https://arxiv.org/abs/2406.04093
Scaling and evaluating sparse autoencoders
Sparse autoencoders provide a promising unsupervised approach for extracting interpretable features from a language model by reconstructing activations from a sparse bottleneck layer. Since language models learn many concepts, autoencoders need to be very
arxiv.org
Sparse Autoencoder를 지속적으로 하긴 하지만 뭔가 확실하게 알고 하는 느낌이 아니라서 읽어 보았습니다.

Dead feature - 현 l1 정규화를 통한 sparse autoencoder 학습은 수 많은 dead feature를 만든다.( 90%)
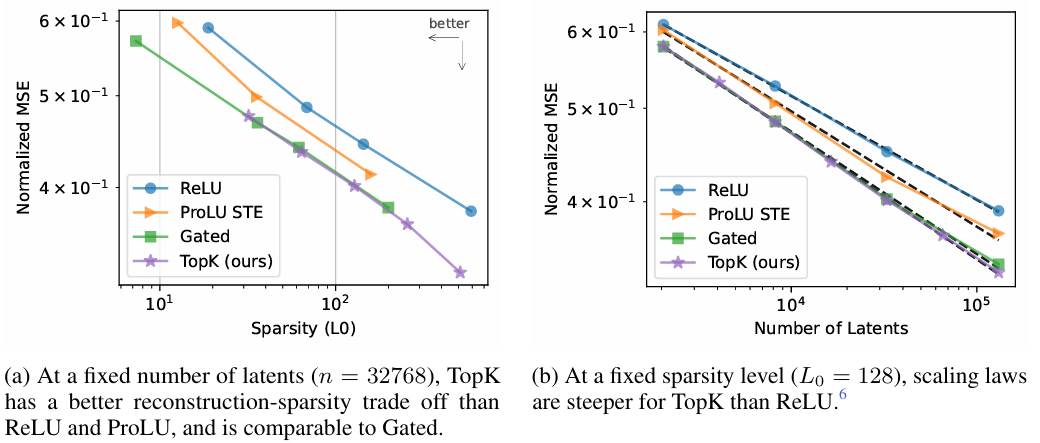
MSE만을 낮추는 것은 latent space가 큰 모델에서는 쉽다 --> 다른 평가, loss 방식이 필요함
Irreducible Loss를 도입하여 품질 향상

평가 방식
1. Downstream loss : SAE로 인한 언어 모델의 손실
2. Probe loss : feature를 잘 잡아내는지
3. Explainability : Latent space가 잘 설명되는지
4. Ablation sparsity : latent space에 feature 몇개를 죽이면 효과가 있는지
Chain of Thought 방식으로 요약:
- 문제가 무엇인지
Sparse Autoencoders(SAE)는 언어 모델에서 해석 가능한 특징을 추출하기 위한 잠재력을 가진 비지도 학습 방법입니다. 하지만, 언어 모델이 많은 개념을 학습하기 때문에 모든 관련된 특징을 복원하려면 매우 큰 오토인코더가 필요합니다. 이 과정에서 복원과 희소성 목표 간의 균형을 맞추는 문제와 'dead latents'(활성화되지 않는 잠재 변수) 문제로 인해 학습이 어렵습니다. - 어떤 방법을 시도했는지
이 논문에서는 이러한 문제를 해결하기 위해 k-sparse autoencoders (k-SAE)를 사용하여 희소성을 직접 제어하는 방법을 제안했습니다. 이는 튜닝을 단순화하고 복원-희소성 경계를 개선합니다. 또한, 대규모에서도 'dead latents' 문제를 해결하기 위한 여러 가지 수정 방법을 제시합니다. - 어떤 방법을 사용했는지
- k-Sparse Autoencoders: k-SAE는 활성화된 잠재 변수를 k개로 제한하는 방법입니다.
- TopK 활성화 함수: 희소성 제어를 위해 TopK 활성화 함수를 사용하여 가장 큰 k개의 값을 남기고 나머지를 0으로 처리합니다. 이 방식으로 L1 규제 없이도 희소성을 유지할 수 있습니다.
- Scaling Laws: 오토인코더의 크기와 희소성, 언어 모델 크기에 따른 확장 법칙을 연구했습니다. 16 million 개의 잠재 변수를 가진 오토인코더를 GPT-4 잔차 스트림에서 학습하여 이 방법의 확장성을 입증했습니다.
- 결과가 어떻게 나왔는지
제안된 방법을 사용하여 k-SAE는 희소성과 복원 능력 간의 균형을 더 잘 맞출 수 있었습니다. 대규모에서조차 dead latents 문제를 크게 줄였으며, 희소성, 설명 가능성, 다운스트림 효과 등의 새로운 평가 지표에서 향상된 결과를 보였습니다. 또한, 오토인코더의 크기가 커질수록 성능이 향상됨을 확인했습니다. - 한계점은 무엇인지
- TopK는 토큰마다 정확히 k개의 잠재 변수를 강제로 사용하기 때문에, 최적의 희소성을 달성하지 못할 가능성이 있습니다.
- 최적화는 더욱 개선될 수 있으며, 특히 dead latents 문제를 해결하기 위한 추가적인 보조 손실 등이 필요할 수 있습니다.
- 또한 GPT-4와 같은 대규모 모델의 모든 활성화를 충분히 해석 가능하게 만드는 것은 아직 도전 과제로 남아 있습니다.
주요 계산식:

결론적으로, 논문은 k-sparse 오토인코더를 확장 가능하고 해석 가능한 방식으로 설계 및 평가하는 방법을 제안하고, 이를 GPT-4 모델에 적용하여 우수한 성능을 보였습니다.
그럼 명확하게 방법론을 설명해줘
1. k-Sparse Autoencoders (k-SAE)
- 정의: k-SAE는 오토인코더에서 활성화된 잠재 변수를 k개로 제한하는 방식입니다. 일반적인 오토인코더는 입력 데이터를 잠재 공간(latent space)으로 압축하고, 복원하는 과정을 거칩니다. 그러나 k-SAE에서는 각 입력에 대해 k개의 활성화된 잠재 변수만 선택하여 사용하도록 강제합니다.
- 목적: 희소성을 유지하면서도 복원 능력을 극대화하는 것이 목표입니다. 희소성(sparsity)을 유지하면 모델이 더 해석 가능하게 되고, 데이터의 중요한 특징만을 학습할 수 있습니다.
- 기존 방법과의 차이점: 기존에는 L1 규제를 통해 희소성을 유지하려 했으나, 이는 활성화 값을 0에 가깝게 만드는 부작용이 있었습니다. 반면 k-SAE는 TopK 활성화 함수를 사용하여 희소성을 직접 제어함으로써 이러한 문제를 해결했습니다.
2. TopK Activation Function (TopK 활성화 함수)
- 정의: TopK 활성화 함수는 오토인코더에서 입력을 잠재 공간으로 변환한 후, 가장 큰 k개의 활성화 값만 남기고 나머지는 0으로 설정하는 방법입니다. 이는 활성화 함수가 선택적으로 중요한 정보만 남기고, 나머지는 무시하게 만드는 역할을 합니다.
- 수식: z=TopK(Wenc(x−bpre))
여기서 Wenc는 인코더 가중치, x는 입력, bpre는 프리 액티베이션 바이아스입니다. - 장점:
- L1 규제와 달리, 활성화가 0으로 축소되지 않으며, 직접적으로 k개의 활성화된 잠재 변수를 선택할 수 있습니다.
- L1 페널티 없이도 희소성을 유지하면서 더 나은 복원 성능을 제공합니다.
- Latent space의 과도한 축소를 방지하여 dead latents 문제를 줄일 수 있습니다.
3. Scaling Laws (확장 법칙)
- 목표: 다양한 오토인코더 크기, 희소성 수준(k 값), 그리고 언어 모델 크기와의 관계를 연구하여 최적의 모델 구조를 찾는 것입니다.
- 방법: 이 논문에서는 GPT-4와 같은 대형 언어 모델에서 활성화된 잔차(residual) 스트림 데이터를 사용하여, 16 million 개의 잠재 변수를 가진 오토인코더를 학습했습니다. 이 과정에서, 복원 오차와 희소성 간의 관계를 설명하는 확장 법칙(scaling laws)을 발견했습니다.
- 결과: 오토인코더의 크기와 희소성(k 값)에 따라 복원 성능이 어떻게 변하는지, 그리고 모델 크기가 클수록 더 많은 잠재 변수가 필요하다는 결론을 도출했습니다. 이를 통해 더 큰 언어 모델에서도 k-SAE를 효율적으로 확장할 수 있음을 확인했습니다.
4. Dead Latents 문제 해결
- Dead Latents 문제: 오토인코더를 학습하는 과정에서 일부 잠재 변수(latent)가 계속해서 활성화되지 않아, 학습이 비효율적으로 이루어질 수 있습니다.
- 해결 방법:
- 인코더 초기화를 디코더의 전치 행렬로 설정하여 초기 학습 시에 잠재 변수가 잘 활성화되도록 유도합니다.
- 보조 손실(auxiliary loss)를 추가하여, 활성화되지 않은 잠재 변수가 복원 오차에 기여하도록 유도합니다. 즉, 학습 도중 활성화되지 않은 잠재 변수들도 일정 비율로 활성화되도록 유도하여 dead latents 문제를 크게 줄였습니다.
- 이러한 기법을 통해 16 million 개의 잠재 변수를 가진 오토인코더에서도 dead latents 비율을 7%로 감소시켰습니다.
5. 평가 및 성능 지표
- 복원 성능(MSE): 오토인코더의 핵심 목표는 입력 데이터를 얼마나 잘 복원할 수 있는가입니다. 이를 측정하기 위해 MSE(Mean Squared Error)를 사용하였으며, k-SAE는 기존 방법들보다 더 나은 복원 성능을 보여주었습니다.
- 희소성 평가: L0 노름(실제 활성화된 잠재 변수의 수)을 사용하여 희소성을 평가했습니다.
- 다운스트림 성능: 복원된 잠재 변수를 언어 모델에 다시 입력했을 때, 해당 언어 모델의 성능이 어떻게 변하는지도 평가되었습니다. k-SAE는 복원 성능뿐만 아니라 다운스트림 성능에서도 우수한 결과를 보였습니다.
이 논문에서 사용된 방법론들은 기존의 sparse autoencoder 학습에서 발생하는 문제점을 해결하면서도 확장 가능성을 입증한 중요한 기법들로, 특히 TopK 활성화 함수와 dead latents 문제 해결을 위한 보조 손실이 핵심적인 역할을 합니다.
여기서 말하는 scailing Law는 뭐지??
논문에서 다루는 확장 법칙(Scaling Laws)는 Sparse Autoencoder(SAE)와 관련된 여러 요소들(오토인코더의 크기, 희소성 수준(k 값), 언어 모델의 크기)사이의 관계를 체계적으로 분석한 것입니다. 이 법칙들은 SAE의 성능을 예측하고, 모델의 크기나 복잡도를 증가시킬 때 어떤 변화가 일어나는지를 설명하는 중요한 개념입니다.
1. Scaling Laws의 목적
- 오토인코더 크기, 희소성, 언어 모델 크기와의 관계 연구: 이 논문의 주요 목표는 오토인코더가 얼마나 크고, 얼마나 많은 잠재 변수(latents)를 사용할 때, 효율적으로 언어 모델의 잔차(residual) 스트림을 복원할 수 있는지에 대한 관계를 수립하는 것입니다. 이는 더 큰 언어 모델(GPT-4 등)을 다룰 때, 오토인코더가 얼마나 확장 가능해야 하는지에 대한 중요한 정보를 제공합니다.
2. Scaling Laws의 구체적인 방법
확장 법칙은 두 가지 주요한 방식으로 오토인코더를 확장시키는 패턴을 설명합니다:
- Compute-MSE Frontier:
- 주어진 계산 자원 내에서, 얼마나 복원 오차를 최소화할 수 있는지를 설명하는 확장 법칙입니다.
- 계산 자원이 증가함에 따라 복원 오차(MSE)가 어떻게 변화하는지 분석합니다. 이는 주로 L(C)로 표현됩니다. 즉, 주어진 계산량 C에 대해 복원 오차는 특정한 비율로 감소합니다. 여기서 L(C)=αC^(−β)와 같은 형태의 파워 법칙을 따릅니다.
- 하지만, 이 접근법은 다소 제한적일 수 있습니다. 왜냐하면 오토인코더의 잠재 변수들이 크기가 다르면, 더 많은 정보를 담고 있어 쉽게 복원 오차를 줄일 수 있기 때문에 MSE만으로는 완전한 비교가 불가능하기 때문입니다.
- Convergence Scaling:
- 오토인코더가 수렴(convergence)할 때까지 훈련하는 방식으로, 최적의 복원 성능을 달성할 때까지 필요한 토큰의 수(token budget)와 오토인코더의 잠재 변수 크기 사이의 관계를 설명합니다.
- 이 방식에서는 오토인코더의 크기가 커질수록 더 많은 토큰을 사용해야 한다는 결론을 도출했습니다. GPT-2 small 모델에서는 Θ(n^0.6), GPT-4에서는 Θ(n^0.65) 정도의 토큰이 필요하다는 결과를 확인했습니다.
3. Scaling Laws의 수식 및 적용
- Compute-MSE 법칙:
L(C)=αC^(−β)+e
여기서 L(C)는 복원 오차, C는 계산량, α와 β는 상수, e는 irreducible loss (더 이상 줄일 수 없는 손실)입니다. 계산량이 증가할수록 복원 오차가 감소하는 파워 법칙을 따릅니다. - Joint Scaling Law:
L(n,k)=exp(α+βklog(k)+βnlog(n)+γlog(k)log(n))+exp(ζ+ηlog(k))
이 수식은 복원 오차가 오토인코더의 잠재 변수 수 n과 활성화된 잠재 변수 수 k에 따라 어떻게 변화하는지를 설명합니다. α, βk, βn, γ, ζ, η는 각각의 상수 값입니다.- 이 법칙에 따르면, 잠재 변수의 수 n이 커질수록, 그리고 활성화된 잠재 변수 수 k가 많을수록 복원 오차가 감소하지만, k 값이 너무 커질 경우 복원 오차는 오히려 증가할 수 있습니다.
4. Scaling Laws의 결과
- 오토인코더 크기와 잠재 변수 수: 오토인코더의 크기(잠재 변수 수)가 커질수록 복원 성능(MSE)이 개선되며, 특히 큰 언어 모델(GPT-4 등)의 경우 더 많은 잠재 변수가 필요합니다.
- 희소성(k 값)과의 관계: k 값이 적정 수준에서는 복원 성능을 크게 향상시키지만, 가 너무 커지면 잠재 변수가 과도하게 활성화되어 복원 오차가 증가할 수 있습니다.
- 모델 크기와의 관계: 더 큰 언어 모델에서는 더 많은 잠재 변수가 필요하며, n이 증가할수록 학습 속도가 느려지지만, 복원 성능은 꾸준히 개선됩니다.
5. Scaling Laws의 의미
이 확장 법칙은 SAE의 성능을 이론적으로 예측하고, 큰 언어 모델에서 효율적인 복원을 위한 오토인코더의 구조 설계에 중요한 가이드를 제공합니다. 특히, 오토인코더의 크기를 적절히 조정하고, 희소성 수준을 최적화함으로써 대규모 언어 모델에서도 뛰어난 복원 성능을 유지할 수 있음을 보여줍니다.
6. 한계점
- 이 법칙들은 특정한 범위 내에서만 유효하며, 극단적인 경우(예: k 값이 너무 크거나, 너무 작은 경우)에는 적용되지 않을 수 있습니다.
- 또한, 학습 속도나 계산량을 최적화하는 문제는 여전히 남아 있으며, 이를 해결하기 위한 추가적인 연구가 필요합니다.
이 논문에서 제시된 Scaling Laws는 SAE를 더 큰 언어 모델에 적용할 때 모델 성능을 예측하고 최적화하는 데 중요한 도구입니다. 이 법칙을 통해 오토인코더의 크기와 희소성 간의 관계를 정량적으로 이해하고, 더 복잡한 모델에서 효과적으로 확장할 수 있는 방법을 제공합니다.
그럼 이 논문은 l1 coefficient로 학습을 하게 되면 가중치가 전부 죽는 경우가 생기고, mse가 덩달아 증가하기 때문에 그 영향을 낮추기 위해서 TopK방식을 활용하는 것이고, k가 너무 커지거나 작지 않은 적절한 숫자면 feature를 적절하게 잘 표현한다는 논문이네?
네, 정확히 이해하셨습니다!
이 논문의 핵심 내용은 L1 규제(L1 regularization)의 한계점을 해결하고자 하는 것입니다. 구체적으로, L1 규제는 가중치를 희소하게 만들기 위해 사용되지만, 그 부작용으로 인해 모든 활성화 값이 0에 가까워지는 현상(activation shrinkage)이 발생할 수 있습니다. 이로 인해 중요한 특징(feature)을 제대로 표현하지 못하고, 복원 성능(MSE)이 저하될 수 있습니다.
주요 포인트:
- L1 규제의 문제:
- L1 규제를 사용하면 활성화된 잠재 변수를 적게 유지할 수 있지만, 이로 인해 가중치가 지나치게 축소되는 부작용이 발생합니다. 결과적으로 복원 성능이 떨어지고, 모든 활성화 값이 0에 가까워지며 'dead latents'가 발생하는 문제가 생깁니다.
- TopK 방식의 도입:
- 이를 해결하기 위해, 논문에서는 TopK 활성화 함수를 도입했습니다. TopK 방식은 가장 큰 k개의 활성화 값만 유지하고 나머지를 0으로 만드는 방식으로, L1 규제를 사용하지 않고도 희소성을 유지할 수 있습니다.
- 이 방식은 가중치가 지나치게 작아지는 문제를 방지하고, 희소성(sparsity)과 복원 성능(MSE) 간의 균형을 잘 맞출 수 있도록 돕습니다.
- k 값의 중요성:
- k 값이 적절한 수준일 때, TopK 방식은 언어 모델의 특징을 잘 복원할 수 있습니다. k가 너무 작으면 중요한 특징을 충분히 표현하지 못할 수 있고, 반대로 k가 너무 크면 희소성이 떨어져 복원 성능이 저하될 수 있습니다.
- 논문에서는 다양한 실험을 통해 k 값과 오토인코더의 크기, 희소성 간의 관계를 정량적으로 분석했습니다. 이를 통해 적정한 k 값이 있을 때, 복원 성능이 최적화된다는 결론을 도출했습니다.
결론:
- L1 규제의 부작용을 극복하기 위해 TopK 활성화 함수를 사용하여 희소성을 직접 제어합니다.
- k 값이 적절한 수준이면, 복원 성능과 희소성 모두에서 뛰어난 성능을 보여줍니다.
- 이 논문은 특히 대규모 언어 모델(GPT-4 등)에서 TopK 방식을 사용하여 효율적인 복원을 수행할 수 있음을 보여주며, Scaling Laws를 통해 오토인코더 크기와 희소성 간의 관계를 설명합니다.
따라서, 논문은 L1 규제의 문제를 해결하면서도 대규모 언어 모델에서도 적용 가능한 효율적인 Sparse Autoencoder 학습 방법을 제시한 것입니다.
그런데 topk 방식은 학습이 조금 진행하기 이전 완전 초기 상황에서 부터 사용하면 문제가 생길 것 같은데 아니야?
여기서 그것에 대한 말은 없었어?
논문에서의 해결 방법:
논문에서는 TopK 방식을 학습 초기 단계부터 바로 적용하는 것에 대한 문제를 일부 해결하기 위한 방법도 제시하고 있습니다. 구체적으로 다음과 같은 방식을 통해 학습 초기 문제를 완화합니다:
- 인코더 초기화 방법:
- 인코더를 디코더의 전치 행렬로 초기화하여, 학습 초기에 인코더와 디코더 사이의 변환이 동일한 방향을 가리키게 만듭니다. 이로써 학습 초기에 TopK 방식이 적용되더라도, 잠재 변수가 비활성화되는 문제를 줄이고, 복원 성능이 크게 떨어지지 않도록 설계했습니다.
- Auxiliary Loss (보조 손실):
- **Auxiliary Loss(보조 손실)**를 추가하여, 학습 과정에서 활성화되지 않은 잠재 변수(dead latents)가 어느 정도 활성화되도록 유도합니다. 이 보조 손실은 학습이 진행되는 동안 활성화되지 않는 잠재 변수들의 복원 오류를 모델링하고, 이를 학습 과정에 반영합니다. 이를 통해 학습 초기에 너무 많은 잠재 변수가 죽는 문제를 줄이고, 학습 후반부에 더 나은 성능을 낼 수 있도록 보조합니다.
- TopK의 성숙도:
- 학습이 진행됨에 따라 TopK 방식이 점진적으로 더 적절한 활성화를 선택하게 됩니다. 초기에는 k 값이 모든 잠재 변수를 사용하지 않을 수 있지만, 학습이 진행되면서 중요한 특징을 중심으로 잠재 변수가 활성화되도록 유도됩니다.
논문에서의 직접적인 언급:
논문에서는 TopK 방식을 처음부터 사용함에 따른 문제를 직접적으로 명시하지는 않았지만, dead latents 문제를 줄이기 위한 보조 기법들을 도입하여 학습 초기 문제를 완화하고자 했습니다.
따라서, TopK 방식의 초기 학습 문제는 인코더와 디코더 초기화를 통해 어느 정도 해결되고, 보조 손실을 통해 비활성화된 잠재 변수들을 활성화하여 문제를 줄이려는 시도가 있습니다.
그런데 인코더를 디코더의 전치 행렬로 초기화 한다면 이 것 또한 디코더가 학습이 되어 있어야 하는거 아닌가?
맞습니다. 인코더를 디코더의 전치 행렬로 초기화한다는 것은 디코더가 이미 학습된 상태여야 할 것처럼 보일 수 있지만, 논문에서 제안하는 방식은 디코더가 학습되기 전에도 이 초기화 방법이 유용하다는 점을 강조합니다. 이 초기화 전략은 학습 초기에 인코더와 디코더 간의 변환을 일치시키고, 잠재 변수가 너무 일찍 죽는 문제를 방지하는 역할을 합니다.
논문에서 이 방법을 사용하는 이유:
- 초기 상태에서의 가중치 일치: 인코더를 디코더의 전치 행렬로 초기화하면, 인코더와 디코더 간의 관계가 학습 초기부터 어느 정도 일치하게 됩니다. 즉, 두 행렬이 서로를 상호 보완하는 방향을 가리키게 되어 학습 초기에 TopK 방식이 적용되더라도 중요한 정보가 너무 일찍 손실되는 것을 방지할 수 있습니다.
- 디코더의 초기화와 학습: 인코더를 디코더의 전치로 초기화한다고 해서 디코더가 이미 학습된 상태라는 것을 의미하지는 않습니다. 디코더와 인코더는 모두 학습 과정에서 함께 업데이트되며, 전치 행렬로 초기화하는 것은 학습 초기에 정보의 흐름을 안정화하고 dead latents 문제를 최소화하기 위한 초기 설정일 뿐입니다.
- 학습 과정에서의 동시 업데이트: 인코더와 디코더는 학습 초기부터 동시적으로 업데이트됩니다. 초기화는 학습을 시작하는 위치를 정의할 뿐이고, 이후 학습 과정에서 두 가중치 행렬은 점진적으로 더 나은 방향으로 조정됩니다.
디코더가 학습되지 않아도 가능한 이유:
- 디코더의 전치 행렬로 인코더를 초기화한다는 것은 학습을 돕기 위한 초기 조건일 뿐입니다. 학습이 시작되면, 디코더와 인코더는 서로의 가중치를 보완하면서 동시에 학습되어 최적의 복원 성능을 달성하게 됩니다. 학습 과정에서는 디코더가 이미 학습된 상태일 필요는 없고, 단지 초기 단계에서 잠재 공간(latent space)이 제대로 형성될 수 있도록 돕는 역할을 합니다.
결론적으로, 인코더를 디코더의 전치 행렬로 초기화하는 것은 학습 초기 단계에서 정보 손실을 줄이고 dead latents 문제를 완화하기 위한 전략이며, 디코더가 학습된 상태일 필요는 없습니다. 이 초기화 방식은 학습의 출발점을 설정하는 것으로, 학습이 진행됨에 따라 인코더와 디코더가 함께 조정됩니다.
논문을 읽고 정리한 평가 방식인데 이게 맞아??
평가 방식
1. Downstream loss : SAE로 인한 언어 모델의 손실
2. Probe loss : feature를 잘 잡아내는지
3. Explainability : Latent space가 잘 설명되는지
4. Ablation sparsity : latent space에 feature 몇개를 죽이면 효과가 있는지
네, 정리한 평가 방식이 전반적으로 맞습니다. 각 항목에 대해 조금 더 자세히 설명드리면, 논문에서 다루는 평가 방식은 Sparse Autoencoder(SAE)의 성능을 다각도로 평가하는 방법입니다. 각 방식은 SAE가 복원 성능뿐만 아니라 모델의 해석 가능성과 실제 유용성에 미치는 영향을 측정하는 데 중점을 둡니다.
1. Downstream Loss
- 정의: 복원된 잠재 변수가 언어 모델에 다시 입력되었을 때, 그 언어 모델의 예측 성능에 미치는 영향을 측정하는 지표입니다.
- 목적: 복원된 잠재 변수가 언어 모델의 성능에 큰 영향을 미치지 않고, 원래의 성능을 잘 유지하는지를 확인합니다. 주로 Kullback-Leibler(KL) divergence와 cross-entropy loss를 사용해 평가됩니다.
- 핵심: SAE가 복원한 값으로 인해 언어 모델의 예측 성능이 크게 변하지 않도록 하는 것이 목표입니다. 즉, SAE로 인해 손실이 얼마나 증가하는지를 측정하는 것입니다.
2. Probe Loss
- 정의: 특정 특징(feature)를 SAE가 얼마나 잘 복원했는지를 측정하는 지표입니다. 각 잠재 변수(latent)에 대해 1D 로지스틱 회귀를 적용해 이 특징을 잘 분류할 수 있는지 확인합니다.
- 목적: SAE가 잠재 공간에서 우리가 기대하는 특정 특징(예: 감정, 주제 등)을 잘 잡아내는지를 평가합니다.
- 핵심: SAE가 학습한 잠재 변수들이 의미 있는 특징을 얼마나 잘 포착하는지, 그리고 이를 통해 특징을 얼마나 정확하게 예측할 수 있는지를 확인합니다.
3. Explainability (설명 가능성)
- 정의: 각 잠재 변수가 쉽게 설명 가능한 방식으로 활성화되는지, 즉 latent space가 해석 가능한지를 평가하는 지표입니다. 주로 Neuron to Graph (N2G) 방식 등을 사용해, 잠재 변수들이 간단한 규칙(예: 특정 n-gram 패턴)으로 설명될 수 있는지를 분석합니다.
- 목적: 잠재 변수의 활성화가 직관적으로 해석 가능해야 하며, 특정 입력이 주어졌을 때 이 입력이 어떻게 잠재 공간에서 표현되는지를 쉽게 설명할 수 있어야 합니다.
- 핵심: 잠재 공간(latent space)이 복잡하지 않고, 쉽게 해석 가능한지를 확인합니다. 모델이 학습한 특징이 단순한 규칙으로 설명될 수 있는지 측정합니다.
4. Ablation Sparsity
- 정의: 특정 잠재 변수를 제거했을 때, 다운스트림 결과에 미치는 영향이 얼마나 희소(sparse)한지를 측정하는 지표입니다. 즉, 몇 개의 잠재 변수만 제거해도 모델의 예측이 크게 변하는지 평가합니다.
- 목적: 언어 모델의 예측에 큰 영향을 미치는 잠재 변수들이 매우 적고, 대부분의 잠재 변수는 상대적으로 중요하지 않다는 가정하에, 개별 잠재 변수를 제거했을 때 다운스트림 효과가 얼마나 희소한지를 측정합니다.
- 핵심: 잠재 변수를 삭제해도 언어 모델의 성능에 미치는 영향이 얼마나 작은지 확인하고, 잠재 공간에서 중요한 변수만 남아있도록 하는 것이 목표입니다.
보완 설명:
- Downstream Loss는 복원 성능을 확인하는 가장 직접적인 방법이고, Probe Loss와 Explainability는 SAE가 학습한 특징들이 실제로 유용하고 해석 가능한지를 확인하는 추가적인 지표입니다. Ablation Sparsity는 잠재 변수의 제거가 모델의 성능에 어떤 영향을 미치는지를 측정하여 잠재 공간의 효율성을 평가합니다.
따라서 정리한 내용은 전반적으로 정확하며, 각 평가 방식은 SAE의 성능을 복원 성능뿐만 아니라 해석 가능성과 실제 유용성 측면에서 다각도로 평가하려는 목적을 가지고 있습니다.