https://dl.acm.org/doi/abs/10.1145/3589334.3645477
Scalable and Effective Generative Information Retrieval | Proceedings of the ACM on Web Conference 2024
Hyung Won Chung, Le Hou, S. Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Dasha Valter, Sharan Narang, G
dl.acm.org
아직은 새로운 doc에 대한 검색은 진행할 수 없음
기존에 가지고 있는 doc를 검색하는 수준이다.

논문 요약 및 분석
이 논문은 "Scalable and Effective Generative Information Retrieval"에 대한 연구로, 대규모 정보 검색에 효과적인 생성 기반 정보 검색 모델을 제안합니다. 이 논문은 생성 기반 검색 모델의 성능을 향상시키기 위해 새로운 최적화 프레임워크인 RIPOR(Relevance-based Identifiers for Prefix-Oriented Ranking)을 제안하고 이를 평가했습니다.
1. 문제 정의
기존의 생성 기반 정보 검색 모델은 소규모, 인위적으로 구성된 데이터셋에서만 좋은 성능을 보이며, 대규모 데이터셋에서는 성능이 저하되는 문제가 있었습니다. 이러한 문제는 문서 ID를 생성할 때 발생하는 오류, 특히 생성 과정에서 중간 단계에서의 정보 손실로 인해 발생합니다.
2. 제안된 방법
논문에서 제안된 RIPOR는 다음과 같은 두 가지 주요 개선점을 도입하여 문제를 해결하고자 합니다:
- Prefix-Oriented Ranking Optimization: 문서 ID 생성의 각 단계에서 관련 문서의 순위를 더 정확하게 예측할 수 있도록 최적화하는 방법을 도입했습니다. 이 방법은 문서 ID의 각 부분에 대해 개별적으로 순위를 매기는 과정에서 오류가 발생하지 않도록 하고, 순차적인 문서 ID 생성에서 정확도를 높입니다.
- Relevance-Based Document ID Construction: 문서 ID를 초기화하는 단계에서 단순한 구문적 정보나 의미적 정보를 사용하기보다는, 질의와 문서 사이의 관련성 정보를 반영하도록 새로운 문서 ID 생성 방식을 제안했습니다. 이는 문서와 질의 사이의 관련성을 더 잘 반영하는 문서 ID를 생성하여, 검색 성능을 향상시킵니다.
3. 방법론
- Prefix-Oriented Ranking Optimization: 생성된 문서 ID의 각 단계마다 해당 문서가 관련 문서로서 순위가 높게 유지되도록 최적화합니다. 이를 위해, 모델이 각 프리픽스(prefix)에 대해 문서의 순위를 매기도록 학습시키며, 학습 과정에서 단계별로 모델의 성능을 점진적으로 향상시킵니다.
- Relevance-Based Document ID Construction: 문서 ID를 생성할 때, 문서의 의미적 유사성뿐만 아니라 질의와의 관련성을 반영하여 문서 ID를 초기화합니다. 이 초기화 과정에서는 잔여 양자화(Residual Quantization) 방법을 사용하여 문서 표현을 더 잘 보존하도록 최적화합니다.
4. 결과
RIPOR는 기존의 생성 기반 정보 검색 모델을 크게 능가하는 성능을 보여주었습니다. 예를 들어, MSMARCO 데이터셋에서 MRR(MEAN RECIPROCAL RANK) 측정에서 30.5%의 향상을 이루었으며, TREC Deep Learning Track에서도 높은 성능을 보였습니다. 이러한 성능 향상은 모델이 대규모 데이터셋에서도 효과적으로 작동할 수 있음을 보여줍니다.
5. 한계점
논문에서 제시한 방법은 다양한 대규모 데이터셋에서 좋은 성능을 보였지만, 다음과 같은 한계점이 있습니다:
- 복잡도 및 계산 비용: 제안된 최적화 기법은 기존 모델에 비해 계산 비용이 크며, 특히 대규모 데이터셋을 처리할 때 많은 자원이 요구됩니다.
- 모델의 일반화 능력: 특정 데이터셋에서 좋은 성능을 보였지만, 모든 도메인에서 동일한 성능을 보장하지는 않습니다. 예를 들어, 문서의 길이나 구조가 크게 다른 경우, 성능이 저하될 가능성이 있습니다.
이 논문은 생성 기반 정보 검색 모델의 한계를 극복하고, 대규모 정보 검색 문제를 해결하기 위한 중요한 발전을 이루었다고 평가할 수 있습니다. 제안된 RIPOR 프레임워크는 향후 다양한 검색 및 정보 처리 작업에서 널리 사용될 가능성이 높습니다.
어떻게 구현한겨?
1. Prefix-Oriented Ranking Optimization 구현
Prefix-Oriented Ranking Optimization은 문서 ID 생성의 각 단계에서 관련 문서의 순위를 정확하게 예측하도록 최적화하는 방법입니다. 이를 구현하기 위해 다음과 같은 절차를 따릅니다:
- 문서 ID 생성 단계별 최적화:
- 문서 ID를 생성할 때, 각각의 토큰(문서 ID의 부분)을 순차적으로 생성합니다. 각 토큰은 이전에 생성된 토큰들(프리픽스)을 바탕으로 예측됩니다.
- 예측된 토큰이 관련 문서의 프리픽스 중 하나인지 여부를 판단하기 위해, 토큰이 생성될 때마다 이 프리픽스의 순위가 높은지(즉, 관련성이 있는지)를 확인합니다.
- 순위 손실 함수 적용:
- 각 프리픽스에 대해 점수(예를 들어, 토큰의 로그 확률)를 계산하고, 이를 바탕으로 손실 함수를 정의합니다. 이 손실 함수는 생성된 프리픽스가 관련 문서의 프리픽스보다 높은 순위에 오도록 학습을 유도합니다.
- 구체적으로, 논문에서는 MarginMSE 손실 함수를 확장하여 프리픽스 기반의 순위 최적화를 수행합니다. 이 손실 함수는 프리픽스의 순위를 제어하는 가중치(α)를 사용해 프리픽스의 초기 단계에서의 순위를 더 중요하게 다룹니다.
- 점진적 학습 전략:
- 학습 초기에 짧은 프리픽스에 대해 모델을 학습시키고, 점차 긴 프리픽스로 학습을 확장해 나갑니다. 이를 통해 모델이 간단한 패턴에서 복잡한 패턴으로 학습할 수 있게 합니다.
- 이때, 다중 목표 학습(multi-objective learning)을 사용하여 이전 단계에서 학습한 프리픽스의 순위를 잊지 않도록 합니다. 즉, 각 학습 단계에서 현재 프리픽스뿐만 아니라 이전 단계에서 학습한 프리픽스 순위도 유지하도록 학습을 진행합니다.
2. Relevance-Based Document ID Construction 구현
Relevance-Based Document ID Construction은 문서의 구문적 또는 의미적 유사성뿐만 아니라, 질의와 문서 사이의 관련성을 반영하여 문서 ID를 초기화하는 방법입니다. 이를 구현하기 위한 단계는 다음과 같습니다:
- Dense Encoder로 문서 표현 학습:
- 문서의 내용을 인코더(예: T5 모델의 인코더)에 입력하고, 디코더의 첫 번째 출력을 통해 문서의 벡터 표현을 생성합니다. 이 벡터는 문서의 전체적인 의미를 요약한 것입니다.
- 질의에 대해서도 동일한 방식으로 벡터 표현을 생성하여 문서와 질의 간의 관련성을 학습할 수 있도록 합니다.
- Residual Quantization을 통한 문서 ID 생성:
- 학습된 문서 벡터를 기반으로 Residual Quantization(RQ) 기법을 사용하여 문서 ID를 생성합니다. RQ는 문서 벡터를 여러 개의 부분 벡터로 분해하여, 이 벡터들이 계층적 구조를 반영하도록 합니다.
- 이러한 RQ를 사용하면 문서 간의 유사성을 잘 보존할 수 있고, 문서 ID의 계층적 구조를 만들어 생성된 문서 ID가 검색 과정에서 더욱 효율적으로 사용될 수 있습니다.
- Document ID 초기화 및 학습:
- 생성된 문서 ID는 초기화된 후, 이를 바탕으로 생성 모델을 학습시킵니다. 이 단계에서 모델은 각 문서에 대한 고유한 ID를 생성하고, 이러한 ID가 질의와 관련된 문서의 순위를 잘 반영할 수 있도록 최적화됩니다.
- 이후, 이 초기화된 문서 ID를 사용하여 seq2seq 사전 학습을 진행합니다. 여기서 문서와 관련된 pseudo-query를 생성하여 문서 ID를 예측하는 방식으로 모델을 학습시킵니다.
종합 구현 전략
위의 두 방법을 결합하여 RIPOR 프레임워크를 구현할 수 있습니다. 이 프레임워크는 다음의 순서로 모델을 학습합니다:
- 문서의 벡터 표현을 학습하고, 이를 기반으로 Residual Quantization을 사용해 문서 ID를 생성합니다.
- 생성된 문서 ID를 기반으로 모델을 초기화하고, seq2seq 사전 학습을 통해 모델이 전체 코퍼스를 잘 이해하도록 합니다.
- 최종적으로, 프리픽스 기반의 순위 최적화를 적용하여 문서 ID 생성의 각 단계에서 관련 문서의 순위가 정확하게 유지되도록 모델을 미세 조정합니다.
이러한 구현 방식은 대규모 데이터셋에서 효율적이고 확장 가능한 정보 검색 모델을 개발할 수 있는 강력한 방법론을 제공합니다.
초록
최근 연구에 따르면 트랜스포머 네트워크를 사용하여 각 문서를 문서 ID 토큰의 시퀀스로 표현함으로써 이를 미분 가능한 검색 인덱스로 활용할 수 있다는 것이 밝혀졌습니다. 이러한 생성 기반 검색 모델은 질의에 대해 문서 ID를 생성하는 문제로 검색 문제를 전환합니다. 그러나 이러한 우아한 설계에도 불구하고, 기존의 생성 기반 검색 모델은 인위적으로 구성된 소규모 데이터셋에서만 좋은 성능을 보입니다. 이 논문은 생성 기반 검색 연구에서 중요한 이정표를 제시하며, 생성 기반 검색 모델이 대규모 표준 검색 벤치마크에서도 효과적으로 학습될 수 있음을 보여줍니다. 보다 구체적으로, 우리는 두 가지 자주 간과되는 기본 설계 고려 사항을 바탕으로 설계된 생성 기반 검색을 위한 최적화 프레임워크인 RIPOR를 제안합니다. 첫째, RIPOR는 순차적인 문서 ID 생성 중 관련성 점수를 정확하게 추정하기 위해 새로운 프리픽스 지향 순위 최적화 알고리즘을 도입합니다. 둘째, RIPOR는 질의와 문서 간의 관련성 연관성을 바탕으로 문서 ID를 생성합니다. MSMARCO 및 TREC Deep Learning Track에서의 평가 결과, RIPOR는 최첨단 생성 기반 검색 모델을 큰 폭으로 능가하는 성능을 보였습니다(예: MS MARCO 개발 세트에서 30.5% MRR 향상).
1. 서론
사전 학습된 기초 모델들은 희소 검색을 위해 질의와 문서 내 용어의 가중치를 재조정하는 모델 [17, 18], 크로스 인코더 재순위화 모델 [41], 이중 인코더 검색 모델 [27, 62, 66, 67] 등 다양한 검색 모델의 개발에 활용되었습니다. 최근 Tay 등 [55]은 사전 학습된 인코더-디코더 모델을 미분 가능한 검색 인덱스(DSI)로 활용하는 우아하고 혁신적인 정보 검색(IR) 방법을 제안했습니다. 이는 지난 1년 동안 NCI [59], DSI-QG [71], DSI++ [39]와 같은 몇몇 생성 기반 검색 모델의 개발로 이어졌습니다. 이들 모델에서는 각 문서 ID가 특수한 문서 ID 토큰의 고유한 시퀀스로 표현되며, 주어진 질의에 대해 제한된 빔 검색 알고리즘 [5]을 사용하여 종종 자율적으로 생성됩니다.
생성 기반 검색의 기존 검색 모델에 대한 뚜렷한 이점은 모델의 파라미터 내에 컬렉션 정보를 캡슐화하여 외부 메모리에 기반한 검색의 필요성을 없앤다는 점입니다. 이 설계는 엔드 투 엔드 학습을 촉진하여 검색에서 이점을 얻는 다양한 작업(예: 오픈 도메인 질의 응답, 사실 확인, 대화형 검색)에서 기존 기초 모델(예: GPT-4) 워크플로와 원활하게 통합할 수 있게 합니다 [21, 56]. 그러나 이론적 매력에도 불구하고, 이전 연구는 생성 기반 검색 모델이 소규모(그리고 종종 인위적으로 구성된) 문서 컬렉션에서만 경험적 성공을 입증할 수 있었습니다. 예를 들어, 간단한 용어 매칭 모델인 BM25는 MSMARCO에서 DSI [55]보다 300% 더 높은 MRR을 달성했으며, 질의 생성 [59, 71]을 통한 데이터 증강 후 이 격차는 76%로 줄어듭니다. 이러한 관찰 결과, 최근 연구 커뮤니티에서는 생성 기반 검색 모델의 실제 세계에서의 영향력에 대해 심각한 회의론이 제기되었습니다 [45].
우리는 생성 기반 검색 모델의 성능이 저조한 이유가 두 가지 자주 간과되는 설계 고려 사항에 있다고 주장합니다. 첫 번째는 문서 ID 디코딩 중에 사용되는 빔 검색 알고리즘의 순차적 특성과 관련이 있습니다. 주어진 질의에 대해, 빔 검색 [54]은 이미 디코딩된 토큰(즉, 문서 ID의 프리픽스)의 누적 점수를 기반으로 각 디코딩 단계에서 상위 𝑘 후보 목록을 유지합니다. 관련 문서의 문서 ID를 성공적으로 생성하려면, 관련 문서의 모든 문서 ID 프리픽스가 빔 검색 디코딩에서 상위 𝑘 후보 목록에 포함되어야 합니다. 이 중요한 측면은 기존 생성 기반 검색 모델에서 고려되지 않았습니다. 이 문제를 해결하기 위해 우리는 프리픽스 지향 순위 최적화 방법을 제안하고, 모델이 관련 문서 ID의 각 프리픽스에 대해 비관련 문서 ID에 비해 더 높은 관련성 점수를 생성하도록 유도하는 새로운 마진 기반 쌍별 손실 함수를 도입합니다. 이 방법은 또한 점진적 학습을 포함하여 모델의 예측을 가장 짧은 프리픽스에서 전체 길이의 문서 ID로 점진적으로 개선합니다. 다중 목표 점진적 학습이 적용되어 모델이 문서 ID 프리픽스에 집중하는 것을 잊지 않도록 합니다.
두 번째로, 기존 방법은 초기 문서 ID를 구성할 때 관련성 정보를 고려하지 않습니다. 대신에 문서 내 구문적 및 의미적 정보를 사용하여 사전 학습된 BERT [16] 또는 sentence-T5 [40]로 초기 문서 ID를 계층적 클러스터링 [55, 59], n-grams [3], 또는 근사 방법 [48, 69]을 사용하여 구성합니다. 그러나 관련성 기반 단어 임베딩 [63]에 의해 입증된 바와 같이, 관련성 정보는 구문적, 의미적, 근접성 기반 목표로 학습된 모델로는 단순히 캡처될 수 없습니다. 생성 기반 검색 모델이 고정된 문서 ID로 최적화를 수행하기 때문에 부적절한 초기 문서 ID 구성은 생성 기반 검색 모델의 효과성에 본질적인 영향을 미치는 병목 현상을 유발합니다. 우리는 이 문제를 해결하기 위해 초기 문서 ID 구성을 위한 새로운 사전 학습 단계를 제시합니다. 여기에서 우리는 인코더-디코더 생성 검색 모델을 타겟 작업에 대해 학습된 관련성 기반 목표를 가진 특별한 밀집 검색 모델로 변환합니다. 학습된 문서 표현은 그 후 잔여 양자화(RQ) [1, 10]를 사용하여 여러 벡터로 분해되며, 이는 관련성 기반 표현의 성공적인 근사로 입증되었습니다.
우리는 MSMARCO [4]와 TREC 2019-20 Deep Learning Track 데이터 [14, 15]를 포함한 표준 대규모 정보 검색 벤치마크에서 실험을 수행했으며, 검색 컬렉션은 880만 개의 구절로 구성되어 있습니다. 우리의 접근 방식은 모든 설정에서 최첨단 생성 기반 검색 모델에 비해 상당한 개선을 달성합니다. 예를 들어, 우리의 RIPOR 프레임워크는 MSMARCO에서 MRR@10 측면에서 최고 성능을 보이는 생성 기반 검색 모델보다 30.5% 더 높은 성능을 보였습니다. 대부분의 설정에서, 우리의 모델은 DPR [27], ANCE [62], MarginMSE [22], TAS-B [23]와 같은 인기 있는 밀집 검색 모델보다도 더 나은 성능을 보여줍니다. 따라서 이 논문은 생성 기반 검색 모델이 대규모에서 효과적으로 작동할 수 있음을 보여주며, 이를 실제 응용 프로그램에 구현할 수 있는 길을 열어주는 중요한 이정표를 설정합니다. 이 분야의 연구를 촉진하기 위해, 우리는 우리의 구현을 오픈소스화하고 학습된 모델 파라미터를 공개합니다.
2. 생성 기반 정보 검색 소개
생성 기반 문서 검색에서 각 문서는 문서 ID 또는 간단히 DocID로 알려진 고유 식별자로 상징화됩니다. T5 [47]와 같은 사전 학습된 인코더-디코더 모델이 주어진 질의에 대해 문서 ID 목록을 생성하는 데 사용됩니다. 생성 검색 모델을 𝑀라고 하고, 문서 𝑑를 길이 𝐿의 문서 ID 𝑐𝑑 = [𝑐𝑑1, 𝑐𝑑2, ... , 𝑐𝑑𝐿]로 나타낸다고 합시다. 다양한 방법이 DocID를 구성하는 데 사용됩니다 [3, 55, 69]. 예를 들어, DSI [55]는 사전 학습된 BERT 모델 [16]에서 얻은 문서 임베딩을 사용하여 계층적 k-평균을 적용합니다. 트리가 구축되면 각 루트에서 리프까지의 경로가 고유한 문서 ID로 사용됩니다.
그림 1에서 볼 수 있듯이, 𝑀은 주어진 질의 𝑞에 대해 문서 ID를 자율적으로 생성하도록 학습되며, 이는 이전에 생성된 토큰들(𝑐𝑑<𝑖) 조건에 따라 각 DocID 토큰 𝑐𝑑𝑖를 생성함을 의미합니다. 따라서 모델은 다음과 같은 방식으로 𝑖번째 DocID 토큰에 대한 조건부 숨김 표현을 생성합니다:
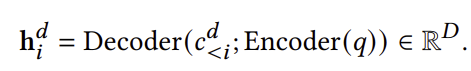
여기서 𝑐𝑑<𝑖 = [𝑐𝑑1, 𝑐𝑑2, ... , 𝑐𝑑𝑖−1]는 디코더의 입력으로 제공되며, 인코딩된 질의 벡터는 디코더에 대한 크로스 어텐션을 계산하는 데 사용됩니다. 생성 검색에서 각 DocID 토큰은 𝐷 차원의 표현과 연결됩니다. 𝐷를 DocID 토큰에 대한 고유 토큰 수, 즉 문서 ID를 나타내는 고유 토큰 수로 하여, 각 위치 𝑖에 대해 토큰 임베딩 테이블 E𝑖 ∈ R𝑉 ×𝐷이 존재한다고 합시다. 따라서 각 DocID 토큰 𝑐𝑑𝑖와 관련된 표현은 E𝑖 [𝑐𝑑𝑖] ∈ R𝐷로 나타냅니다. DocID 토큰 임베딩 행렬은 서로 다르므로,
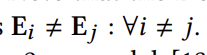
입니다.
seq2seq 모델 [13, 43, 47]에서 영감을 받아, 기존 생성 검색 모델은 다음과 같이 로그 조건부 확률에 기반하여 관련성 점수를 추정합니다:
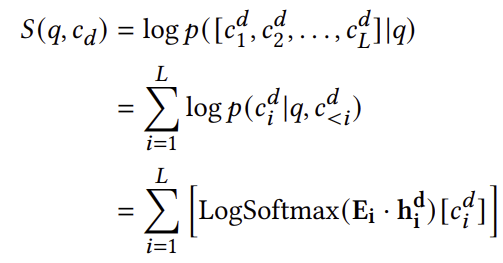
여기서 𝑆(𝑞, 𝑐𝑑)는 질의-문서 쌍에 대한 점수 함수입니다. 이 논문에서는 계산 비용이 적고, 마진 기반 쌍별 손실과 더 잘 일치하기 때문에 조건부 로짓 접근 방식을 채택합니다. 이 접근 방식은 질의와 문서 표현 사이의 내적 유사성을 사용하는 밀집 검색 모델에서 영감을 받아, DocID에 해당하는 토큰 임베딩 벡터와 질의 및 이전 디코딩에서 학습된 숨겨진 벡터 간의 내적 유사성을 계산합니다. 이를 더 구체적으로 설명하면, 이 접근 방식은 다음과 같이 공식화할 수 있습니다:
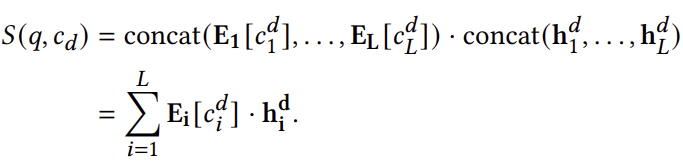
이러한 점수 함수를 사용하여 생성 검색 모델은 제한된 디코딩과 함께 빔 검색을 통해 문서의 순위 목록을 생성합니다 [5]. 여기서 상위 𝐾개의 유효한 DocID가 점수 함수에 따라 생성됩니다. 각 DocID는 원래 문서로 매핑됩니다. 결과적으로 𝐾개의 문서가 순위 목록으로 생성됩니다.
3. 방법론
이 논문에서는 문서 ID 구성 및 프리픽스 지향 순위 최적화를 위한 범용 프레임워크인 RIPOR를 제안합니다. 이 프레임워크는 어떤 인코더-디코더 아키텍처에도 적용 가능하며, 생성 기반 검색 모델의 성능을 향상시킵니다. RIPOR 프레임워크의 개요는 그림 2에 설명되어 있습니다. 처음에 생성 모델 𝑀은 밀집 인코더로 간주되며, 관련성 기반 목표로 미세 조정됩니다. 학습이 완료된 후, RIPOR는 잔여 양자화(RQ) [10]를 사용하여 각 문서에 대한 고유 식별자를 도출합니다. 이후 Pradeep 등 [45], Wang 등 [59], Zhuang 등 [71]을 따라, 문서에서 생성된 가상 질의를 사용하여 모델을 사전 학습하는 seq2seq 사전 학습 접근 방식을 활용합니다. 다음으로, 모델 𝑀의 파라미터를 정제하기 위한 새로운 순위 지향 미세 조정 절차를 도입합니다. 다음 두 섹션에서는 RIPOR의 두 가지 주요 구성 요소인 프리픽스 지향 순위 최적화와 관련성 기반 문서 ID 구성의 동기와 방법론에 대해 설명합니다. 전체 최적화 파이프라인에 대한 자세한 설명은 3.3절에 제시되어 있습니다.
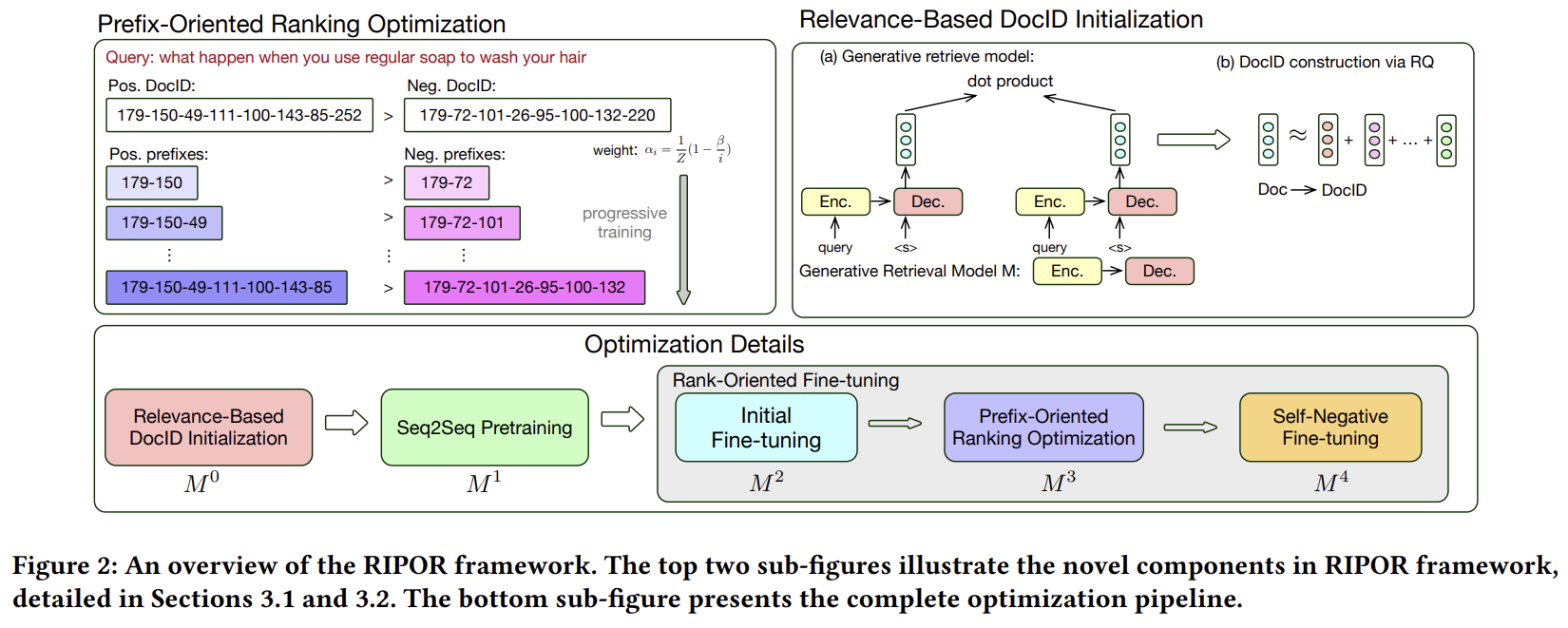
3.1 프리픽스 지향 순위 최적화
최신 생성 기반 검색 모델들, 예를 들어 LTRGR [31]와 같은 모델들은 최적화를 위해 학습-대-순위 손실을 채택합니다. 이 모델의 목표는 질의 𝑞, 관련 문서 𝑑+ 및 비관련 문서 𝑑−로 구성된 학습 삼중항(triplet)에 대해 𝑆(𝑞, 𝑐𝑑+) > 𝑆(𝑞, 𝑐𝑑−)을 보장하는 것입니다. 우리는 이 모델링이 최적이 아니라고 가정합니다. 주요한 간과는 빔 검색의 본질적 특성, 즉 문서 ID 토큰을 왼쪽에서 오른쪽으로 순차적으로 디코딩하는 과정에서 발생합니다. 전체 길이의 문서 ID에 대한 쌍별 순위에만 집중하는 것은 관련 문서가 초기 디코딩 단계에서 빔 검색의 제거 과정을 통과할 수 있음을 보장하지 못합니다. 따라서 우리는 각 디코딩 단계에서 정확한 점수를 생성하는 모델을 개발하는 것을 목표로 합니다. 형식적으로, 우리는 다음 기준을 만족하기를 원합니다: 𝑆𝑖prefix(𝑞, 𝑐𝑑+) ≥ 𝑆𝑖prefix(𝑞, 𝑐𝑑−), ∀𝑖 ∈ [1, 𝐿], 여기서 𝑆𝑖prefix(𝑞, 𝑑)는 문서 ID의 처음 𝑖개의 토큰에 대해 생성 기반 검색 모델이 생성한 관련성 점수를 나타냅니다: [𝑐𝑑1, 𝑐𝑑2, ... , 𝑐𝑑𝑖].
마진 분해 쌍별 손실: MarginMSE [22]에서 영감을 받아, 지식 증류를 위한 쌍별 손실을 다음과 같이 정의합니다:
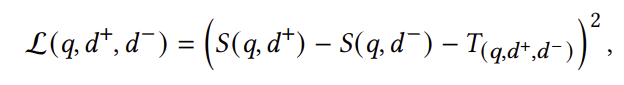
여기서 𝑇(𝑞,𝑑+,𝑑−)는 일반적으로 크로스 인코더 [41]에서 유도된 교사 모델이 예측한 골든 마진을 나타냅니다. 이전 연구 [22, 66]에 따르면 이 손실 함수는 대규모 검색 벤치마크에서 데이터 희소성 문제를 해결하고, 라벨이 없는 질의-문서 쌍에 대한 가상 라벨을 활용하여 다른 쌍별 손실 함수들 [62]보다 자주 우수한 성능을 보인다고 합니다.
생성 검색의 경우, 우리는 각 디코딩 단계 𝑖에서 𝑐𝑑+와 𝑐𝑑−의 프리픽스 간 쌍별 순위를 모델링하여 MarginMSE 손실을 확장합니다:
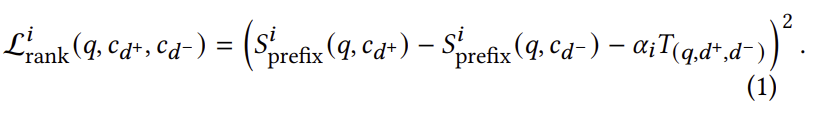
여기서 각 단계 𝑖에서 우리는 𝛼𝑖를 곱하여 골든 마진을 재가중합니다. 이 결정의 이유는 문서 ID의 초기 디코딩 단계에 중점을 두기 때문입니다. 이 동기를 바탕으로, 𝛼𝑖는 𝑖에 대해 단조 증가 오목 함수여야 합니다. 형식적으로, 𝛼𝑖 값은 다음 제약을 만족해야 합니다: 𝛼𝑖 − 𝛼𝑖−1 ≥ 𝛼𝑖+1 − 𝛼𝑖 모든 𝑖에 대해. 우리의 실험에서, 우리는
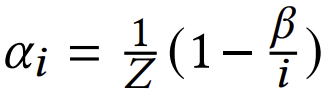
를 사용하며, 여기서 𝑍는 1−𝛽/𝐿로 정의된 정규화 인자이며, 𝛽는 상수 하이퍼파라미터입니다. 다른 오목 함수들에 대한 탐색은 향후 연구로 남겨두겠습니다. 효율성을 위해, 우리는 𝑖 = 4, 8, 16, 32에 대해서만 프리픽스 지향 최적화를 수행하며, 따라서 𝛽를 2로 설정합니다. 이 𝛼𝑖의 오목 공식은 초기 단계에서 더 큰 서브 마진을 강조하여, 어떤 질의 𝑞에서도 𝑆𝑖prefix(𝑞, 𝑐𝑑+)가 𝑆𝑖prefix(𝑞, 𝑐𝑑−)를 초과하도록 보장합니다. 또한, 𝛼𝐿 = 1이기 때문에, 전체 길이의 DocID 시퀀스에 대한 예측된 마진은 실제 마진과 일치하여 순위 지식의 충실성을 유지합니다.
점진적 학습: 빔 검색의 좌에서 우로 진행되는 디코딩 특성에 맞춘 표현을 더 잘 학습하기 위해, 우리는 커리큘럼 학습 [2, 36, 38, 66]에서 영감을 받아 점진적 학습 전략을 구현합니다. 학습 과정은 가장 짧은 프리픽스로 시작됩니다. 이를 통해 모델이 기본적인 시퀀스 표현에 집중하고, 이후 단계에 필요한 충분한 역량을 구축할 수 있습니다. 학습이 진행됨에 따라 범위는 더 긴 프리픽스로 체계적으로 확장되어, 최종적으로 전체 길이의 시퀀스(길이 𝐿)에서 학습이 이루어집니다.
더 긴 프리픽스에서 학습하는 동안, 모델이 이전에 획득한 짧은 프리픽스와 관련된 지식을 간과하는 경향이 있음을 실험적으로 발견했습니다. 이러한 치명적인 망각 문제를 완화하기 위해, 우리는 각 시간 단계에서 다중 목표 학습을 적용하여 이전 단계에서 획득한 지식을 유지하도록 합니다. 주어진 학습 데이터

에서, 우리는 다음의 다중 목표 손실 함수를 사용합니다:

이 손실 함수에서, 항목 (1)은 현재 단계 𝑖에 특화된 쌍별 순위를 획득하는 역할을 하며, 항목 (2)는 모델이 이전 프리픽스에서의 순위 지식을 유지하도록 보장합니다. 앞서 언급한 대로, 효율성을 위해 𝑖 = 4, 8, 16, 32에 대해서만 이 학습 과정을 반복합니다.
3.2 관련성 기반 DocID 생성
생성 기반 검색 모델은 주로 두 단계 최적화 접근 방식을 채택합니다. 먼저, 계층적 k-평균 [55, 59] 또는 문서에서 추출한 판별적 텍스트 설명 [3, 31, 32]과 같은 다양한 방법을 사용하여 문서 ID를 초기화합니다. 이후 단계에서는 첫 번째 단계에서 얻은 고정된 DocID를 활용하여 크로스 엔트로피 손실 [3, 55] 또는 학습-대-순위 손실 [31]로 모델을 최적화합니다. 이 단계에서 DocID는 변경되지 않기 때문에, 이는 생성 기반 검색 모델의 전체적인 효율성에 큰 병목으로 작용할 수 있습니다.
우리는 DocID 설계가 두 가지 특정 방식에서 중요하다고 주장합니다: 첫째, 내재된 유사성을 가진 문서들이 그에 상응하는 유사한 DocID를 가져야 합니다. 둘째, 생성 검색에서 디코딩을 위한 빔 검색의 특성으로 인해, 이러한 DocID는 계층적 구조를 포함해야 합니다. 특히, 이 문맥에서의 유사성 개념은 미묘하며, 이는 특정 질의와 연결되어 있으며 자연어 처리에서 관찰되는 표준 언어적 유사성과는 다릅니다. 이러한 도전 과제에 대응하기 위해, 우리는 DocID 초기화를 위한 관련성 기반 방법을 소개합니다. 이 접근 방식은 질의-문서 관련성의 미묘함과 필수적인 계층적 구조를 모두 캡슐화하도록 설계되어, 생성 검색 작업에서 효과적인 성능을 보장합니다.
밀집 인코더로서의 생성 검색 모델: 문서 간의 관련성 기반 유사성을 포착하기 위해, 우리는 𝑀의 인코더-디코더 아키텍처를 활용하여 밀집 검색 모델에서 영감을 얻은 최적화 프로세스를 설계했습니다. 구체적으로, 문서 내용을 인코더에 입력하고, 특수 시작 토큰을 디코더에 입력으로 사용합니다. 그런 다음 문서 표현은 디코더의 첫 번째 맥락화된 출력 임베딩에서 도출됩니다:
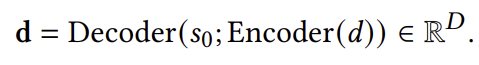
여기서 𝑠0는 시작 토큰입니다. 질의에 대해서도 유사한 접근 방식을 채택하여 그 표현을 결정합니다. 모델 𝑀을 최적화하기 위해, 우리는 3.3.1절에서 소개된 다단계 음성 샘플링을 활용한 MarginMSE 손실 [22]을 사용합니다.
잔여 양자화(Residual Quantization): [45, 55, 59, 71]에서 문서 ID 생성에 사용된 계층적 k-평균은 원래 표현과 근사된 표현 간의 왜곡 오류를 명시적으로 최소화하지 않습니다. Ge 등 [20]에 의해 강조된 바와 같이, 대규모 데이터셋에서는 정보 검색 메트릭(MAP)과 왜곡 오류 간에 주목할 만한 반비례 관계가 있습니다. 이러한 관찰에 영감을 받아, 우리는 왜곡 오류를 명시적으로 최소화하도록 설계된 양자화 기반 기법들 [1, 10, 20, 58]을 채택합니다. 수많은 양자화 알고리즘 중에서, 우리는 Residual Quantization (RQ) [1, 10]을 선택했습니다. 그 이유는 다음과 같습니다: (1) RQ의 재귀 절차는 생성 검색에 내재된 빔 검색 전략과 일치하는 계층적 문서 구조를 캡슐화하며, (2) 제품 양자화(PQ) [20, 58]와 같은 방법에 비해, 더 짧은 길이의 DocID로도 강력한 성능을 달성할 수 있어 추론 시 메모리와 시간을 절약할 수 있습니다. 𝑀을 밀집 인코더로 사용하여 각 문서 𝑑에 대한 표현 𝑑를 계산합니다. 이후, RQ를 사용하여 토큰 임베딩 테이블 {E𝑖}𝐿𝑖=1을 최적화하여 각 문서 𝑑에 대해 최적의 DocID 𝑐𝑑 = [𝑐𝑑1, ... , 𝑐𝑑𝐿]를 결정합니다. 최적화 후, 각 𝑑는 다음과 같이 토큰 임베딩의 시퀀스를 사용하여 근사될 수 있습니다:

훈련된 모델 𝑀과 임베딩 테이블 {E𝑖}𝐿𝑖=1은 생성 검색 내에서 후속 최적화 단계의 초기 가중치로 사용됩니다.
3.3 최적화 세부 사항
우리의 최적화 과정은 세 가지 뚜렷한 단계로 구성됩니다: (1) DocID 초기화 (2) seq2seq 사전 학습, (3) 순위 지향 미세 조정.
3.3.1 DocID 초기화: 3.2절에서 설명한 대로, 우리는 𝑀을 밀집 인코더로 취급합니다. 밀집 인코더 𝑀을 최적화하기 위해, 우리는 최근 발전한 다단계 학습 전략 [62]을 사용합니다. 다단계 학습의 구체적인 단계는 다음과 같습니다:
초기 단계에서는 BM25 [51]를 사용하여 각 질의에 대해 상위 𝐾(우리의 작업에서는 𝐾 = 100을 선택)개의 문서를 샘플링하고, MarginMSE [22] 손실 함수를 사용하여 모델을 학습시킵니다. 모델이 학습된 후, 우리는 모델 𝑀에서 각 문서에 대한 밀집 표현 𝑑를 얻습니다. 각 질의 𝑞에 대해, 우리는 최근접 이웃 검색을 적용하여 상위 𝐾개의 문서를 검색합니다. 그런 다음, 검색된 문서들로 동일한 손실 함수를 사용하여 모델을 학습시킵니다. 학습 후, 우리는 잔여 양자화(RQ)를 적용하여 각 문서에 대한 DocID를 얻습니다. 이 훈련된 모델을 𝑀0로 표시하며, 임베딩 테이블 {E𝑖}𝐿𝑖=1은 다음 단계의 초기 가중치로 사용됩니다.
3.3.2 Seq2seq 사전 학습: 우리의 모델 𝑀이 코퍼스를 포괄적으로 이해할 수 있도록 하기 위해, 우리는 seq2seq 사전 학습 단계를 포함시킵니다. 문서 𝑑을 입력으로 사용하고 해당 의미적 토큰 [𝑐𝑑1, ... , 𝑐𝑑𝐿]을 예측하는 대신, 우리는 이전 연구 [59]에 따라 각 문서와 관련된 가상 질의를 DocID 예측의 입력 대리자로 사용합니다. 구체적으로, doc2query 모델 [11]을 활용하여 각 문서에 대해 𝑁𝑝𝑠𝑒𝑢𝑑𝑜 가상 질의를 생성합니다. 그런 다음 관련 DocID의 토큰을 정답 라벨로 사용하여 교차 엔트로피 손실을 통해 모델을 최적화합니다. 이 단계에서 학습된 모델은 𝑀1로 표시됩니다.
3.3.3 순위 지향 미세 조정: 우리의 모델을 최적화하기 위해, 우리는 3.1절에서 설명한 쌍별 손실을 활용합니다. 문헌에 따르면, 음성 샘플링 [62]과 감독 신호의 품질 [22, 23, 66]이 순위 모델의 성능을 향상시키는 데 중요한 역할을 합니다. 이를 바탕으로, 우리는 모델의 역량을 점진적으로 향상시키고, 후속 단계에서 개선된 음성을 추출하기 위해 다단계 학습 전략 [62, 67]을 통합합니다.
초기 미세 조정: 이 단계는 생성 기반 검색 모델을 워밍업하고 이후 단계에 고품질 음성 샘플을 제공하는 것을 목표로 합니다. 우리는 3.3.1절에서 설명한 모델 𝑀0를 밀집 인코더로 사용하여, 각 문서를 임베딩된 표현을 통해 인덱싱하고 각 질의에 대해 100개의 문서를 검색합니다. 3.3.1절에서 초기화된 DocID를 사용하여 각 검색된 문서를 해당 DocID에 매핑합니다. 음성 샘플과 정답 질의-DocID 긍정 쌍을 기반으로 학습 데이터 D𝑅을 구성할 수 있습니다. 후속 단계에서는 다르게 접근하지만, 여기에서는 Eq 1에서 정의된 전체 시퀀스 L𝐿𝑟𝑎𝑛𝑘를 사용합니다. 초기 모델 𝑀1로부터 시작하여, 학습 후 모델은 𝑀2로 표시됩니다.
프리픽스 지향 순위 최적화: 질의 𝑞에 대해, 우리는 모델 𝑀2에서 제한된 빔 검색을 적용하여 100개의 DocID를 검색하며, 각각은 해당 문서로 다시 매핑됩니다. 이 문서들은 추가된 음성 샘플의 소스로 사용되며, 우리는 이전 단계와 유사한 방식으로 학습 세트 D𝐵를 구성합니다. 이 단계의 종합적인 학습 세트는 최근접 이웃 검색과 빔 검색 모두에서 데이터를 통합하여 D = D𝑅 ∪ D𝐵로 표시됩니다. 모델을 최적화하기 위해, 우리는 3.1절에서 설명된 점진적 학습을 활용합니다. 각 최적화 단계 𝑖에 대해, 우리는 3.1절에서 설명된 다중 목표 손실 함수를 사용합니다. 이 섹션에서 훈련된 모델은 𝑀3로 표시됩니다.
자체 음성 미세 조정: 모델의 효과성을 높이기 위해, 우리는 𝑀3에서 제한된 빔 검색을 사용하여 학습 데이터 세트 D𝐵𝑠𝑒𝑙𝑓를 설정합니다. 훈련은 전체 길이 설정(𝑖 = 𝐿)에서 동일한 다중 목표 손실 함수로 진행되며, 𝑀4로 표시됩니다.
4 실험
4.1 실험 설정
4.1.1 데이터셋: 우리는 8.8M개의 구절과 불완전한 주석(질의당 평균 약 1.1개의 관련 구절)을 가진 532K개의 훈련 질의로 구성된 MSMARCO 데이터셋 [4]에서 우리의 검색 모델을 평가합니다. 세 가지 데이터셋을 사용하여 모델을 평가합니다: (1) 7K개의 질의와 불완전한 주석이 포함된 MSMARCO-Dev, (2, 3) TREC DL 2019 & 2020: 각각 43개와 54개의 질의가 포함된 TREC 딥러닝 트랙의 첫 번째와 두 번째 반복에서 사용된 구절 검색 데이터셋 [14, 15]. 평가를 위해 모든 데이터셋에 대해 recall@10을 보고하며, 각 데이터셋에 대한 공식 메트릭도 보고합니다: MSMARCO-Dev의 MRR@10과 TREC DL 2019 및 2020의 NDCG@10.
4.1.2 구현 세부 사항: 우리는 사전 학습된 T5-base 모델 [47]을 생성 검색 모델의 백본으로 사용합니다. DocID 초기화를 위해 Faiss [26]의 잔여 양자화(RQ) 구현을 채택했습니다. DocID의 길이 𝐿은 32이며, 어휘 크기 𝑉는 256입니다. 반복된 DocID가 발생할 가능성이 매우 낮다는 것을 발견했기 때문에 [48]에서와 같은 추가 코드를 추가하지 않았습니다. DocID 반복에 대한 분석은 부록 B에 나와 있습니다. seq2seq 사전 학습을 위해, T5-large doc2query 모델 [11]이 각 문서에 대해 10개의 가상 질의를 생성합니다. 우리는 [11]에 언급된 대로 교차 엔트로피 손실을 사용하여 MSMARCO 훈련 세트에서 먼저 doc2query 모델을 학습합니다. 최적화는 Adam 옵티마이저 [28]를 사용하여 선형 스케줄링과 총 학습 단계의 4.5%에 해당하는 워밍업 비율로 수행됩니다. DocID 초기화 및 순위 지향 미세 조정 단계에서는 학습 속도를 0.0001로 설정하고, 120 에포크와 배치 크기 64로 설정합니다. seq2seq 사전 학습에서는 학습 속도를 0.001로 설정하고, 250,000단계와 배치 크기 256으로 설정합니다. 모든 실험은 8개의 40GB A100 GPU를 사용하여 수행되었습니다. 추론을 위한 빔 크기는 1000입니다. 전체 최적화 과정의 학습 시간은 부록 C에 보고됩니다.
4.1.3 비교 기준: 우리는 DSI [55], DSI-QG [71], Ultron-PQ [69], NCI-QG [59], SEAL [3], [32], LTRGR [31]와 같은 최첨단 생성 검색 모델을 비교 기준으로 사용합니다. 또한 BM25 [51], DPR [27], ANCE [62], MarginMSE [22], TAS-B [23]와 같은 경쟁력 있는 희소 및 밀집 검색 모델도 참조로 선택했습니다.
4.2 실험 결과
4.2.1 주요 결과: 우리는 표에 RIPOR와 비교 기준의 성능을 보고합니다. 첫째, DSI, DSI-QG, NCI-QG, SEAL, MINDER를 포함한 대부분의 생성 검색 모델은 세 가지 평가 세트 전반에서 BM25보다 일관되게 뒤처집니다. 반면에, 학습-대-순위 알고리즘을 통합한 LTRGR 모델은 BM25를 능가합니다. 이러한 관찰은 생성 검색 모델을 설계할 때 학습-대-순위 방법론을 통합하는 것이 중요함을 강조합니다. 둘째, RIPOR는 모든 생성 검색 비교 기준을 일관되게 능가하며, 상당한 이점을 보여줍니다. 특히, 상위 성능을 보이는 비교 기준인 LTRGR과 비교했을 때, RIPOR는 MSMARCO Dev 세트에서 MRR@10에서 30.5%, TREC-20 테스트 세트에서 NDCG@10에서 94%의 향상을 달성했습니다. 셋째, 우리 RIPOR는 밀집 검색 모델과 비교 가능한 결과를 얻을 수 있습니다. 예를 들어, ANCE와 비교했을 때, 우리 모델은 MSMARCO Dev에서 MRR@10 기준으로 16% 향상, TREC DL 19 및 20에서 각각 NDCG@10 기준으로 4.7% 및 7.5% 향상을 달성했습니다.
4.2.2 절삭 연구: 우리는 RIPOR의 각 구성 요소가 미치는 영향을 조사하기 위해 MSMARCO 데이터셋에서 철저한 절삭 연구를 수행했습니다. 결과는 표 2에 보고됩니다.
첫 번째 행에서 프리픽스 지향 순위 최적화를 통합하는 것이 중요함을 알 수 있습니다. 이 최적화가 없으면 MRR@10에서 19%의 성능 저하가 발생합니다. 이 접근 방식을 사용하지 않으면, 모델은 질의에 응답할 때 관련 DocID의 모든 프리픽스가 비관련 DocID보다 더 높은 점수를 받는 것을 보장하지 못합니다. 이는 빔 검색의 초기 단계에서 관련 DocID를 버릴 위험을 증가시켜 정보 검색 성능에 부정적인 영향을 미칩니다.
두 번째 행에서는 프리픽스 최적화 내에서 다중 목표 학습을 통합하는 것이 중요함을 추론할 수 있습니다. 이 포함은 MRR@10에서 추가적으로 5%의 성능 향상을 가져옵니다. 이 향상은 점진적 학습의 후반 단계에서 발생하는 망각 문제를 완화하는 접근 방식의 효과 덕분으로 간주될 수 있습니다. 특히, 이 방법론은 손실 계산에 최소한의 추가만 도입하여 학습 중 계산 오버헤드를 증가시키지 않습니다.
세 번째 행에서는 최종 학습 단계에서 자체 음성 미세 조정을 사용하지 않은 RIPOR의 결과가 보고됩니다. 이 전략을 포함하면 MRR@10에서 2.5% 향상, Recall@10에서 3.5% 향상을 가져옵니다. 이러한 어려운 음성 샘플을 전략적으로 활용함으로써, 우리는 모델의 역량을 강화하여 관련 DocID가 잠재적으로 높은 점수를 받는 어려운 음성보다 일관되게 더 높은 순위를 유지하도록 보장하며, 결과적으로 모델의 전체 효과성을 높입니다.
네 번째 행에서는 seq2seq 사전 학습을 통합함으로써 RIPOR가 MRR@10에서 4% 향상을 달성함을 알 수 있습니다. 이 방법은 모델이 전체 코퍼스에 걸쳐 문서 정보를 캡슐화할 수 있게 하여 밀집 검색 모델의 인덱싱 단계를 반영하며, 결과적으로 관찰된 성능 향상을 이끌어냅니다.
다섯 번째 행에서는 생성 검색 모델을 밀집 인코더로 처리하지 않고 대신 문서별로 sentence-T5 [40]를 사용하여 숨겨진 표현을 도출할 때, MRR@10에서 73%의 상당한 성능 저하가 발생합니다.
마지막으로, RQ를 PQ로 대체하면 MRR@10에서 197% 감소로 나타나는 상당한 성능 저하가 발생합니다. PQ가 밀집 검색 도메인에서 효과적인 양자화 알고리즘으로 인식되지만, 우리의 결과는 PQ가 생성 검색에 적합하지 않음을 시사합니다. 이 한계는 문서 간의 계층적 구조를 캡슐화하지 못하는 PQ의 한계에서 비롯될 수 있으며, 이는 특히 빔 검색을 사용할 때 생성 검색에서 중요한 속성입니다. 우리는 부록 A에서 RQ와 PQ의 특성을 추가로 분석합니다.
4.3 분석 및 논의
4.3.1 DocID 조합의 영향: 문서 식별자(DocID)의 구성, 특히 그 길이 𝐿과 어휘 크기 𝑉은 모델 𝑀의 효과에 영향을 미칩니다. 우리는 이 관계를 MSMARCO Dev 세트에서 다양한 성능 메트릭을 평가하여 조사하며, 세부 사항은 표 3에 나와 있습니다. 첫째, 추가 매개변수를 일정하게 유지할 때(𝐿 × 𝑉 × 𝐷로 정량화됨), DocID 길이 𝐿이 증가함에 따라 MRR@10 및 Recall@10에서 성능이 향상됨을 관찰했습니다. 둘째, DocID 길이 𝐿을 고정하고 어휘 크기 𝑉을 증가시키면 성능 메트릭이 눈에 띄게 향상됩니다. 예를 들어, 𝐿 = 16일 때, 어휘 크기를 512에서 1024로 늘리면 MRR@10 기준으로 5.5% 향상이 발생합니다.
4.3.2 문서 근사 표현의 품질: 3.2절에서는 모델의 성능에 대한 관련성 기반 문서 유사성의 중요성을 강조했습니다. 우리의 모델이 이러한 신호를 포착할 수 있음을 보여주기 위해, 우리는 TREC DL 19 및 TREC DL 20에서 20개의 질의와 그에 해당하는 관련 문서를 무작위로 선택했습니다. 우리는 근사 벡터 표현 ˆd = ∑𝐿𝑖=1 E𝑖 [𝑐𝑑𝑖]을 사용하고, T-SNE [57]을 적용하여 각 문서의 근사 표현을 시각화를 위해 2D 공간에 투영했습니다. 그림 3에 설명된 대로, 우리는 𝐿 = 1, 2, 4, 8, 16, 32와 같이 다른 프리픽스 길이에 대한 클러스터링 품질을 연구했습니다. 첫째, 𝐿 ≥ 8일 때, 동일한 질의에 관련된 문서들이 해당 클러스터에 위치하여, RIPOR가 관련 문서를 효과적으로 서로 가깝게 배치하면서 비관련 문서들을 멀리 떨어뜨린다는 것을 나타냅니다. 둘째, 𝐿이 증가함에 따라 클러스터링 품질이 점진적으로 향상됩니다. 이는 𝐿이 증가함에 따라 근사 벡터 ˆd와 원래 벡터 d 사이의 거리가 감소하여, 근사가 더 세밀한 정보를 포착할 수 있기 때문일 수 있습니다.
4.3.3 프리픽스 길이의 영향: 프리픽스 길이는 원래 벡터와 근사 벡터 간의 왜곡 오류에 영향을 미치기 때문에 RIPOR 프레임워크에서 중요한 역할을 합니다. 4.3.2절에서는 저차원 공간에서 문서 유사성 측면에서 그 효과에 대한 질적 관점을 제공했으며, 이 섹션에서는 그림 4에 설명된 대로 검색 성능에 대한 정량적 영향을 분석합니다. RIPOR의 다양한 DocID 조합을 보여주는 왼쪽 그림을 참조하면 여러 트렌드가 나타납니다. 첫째, 프리픽스 길이 𝐿이 증가함에 따라 성능이 지속적으로 향상됩니다. 둘째, 이 성능 향상 속도는 짧은 프리픽스 길이에서 더 두드러지며, 𝐿 ≤ 8일 때 향상이 더 크다는 것을 알 수 있습니다. 셋째, 동일한 프리픽스 길이에서, 더 큰 어휘 크기를 가진 변형이 더 나은 성능을 보이는 경향이 있습니다. 오른쪽 그림에서 4.3.3절의 절삭 연구에서 선택된 세 가지 변형과 RIPOR를 비교할 때, 다음과 같은 관찰이 이루어집니다. 첫째, 프리픽스 지향 최적화를 제외하면 성능이 항상 감소합니다. 둘째, "sentence-T5로 대체" 변형의 성능 곡선은 DocID 초기화의 중요한 역할을 강조합니다. 프리픽스 지향 최적화와 비교할 때, DocID 초기화가 모델 성능에 더 중요한 역할을 할 수 있습니다. 이를 제거하면 성능이 더 크게 떨어집니다. 셋째, 제품 양자화(PQ)는 생성 검색과 덜 호환되는 것으로 보이며, 𝐿 >= 8일 때 성능이 거의 증가하지 않습니다. 성능 정체는 PQ가 문서 간의 계층적 미묘함을 포착하지 못하는 단점 때문일 수 있으며, 이는 더 긴 프리픽스 길이에서 얻을 수 있는 이점에 영향을 미칩니다.
5 관련 연구
고전적인 신경 IR 모델: 정보 검색(IR) 작업에서 사전 학습된 언어 모델(LM) [16, 34, 47, 52]을 미세 조정하는 것이 다양한 시나리오에서 BM 25와 같은 전통적인 모델 [27, 41, 62]에 비해 더 효과적이라는 것이 입증되었습니다. 이러한 발전은 주로 광범위한 코퍼스에서 자기 지도 학습(SSL)을 통해 획득한 LM의 텍스트 의미에 대한 깊은 이해와, 미세 조정을 위한 대규모 IR 학습 데이터셋의 가용성 [4, 29]에서 비롯되었습니다. LM에 의해 강화된 고전적인 신경 IR 모델은 크게 세 가지 유형으로 분류될 수 있습니다: (1) 크로스 인코더 모델, (2) 듀얼 인코더 모델, (3) 희소 검색 모델입니다. 크로스 인코더 모델 [41, 42, 46, 70]은 질의-문서 쌍을 함께 연결하여 입력으로 사용하여 관련성 점수를 예측합니다. 그러나 크로스 인코딩 특성 때문에, 이러한 모델들은 추론 속도에 한계가 있어 빠른 검색에는 부적합합니다. 검색을 위해 밀집 인코더 모델 [19, 22–24, 27, 33, 35, 46, 61, 62, 65–67]은 듀얼 인코더 아키텍처를 사용하여 질의와 문서를 저차원 공간으로 개별적으로 인코딩합니다. 추론 중에는 빠른 검색을 위해 근사 최근접 이웃 검색(ANNs) [37, 62]이 적용됩니다. 희소 검색 모델 [11, 12, 17, 18]은 검색을 위한 대체 방법을 제공합니다. 이러한 모델은 질의와 문서를 고차원 벡터로 투사하여 각 요소의 가중치가 해당 하위 단어의 중요한 점수를 나타내는 단어집합 접근법 [50, 51]에서 영감을 받았습니다. FLOPs [17, 18, 44] 또는 L1 [64] 정규화자가 고차원 벡터를 희소화하여 중요한 하위 단어를 필터링하는 데 사용됩니다. 검색을 위해 역색인 [51]이 적용됩니다.
생성 검색: 밀집 및 희소 검색 모델에서 사용되는 기존의 "검색 후 인덱스" 접근법과는 달리, 생성 검색(GR) [8, 55]은 각 문서를 DocID로 불리는 고유 식별자로 표현하는 최근의 생성 언어 모델(LM) [13, 43, 47]의 발전에 의해 촉발된 획기적인 패러다임을 도입합니다. T5와 같은 시퀀스 투 시퀀스 모델은 질의에 응답하여 관련 DocID를 생성하도록 학습되며, 이는 최종 순위를 생성하기 위해 해당 문서로 다시 매핑됩니다. DocID는 미세 조정 단계에서 고정되어 있으며, 종종 효과적인 GR 모델 훈련의 병목 역할을 합니다. 일반적으로 DocID는 두 가지 범주로 나뉩니다: (1) 의미 기반 DocID와 (2) 단어 기반 DocID입니다. 의미 기반 DocID는 문서 표현에서 문서 간의 의미적 관계를 포착하기 위해 양자화 [6, 48, 69] 또는 계층적 클러스터링 접근법 [39, 53, 55, 59]을 사용합니다. 최근 연구 [25, 53]에서는 GR을 위한 학습 가능한 DocID를 얻기 위해 토큰화 학습 방법을 도입하기도 했습니다. 단어 기반 DocID는 n-그램 [3, 7, 31, 32, 60], 제목 [5, 8, 9, 30], URL [49, 69], 중요한 단어 [68] 등을 포함하여 문서 내용에서 직접 구성됩니다.
6 결론 및 향후 연구
우리는 대규모 데이터셋을 위한 생성 검색 모델의 성능을 향상시키기 위해 설계된 RIPOR 프레임워크를 소개했습니다. 우리는 DocID 생성의 순차적 특성을 활용하기 위해 새로운 프리픽스 지향 순위 최적화 방법을 사용했습니다. 생성 검색을 밀집 인코더로 간주하여 이를 목표 작업에 맞게 미세 조정하고, DocID 생성을 위해 잔여 양자화를 적용했습니다. 우리의 실험 결과는 이 DocID 생성이 문서 간의 관련성 기반 유사성을 캡슐화하여 IR 작업의 효과성을 향상시킴을 입증했습니다. 앞으로는 모델의 효율성을 더욱 최적화하고, 이 프레임워크를 오픈 도메인 QA 및 사실 확인과 같은 다른 지식 집약적인 작업에 통합하는 것을 목표로 하고 있습니다.