2024.07.23 - [인공지능/강화학습] - MATLAB/Simulink를 통한 강화학습 with Driving Scenario designer
MATLAB/Simulink를 통한 강화학습 with Driving Scenario designer
강화학습을 진행하면서 보상함수의 중요성에 대해 뼈져리게 느끼고 있네요 ㅎㅎ... 위 사진을 보시면 학습시간이 어마 무시하다는 것을 알 수 있습니다.다른 Fully Connected Layer를 기반으로 한 12k
yoonschallenge.tistory.com
이전에도 계속 작성했던 글인데 이제 슬슬 학습의 효과도 나고 있습니다.
아직 속도에 대해선 해결하지 못했지만 금요일에 MathWorks에서 오시는 분을 뵙기로 했으니 그 때 해결해보려고 합니다.
일단 학습 자체는 여러 구역을 탐험하며 잘 진행하였습니다.

마무리가 아쉽기는 하지만 그래도 도착도 여러 번 했고, 다양한 경험을 통해 얍삽하게 reward를 채우는 법도 알아냈죠...
대략 28시간 정도 걸렸고, 그래프에서 보이듯 400번의 에피소드가 반복되고 나서야 조금 학습했구나가 보였습니다....
그게 12시간 정도 걸린거죠......
강화학습의 어려운 점 인것 같습니다.

여기서 pos에 대한 reward를 수정했습니다.
다른 reward에 비해 과하게 크더라고여
마지막에 이상한 방향으로 탐험을 시작하는 바람에 영상 자체는 이상하게 나오긴 했지만 그래도 재학습하여 목표 지점에 도달하도록 만들면 멀쩡한 모습을 보일 것으로 기대하고 있습니다.
내일은 잘 도착하고, 또 다른 맵을 통해 학습한 모델을 가지고 오겠습니다.
동적 장애물을 진행할 예정이었는데 금요일에 학습 시작할 수 있겠네요

거의 막바지 단계입니다.

Reward Function에서는 관측값을 받아서 reward를 측정합니다. fail과 success에 대해서도 보상을 주고, 관측값에 대해서도 여러 보상을 만들어 자율주행을 좀 더 안전하게, 빠르게 도달하기 위해 노력하고 있습니다.

Agent에서 나온 Action은 차량 동역학 모델을 통해 속도, 위치, 각속도, Yaw값으로 변화합니다.
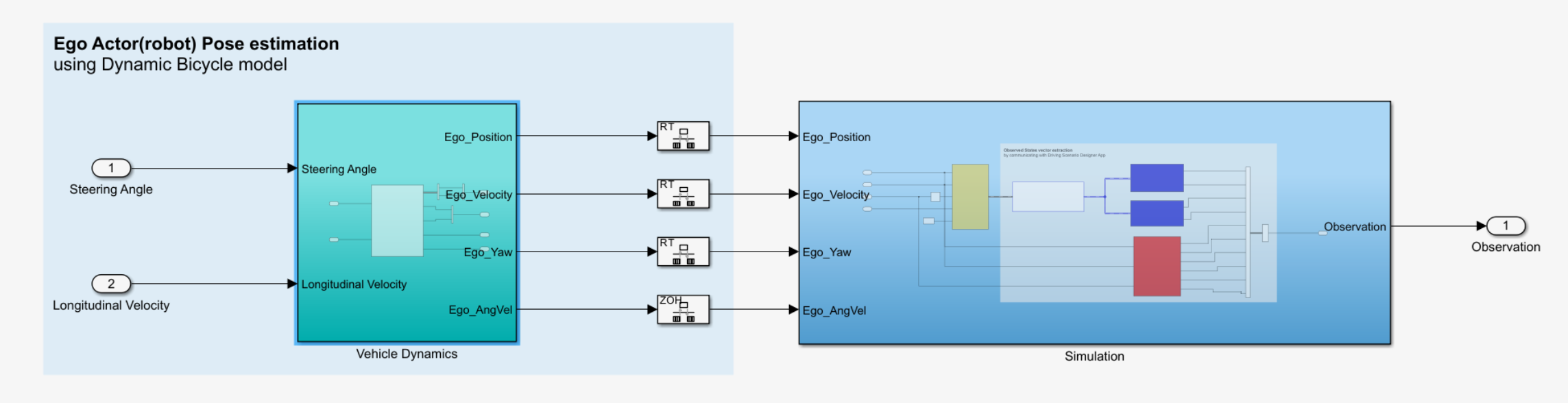
이 값이 그대로 simulation에 들어가면 simulation은 변화한 값에 따라 새로운 sensor 값을 보내주며 새로운 action을 유발하게 됩니다.

지금 막 재학습을 시작하여 아직은 좋은 모습을 보여주진 못하네요 ㅎㅎ...
내일은 좀 더 나은 모델을 가지고 다시 작성해보겠습니다.
'인공지능 > 강화학습' 카테고리의 다른 글
| matlab 강화학습 - Driving Scenario Designer을 활용한 AMR end to end 최종 (0) | 2024.08.06 |
|---|---|
| MATLAB/Simulink를 통한 강화학습 with Driving Scenario designer (0) | 2024.07.23 |
| 강화학습을 통한 실내 자율주행 로봇 만들기 첫 학습 matlab, simulink, driving scenario designer (0) | 2024.07.21 |
| AI 경진대회 - Scenario Reader와 RL Agent 묶기 (1) | 2024.07.20 |
| AI 경진대회 준비 - MATLAB ultrasonic 센서 오류 (0) | 2024.07.17 |