https://huggingface.co/HuggingFaceTB/SmolLM-135M
HuggingFaceTB/SmolLM-135M · Hugging Face
SmolLM Table of Contents Model Summary Limitations Training License Citation Model Summary SmolLM is a series of state-of-the-art small language models available in three sizes: 135M, 360M, and 1.7B parameters. These models are built on Cosmo-Corpus, a met
huggingface.co
제가 사용한 모델입니다.
기존 모델들이 툭하면 GPU를 초과했다고 그래서.... 제일 작은 모델을 가져왔습니다.
일단 Matlab 도메인에 대해 먼저 물어봤었습니다.

많이 애매한 결과가 나왔습니다....
이건 학습이 안된 것으로 보입니다.
Matlab에 대해서만 알지 simulink와 그 내부 프로그램들은 하나도 모르네요
그래서 이전에 직접 받아온 데이터로 학습해주었습니다.
%pip install transformers
%pip install -U datasets
%pip install -U accelerate
%pip install -U peft
%pip install -U bitsandbytes
import pandas as pd
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig, TextDataset, DataCollatorForLanguageModeling,pipeline
from transformers import Trainer, TrainingArguments
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
device
checkpoint = "HuggingFaceTB/SmolLM-135M"
device = "cuda" # for GPU usage or "cpu" for CPU usage
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
# for multiple GPUs install accelerate and do `model = AutoModelForCausalLM.from_pretrained(checkpoint, device_map="auto")`
model = AutoModelForCausalLM.from_pretrained(checkpoint).to(device)
inputs = tokenizer.encode("def print_hello_world():", return_tensors="pt").to(device)
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))필요한 것들 다 설치하고, 모델을 불러 옵니다!
여기까지는 문제 없이 잘 됩니다. GPU 공간도 넉넉하고 모델이 작아서 너무 빨리 잘 됩니다.

토크나이저는 이런 출력을 하고 있습니다.
import os
from datasets import load_dataset
tokenizer.pad_token = tokenizer.eos_token
dataset = load_dataset('csv', data_files='/kaggle/input/572k-matlab-data/cleaned_matlab_data.csv')
if tokenizer.pad_token is None:
tokenizer.add_special_tokens({'pad_token': tokenizer.eos_token})
# 올바른 입력 형식으로 변환
def tokenize_function(examples):
return tokenizer(examples['Text'], padding='max_length', truncation=True,max_length = 128)
# 데이터셋을 매핑하여 토큰화
tokenized_dataset = dataset['train'].map(tokenize_function, batched=True, remove_columns=["Text"])제 데이터를 불러오고, 토크나이저를 통해 토큰화를 진행해줍니다.
from peft import get_peft_model, LoraConfig, TaskType
peft_config = LoraConfig(task_type=TaskType.CAUSAL_LM,
inference_mode=False, #학습시킬 것이기 때문에
r=32, # train할 파라미터의 수
lora_alpha=32,
lora_dropout=0.1)
model = get_peft_model(model, peft_config)
model.to(device)다른 파라미터들은 그대로 두고 RoLA를 통해 효율적인 파인튜닝을 진행하겠습니다.
PeftModelForCausalLM(
(base_model): LoraModel(
(model): LlamaForCausalLM(
(model): LlamaModel(
(embed_tokens): Embedding(49152, 576)
(layers): ModuleList(
(0-29): 30 x LlamaDecoderLayer(
(self_attn): LlamaSdpaAttention(
(q_proj): lora.Linear(
(base_layer): Linear(in_features=576, out_features=576, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=576, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=576, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(k_proj): Linear(in_features=576, out_features=192, bias=False)
(v_proj): lora.Linear(
(base_layer): Linear(in_features=576, out_features=192, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=576, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=192, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(o_proj): Linear(in_features=576, out_features=576, bias=False)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): LlamaMLP(
(gate_proj): Linear(in_features=576, out_features=1536, bias=False)
(up_proj): Linear(in_features=576, out_features=1536, bias=False)
(down_proj): Linear(in_features=1536, out_features=576, bias=False)
(act_fn): SiLU()
)
(input_layernorm): LlamaRMSNorm()
(post_attention_layernorm): LlamaRMSNorm()
)
)
(norm): LlamaRMSNorm()
)
(lm_head): Linear(in_features=576, out_features=49152, bias=False)
)
)
)모델은 이렇게 생겼습니다.

이렇게 보면 파라미터도 엄청나게 많네요
1.3%정도만 학습해서 최적의 fine-tuning을 진행할 수 있을 진 모르겠네요
# Prepare data collator
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False,
)
# Set training arguments
training_args = TrainingArguments(
output_dir='/mnt/data/model_output',
overwrite_output_dir=True,
num_train_epochs=3,
per_device_train_batch_size=2,
prediction_loss_only=True,
fp16=False, # Disable mixed precision for debugging
)
trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=tokenized_dataset,
)트레이너 정의도 해주고, epoch는 아무생각없이 3회나 반복했더라고요 ㅎㅎ..... 그건 잘못하긴 했고..
일단 3에폭 학습하는덴 GPU P100써서 16분 정도 걸렸습니다.
os.environ["CUDA_LAUNCH_BLOCKING"] = "1"
os.environ["WANDB_DISABLED"] = "true"이건 자꾸 이상한게 떠서 GPT한테 얻어냈네요
try:
trainer.train()
except RuntimeError as e:
print(f"RuntimeError: {e}")이렇게 학습을 진행했습니다!
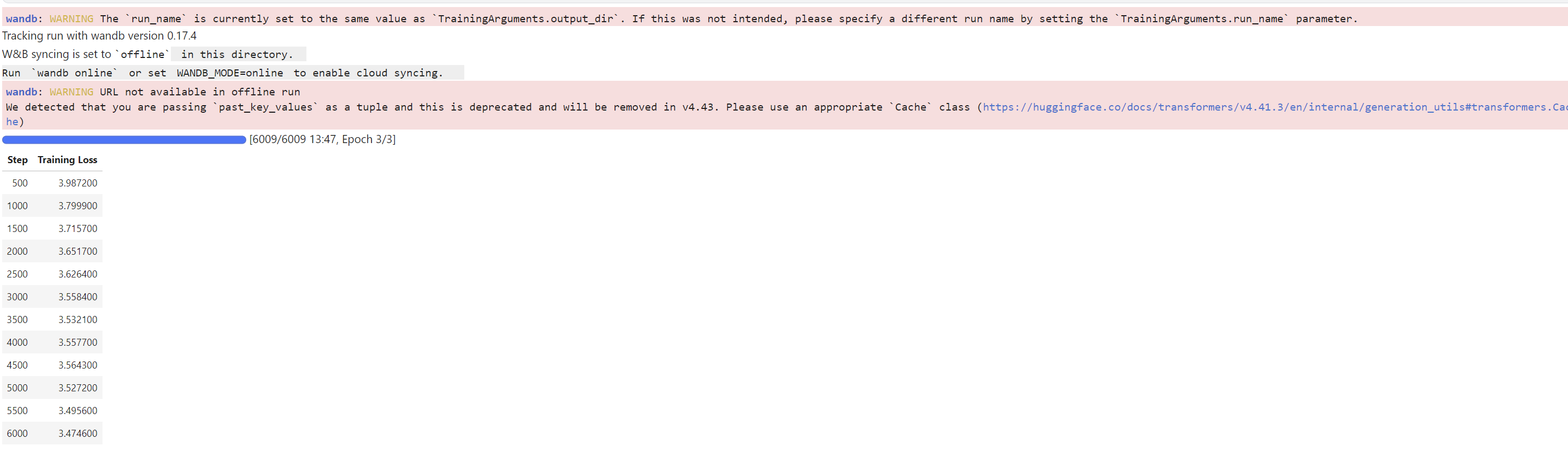
로스는 막 확확 줄어들지는 않네요

결과는 상당히 괜찮아 보였습니다.
matlab에 대해 물어봣을 땐 이상하지만 나머지에 대해서는 확실히 학습한 모습입니다.
이제 웹 스크롤링을 진행하고 있습니다.
import os
from urllib.parse import urljoin
import scrapy
from scrapy.crawler import CrawlerProcess
from scrapy.utils.log import configure_logging
from scrapy.utils.project import get_project_settings
class MathWorksSpider(scrapy.Spider):
name = "mathworks"
start_urls = ['https://nl.mathworks.com/']
custom_settings = {
'DOWNLOAD_DELAY': 1, # 1초 간격으로 요청을 보냄
'ROBOTSTXT_OBEY': False,
'DUPEFILTER_DEBUG': True,
'HTTPERROR_ALLOWED_CODES': [400, 403, 404, 500]
}
def parse(self, response):
page = response.url
self.log(f'Visiting: {page}')
# Extract and follow all links on the current page
for href in response.css('a::attr(href)').getall():
if href.startswith('mailto:'):
continue
url = urljoin(response.url, href)
if "mathworks.com" in url:
yield scrapy.Request(url, callback=self.parse)
# Save the page content
page_content = response.body.decode('utf-8')
page_path = response.url.replace('https://', '').replace('/', '_').replace('?', '_')
with open(f'data/{page_path}.html', 'w', encoding='utf-8') as f:
f.write(page_content)
# Append page content to a single text file
with open('data/combined_content.txt', 'a', encoding='utf-8') as f:
f.write(page_content)
f.write("\n" + "="*80 + "\n") # 페이지 구분을 위해 구분선 추가
if not os.path.exists('data'):
os.makedirs('data')
# Configure logging
configure_logging({'LOG_FORMAT': '%(levelname)s: %(message)s'})
settings = get_project_settings()
settings.update({
'LOG_LEVEL': 'INFO',
})
process = CrawlerProcess(settings)
process.crawl(MathWorksSpider)
process.start()이걸 미리 알았더라면 이전처럼 막 긁어서 복사하진 않았을텐데...
이게 생각보다 오래걸려서 이거 다 끝나면 내일 또 거대한 학습을 진행해보도록 하겠습니다.

생각보다 폴더 크기가 많이 커지네요...?
'인공지능 > 자연어 처리' 카테고리의 다른 글
| 학습한 모델 웹사이트 챗봇으로 시각화 하기! - 모델 서빙하기 2 (0) | 2024.08.14 |
|---|---|
| 학습한 모델 시각화 하여 보기 깔끔하게 하기! - 모델 서빙하기 1 (0) | 2024.08.13 |
| SLM Phi-3 활용해서 Parameter efficient fine-tuning 진행하기 (1) | 2024.07.23 |
| LLaMa3 LoRA를 통해 parameter efficient fine-tuning 진행하기 2(Matlab 도메인) - python (10) | 2024.07.22 |
| LLaMa3 LoRA를 통해 parameter efficient fine-tuning 진행하기 1(Matlab 도메인) - python (0) | 2024.07.22 |