여태까지 진행했던 프로젝트의 끝이 났네요
학습하는데 1000시나리오에 20시간도 넘게 걸리니 도저히 완벽하고, 다양한 학습에서 진행할 순 없더라고요
그래도 한 시나리오는 완벽하게 끝내는 모델을 완성했습니다.
https://kr.mathworks.com/matlabcentral/fileexchange/170616-rl-based-amr-controller
RL-Based AMR Controller
Using Reinforcement learning, we implemented AMR controller with MATLAB/Simulink.
kr.mathworks.com
코드는 여기서 확인해 볼 수 있습니다.
https://www.youtube.com/watch?v=V8dMHNvj_tc
발표 영상입니다.. ㅎㅎ..

저희 목표였습니다.
센서 성능의 의존도와 개발 복잡도를 낮춰 효율적이고, 실시간 처리 성능을 높인 AMR을 만드는 것이 저희 강화학습 모델의 종착점입니다.

강화 학습 모델의 로직 다이어그램 입니다.
DDPG를 사용한 이유에는 연속적이고 복잡한 action 공간 처리에 유리하고, 정책과 critic의 장점을 결합하여 최적의 action을 도출하기에 사용하였습니다.
시뮬레이션을 사용한 이유는 매 에피소드 마다 에이전트의 행동을 시각화할 수 있어 수정을 즉각적으로 진행할 수 있으며 학습 환경을 유동적으로 변경할 수 있고, VILS 환경 학습보다 시간, 비용, 안전 문제에 뛰어나기 때문입니다.

그리하여 구성된 메인 모델입니다.
로봇 컨트롤러는 강화학습 부분으로 agent 입니다.
Environment는 관측 값을 출력하며 Reward Funcition은 관측값을 통해 Reward와 isdone을 출력합니다.
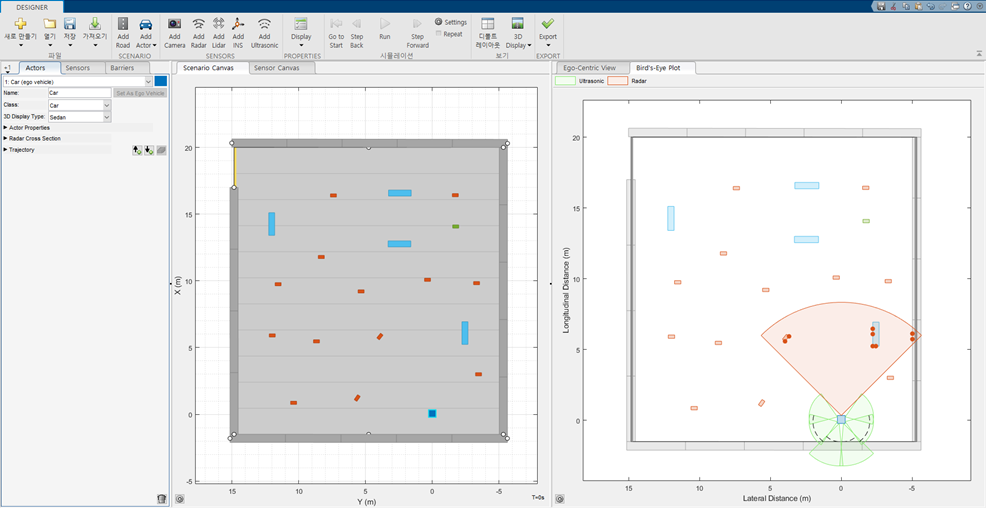
초기에 작성한 맵입니다.

빨간색이 Radar이고, 초록색이 UltraSonic 센서 입니다.

Env 내부 모습입니다.
agent에서 출력된 steering Angle과 Velocity를 동역학 모델에 맞추어 차량의 포지션 이동을 계산해줍니다.

Simulation 내부는 이렇게 되어 있습니다.
packEgo가 계산된 값을 버스로 묶어서 Scenario Reader에 보내주고, 그 값을 통해 라이다와 초음파 센서 값들이 변동되게 됩니다.
이 과정에서 모두 스케일링이 진행되고, 빨간 박스에선 오차도 계산 됩니다.
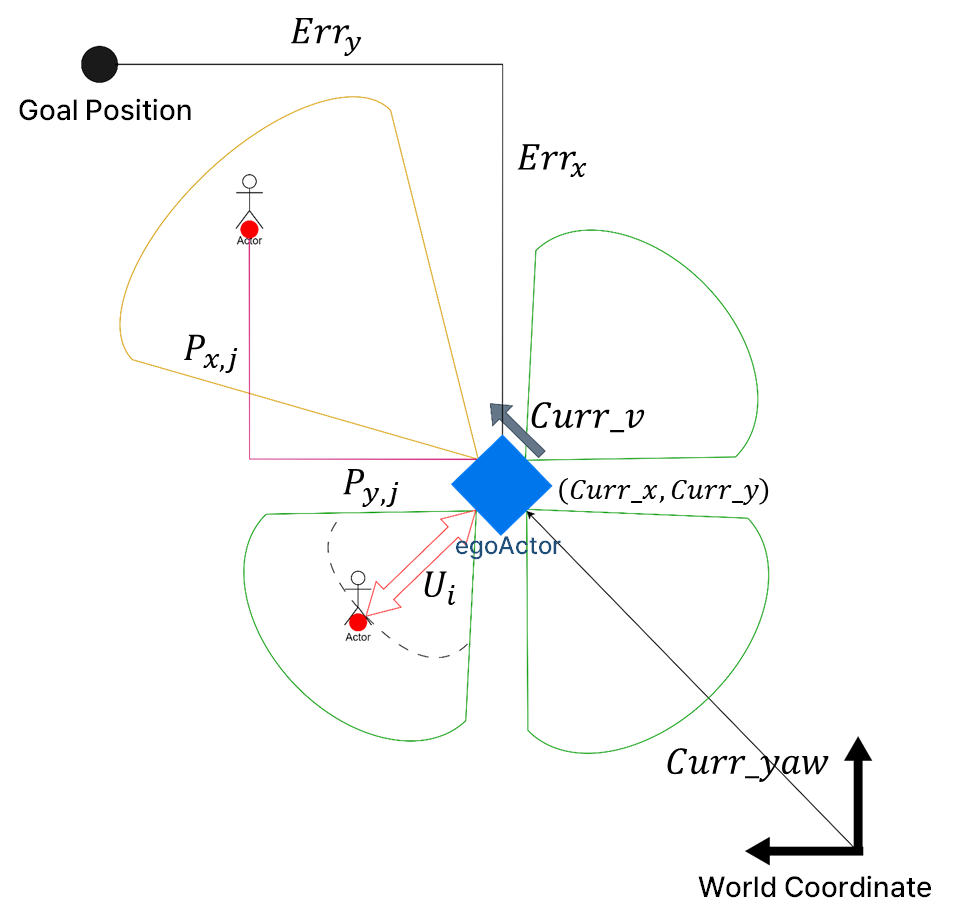
입력으로 사용된 관측값들 입니다.

위와 같이 쌓아서 들어갑니다. t-1 시점가지 고려하여 동적 물체도 잘 인식하도록 하였습니다.

Reward Function 내부입니다.

Success 로직으로 원 내부로 egeActor의 중심점이 들어가면 성공하게 됩니다.

fail 로직도 단순하게 일정 거리보다 가까워지면 fail로 isdone이 출력됩니다.
시간도 있었는데 시간에 따라 출력값이 달라지는 것을 보았습니다.

보상함수는 복잡한 과정을 거쳐서 생성하였습니다.
하나를 잘못 만들어도 예상치 못하는 결과를 가져왔기 때문에 스케일을 맞추고, 다양한 경우의 수를 생각하느라 애를 먹은 것 같네요 ㅎㅎ..

이게 대략 27시간 정도 걸렸씁니다.,...

이게 17초만에 도착한 모델입니다.
보상함수의 변동을 통해 33초가 걸리던 모델을 효과적으로 변동시킬 수 있었습니다.

속도 그래프를 보시면 마지막에 거의 속도를 내지 않은 것을 볼 수 있지만 agent를 업데이트하고 나서 일정한 속도로 계속 나아가는 것을 볼 수 있습니다.

추후 다양한 환경에서 활용하기 위해선 위와 같은 단계로 진행할 수 있고, 리소스가 확보된다면 다양한 모델을 다양한 환경에서 학습해보고 싶네요...
'인공지능 > 강화학습' 카테고리의 다른 글
| MATLAB/Simulink를 통한 자율 주행 로봇 강화학습 하기 (2) | 2024.07.24 |
|---|---|
| MATLAB/Simulink를 통한 강화학습 with Driving Scenario designer (0) | 2024.07.23 |
| 강화학습을 통한 실내 자율주행 로봇 만들기 첫 학습 matlab, simulink, driving scenario designer (0) | 2024.07.21 |
| AI 경진대회 - Scenario Reader와 RL Agent 묶기 (1) | 2024.07.20 |
| AI 경진대회 준비 - MATLAB ultrasonic 센서 오류 (0) | 2024.07.17 |