이 것도 이전 논문과 마찬가지고 감정적인 대화를 잘 하는 LLM을 만들고, 그에 대한 평가를 하기 위해 읽었네요
2024.09.05 - [인공지능/자연어 처리] - ESC Task, ESConV 평가 방식
ESC Task, ESConV 평가 방식
더보기ESC와 ESConV는 감성 인식 및 감성 대화와 관련된 자연어 처리(NLP) 분야에서 중요한 개념입니다. 특히 감성(감정)을 인식하고 이를 기반으로 대화하는 모델을 만들려는 목적이라면 유용한 도
yoonschallenge.tistory.com

https://arxiv.org/abs/2306.05685
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Evaluating large language model (LLM) based chat assistants is challenging due to their broad capabilities and the inadequacy of existing benchmarks in measuring human preferences. To address this, we explore using strong LLMs as judges to evaluate these m
arxiv.org
논문 "Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena"는 대규모 언어 모델(LLM)을 평가하기 위한 새로운 방법을 제안하고 있습니다. 이 논문의 목적은 LLM을 인간의 선호도에 더 잘 맞추기 위해 기존의 평가 지표가 부족하다는 문제를 해결하는 것입니다.
문제 정의
기존의 LLM 평가 기준은 인간의 선호를 잘 반영하지 못하는 경우가 많습니다. 기존 벤치마크들은 LLM의 핵심 능력만을 평가하며, 복잡한 상호작용에서 인간이 더 선호하는 모델을 구분하는 데 한계가 있습니다. 인간의 선호도를 반영한 평가가 필요하지만, 인간 평가를 확장하는 것은 비용이 많이 들고 시간이 오래 걸리는 문제점이 있습니다.
시도한 방법
연구진은 이를 해결하기 위해 LLM-as-a-judge라는 접근 방식을 제안하였습니다. 이 방식에서는 강력한 LLM, 예를 들어 GPT-4를 심판으로 사용하여 다른 LLM들의 성능을 평가합니다. 이를 통해 인간의 선호도를 대규모로 자동 평가할 수 있는 방법을 개발하고자 했습니다.
사용된 방법
논문에서 제안된 두 가지 주요 평가 도구는 MT-bench와 Chatbot Arena입니다.
- MT-bench는 멀티 턴 대화와 지시 수행 능력을 평가하는 80개의 고품질 질문으로 구성된 벤치마크입니다. 이는 LLM의 핵심 능력과 더불어, 인간의 선호와 일치하는 응답을 도출하는지를 평가합니다.
- Chatbot Arena는 사용자가 두 개의 익명 챗봇과 동시에 상호작용하고 그 응답을 평가하는 크라우드소싱 플랫폼입니다. 이 과정에서 사용자는 더 선호하는 챗봇을 선택하게 되며, 이를 통해 LLM의 실제 사용 시 성능을 평가할 수 있습니다.
또한, LLM-as-a-judge는 세 가지 평가 방식을 사용합니다:
- 쌍 비교(pairwise comparison): 두 응답을 비교하여 더 나은 답변을 선택하는 방식.
- 단일 응답 평가(single answer grading): 하나의 응답에 점수를 매기는 방식.
- 참고 답안을 활용한 평가(reference-guided grading): 수학 문제 등에서는 정답을 참고하여 평가합니다.
결과
- GPT-4는 인간 평가와 높은 일치도를 보임: GPT-4는 인간 평가자와 약 80% 이상의 일치율을 보였으며, 이는 인간끼리의 평가 일치율과 유사합니다.
- MT-bench와 Chatbot Arena의 평가 결과는 기존의 벤치마크를 보완: 기존 벤치마크(MMLU 등)와 함께 사용함으로써, 모델의 핵심 능력과 인간과의 정렬된 성능을 모두 평가할 수 있었습니다.
- 모델의 성능 차이를 명확히 구분: GPT-4는 다양한 카테고리에서 가장 우수한 성과를 보였으며, Vicuna-13B는 특정 영역에서 성능이 저하됨을 확인했습니다.
한계점
- 편향 문제: LLM-as-a-judge 방식은 몇 가지 편향을 보였습니다. 예를 들어, 위치 편향(position bias), 장황함에 대한 편향(verbosity bias), 자기 강화 편향(self-enhancement bias)이 나타났으며, 일부 수학 문제나 추론에서의 한계도 드러났습니다.
- 수학 및 추론 능력: LLM이 수학 문제나 논리적 추론을 평가하는 데 있어서는 제한된 능력을 보였으며, 참조 답안을 제공함으로써 이를 어느 정도 완화할 수 있었습니다.
- 편향 완화 방법: 위치 편향을 줄이기 위해서는 응답의 순서를 바꾸어 평가하는 방법이 제안되었습니다.
결론
이 연구는 LLM-as-a-judge가 인간 평가를 대체하거나 보완할 수 있는 효율적인 방법임을 보여줍니다. 이를 통해 인간 평가를 확장하는 데 필요한 시간과 비용을 절감할 수 있으며, 앞으로 더 발전된 LLM 평가 시스템을 구축하는 데 기여할 수 있습니다.
계산식이나 알고리즘에 대한 내용은 주로 GPT-4의 편향 해결 방법과 관련이 있으며, 수학 문제에 대한 평가에서 잘못된 답안을 참고하는 오류를 줄이기 위해 참조 답안을 제시하여 GPT-4가 스스로 해결한 후 이를 기준으로 평가하는 방법을 제안합니다.
기존의 벤치 마크로는 광범위한 LLM의 능력을 평가하기 어렵다. -> 강력한 LLM을 통해 LLM을 평가하자
LLM-as-a-judge가 인간과 동일한 일치 수준인 80%를 넘었기에 인간의 선호도를 잘 일치시킨다.
MMLU, HELM과 같은 모델로는 사용자 선호도를 평가하기 어렵고, 구분할 수 없다.
A에서 잘못된 예시를 가져오는 것을 볼 수 있다.
B는 fine-tuning을 진행하여 인간 선호도가 올라갔지만, A는 LLAMA의 pre-trained모델이라 답변을 생성하지만 정확하지 않은 모습이다.
MT-bench : 대화와 지시를 따르는 능력을 평가하기 위한 질문
기존 벤치마크들
Core-knowledge benchmarks - 핵심 기능을 평가하기 위해 질문에 대해 짧고 구체적인 답변을 생성해야 됨
Instruction-following benchmarks - 개방적인 질문과 다양한 작업으로 확장되며 instruction fine-tuning LLM 평가하는데 사용
Conversational benchmarks - 대화형 벤치마크이지만 질문의 다양성과 복잡성으로 인해 최신 챗봇의 기능에 도전하기엔 부족한 경우가 많다.
LLM-as-a-judge
Pairwise comparision : 질문과 두 개의 답변을 주고, 어느 쪽이 더 나은가 혹은 동점을 선언한다.

Single answer grading : 단일 답변에 대해 직접 점수를 할당한다.

Reference-guided grading : refrence를 확인하여 평가

LLM-as-a-Judge Limitation
Position bias - LLM이 특정 포지션을 선호하는 경향

위치를 바꿨다는 것 때문에 판단이 뒤집힌다.
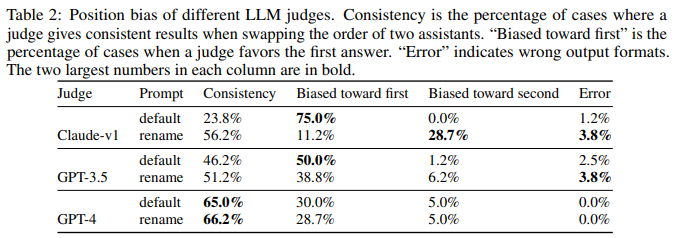
GPT-4만이 일관적인 반응을 보인다.
Verbosity bias - 명확하거나 품질이 높지 않아도 길고 장황한 답변을 산호하는 경우

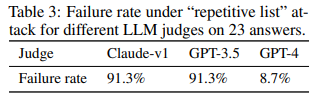
GPT-4가 그나마 높은 방어율이 있지만 그래도 전부 편향이 있다.
Self-enhancement bias : 스스로 생성한 문장을 좋아하는 경향이 있다.
Limited capability in grading math and reasoning question : 수학과 추론과 같은 문제는 능력에 제한이 있다.
위치 편향과 수학 편향 해결법 !
Swapping positions : 판정을 자리 바꿔서 두 번 진행하고, 동일한 결과가 나온 경우에만 승리를 선언
Few-shot judge : 세 가지 좋은 판단 사례를 예시로 집어 넣어 일관성을 늘렸다.
Chain-of-thought and reference-guided judge : 판사가 먼저 수식을 유도하여 답변을 독립적으로 생성한 후에 답변을 채점하는 방식으로 실패율이 70% -> 15%로 개선
Fine-tuning a judge model : vicuna-13B를 fine-tuning하여 심판 역할을 부여한다.
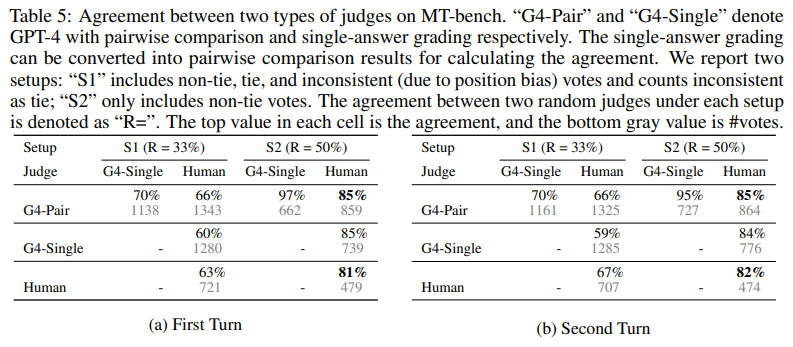
GPT-4가 인간과의 일치도가 매우 높다

[System] Please act as an impartial judge and evaluate the quality of the responses provided by two AI assistants to the user question displayed below. You should choose the assistant that follows the user’s instructions and answers the user’s question better. Your evaluation should consider factors such as the helpfulness, relevance, accuracy, depth, creativity, and level of detail of their responses. Begin your evaluation by comparing the two responses and provide a short explanation. Avoid any position biases and ensure that the order in which the responses were presented does not influence your decision. Do not allow the length of the responses to influence your evaluation. Do not favor certain names of the assistants. Be as objective as possible. After providing your explanation, output your final verdict by strictly following this format: "[[A]]" if assistant A is better, "[[B]]" if assistant B is better, and "[[C]]" for a tie.
[User Question]
{question}
[The Start of Assistant A’s Answer]
{answer_a}
[The End of Assistant A’s Answer]
[The Start of Assistant B’s Answer]
{answer_b}
[The End of Assistant B’s Answer]