\n\n")
output = chat_pipeline(chat)
chat = output[0]['generated_text']
response = output[0]['generated_text'][-1]['content']
#f.write(f"response: {response}\n-------------\n\n")
pre_prompt = pre_prompt_template.format(content=context, response=response)
context = context + "\n\nassistant: " + response
completion = client.chat.completions.create(
model="gpt-4o-2024-08-06",
messages=[
{"role": "system", "content": pre_prompt} # pre_prompt는 system 역할로 전달
]
)
#f.write(f"gpt: {completion.choices[0].message.content}\n-------------\n\n")
score = split_score_string(completion.choices[0].message.content)
#print(score)
c1 += int(score[0])
c2 += int(score[1])
c3 += int(score[2])
c4 += int(score[3])
c5 += int(score[4])
dialog_score += int(score[4]) + int(score[3]) +int(score[2]) +int(score[1]) +int(score[0])
dialog_c4 += int(score[3])
count+= 1
total_count+=1
if chat and chat[-1]['role'] == 'assistant':
f.write("\n")
f.write(f"dialog end \n\n dialog_score: {dialog_score} aveg:{dialog_score/count}\n dialog_c4: {dialog_c4} aveg: {dialog_c4/count}\n c1: {c1} c2: {c2} c3: {c3} c4: {c4} c5: {c5}\n aveg c1: {c1/total_count} c2: {c2/total_count} c3: {c3/total_count} c4: {c4/total_count} c5: {c5/total_count}\ncount: {count} total_count: {total_count}\n-------------\n\n")
f.flush() # 매번 저장하여 데이터 유실 방지
continue
#print("input: " + str(chat))
output = chat_pipeline(chat)
chat = output[0]['generated_text']
response = output[0]['generated_text'][-1]['content']
pre_prompt = pre_prompt_template.format(content=context, response=response)
#f.write(f"response: {response}\n\n")
completion = client.chat.completions.create(
model="gpt-4o-2024-08-06",
messages=[
{"role": "system", "content": pre_prompt} # pre_prompt는 system 역할로 전달
]
)
#f.write(f"gpt: {completion.choices[0].message.content}\n-------------\n\n")
score = split_score_string(completion.choices[0].message.content)
c1 += int(score[0])
c2 += int(score[1])
c3 += int(score[2])
c4 += int(score[3])
c5 += int(score[4])
dialog_score += int(score[4]) + int(score[3]) +int(score[2]) +int(score[1]) +int(score[0])
dialog_c4 += int(score[3])
count+= 1
total_count+=1
f.write(f"dialog end \n\n dialog_score: {dialog_score} aveg:{dialog_score/count}\n dialog_c4: {dialog_c4} aveg: {dialog_c4/count}\n c1: {c1} c2: {c2} c3: {c3} c4: {c4} c5: {c5}\n aveg c1: {c1/total_count} c2: {c2/total_count} c3: {c3/total_count} c4: {c4/total_count} c5: {c5/total_count}\ncount: {count} total_count: {total_count}\n-------------\n\n")
f.write("\n")
f.flush() # 매번 저장하여 데이터 유실 방지
total_score = c1 + c2 + c3 + c4 + c5
f.write(f"evaluate end \n\n total_score: {total_score} aveg:{total_score/total_count}\n c1: {c1} c2: {c2} c3: {c3} c4: {c4} c5: {c5}\n aveg c1: {c1/total_count} c2: {c2/total_count} c3: {c3/total_count} c4: {c4/total_count} c5: {c5/total_count}\ntotal_count: {total_count}\n-------------\n\n")이렇게 하면 마무리!
저는 도중에 GPT가 예상치 못한 출력을 뱉어서 한번 끄는 바람에 입력을 넣어줬습니다.
평상시라면 0으로 두고 사용할 것 같습니다.
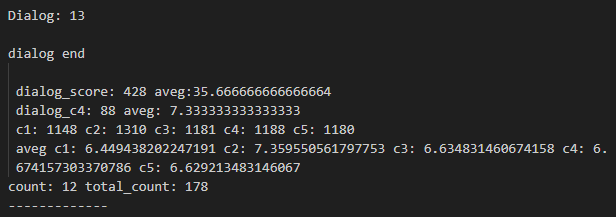
이렇게 잘 뱉고 있습니다.
728x90
'인공지능 > 자연어 처리' 카테고리의 다른 글
| SAE tutorials - SAE basic (2) | 2024.09.22 |
|---|---|
| SAE 튜토리얼 진행해보기 - training SAE (1) | 2024.09.20 |
| 모델 추론 코드 작성하기 - Transformer, peft, inference (1) | 2024.09.19 |
| ESC Task, ESConV 평가 방식 (3) | 2024.09.05 |
| Model의 파라미터를 줄이는 방법 - Pruning with LLM 1 (1) | 2024.09.05 |