2024.07.22 - [소프트웨어] - LLaMa3 LoRA를 통해 parameter efficient fine-funing 진행하기 2(Matlab 도메인) - python
LLaMa3 LoRA를 통해 parameter efficient fine-tuning 진행하기 2(Matlab 도메인) - python
일단 저는 driving scenario tool box와 reinforcement learning에 대한 정보가 부족하기 때문에 그것에 대한 정보를 번갈아서 넣어 줄 예정입니다.url을 하나씩 남기면서 모아볼게요...아직 웹 크롤링은 잘 모
yoonschallenge.tistory.com
이전에 진행했던 내용이 아쉽게도 GPU용량 부족 때문에 진행하지 못해서 더 작은 모델을 생각해 봤습니다.
https://news.microsoft.com/source/features/ai/the-phi-3-small-language-models-with-big-potential/
Tiny but mighty: The Phi-3 small language models with big potential
A series of SLMs offer many of the same capabilities found in LLMs but are smaller in size and are trained on smaller amounts of data.
news.microsoft.com
이 글을 봐보시면
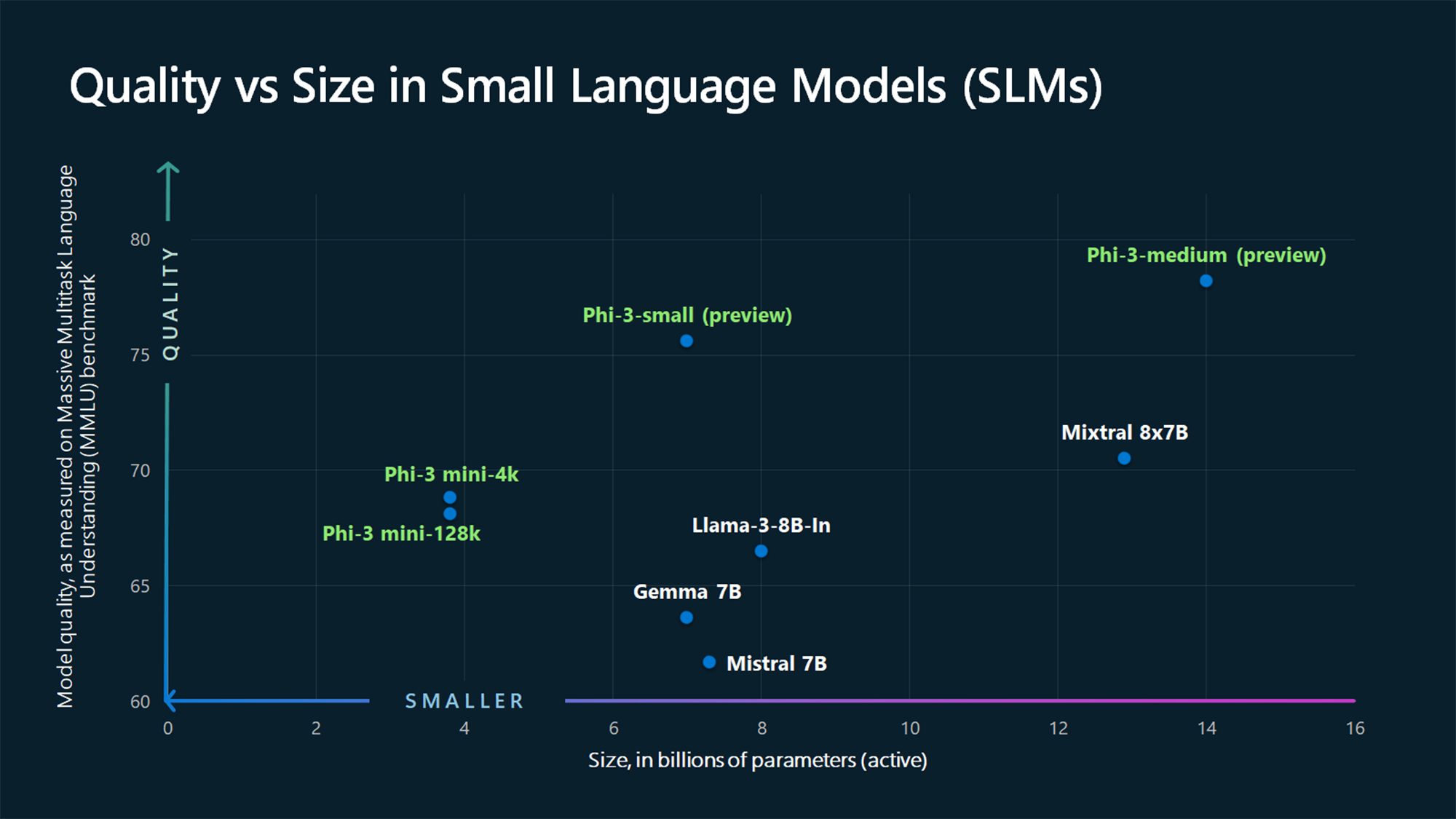
확실히 작지만 강력합니다
New models added to the Phi-3 family, available on Microsoft Azure | Microsoft Azure Blog
We are introducing Phi-3-vision, a multimodal model that brings together language and vision capabilities, now available on Microsoft Azure. Learn more.
azure.microsoft.com
LLaMa -3 8B보다 강력한 Phi-3 mini-4k를 사용해보려고 합니다.
일단 기존에 있는 데이터로 먼저 학습을 진행해보고, 이상하거나 마음에 들지 않으면 데이터를 늘려서 다시 한번 해보겠씁니다.
https://huggingface.co/collections/microsoft/phi-3-6626e15e9585a200d2d761e3
Phi-3 - a microsoft Collection
Phi-3 family of small language and multi-modal models. Language models are available in short- and long-context lengths.
huggingface.co
허깅페이스 주소는 여기 있습니다.
Fine-Tuning Phi-3 with Unsloth for Superior Performance on Custom Data:
Phi-3, a powerful large language model (LLM) from Microsoft AI, holds immense potential for various tasks. But to truly unlock its…
medium.com
이 사이트에서 참조를 했고
2024.07.21 - [인공지능/자연어 처리] - 자연어 처리 : LLaMa Pretrain하기 - python 실습
자연어 처리 : LLaMa Pretrain하기 - python 실습
https://docs.google.com/forms/d/e/1FAIpQLSfqNECQnMkycAp2jP4Z9TFX0cGR4uf7b_fBxjY_OjhJILlKGA/viewform?pli=1&pli=1 Request FormThank you for your interest in Meta AI’s LLaMA (Large Language Model Meta AI) models. To request access to the models, please fil
yoonschallenge.tistory.com
여기와 비슷한 방식으로 진행하지 않을 까 싶네요
아 왜 그냥 모델은 안주고 instruct모델만 나와있는지.....
일단 또 해결해보고 오겠습니다...
아
그냥 모델을 안주네요......
내일 또 다른 SLM을 가지고 다시 fine-tuning 해봐야겠네요...............................................................
여기 7B 이하의 파라미터를 가지고 있으며 코딩 작업에 적합한 성능을 보이는 소형 언어 모델(SLM) 10개를 소개합니다. 이 모델들은 공개되어 있으며 사용하기 쉬운 모델들입니다:
- GPT-3 Ada (OpenAI)
- 모델 크기: 약 2.7B 파라미터
- 추천 이유: 높은 코딩 정확도와 다양한 프로그래밍 언어에 대한 광범위한 이해. OpenAI의 API를 통해 쉽게 접근 가능.
- Codex (OpenAI)
- 모델 크기: 약 6B 파라미터
- 추천 이유: GPT-3 기반의 모델로, 코드 생성에 특화되어 있어 다양한 코딩 문제 해결에 효과적. API 사용이 용이.
- GPT-Neo (EleutherAI)
- 모델 크기: 1.3B 및 2.7B 파라미터 버전 존재
- 추천 이유: 공개 소스 모델로 쉽게 접근 가능하며, 코딩 작업에 비교적 좋은 성능을 보임.
- GPT-J (EleutherAI)
- 모델 크기: 6B 파라미터
- 추천 이유: 코드 생성 및 자연어 처리에서 뛰어난 성능을 보여주며, 오픈 소스로 제공되어 자유롭게 사용 가능.
- T5-Small (Google)
- 모델 크기: 60M 파라미터
- 추천 이유: 매우 작은 모델이지만 특정 코딩 작업에서는 좋은 성능을 보임. 공개된 모델로 사용하기 쉬움.
- CodeT5 (Salesforce)
- 모델 크기: 220M 파라미터 (Small 버전)
- 추천 이유: 코드 스니펫 생성 및 자동 완성에 특화되어 있으며, 공개된 모델로 접근성이 좋음.
- CodeBERT (Microsoft)
- 모델 크기: 125M 파라미터
- 추천 이유: 코드 검색과 코드-텍스트 관련 작업에 뛰어난 성능을 보이며, 공개된 모델로 사용이 용이.
- BART-Base (Facebook)
- 모델 크기: 140M 파라미터
- 추천 이유: 코드 요약 및 변환 작업에 효과적이며, 공개된 모델로 쉽게 접근 가능.
- mT5-Small (Google)
- 모델 크기: 300M 파라미터
- 추천 이유: 다국어 코딩 지원이 가능하며, 코드 생성 및 변환 작업에 적합. 공개된 모델로 사용이 용이.
- MiniLM (Microsoft)
- 모델 크기: 33M 파라미터
- 추천 이유: 매우 경량화된 모델로, 빠른 응답 속도가 요구되는 코딩 작업에 적합. 공개된 모델로 접근성이 좋음.
이 모델들은 각기 다른 특성과 장점을 가지고 있어, 사용자의 특정 필요에 따라 선택할 수 있습니다. 모두 공개되어 있어 사용이 용이하며, 특히 코딩 관련 작업에 좋은 성능을 보여 추천합니다.
https://huggingface.co/apple/DCLM-7B
apple/DCLM-7B · Hugging Face
Model Card for DCLM-Baseline-7B DCLM-Baseline-7B is a 7 billion parameter language model trained on the DCLM-Baseline dataset, which was curated as part of the DataComp for Language Models (DCLM) benchmark. This model is designed to showcase the effectiven
huggingface.co
이걸로 진행하겠습니다....
https://huggingface.co/HuggingFaceTB/SmolLM-1.7B
HuggingFaceTB/SmolLM-1.7B · Hugging Face
SmolLM Table of Contents Model Summary Limitations Training License Citation Model Summary SmolLM is a series of state-of-the-art small language models available in three sizes: 135M, 360M, and 1.7B parameters. These models are built on Cosmo-Corpus, a met
huggingface.co
'인공지능 > 자연어 처리' 카테고리의 다른 글
| 학습한 모델 시각화 하여 보기 깔끔하게 하기! - 모델 서빙하기 1 (0) | 2024.08.13 |
|---|---|
| python 실습 - Huggingface SmolLM fine-tuning 하기 with LoRA - matlab data (0) | 2024.07.25 |
| LLaMa3 LoRA를 통해 parameter efficient fine-tuning 진행하기 2(Matlab 도메인) - python (10) | 2024.07.22 |
| LLaMa3 LoRA를 통해 parameter efficient fine-tuning 진행하기 1(Matlab 도메인) - python (0) | 2024.07.22 |
| 자연어 처리 Python 실습 - Parameter Efficient Fine tuning (3) | 2024.07.22 |