https://arxiv.org/abs/2301.02401
You Truly Understand What I Need: Intellectual and Friendly Dialogue Agents grounding Knowledge and Persona
To build a conversational agent that interacts fluently with humans, previous studies blend knowledge or personal profile into the pre-trained language model. However, the model that considers knowledge and persona at the same time is still limited, leadin
arxiv.org

여전히 지식과 페르소나를 동시에 사용하는 모델은 환각이 있다.
-> 후보 점수 (candidate scoring)을 통해 적절한 지식과 페르소나 선택
-> 지식과 페르소나를 통해 쿼리를 강화하고, RAG를 사용하여 환각을 줄이고, 매력적인 대화 진행
INFO(INtellectual and Friendly dailOg agents) - 외부 지식과 페르소나로 동시에 반응한다
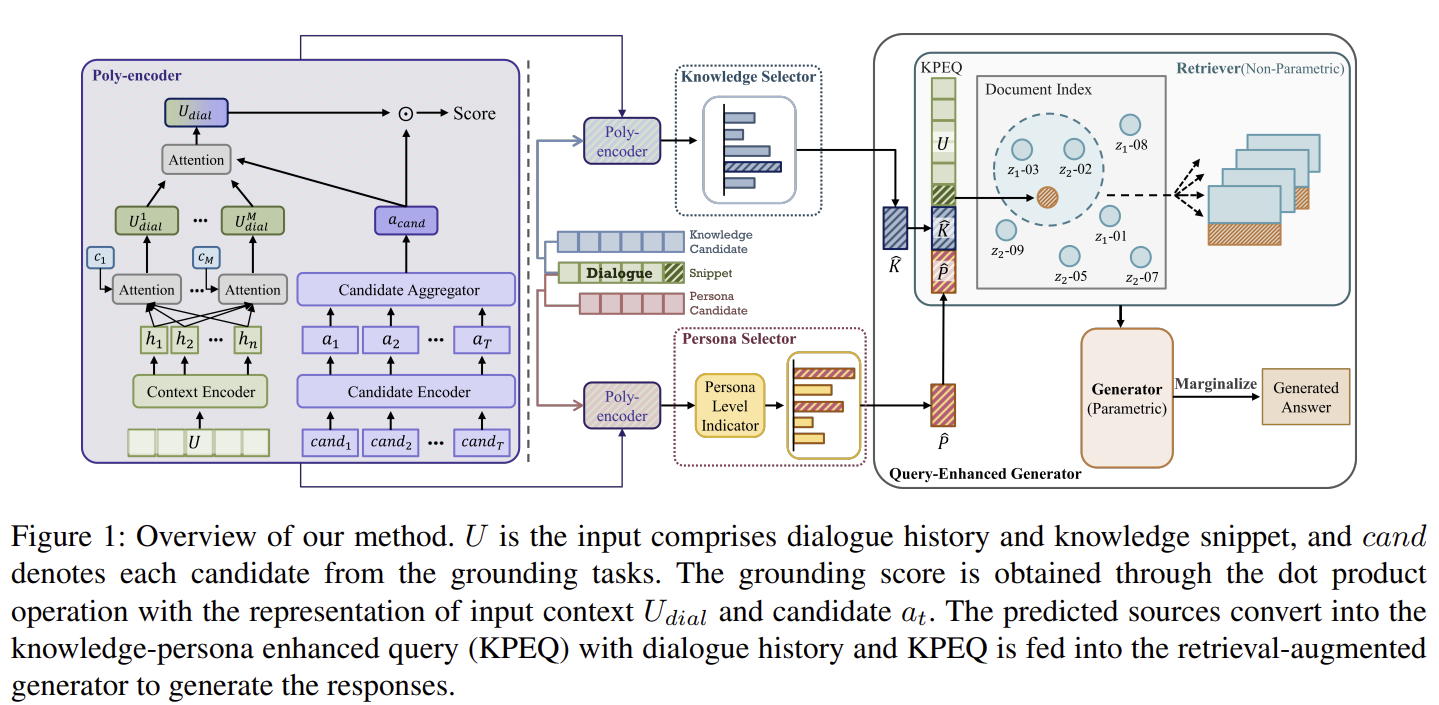
그런데 지식을 이미 poly-encoder로 선택했는데 굳이 RAG로 한번 더 찾는 이유가 있을까...?
poly-encoder는 관련성 높은 문서만 뽑아서 가져옴
RAG는 할루시네이션 방지하여 정확한 결과를 출력
이 논문은 인간과 유창하게 상호작용하는 대화형 인공지능 에이전트를 구축하기 위해 제안된 모델에 대해 다루고 있습니다. 특히 외부 지식과 사용자 개별 프로필(페르소나)을 동시에 활용하는 대화 에이전트를 제안하고, 이를 통해 기존 모델의 한계를 극복하려고 시도합니다.
1. 문제 정의
기존의 대화형 에이전트는 지식 또는 페르소나 중 하나만을 고려하거나 두 요소를 통합하는 데 제한이 있었습니다. 이로 인해 생성된 답변에서 잘못된 정보(환각)나 사용자 프로필을 수동적으로 사용하는 문제가 발생했습니다. 이러한 문제는 대화의 풍부함과 자연스러움을 저해하여, 사람과의 상호작용에서 비자연적인 대화가 이루어지게 했습니다. 논문은 외부 지식과 사용자 페르소나를 동시에 활용하여 환각을 줄이고 보다 매력적이고 지식 기반의 대화를 생성하는 에이전트를 개발하는 문제를 해결하려고 합니다.
2. 시도한 방법
이 연구는 INFO(Intellectual and Friendly dialOg agent)를 제안하며, 이는 외부 지식과 사용자 페르소나를 기반으로 답변을 생성합니다. INFO 모델은 다음과 같은 방식을 채택했습니다.
- 후보군 선택: 대화 내역과 지식을 기반으로 적절한 답변 후보를 선택하는 Poly-Encoder를 사용합니다. Poly-Encoder는 후보 간의 유사성을 평가하고, 대화 맥락에 맞는 적절한 지식과 페르소나를 선택합니다.
- 조회 강화 생성: RAG(Retrieval Augmented Generation) 모델을 사용하여 비파라메트릭 메모리와 파라메트릭 생성기를 결합합니다. 이를 통해 모델은 대화 중 필요한 외부 지식을 효율적으로 조회하고 활용하여 일관성 있는 답변을 생성합니다.
- 지식-페르소나 강화 쿼리(KPEQ): 대화 히스토리와 선택된 페르소나 및 지식을 결합한 쿼리를 생성하여 답변의 일관성을 유지하고 환각을 줄입니다.
3. 사용한 방법
INFO는 두 가지 주요 모듈로 나뉩니다:
- 지식 선택기와 페르소나 선택기: Poly-Encoder를 기반으로 한 후보 평가 모듈을 사용하여, 주어진 대화 맥락과 후보군 간의 관련성을 계산합니다. 그 후 가장 적합한 후보를 선택합니다.
- 조회 강화 생성기: 선택된 지식과 페르소나를 기반으로 답변을 생성하는 과정에서 RAG-Token 또는 RAG-Sequence를 사용하여 더욱 자연스럽고 정보성이 높은 대답을 생성합니다. RAG는 다양한 패러그래프에서 적절한 정보를 검색하여 환각을 줄이는 역할을 합니다.
4. 실험 결과
INFO 모델은 기존의 GPT-2, BART와 같은 모델보다 뛰어난 성능을 보였습니다. 자동 평가에서 INFO는 생성과 지식 기반 태스크에서 최고 수준의 성능을 기록했습니다. 또한 인간 평가에서도 유창성, 적합성, 참여도, 환각 여부에서 긍정적인 평가를 받았습니다.
주요 성능 지표로는 BLEU, ROUGE-1, ROUGE-2, chrF++ 등에서 큰 개선을 보였으며, 특히 환각 감소와 더 나은 지식 활용도 면에서 이전 모델들보다 우수한 결과를 보여줬습니다.
5. 한계점
INFO는 실세계 응용에서는 몇 가지 한계점이 존재합니다:
- 지식 및 페르소나 부재 상황: INFO는 사전 정의된 지식 또는 페르소나가 없을 때는 성능이 저하될 가능성이 있습니다. 실세계에서는 이러한 후보군이 항상 존재하지 않기 때문에 문제를 야기할 수 있습니다.
- 계산 리소스: INFO는 토큰 수준에서 손실을 계산하는 방식 때문에 높은 GPU 리소스를 요구합니다. 이는 대규모 실험 및 배포에서 비용이 많이 드는 문제를 야기할 수 있습니다.
- 환각 평가 데이터 부족: 인간 평가에서 환각 완화 능력을 평가하는 데이터 수가 제한적이어서 이를 더욱 확장된 사례에서 검증할 필요가 있습니다.
결론
INFO 모델은 외부 지식과 페르소나를 결합하여 자연스럽고 매력적인 대화형 에이전트를 구축하는 데 성공했습니다. 다만, 실세계 응용에서 더 다양한 시나리오에 대해 테스트하고 평가할 필요가 있으며, 계산 효율성을 높이는 연구가 추가적으로 요구됩니다.
그런데 지식을 이미 poly-encoder로 선택했는데 굳이 RAG로 한번 더 찾는 이유가 있을까...?
이 논문에서 INFO 모델은 Poly-Encoder와 RAG(Retrieval-Augmented Generation) 두 가지 메커니즘을 결합하여 사용하고 있습니다. 여기서 Poly-Encoder는 지식과 페르소나 선택을 위한 단계에서 사용되고, RAG는 선택된 지식과 페르소나를 활용하여 답변을 생성하는 과정에서 사용됩니다. 각 단계의 역할은 다소 상이하며, 이를 통해 모델의 성능을 최적화하려는 의도가 담겨 있습니다. 논문을 기반으로 이 두 가지 메커니즘이 결합되는 이유를 설명하겠습니다.
Poly-Encoder의 역할
Poly-Encoder는 지식과 페르소나 후보들 중에서 대화 맥락과 가장 관련성이 높은 것을 선택하는 데 사용됩니다. 이 단계는 후보군에서 적절한 지식과 페르소나를 선택하는 과정입니다. Poly-Encoder는 대화의 히스토리와 지식, 페르소나 간의 유사성을 측정하여 가장 관련성이 높은 항목을 찾아냅니다. 이 과정은 빠르고 효율적으로 관련 후보를 좁히는 역할을 합니다.
그러나 Poly-Encoder는 텍스트 생성에 직접적으로 관여하지 않으며, 단순히 선택된 지식과 페르소나를 기반으로 하는 더 높은 수준의 세부 정보를 다루지 않습니다. 이는 지식과 페르소나가 선택되었더라도, 그 정보를 어떻게 최종적으로 문장에 반영하고 답변을 생성할 것인가에 대한 문제는 여전히 남아있다는 의미입니다.
RAG의 역할
RAG는 Retrieval-Augmented Generation, 즉 지식 조회 기반 생성 모델입니다. 이 모델은 선택된 지식과 페르소나를 바탕으로 답변을 생성하는 과정에서 사용됩니다. RAG는 Poly-Encoder에서 선택된 정보에 추가적으로 정확한 지식 세부 사항을 검색하고, 이를 기반으로 보다 정교한 답변을 생성합니다. 이렇게 함으로써 답변이 더욱 일관되고, 실제로 참조할 수 있는 지식에 기반하도록 보장합니다.
결합의 이유
- 환각(Hallucination) 방지: Poly-Encoder는 대화 맥락에 맞는 지식과 페르소나를 선택하는 역할을 하지만, 이 정보를 기반으로 생성된 답변이 여전히 환각된 정보를 포함할 수 있습니다. 이를 방지하기 위해 RAG는 추가적으로 정확한 지식을 검색하여, 생성된 답변이 더욱 사실에 기반하고 신뢰성 있는 정보를 포함하도록 돕습니다.
- 정확한 세부 정보: Poly-Encoder는 큰 틀에서 적절한 지식을 선택할 수 있지만, RAG는 세부적인 정보를 검색하여 답변의 질을 높입니다. 즉, Poly-Encoder가 대략적인 방향을 설정하면 RAG는 그 방향에 맞는 구체적인 정보를 찾아 답변을 더 풍부하게 만듭니다.
- 유연성 및 확장성: Poly-Encoder가 선택한 정보는 고정된 지식 기반에서만 활용될 수 있는 한계가 있습니다. 반면 RAG는 필요시 추가적인 외부 지식을 동적으로 검색하여 활용할 수 있으므로, 답변의 정확도와 유연성을 높이는 데 기여합니다.
결론
Poly-Encoder는 적합한 지식과 페르소나를 선택하는 역할을, RAG는 선택된 정보를 기반으로 정교한 답변을 생성하는 역할을 합니다. 이 두 가지 모델의 결합은 더 정확하고 신뢰성 있는 대화를 만들어내기 위해 설계된 방식으로, 특히 환각을 줄이고 더 풍부한 대화를 생성하는 데 중점을 둡니다.
요약
4. 실험
- 데이터셋: 논문에서는 FoCus 데이터셋(12,484개의 대화, 5,152개의 지식 소스, 32,855개의 페르소나 문장)으로 실험을 진행했습니다. 이 데이터셋은 사용자 페르소나와 외부 지식을 기반으로 하는 맞춤형 대화 모델을 평가하기 위한 것입니다.
- 실험 설정: Poly-Encoder는 BERTlarge로 구현되고, RAG 기반의 Hugging Face 모델을 사용했습니다. 최적화에는 AdamW 옵티마이저와 FAISS 라이브러리가 활용되었습니다.
- 비교 대상: GPT-2 및 BART 모델과 비교 실험이 진행되었습니다.
4.2 자동 평가
- 평가 지표: chrF++, BLEU, ROUGE-1, ROUGE-2, ROUGE-L, BERTscore 등이 사용되었습니다.
- 성과: INFO 모델은 18% 이상의 성능 향상을 보였고, 지식 및 페르소나 정확도에서 기존 모델 대비 크게 우수했습니다.
4.3 인간 평가
- 평가 기준: 유창성, 적합성, 원천 지식 활용도, 참여도, 환각 여부로 평가되었으며, INFO는 모든 항목에서 가장 높은 평가를 받았습니다. 특히 환각이 가장 적은 모델로 평가되었습니다.
5. 결과 분석
- Poly-Encoder와 RAG 비교: INFO는 Poly-Encoder보다 RAG 기반 모델이 더 정확한 문장 생성을 지원했으며, 환각을 줄이고 페르소나와 지식을 잘 반영했습니다.
5.2 리트리버 비교
- INFO의 리트리버 성능: INFO는 TF-IDF 및 DPR보다 더 우수한 문서 검색 성능을 보여주었습니다. 특히 문맥에 맞는 문서를 더 잘 찾아냈습니다.
5.3 선택 모듈 효과
- 선택 모듈의 영향: INFO는 지식과 페르소나의 선택에 따라 성능이 다소 달라졌지만, 페르소나 선택 성능에 개선의 여지가 있다고 분석되었습니다.
6. 결론
- INFO의 장점: 외부 지식과 페르소나 정보를 결합한 대화형 에이전트로서, 최첨단 성능(SoTA)을 달성했으며, 환각을 줄이고 참여도를 높이는 데 성공했습니다.
7. 한계
- 제한점: INFO는 현실 세계의 응용에서 제한적일 수 있으며, 고비용의 GPU 자원이 필요합니다. 미래 연구에서는 오픈 도메인 및 실제 환경에서의 성능을 확장하고 효율성을 개선하는 연구가 필요합니다.
이 요약을 통해 논문의 핵심 내용과 실험 결과, 한계점을 쉽게 파악할 수 있습니다.