https://www.semanticscholar.org/paper/Call-for-Customized-Conversation%3A-Customized-and-Jang-Lim/c65c96cfc8b448fe9fd6bbfe1aaaea727515f4f7
www.semanticscholar.org
기존 배경 지식, 기존 대화 내용을 잘 활용하는 챗봇, LLM을 만들어 보자!
데이터 세트의 발전과 프리 트레인 모델의 발전으로 인간과 기계의 대화는 최근 상당히 발전했다. 그러나 개인 정보를 반영한 답변에는 아직 제약이 존재한다.
검색을 통한 지식이 필요한 대답이 있고, 사용자와 대화 데이터를 통해 사용자 맞춤 대답을 내놓는 경우가 있다.
for Customized conversation data set - 사용자의 페르소나를 반영하는 지식 기반 답변을 지원하는 데이터 셋
랜드마크는 다양한 사전 지식이 필요하기 때문에 지식의 다양성 보존
1. 페르소나 만들기 - 페르소나는 worker들이 아바타와 랜드마크 선택 후 랜드마크에 대한 개인 배경을 만들어 키워드를 통해 페르소나 문장 생성 -> 페르소나 생성 -> 매력적인 대화 이어짐
2. dialog 만들기 - 페르소나와 랜드마크 지식을 모두 고려해 대화 -> 기계와 인간의 역할을 번갈아가며 혼자 대화를 진행 -> 일관되고, 자연스러운 대화가 가능
FoCus - 페르소나를 경험, 선호도, 소유, 취미, 관심사에 대해 설명
grounding - 출력의 이유를 말해주는 원본을 알려준다.
대화의 유형
inform - 페르소나 없이 지식만 활용
confirm - 페르소나를 반영하나 범위가 제한되어 있어 깊이 활용되지 않는다.
suggest - 페르소나를 반영하여 사용자에게 불호인 정보를 제공하지 않고, 맞춤형 지식을 제공한다.
위키 디피아 문서에서 과도한 메모리 소비를 피하기 위해 TF-IDF를 활용해 가장 관련성 높은 상위 5개 구절 선택
BERTscore를 통해 얼마나 유사한지 측정
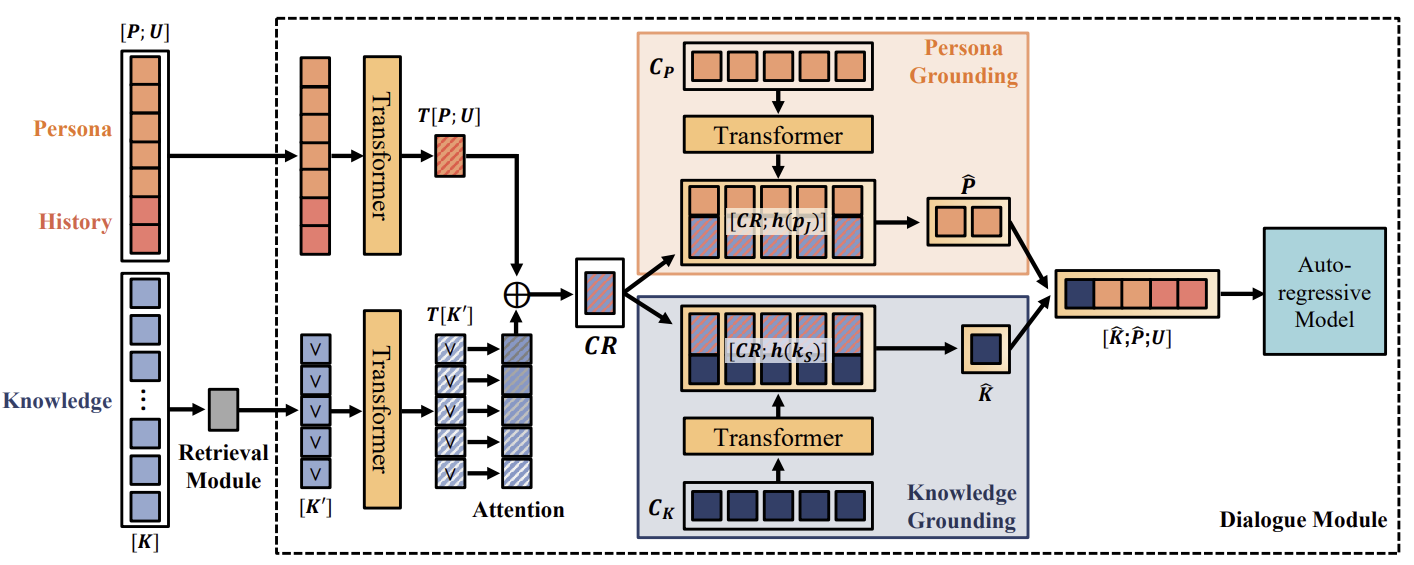
지식 단락을 선택한 후 모델은 지식, 페르소나, 기록과 관련성이 높은 벡터를 생성한다.! -> 이 벡터는 페르소나(Cp- 5개)와 지식(Cr-10개)을 선택하는데 사용 -> 결합되어 언어 모델에 공급
CR은 선택된 지식 K와 페르소나와 기록인 P,U가 각각 transformer를 지나 Bahdanau attention을 통해 업데이트 되고, concat하여 생성된다.
사전 훈련된 모델이 생성 작업에서 높은 성능을 보이지만 그것이 PG,KG가 높은 것은 아니다.
앞으로 위 데이터셋으로 훈련된 모델은 사용자의 페르소나에 따라 전문적인 지식이 필요한 상황에서 개인 비서의 형태로 활용될 수 있습니다. 이 연구가 대화 에이전트를 더 매력적이고 탐구할 기초 능력을 갖춘 지식을 갖춘 것으로 만드는 것을 목표로 해보자.

논문은 "Call for Customized Conversation: Customized Conversation Grounding Persona and Knowledge"라는 제목을 가지고 있으며, 주로 사용자 개인 정보(페르소나)와 특정 주제에 대한 지식을 바탕으로 대화 에이전트가 맞춤형 응답을 생성하는 문제를 다루고 있습니다. 이 논문을 요약하고 Chain-of-Thought 방식으로 분석하겠습니다.
1. 문제 정의
기존의 대화형 에이전트는 사용자에게 제공하는 정보가 일관성이 부족하거나 맞춤형이 아닌 경우가 많습니다. 예를 들어, 사용자가 채식주의자인데도 불구하고 스테이크 하우스를 추천하는 문제가 발생할 수 있습니다. 이 문제의 원인은 대화 에이전트가 사용자 페르소나와 관련 지식을 적절히 결합하여 응답을 생성하지 못하기 때문입니다. 이 논문은 사용자 페르소나와 지식을 적절히 융합하여 맞춤형 답변을 생성하는 대화형 에이전트를 개발하는 것을 목표로 합니다.
2. 방법론
이 논문에서는 사용자 페르소나와 위키피디아 지식을 기반으로 대화 데이터를 생성하고 이를 평가하기 위해 "FoCus"라는 새로운 데이터셋을 제안합니다. 이 데이터셋은 사용자 페르소나와 주제에 대한 지식을 기반으로 맞춤형 대답을 생성하는 것을 목표로 하며, 두 가지 하위 과제를 설정했습니다:
- Persona Grounding (PG): 사용자 페르소나를 반영하는 능력 평가
- Knowledge Grounding (KG): 적절한 지식을 사용하여 응답을 생성하는 능력 평가
3. 사용한 방법
이 논문에서는 대화 에이전트의 성능을 평가하기 위해 사전 훈련된 언어 모델인 BART, GPT-2와 트랜스포머 기반 모델을 활용했습니다. 이 모델들은 다중 과제 학습(Multi-Task Learning) 방식을 사용하여 페르소나와 지식을 기반으로 응답을 생성합니다. 구체적으로:
- Retrieval Module: 사용자 질문과 관련된 위키피디아 지식 문단을 TF-IDF 방식으로 검색합니다.
- Dialog Module: 검색된 지식 문단과 사용자 페르소나, 대화 기록을 바탕으로 응답을 생성합니다.
4. 결과
모델의 성능은 자동화된 평가와 인간 평가를 통해 측정되었습니다. 다음과 같은 결과가 도출되었습니다:
- 언어 생성 성능: GPT-2와 BART 모델이 높은 성능을 보였으며, 특히 지식 기반 응답 생성에서 우수한 결과를 나타냈습니다. 예를 들어, GPT-2 +KG 모델은 가장 높은 BLEU 점수와 ROUGE-L 점수를 기록했습니다.
- Persona Grounding 및 Knowledge Grounding: BART와 GPT-2 모델은 두 가지 하위 과제 모두에서 높은 정확도를 보였으며, 지식과 페르소나를 적절히 결합하여 맞춤형 대화를 생성할 수 있었습니다.
5. 한계점
이 연구는 맞춤형 대화를 생성하는 데 있어 중요한 기여를 했지만, 몇 가지 한계점이 존재합니다. 첫째, 페르소나와 지식을 결합하는 과정에서 특정 페르소나 정보가 과소 사용될 수 있습니다. 둘째, 자동 평가에서 높은 점수를 기록한 모델도 실제 사용자와의 대화에서 완전히 만족스러운 성능을 보이지 않을 수 있습니다. 마지막으로, 이 데이터셋은 특정 주제에 한정되어 있어 다양한 주제에 확장하는 데 한계가 있을 수 있습니다.
6. 계산식
이 논문에서 제시한 주요 계산식은 다음과 같습니다:
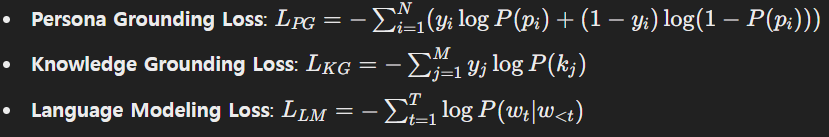
결론
이 연구는 사용자 페르소나와 지식을 결합한 맞춤형 대화 에이전트의 가능성을 제시했으며, 이를 통해 더 인간다운 대화 에이전트를 개발하는 데 기여할 수 있을 것으로 보입니다.
이 논문에서는 Persona Grounding (PG)와 Knowledge Grounding (KG) 성능을 높이기 위해 여러 방법을 사용했습니다. 이 방법들은 대화 모델이 사용자 페르소나와 위키피디아 지식을 적절하게 반영한 맞춤형 응답을 생성할 수 있도록 설계되었습니다. 이를 구체적으로 설명하겠습니다.
1. Persona Grounding (PG)를 높이기 위한 방법
Persona Grounding은 대화 에이전트가 사용자 페르소나(즉, 사용자에 대한 개인적인 정보나 선호도)를 기반으로 맞춤형 응답을 생성하는 능력을 의미합니다. PG 성능을 높이기 위해 논문에서 사용한 주요 방법들은 다음과 같습니다:
- Persona Candidate Selection: 모델은 매 대화 턴마다 여러 개의 페르소나 후보 중에서 적합한 페르소나를 선택하는 작업을 수행합니다. 이 때 모델은 각 페르소나 문장을 특수 토큰을 사용해 구분하고, 선택할 때 해당 페르소나 문장이 현재 대화와 얼마나 연관성이 있는지를 학습합니다.
- Context-Relevant Representation: 모델은 대화의 문맥과 관련된 표현을 생성하여, 이를 바탕으로 적합한 페르소나를 선택합니다. 이 표현은 페르소나 정보와 대화 기록을 결합하여 트랜스포머 모델을 통해 인코딩됩니다. 이후, 이 표현은 페르소나 후보들의 표현과 결합되어, 모델이 가장 적합한 페르소나 문장을 선택하도록 합니다.
- Attention Mechanism: 트랜스포머 구조에서 사용되는 어텐션 메커니즘을 통해 모델은 대화 문맥과 페르소나 정보를 연관시켜, 대화의 흐름에 적합한 페르소나를 강조하는 방식으로 학습됩니다.
- Loss Function (Loss 함수): PG의 손실 함수는 각 페르소나 문장이 정답인지 여부를 판단하는 이진 분류 문제로 모델을 학습시킵니다. 이 때, 정답인 페르소나 문장은 1로 레이블링되고, 그렇지 않은 문장은 0으로 레이블링되어 손실이 계산됩니다.
- 이 때 사용된 손실 함수는 다음과 같습니다:

2. Knowledge Grounding (KG)를 높이기 위한 방법
Knowledge Grounding은 모델이 위키피디아와 같은 외부 지식을 기반으로 적절한 정보를 활용해 응답을 생성하는 능력을 의미합니다. KG 성능을 높이기 위해 논문에서 사용한 주요 방법들은 다음과 같습니다:
- Knowledge Retrieval Module (지식 검색 모듈): 위키피디아에서 주어진 질문과 관련된 지식 문단을 검색하기 위해 TF-IDF 기반의 검색 시스템을 사용합니다. TF-IDF 점수를 사용하여 사용자 질문과 가장 관련성이 높은 5개의 문단을 추출합니다. 이 방법은 빠르고 효율적인 검색이 가능하며, 검색된 문단들은 이후 대화 생성 과정에서 지식 소스로 사용됩니다.
- BERTScore 평가: 지식 검색 모듈의 성능을 평가하기 위해 BERTScore를 사용했습니다. BERTScore는 검색된 문단이 실제로 얼마나 정답에 가까운지를 평가하는 데 사용되었으며, 검색된 문단과 정답 문단 간의 의미적 유사성을 측정합니다. 이 방법을 통해 검색된 지식이 얼마나 정확하고 유용한지를 보장합니다.
- Knowledge Candidate Selection: 모델은 매 턴마다 검색된 지식 문단들 중에서 가장 적합한 문단을 선택하는 작업을 수행합니다. 이 때 지식 후보 역시 특수 토큰으로 구분되어 트랜스포머 구조를 통해 인코딩되며, 모델은 각 문단이 대화 흐름과 얼마나 연관이 있는지 학습합니다.
- Knowledge Grounding Loss Function: KG 손실 함수는 선택된 지식 문단이 정답인지 여부를 학습합니다. 정답 문단은 1로 레이블링되고, 오답 문단은 0으로 레이블링되어 손실이 계산됩니다.
- KG 손실 함수는 다음과 같이 정의됩니다:
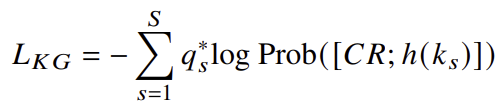
3. Multi-Task Learning (다중 과제 학습)
논문에서는 다중 과제 학습(Multi-Task Learning) 방식을 사용하여 모델이 동시에 페르소나와 지식을 선택하고, 이를 기반으로 응답을 생성하는 능력을 학습하도록 했습니다. 이 방식에서는 PG와 KG 과제를 동시에 학습시켜, 모델이 대화 문맥에서 적절한 페르소나와 지식을 모두 고려하도록 유도합니다. 최종적인 손실 함수는 PG, KG, 그리고 언어 생성(응답 생성)에서 발생하는 손실을 모두 고려하여 다음과 같이 정의됩니다:
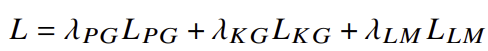
여기서 λ 값들은 각 손실에 대한 가중치를 나타내며, 이들을 조정함으로써 모델이 각 과제에 집중하도록 합니다.
결론
이 논문에서는 사용자 페르소나와 지식을 기반으로 맞춤형 응답을 생성하기 위해 페르소나와 지식의 선택 및 다중 과제 학습을 활용했습니다. 이를 통해 대화 에이전트가 보다 사용자 친화적이고 지식 기반의 응답을 생성할 수 있도록 했으며, 이는 기존 모델의 한계를 극복하는 중요한 성과로 평가됩니다.