기본적인 딥러닝은 이 전에 작성한 글에서 확인하면 됩니다.
2024.08.25 - [인공지능/공부] - 딥러닝 복습 1 - Linear Reagression, Logistic regression,Neural Network
딥러닝 복습 1 - Linear Reagression, Logistic regression,Neural Network
Linear Regression 선형 회귀로 지도학습(Supervised Learning)을 통해 정답을 학습해 입력에 대한 예측을 출력ex) 집값 예측, 키에 따른 몸무게 예측, 주식 등등..Cost function예측 값h(x)과 정답 값(y)에 대한
yoonschallenge.tistory.com
2024.08.25 - [인공지능/공부] - 딥러닝 복습 2 - Regularization, Drop out, Hyper Parameter, optimization
딥러닝 복습 2 - Regularization, Drop out, Hyper Parameter, optimization
Regularization이전 글에서 나왔던 오버 피팅을 방지하기 위해 나왔던 방법이다.2024.08.25 - [인공지능/공부] - 딥러닝 복습 1 - Linear Reagression, Logistic regression,Neural Network 딥러닝 복습 1 - Linear Reagression,
yoonschallenge.tistory.com
Transformer
LSTM으로 long term memory를 모델링 했지만 결국 long term dependency를 해결하지 못함
attention을 통해 정보를 가중합하자!!
input embedding - 모델로 입력 되는 값
positional embedding - 입력에 대한 순서 정보를 주입하기 위해 일정한 규칙의 숫자를 정한다.
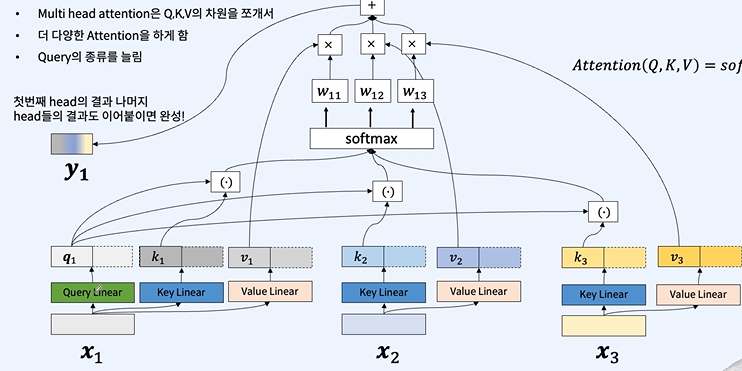
transformer도 encoder, decoder 구조로 되어있다.
encoder only - BERT, RoBERTa1
decoder only - GPT-3
encoder, decoder - BART, T5
Transfer learning
전이학습으로 A에 대해 학습 된 모델이 새로운 문제인 B를 해결하기 위해 학습을 진행하는 상황이다.
파라미터를 전부 다 바꾸거나 일정 부분을 고정해서 나머지만 바꾼다.


인공지능이 단어를 표현하는 방법 (token)
인공지능은 단어를 그대로 이해할 수 없다. 숫자로 변환해야 한다.
그럼 어떻게 숫자로 변환하냐...?
-> 단어로 쪼개기
-> 공백 단위로 쪼개기
-> 글자 마다 쪼개기
-> ....
너무 많다.
적당히 원하는 방식으로 고르거나, 통계적인 방식도 사용할 수 있다.

그럼 문장은 어떻게 표현할까?

이 방식은 순서가 뭉게져서 사라진다.

n이 커질수록 사전 크기가 커지고, 모든 경우를 사전에 등록하니 문제가 생긴다.

중요하지 않은 토큰인 조사의 빈도 수가 높은 경우이다.
이 경우는 어떻게 없앨 수 있을까?

CNN과 RNN을 통해 입력 정보를 읽어올 수 있다.
Self-attention
self-attention은 RNN과 CNN의 일반화로 모든 문맥을 고려하며 국소 지역의 문맥도 고려한다.
문장의 그럴듯함을 측정하는 법
Language modeling - 문장의 그럴듯 함을 계산하는 모델링으로 self-supervised learning을 진행한다.
종류로는 Autoregressive Language model(N-gram Language model, neural language models), bi-directional language model이 있다.
Autoregressive Language Modeling
이전 토큰들이 주어졌을 때 다음 토큰의 확률 분포의 봅이다.
데이터 셋에 있는 문장보다 짧아도 확률을 계산할 수 있고, 문장 단위로 데이터셋을 준비할 필요 없이 말뭉치면 된다.
그러나 확률 분포가 너무 크고, 사전의 개수마다 공간도 너무 크다!
N-Gram Language Modeling
n개 만큼의 확률만 가지고 온다.
그러나 LM학습할 때 사용하지 않은 n-gram이 나오면 전체 확률이 0이 되는 문제가 생긴다

smoothing을 통해 0이 없도록 만든다.
그러나 이런 방식들은 Long-term dependency나 data sparsity가 생기게 된다.
문맥을 통해 단어가 가지는 의미를 알 수 있다!
RNN Language modeling 학습

선택되는 단어를 지속적으로 다음 시퀸스의 입력으로 넣어 문장을 생성할 수 있다.
Transformer를 이용한 Language modeling
decoder only - Autoregressive LM으로 각 토큰의 입력 위치에 대해 다음 토큰을 예측하도록 모델링한다.
미래 토큰을 활용하지 못하도록 attention에 masking을 씌워 지금 입력된 값 까지만 확인할 수 있도록 진행한다.
encoder only - Bi-drectional Transformer을 이용한 LM으로 한 위치의 토큰의 확률을 계산할 때 주변 문맥을 모두 보고 해당 위치의 토큰의 확률을 근사한다.
'인공지능 > 자연어 처리' 카테고리의 다른 글
| 세미나 정리 8-29 (0) | 2024.08.29 |
|---|---|
| 자연어 처리 복습 2 - NLP Task, token, 데이터 전처리 (0) | 2024.08.27 |
| 학습한 모델 웹사이트 챗봇으로 시각화 하기! - 모델 서빙하기 2 (0) | 2024.08.14 |
| 학습한 모델 시각화 하여 보기 깔끔하게 하기! - 모델 서빙하기 1 (0) | 2024.08.13 |
| python 실습 - Huggingface SmolLM fine-tuning 하기 with LoRA - matlab data (0) | 2024.07.25 |