추천 시스템은 온라인 정보를 필터링하여 사용자들의 관심사에 맞는 아이템을 발견하도록 도움을 줍니다.
전통적인 추천 시스템은 사용자의 과거 클릭, 구매 내역, 평점 등 상호 작용 기록을 바탕으로 사용자와 아이템의 표현을 학습하고, 추천을 진행합니다.
그러나 콜드 스타트 추천은 사용자, 아이템 간의 상호작용 정보가 없어 개인화된 추천 제공에 어려움을 겪는 것으로 주로 스타트업 기업에서 발생합니다.
이러한 문제를 해결하기 위해 PromptRec라는 접근 방식을 통해 대형 언어 모델의 인 컨텍스트 학습 능력으로 감성 분석 작업으로 변환하였습니다. 그러나 이 접근법은 대형 언어 모델의 인 컨텍스트 러닝에 상당히 의존하고, 지연 시간이 매우 컸기 때문에 새로운 방안을 찾아야 했습니다.

이전 콜드 스타트 추천 문제는 기존 시스템에서 새로운 아이템, 새로운 유저가 참여했을 때를 기준으로 연구를 진행했지만, 이번 연구에서는 완전히 새로운 시스템에서 추천을 진행하는 시스템 콜드 스타트 추천 문제연구를 진행하였습니다.
SLM도 LLM과 같이 인 컨텍스트 리코맨더가 될 수 있을까?
이 질문에 답하기 위해 히든 마르코프 모델이라는 개념을 조금 알고 진행해야 합니다.

Markov model은 어떠한 날씨, 주식가격 등과 같은 어떠한 현상의 변화를 확률 모델로 표현한 것이다. Hidden Markov model (HMM)은 이러한 Markov model에 은닉된 state와 직접적으로 확인 가능한 observation을 추가하여 확장한 것이다. HMM은 observation을 이용하여 간접적으로 은닉된 state를 추론하기 위한 문제를 풀기 위해 사용된다.
위 그림은 은닉된 state와 그에 따른 observation의 개념을 나타낸다. HMM을 이용해 우리가 풀고자 하는 문제는 관측 가능한 것은 오직 yt뿐이며, yt는 qt에 종속적으로 발생한다고 할 때, yt의 sequence를 통해 qt의 sequence를 추론하는 것이다.

위 질문에 답하기 위해 언어 모델을 활용한 간단하지만 효과적인 인컨텍스트 학습 접근 방식인 PromptRec을 제안하여 시스템 콜드 스타트 추천 문제를 해결하고자 합니다. 구체적으로, PromptRec은 먼저 사용자와 아이템의 프로필 특징을 자연어 설명으로 변환 후, 추천 작업을 이진 감성 단어에 대한 언어 모델링 작업으로 재구성하는 템플릿을 적용합니다. 마지막으로 언어 모델을 활용하여 작업을 수행하고 추천을 제공합니다. 초기 실험 결과, 대형 언어 모델은 개인화된 콜드 스타트 추천을 성공적으로 수행했지만, 작은 언어 모델은 실패했으며, 이는 LLM의 인컨텍스트 학습 능력에서 관찰된 스케일링 법칙과 일치합니다.
이 이유를 이해하기 위해, 우리는 Hidden Markov Model (HMM) 가정 하에 PromptRec의 인컨텍스트 추천 메커니즘을 공식화하기 위한 이론적 프레임워크를 제안합니다. 이 가정 하에서, 언어 모델은 입력된 프롬프트(사용자-아이템 프로필 및 템플릿)를 기반으로 '개념'(감성 극성)을 먼저 추론한 후, 추론된 개념과 입력을 기반으로 추천을 제공합니다. 우리의 분석은 언어 모델이 사용자-아이템 컨텍스트와 서로 다른 사전 학습된 개념에 대한 사전 확률을 조건으로 감성 단어의 가능성을 추정하여 인컨텍스트 추천을 수행함을 보여줍니다. 작은 언어 모델은 파라미터가 제한적이기 때문에 이 두 가지 요소에 대한 정확한 추정을 제공하지 못합니다.

위 발견을 바탕으로 데이터 중심 파이프라인을 통해 인 컨텍스트 예측 확률의 추정을 개선하여 작은 언어 모델의 추천 성능을 향상했습니다. 이 파이프라인은 모델 사전 학습과 프롬프트 템플릿 사전 학습이라는 두 가지 단계로 구성됩니다.
구체적으로 추천 시나리오와 관련된 코퍼스에서 언어 모델을 사전 학습하고, 다른 추천 도메인과의 상호작용을 통해 프롬프트 템플릿을 사전학습하는 것으로 작은 언어 모델의 성능을 향상할 수 있습니다.
이 때 학습 데이터는 목표로 하는 추천 도메인과는 다른 도메인이기 때문에 시스템 콜드 스타트 설정을 위반하지 않습니다.
이 두 가지 사전 학습을 진행하기 위해 코퍼스를 어떻게 찾을지, 프롬프트 템플릿을 다양한 도메인에 걸쳐 어떻게 일반화 시킬 것이라는 문제를 해결해야 합니다.
첫 번째는 콜드 스타트 시나리오와 상호 작용 정보를 최대화하여 일반 코퍼스를 정제하고, 두 번째는 프롬프트 템플릿을 작업과 도메인 프롬프트로 분해하여 다양한 추천 시나리오에서 사용 가능하도록 하였습니다.

추천 데이터 셋은 유저, 아이템, 사용자- 아이템 상호작용을 저장하는 행렬로 구성됩니다. R은 각 아이템과 사용자마다 0,1로 사용 했는지 나타냅니다.
각 사용자와 아이템은 프로필 특성을 가지며 cu와 ci로 표시되고 각각 특성을 설명합니다. 예로 사용자는 나이, 성별 직업이 있고, 아이템은 이름, 브랜드, 카테고리 등이 있습니다.
추천 시나리오를 설명하기 위해 클릭율 예측 작업 즉 CTR을 선택했습니다. 각 기록은 0,1로 표현되어 있고, 1은 클릭했음을 표현합니다. 추천 시스탬 f는 유저 아이템 프로필을 입력으로 받아 사용자가 해당 아이템을 클릭할 확률을 0에서 1로 출력으로 예측합니다. CTR 예측의 목표는 예측된 확률과 실제 사용자 아이템 상호작용 간의 차이를 최소화하는 것입니다.
시스템 콜드 스타트 추천에서는 상호작용 기록을 얻을 수 없으며 즉 유저와 아이템 정보만 가지고 R행렬은 비어있는 것입니다. 유저와 아이템 특성을 통해 아이템을 추천하는 것이 목표 입니다.

전통적인 지도 학습 패러다임에서는 모델을 조정할 학습 데이터가 없기 때문에 시스템 콜드 스타트 설정에서 실패합니다. LLM의 인 컨텍스트 학습 능력은 이 문제를 극복할 수 있는 방법입니다. 이 때 다운 스트림 작업은 "프롬프트 학습"이라고도 하는 LM 학습 작업 중 하나로 형식화 됩니다. 최근 프롬프트 기반 추천 시스템은 추천 프로세스를 언어 모델링 작업과 일치 시키는 방식으로 LLM을 사용해 아이템 이름이 나타날 확률을 추정합니다.
예를 들어 "a user cliked hiking shoes, will also click trekking poles"이라는 문맥이 주어지면 "trekking poles"가 나올 확률을 해당 아이템에 대한 사용자 선호도로 간주합니다.
그러나 단순히 아이템 이름을 예측하는 것은 제로샷 상황에서 추천에 효과적이지 않습니다. 이는 아이템 이름의 확률이 이름의 모든 단어에 영향을 받아 일반적인 단어로 구성된 이름을 가진 아이템이 문맥에 상관없이 더 높은 확률로 나타날 가능성이 있기 때문입니다.
예를 들어 리그 오브 레전드는 젤다의 전설보다 자연스럽게 더 높은 확률을 가지는데 이는 리그가 젤다보다 코퍼스에서 더 일반적이기 때문입니다.

이 문제를 해결하기 위해 이름을 예측하는 대신, 선택된 이진 단어의 확률을 예측하여 추천을 제공합니다. 감성 단어와 관련된 확률을 예측하면 희귀하거나 빈번하게 나타나는 언어의 영향을 줄여 사용자 선호도를 보다 정확하게 표현할 수 있습니다. 사용자 아이템 쌍 cu, ci를 문맥 Xu,i로 매핑하는 프롬프트 함수 fprompt를 정의합니다. fprompt는 도메인 마다 전문가에 의해 생성되며 언어 모델 fLM은 프롬포트를 전달 받아 아이템에 대한 선호도를 다음과 같이 예측합니다.
V포지티브와 V 네거티브는 미리 정의된 긍정 및 부정 감성 어휘 집합이고, V는 전체 어휘 집합입니다.
p w바 xu,i는 fLM이 인 컨텍스트 학습을 통해 문맥 xu,i를 조건으로 해 단어 w를 생성할 확률입니다.
아래 적힌 탬플릿을 생성합니다. 밑줄친 각 단어는 슬롯으로 사용자와 아이탬 프로필 cu, ci로 채워집니다. V포지티브가 굳이고, V네거티브가 배드라면 예측된 선호도는 마스크 위치에서 좋다와 나쁘다가 나올 확률을 정규화하여 계산됩니다.

각 감성 어휘 집합에 하나의 단어만 고려한다고 가정하면, 즉 |Vpos| = |Vneg| = 1인 경우, 사용자-아이템 쌍에 대한 콜드 스타트 추천의 목표는 다음과 같이 정의됩니다
여기서 𝑦𝑢,𝑖는 실제 선호도 𝑟𝑢,𝑖 = 1일 때 Vpos에 있는 유일한 긍정 단어를 나타내며, 그렇지 않은 경우 Vneg에 있는 유일한 부정 단어를 나타냅니다. 위의 방정식은 추천의 효과가 예측의 정확한 추정에 크게 의존함을 나타냅니다. 이는 LLM을 활용하여 달성됩니다. 그러나 온라인 추천에서 LLM을 사용하는 단점은 상대적으로 느린 추론 속도입니다. 이 문제를 극복하는 한 가지 방법은 PromptRec에서 작은 언어 모델을 사용하는 것이지만, 이들은 제한된 인컨텍스트 학습 능력을 가진 것으로 알려져 있습니다.
언어 모델의 인컨텍스트 학습 능력을 향상시키는 방법을 분석하기 위해, 우리는 언어 모델이 히든 마르코프 모델로 단어를 생성한다고 가정하여 모델 예측을 확장합니다. 히든 마르코프 가정 하에서, 언어 모델 𝑓LM은 두 단계의 과정을 통해 단어를 생성하는데, 먼저 개념 기반 Θ에서 개념 𝜃 ∈ Θ를 선택하고, 그 개념에 따라 단어 시퀀스를 샘플링합니다. 따라서 우리는 인컨텍스트 추천 목표 함수를 다음과 같이 확장할 수 있습니다:
효과적인 추천 모델은 위 방정식의 각 요소에 대한 정확한 추정이 필요합니다. 뒤의 4.3장에서는 모델 사전 학습을 통해 더 나은 확률 추정을 위한 데이터 정제 전략을 소개합니다. 4.4장에서는 프롬프트 사전 학습을 통해 X𝑢,𝑖의 디자인을 개선하는 방법을 소개합니다.

언어 모델이 코퍼스를 사전 학습한 후 추천 작업에 사용될 수 있는 이유를 분석하는 것으로 시작됩니다. 언어 모델은 단어 w가 그 시퀸스의 우도를 최대화 하도록 사전학습 됩니다.
HMM 프레임워크에 따르면 사전 학습 목표는 다음과 같습니다.
이 목표는 언어 모델이 개념에 따라 단어 확률을 구분할 수 있도록 장려합니다. 만약 타겟 데이터 쌍xu,i와 yu,i이 사전 학습 시퀸스 즉w에 존재한다면 모델은 다음 목표 함수로 최적화될 기회를 같습니다.
여기서 베이즈 정리에 따라 다시 다음과 같이 변환될 수 있습니다.
xu,i와 y u,i를 포함하는 텍스트를 사전학습하는 것이 확률 추정을 더 정확하게 함으로써 추천 성능을 향상시킬 수 있음을 나타냅니다.
그러나 x와 y를 포함하는 큰 일반 코퍼스에서 작은 언어 모델을 학습하는 것은 제한된 파라미터를 사용해 관련 없는 문서를 인코딩하게 되어 낭비를 하게 됩니다.
그래서 일반 코퍼스를 작은 크기로 정제하여 더 유용한 정보만을 사전 학습에 사용하는 방법이 다음 페이지에 나옵니다.

다양한 실제 세계의 소스에서 수집된 일반 코퍼스 C는 콜드 스타트 시나리오를 포함하고 있습니다.
일반 코퍼스에서 fLM을 사전학습 하는 것은 콜드 스타트 추천에 유익할 수 있으나 많은 자원과 파라미터가 필요하기 때문에 어려움이 있습니다.
또한 데이터 크기를 줄이기 위해 일반 코퍼스를 정확하게 콜드 스타트 시나리오만을 포함하도록 하는 것도 어렵습니다.
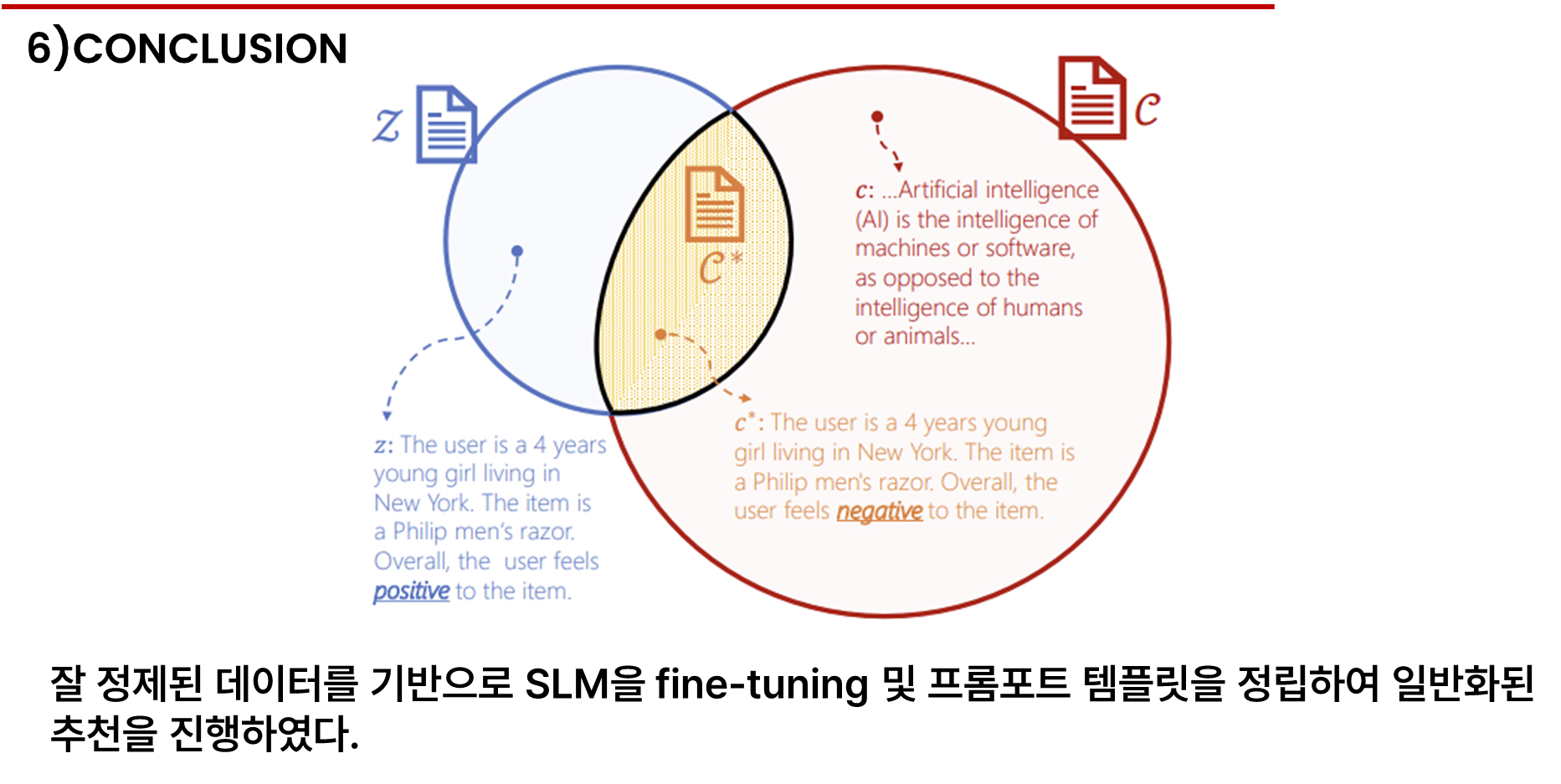
그리하여 콜드 스타트 시나리오 정보를 유지하며 K개의 문서만 포함하는 정제된 코퍼스 C 햇을 제안합니다.
자체적으로 구축한 코퍼스 Z를 기반으로 C 햇을 구성합니다. Z는 모든 가능한 사용자, 아이템 프로필과 모든 감성 극성 즉 y를 포함합니다.
콜드 스타트 시나리오에서 Z는 모든 가능성을 포함함으로 C*는 Z에 포함될 수 있습니다. 또한 일반 코퍼스와 우리가 구축한 코퍼스는 모두 C*를 포함하므로 C와 Z의 정보를 최대화하는 하위 집합 C 햇을 찾음으로써 C*를 얻을 수 있습니다.
좌측 하단 식에서 MI는 상호정보를, H는 엔트로피를 의미하며, p는 두 텍스트의 결합 확률과 조건부 확률을 나타냅니다.
아래의 설계를 통해 콜드 스타트 시나리오와 가장 관련이 있는 문서 K개를 추출할 수 있으며 이는 유저와 아이템 프로필을 암묵적으로 포함합니다.
이렇게 만든 데이터셋 C햇은 일반 코퍼스 C와 자체 코퍼스인 Z와의 유사도, C이후에 Z가 나오는 것에 대한 높은 확률만을 가지고 가면서 fLM의 인 컨텍스트 추천 성능을 향상하였씁니다.
여기서 gLM은 ctr예측에 활용되는 fLM과는 다른 언어 모델이며, gLM은 전처리 용 모델입니다.
프롬포트 탬플릿 S를 사용자 아이템 컨텍스트 Xu,i의 프리픽스로 간주하면 학습 목표는 다시 변경됩니다.
S*은 경사 하강법을 통해 아래와 같이 최적화 될 수 있습니다.
그러나 콜드 스타트 알고리즘에서 R행렬을 관찰할 수 없기에 다른 추천 시나리오에서 상호작용 기록을 수집합니다.
이 데이터셋을 src라고 부르며 사용자 집합, 아이템 집합, 상호작용 행렬, 프로필 특징을 포함합니다.
src데이터 셋은 상호작용 행렬인 R행렬을 그대로 사용하여 학습하고, 콜드 데이터 시나리오를 포함하지 않습니다.
마지막 식을 보면 최적의 프리픽스 S*가 Xu,i와 y의 매핑에서 정보를 포착한다는 것을 보여줍니다.
그러나 다른 도메인에서는 최적의 S*을 생성하지 못하여 다른 방법이 필요했습니다.

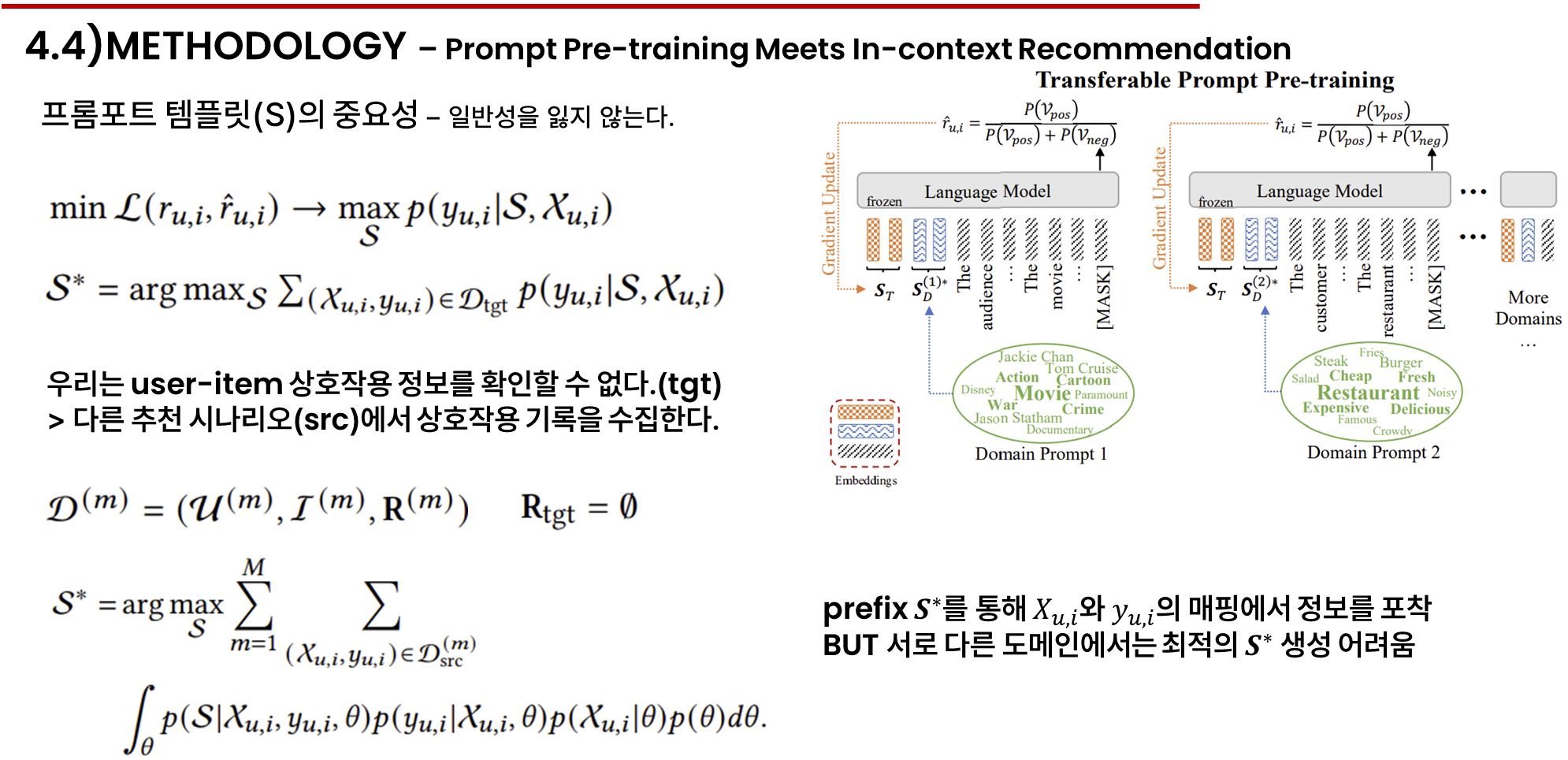
이 문제를 해결하기 위해 프리픽스 S를 작업 프롬프트 St와 도메인 프롬포트 SDm으로 나누어 추천과 특정 시나리오 주제를 반영하였습니다.
st는 x와 y의 매핑에서 정보를 포착하고, sdm은 X의 고유 특성을 반영하여 다시 표현하였씁니다.
여기서 st는 고정되지만 sdm은 도메인마다 바뀌기에 콜드 스타트 시나리오에서 이 목표를 달성하기 어려운데 주제를 반영하는 인코딩이 필요하므로 아이템 프로필을 키워드로 표현할 수 있습니다. 그리하여 목표 도메인의 아이템 프로필에서 키워드를 추출하여 목표 도메인 프롬포트인 sd타겟을 추정합니다.
여기서 gdom은 tf-idf와 같은 키워드 추출 방법으로 설계됩니다.
두 번째 단계는 소스 데이터셋의 상호작용을 활용해 프롬포트 분해 방법을 사용하여 마지막 식과 같이 작업 프롬프트를 최적화합니다.
st*를 얻은 후에는 그림에서 설명된 대로 이를 d tgt에서의 콜드 스타트 추천에 적용할 수 있습니다. 구체적으로는 st*와 sd타겟*은 콜드 스타트 추천에서 각 사용자 아이탬 컨텍스트 xu,i의 프리픽스로 삽입됩니다.

이 벤치마크는 전통적인 지도 학습 방법, 규칙 기반 방법, LLM 기반 방법을 포함한 기준 방법을 고려하며, 모든 기준과 향후 테스트는 GAUC를 사용하여 평가됩니다.
콜드 스타트 추천의 제약은 학습 중 사용자 아이템 상호작용이 부족하다는 점으로 추천 시스템이 개인화된 추천을 제공하기 위해 프로필 특징에 크게 의존한다는 점이 있습니다.
이러한 요구를 만족하는 3가지 데이터셋으로 ml100k는 영화 추천 능력, 쿠폰은 매장 할인 추천, 레스토런트는 선호도를 예측하는 능력 측정입니다.
crt은 AUC로 평가할 수 있는 이진 분류 작업이지만 AUC는 모든 사용자- 아이템 상호작용을 계산에 포함하기에 개인화된 추천에 사용하는데 한계가 있다. 이는 다른 사용자들 간의 예상치 못한 간섭을 초래할 수 있으므로 GAUC를 사용해 각 사용자에 대해 AUC를 계산한 뒤 가중 평균으로 이를 집계하여 문제를 해결했습니다.
여기서 #히스토리는 사용자 u의 기록 수입니다.
우리는 두 가지 범주의 기준 방법을 고려합니다. 첫 번째는 인간이 설계한 규칙에 의존하는 기준으로, 예를 들어 무작위로 사용자에게 아이템을 추천하는 Random 방법이 있습니다. 두 번째 범주는 언어 모델 기반의 비지도 학습 방법으로, 사용자의 언어화된 특징과 아이템의 언어화된 특징을 입력으로 사용하고, LLM의 출력물을 사용하여 추천을 수행합니다. 예를 들어, EmbSim [66]은 사용자와 아이템의 언어화된 특징의 두 가지 임베딩을 생성하고, 이 임베딩들의 내적(dot product)을 통해 사용자-아이템 선호도를 예측합니다. PairNSP는 다음 문장 예측 작업 [6]을 적용하여, 사용자의 언어화된 특징과 아이템의 언어화된 특징을 결합하여 이를 언어 모델에 입력하고, 이들이 동일한 문맥에 속하는지를 결정합니다. ItemLM [5]은 사용자-아이템 컨텍스트 내에서 아이템 이름이 나타날 확률을 계산하여 선호도를 예측합니다.
prompt rec의 일반화를 보여주기 위해 다양한 규모, 구조, 사전학습 전략, 모델 크기를 가진 여러 대형 언어 모델을 고려하여 파라미터가 355~7B인 모델을 골랐습니다.
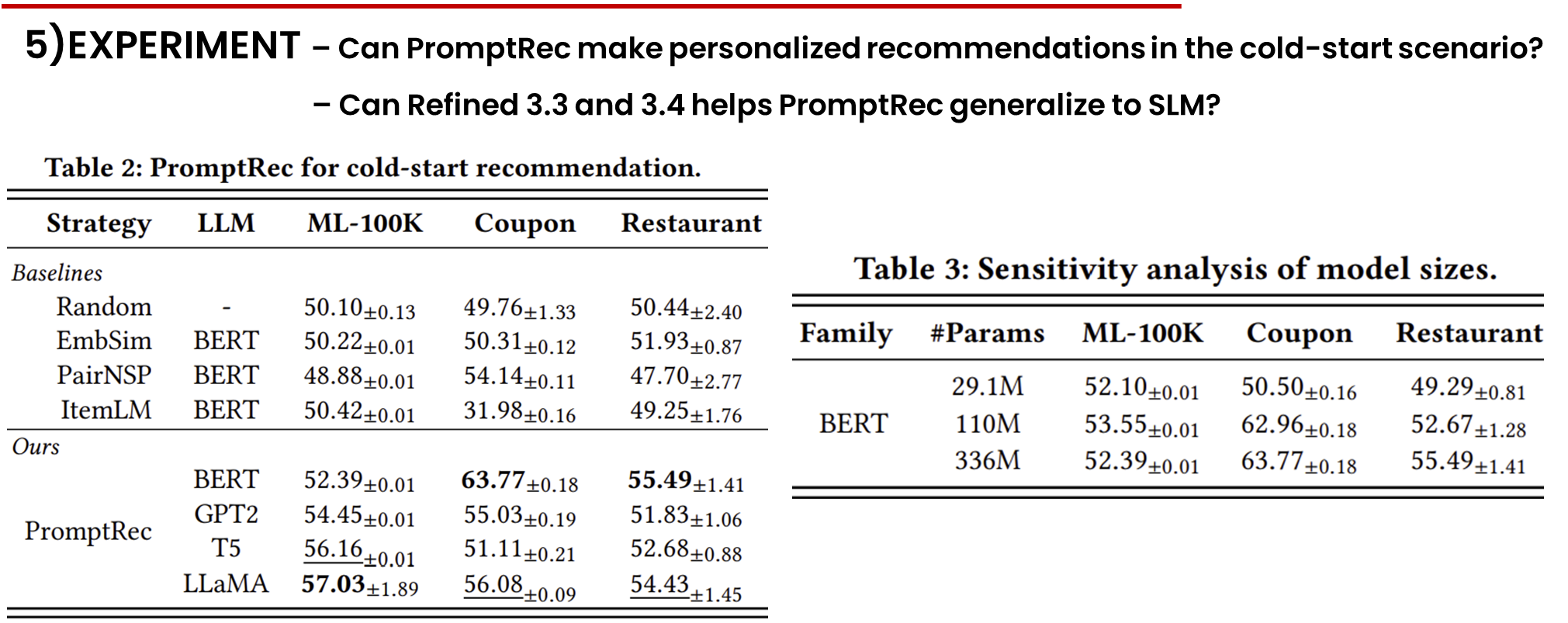
표 2는 제안된 벤치마크에서 다양한 백본 대형 언어 모델과 함께 PromptRec 접근법의 결과를 보여줍니다. 우리는 또한 BERT-large를 사용한 여러 기준 제로샷 솔루션의 결과를 상단에 보고합니다. 추가로, 표 3은 다양한 규모의 BERT 결과를 보고합니다. 아래와 같은 몇 가지 관찰이 이루어졌습니다.
기존 방법은 시스템 콜드 스타트 설정에서 개인화된 추천을 제공하는 데 대부분 실패했습니다. 시스템 콜드 스타트 설정에서 모든 데이터셋에서 일관된 효과적인 추천을 제공하는 기준 방법은 없습니다. 그 이유로는 다음과 같은 가능성이 있습니다. 본질적으로, 개인화된 추천은 모델이 동일한 카테고리의 아이템 간의 세부적인 차이를 포착해야 합니다. 그러나 EmbSim과 PairNSP가 사용하는 텍스트 표현과 NSP 작업 [6]은 대략적인 의미만 구별할 수 있습니다. 따라서 이들은 추천 작업을 잘 처리하지 못합니다. 반면, ItemLM은 세부적인 사전 학습 작업(예: MLM [6])에 의존하지만, 이는 3.1절에서 논의된 언어적 편향으로 인해 어려움을 겪습니다. 이러한 관찰은 시스템 콜드 스타트 추천을 수행하는 것이 매우 도전적이라는 것을 보여줍니다.
PromptRec은 다양한 LLM 계열에 대해 시스템 콜드 스타트 추천으로 일반화될 수 있습니다. PromptRec은 각 데이터셋에서 모든 LLM 후보와 함께 Random 전략보다 유의미한 개선을 보여, 강력한 일반화 능력을 나타냅니다. 특히, PromptRec은 세 가지 데이터셋에서 각각 최대 6.93%, 14.01%, 5.05% GAUC로 Random 전략을 개선하여 대형 언어 모델이 강력한 인컨텍스트 학습 능력으로 개인화된 추천을 제공할 수 있음을 입증했습니다.
표 3번에서 bert 계열이 모델 크기가 커짐에 따라 성능이 점진적으로 향상되며 29.1M 모델이 쿠폰과 음식점 데이터셋에서 콜드 스타트 추천을 제공할 수 없는 것을 보고 promptrec는 모델 크기에 민감한 것 보여줍니다.
작은 언어 모델에 대해 개선이 필요함을 확인할 수 있습니다.
RCMP는 일반 코퍼스를 정제하고, 정제된 코퍼스에서 언어 모델을 추가로 사전 학습하는 두 단계로 구성됩니다.
TPPT는 벤치마크의 각 데이터셋을 단일 콜드 스타트 시나리오로 간주하므로, 우리는 나머지 두 데이터셋을 사용하여 작업 프롬프트 St를 사전 학습합니다. 도메인 프롬프트 Sd는 각 데이터셋의 상위 TF-IDF [42] 점수 키워드에서 파생됩니다.
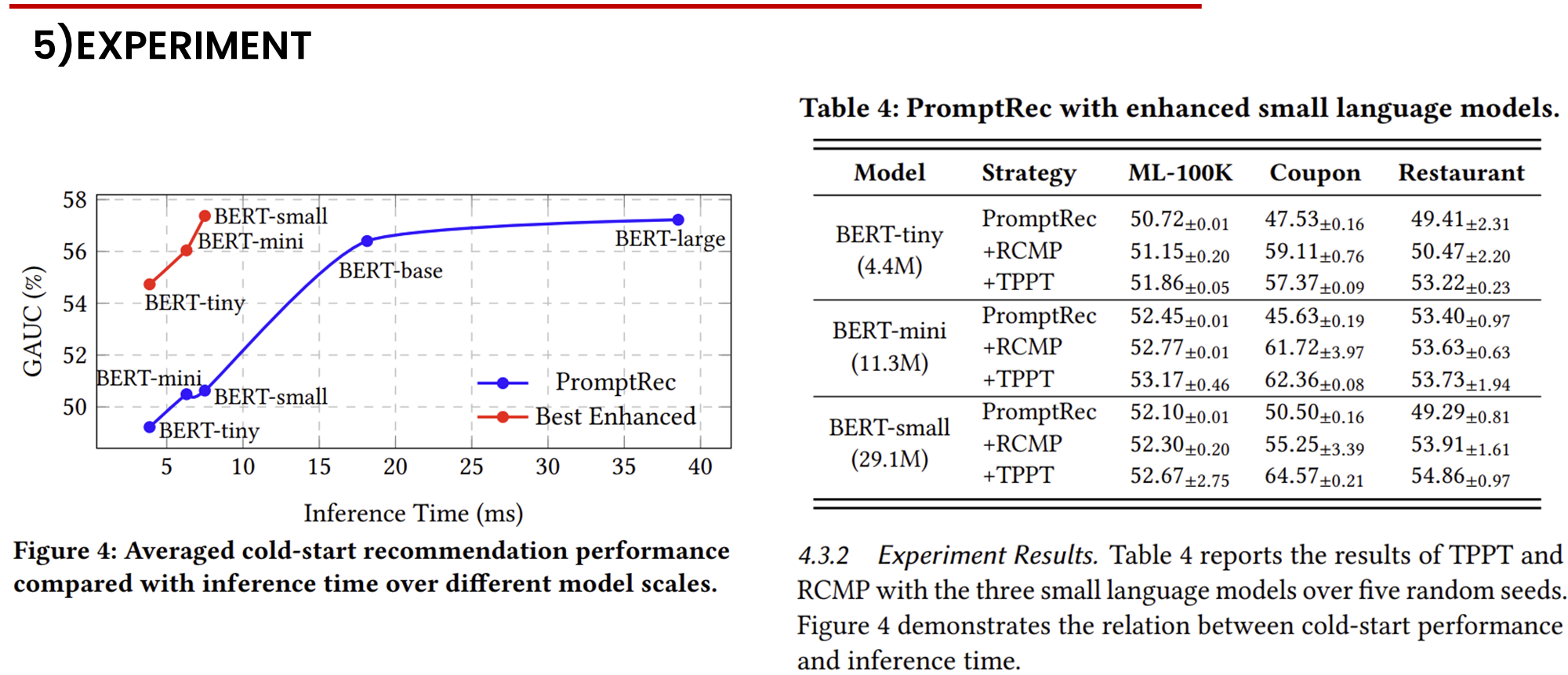
표 4는 TPPT와 RCMP 전략이 세 가지 작은 언어 모델에서 다섯 개의 랜덤 시드로 실험한 결과를 보고합니다. 그림 4는 콜드 스타트 성능과 추론 시간 간의 관계를 보여줍니다.
정제된 코퍼스에서 추가 사전 학습을 한 작은 언어 모델은 콜드 스타트 추천 성능을 향상시킵니다. 표 4에서 RCMP 전략은 작은 언어 모델을 사용하여 모든 데이터셋에서 PromptRec의 성능을 향상시킵니다. 특히, RCMP는 BERT-mini의 성능을 45.63% GAUC에서 61.72% GAUC로 크게 향상시켰습니다. PromptRec의 성능이 약 50.00% GAUC 이하였던 다섯 가지 경우에서, RCMP는 BERT-tiny를 사용한 Restaurant 데이터셋을 제외하고 효과적인 인컨텍스트 추천을 가능하게 했습니다. 이러한 결과는 RCMP가 정제된 코퍼스에서의 고급 사전 학습을 통해 작은 언어 모델이 인컨텍스트 추천을 달성할 수 있도록 한다는 것을 나타냅니다.
전이 가능한 프롬프트의 사전 학습은 작은 언어 모델이 더 나은 콜드 스타트 추천을 하도록 돕습니다. 표 4에서 TPPT 전략은 대부분의 상황에서 PromptRec의 콜드 스타트 추천 성능을 향상시킵니다. 특히, 쿠폰 데이터셋에서 BERT-small은 GAUC 64.57을 달성하여 모든 후보 모델 중 BERT-large가 달성한 최고 GAUC 63.77을 능가했습니다. 또한, TPPT는 이전에 언어 모델이 최적이 아니었던 다섯 가지 설정 모두에서 인컨텍스트 추천을 촉진했습니다. 더욱이, TPPT는 콜드 스타트 시나리오에서 일관되게 RCMP보다 뛰어난 성능을 보였습니다. 이러한 결과는 작은 언어 모델이 콜드 스타트 상황에서 인컨텍스트 추천을 위한 잠재력을 가지고 있지만, 이를 활성화하기 위해 최적의 프롬프트가 필요함을 나타냅니다.
개선된 작은 언어 모델은 훨씬 더 빠른 추론 속도로 효과적인 추천을 제공합니다. 그림 4는 다양한 모델 크기에서 PromptRec의 원래 성능과 향상된 성능을 비교합니다. 향상된 성능을 계산하기 위해, 우리는 각 데이터셋에서 TPPT 또는 RCMP 중 더 나은 결과를 선택한 후, 세 가지 데이터셋에서 평균을 냈습니다. 주목할 만하게도, BERT-large가 거의 40ms의 추론 시간을 사용하여 약 58%의 GAUC를 달성하는 반면, 우리의 방법은 작은 모델을 약 5ms 만에 BERT-large 성능에 근접하게 향상시켜, 모델 크기와 효율성 간의 균형을 강조했습니다.