1주 차 - 생성형 인공지능이란?
1차시 - CHAT GPT란?
Chat GPT == LLM : 언어모델(LM)을 더욱 확장한 개념으로 인간의 언어를 이해하고 생성하도록 훈련된 인공지능
GPT : 트랜스포머 Decoder 모델인 생성형 사전 학습 트랜스포머를 기반으로 한다.
G : Generative = 생성형
P : Pre-train = 사전 학습
T : Transformer = 자연어를 처리하는 딥러닝 기술, 글자럴 번역한다는 의미
GPT 이전엔 BERT이었고, 사용자의 텍스트(Query)를 기반으로 텍스트 응답을 형성한다.
인코더 : 외부의 글자를 인코딩한다. 학습할 때 사용
디코더 : 인코더 된 정보를 통해 생성.
Transformer Decoder 모델은 Masked Multi-Head Self Attention을 통해 학습
강화 학습으로 사용자 피드백(RLHF)을 통한 미세 조정(Fine-tuning, 사전 학습 된 모델을 또 학습)한다.
GPT 3.5 한계 : 정보의 제한, 사실에 근거하지 않은 부정확한 답변, 불확실한 Query에 대한 추측
2차시 - 생성형 인공지능이란?
생성형 인공지능은 텍스트, 이미지, 음악 등 콘텐츠 생성을 중점으로 둔 인공지능의 한 분야이다.
이미지 생성 : GAN, Autoencoder를 사용하여 실제 이미지를 생성할 수 있다.
텍스트 생성 : RNN, Transformer를 통해 유용한 텍스트 생성 가능
비디오 생성 : 3D CNN, GAN을 사용하여 생성
오디오 생성 : 1D CNN, GAN을 통해 생성
생성형 인공지능은 encoder와 decorder로 구성되어 있다.
인코더 : 입력을 해석, Contextual Information 형성
디코더 : Contextual Information을 통해 출력 생성
GAN : 생성기와 판별기로 구성 - 인코더(판별기)의 피드백을 통해 원하는 영상 제작
VAE : 표준 인코더-디코더 아키텍쳐 판별기 - 여기에는 분산과 평균을 신경쓰네요, 노이즈 제거 및 특성 변환
Flow-based Model : 디코더가 인코더의 역함수이다.
Diffusion Model : 노이즈 생성 및 노이즈 제거 수행 - 가장 정밀한 모델이다
데이터셋 : 대규모 모델을 생성하려면 데이터의 품질 및 개수가 중요하다. 데이터 증강, 전이 학습 등 몇 가지 방법이 있지만 개선이 필요하다.
보안 : 생성 모델이 인간에 위협이 되는 경우가 생기므로 법의 규제를 받아야 한다.
3차시 - 인지 인공지능(Coginitive AI)과의 차이점
인지 인공지능은 컴퓨터가 인간의 사고와 인지 과정을 시뮬레이션하는 방법을 연구하는 인공 지능의 한 분야
지능적인 의사 결정, 문제 해결은 학습, 추론, 언어 이해, 지식 표현 및 기타 기술적 수단을 통해 이루어짐
데이터 마이닝, 머신 러닝, 자연어 처리를 활용하여 작업 수행
인지 인공지능의 구성 요소
지식 표현 : 지식을 설명 및 정리, 지식 간 추론 및 사용 지원
학습 : 데이터에서 패턴을 자동으로 학습, 자체 모델을 지속적으로 최적화
자연어 처리 : 컴퓨터가 자연어를 이해하고 처리할 수 있게 해준다.
컴퓨터 비전 : 이미지 및 비디오에서 객체에 대한 인식 및 분석
추론 및 의사 결정 : 기존 정보를 기반으로 추론 및 의사결정 하여 최적의 솔루션 제공
데이터 마이닝도 추론 분야다
인지 AI 응용 분야
지능형 고객 서비스 : 사용자와 상호작용하고 음성 또는 텍스트를 통해 도움말 제공
지능형 검색 : 사용자 요구에 따라 데이터에서 정확하게 관련 정보 제공
지능형 번역 : 자연어를 다른 자연어로 번역
지능형 이미지 분석 : 의료 이미지를 분석하고 판단하여 종양 및 병 찾기
자율 주행 : 비전 기술과 센서를 사용하여 차량 이동 관리
인지 인공지능과 생성 인공지능의 구성 요소는 비슷하지만 목적이 다르다.
인지 인공지능은 인간과 같은 인지 능력을 발휘할 수 있는 시스템을 개발하는 것을 목표
생성형 인공지능은 이미지와 텍스트 등의 데이터를 생성하는 시스템을 개발하는 것을 목표
4차시 - 언어 및 영상 생성
언어 생성(Language Generation)은 프로그램을 사용하여 자연스러운 인간 언어의 규범에 부합하는 텍스트를 생성하는 프로세스
언어학, 컴퓨터 과학, 인공지능 분야의 교차응용을 포함하는 자연어 처리(NLP)에서 중요한 분야이다.
언어 생성 기술은 자동화된 질의 응답 시스템, 챗봇, 지능형 고객 서비스 시스템, 자동 콘텐츠 생성에 널리 사용 가능하다.
언어 생성에 사용되는 모델엔 마르코프 체인, Rnn, Transformer,LSTM 등이 있다.
자연어 생성 네트워크는 언어 생성에 대한 딥러닝 기반 접근 방식으로 신경망 모델링하여 언어 법칙과 특징 학습 및 새로운 텍스트를 생성
주요 장점 : 문맥 정보를 처리, 자연스럽고 유창하고 표현력이 풍부한 텍스트 생성, 수동으로 설계하지 않는다.
이미지 생성 : 컴퓨터 알고리즘을 통해 이미지 생성 프로세스
완전히 가상의 이미지로 규칙 기반 방법, 통계 기반 방법, 딥 러닝등 다양한 알고리즘이 포함된다.
딥러닝 기반 이미지 생성은 입력 이미지와 출력 이미지 사이의 매핑 관계를 학습하도록 훈련된 신경망 모델을 사용한다.
이러한 모델에는 고품질 이미지를 생성할 수 있는 GAN, VAE 등이 있다.
GAN : 생성기와 판별기 두가지 신경망으로 구서오디었다.
판별기에서 No로 판별되면 Generator가 학습되어 Generator는 yes가 많이 나오도록 학습하게 된다.
Discriminator는 판별을 정확하게 하도록 학습한다.
VAE : 입력 영상의 잡재 변수(Latent vector, space)분포를 학습한 다음 이 분포를 기반으로 새 이미지를 생성한다.
Autor encoder 기반 모델이다.
5차시 - 언어 생성 방법
언어 생성을 위한 데이터 집합 == Text corpus
여러 문장으로 구성되며 클래스, 품사, 번역과 같은 정보를 포함하기도 한다.
전처리
토큰화 : 텍스트를 컴퓨터가 입력받을 수 있도록 다른 입력 요소로 분리
벡터화 : 토큰을 숫자 표현으로 변환
임베딩 : 의미 관계 또는 문맥적 의미를 추가하여 벡터 표현을 더욱 개선
언어 모델 : 언어 생성을 위한 가장 최근의 두가지 딥 러닝 모델
RNN : 메모리를 저장하고 시간적 종속성을 포착하는 순차적 숨겨진 상태를 사용한다.
Transformer : 모든 입력 토큰에 문맥 관계를 생성하는 Multi head Self attention을 사용한다.
모델 학습
1. 무작위 Weight로 모델 초기화
2. 학습 데이터를 모델에 주어 예측값 얻기
3. 예측된 출력과 정답 값의 차이를 계산
4. back propagation, optimizer를 통해 모델 weight를 업데이트하여 loss를 최소화
5. 전체 데이터 세트에 대해 epoch만큼 반복하여 성능 개선
모델이 높은 성능을 달성하거나 손실이 그대로면 훈련 중단
언어 모델 평가 지표
난해성 : 다음 단어를 얼마나 잘 예측하는지
이중 언어 평가 연구(BLEU) 점수 : 생성된 텍스트와 참조 텍스트 간의 유사성 측정
주관적 사람 평가 : 평가자의 주관적 평가
정성적 분석 : 텍스트의 일관성, 문법, 주어진 문맥과의 관련성을 수동으로 검사하고 평가
작업 별 지표 : 작업에 따른 특정 평가 지표. ROUGE를 사용 가능하다.
퀴즈
다음 문장의 빈칸에 들어갈 가장 적절한 단어를 고르시오.
1. “ ChatGPT는 OpenAI에서 개발한 초거대 언어모델 _____입니다.”
CNN
DALL-E
Large Language Model(LLM)정답
GAN
생성형 인공지능 출력의 종류가 아닌것은?
하나를 선택하세요.
1.
이미지생성
2.
아바타생성
정답
3.
텍스트생성
4.
비디오생성
인지 인공지능의 구성요소가 아닌것은?
하나를 선택하세요.
1.
지식표현
2.
학습
3.
자유어 처리
4.
연산 비전
이건 자유어를 자연어로 봐서 틀렸네요,,,,
뭐지 뭐지 고민하다가 연산 비전했는데 자유어 였습니다.....
3. 다음 문장의 빈칸에 들어갈 가장 적절한 단어를 고르시오.
“언어생성(Language generation)는 컴퓨터 프로그램을 사용하여 자연스러운 인간 언어의 규범에 부합하는 ______를 생성하는 프로세스입니다.”
하나를 선택하세요.
1.
텍스트
정답
2.
이미지
3.
오디오
4.
코드
언어 규범에 부합하다는 것에서 너무 텍스트 밖에 안남기도 하고 언어 생성 모델은 텍스트를 출력하죠
다음 문장의 빈칸에 들어갈 가장 적절한 단어를 고르시오.
언어 생성을 위한 데이터 집합을 ______라고 합니다.
하나를 선택하세요.
텍스트 코엑스
텍스트 코퍼스
정답
비디오 코런스
오디오 코랜스
언어 모델은 텍스트 데이터가 필요한데 데이터 집합을 뜻하는 코퍼스와 합성해주면
텍스트 코퍼스가 나옵니당
2주 차 - 재귀 신경망
1차시 - RNN 1
ANN(기본적인 딥러닝)이나 CNN내의 요소는 서로 독립적이며 추가 메모리가 필요하지 않지만 실생활에서 요소는 서로 연결되어 있다. 언어는 맥락을 통해 우리가 이해할 수 있는 것인데 일반 신경망은 이 작업을 수행할 수 없으므로 약간의 메모리가 필요하다.
재귀 신경망 (Recurrent Neural Network)는 순차적 or 시꼐열 데이터를 위해 설계된 신경망으로 방향성 비순환 그래프로 표시한다. 숨겨진 단위(Hidden state, layer )는 이전 데이터와 현재 데이터의 정보를 저장한다.
단방향 RNN은 전방향 레이어만 사용해서 과거 정보만 접근 가능하며 다음 출력 토큰을 예측하는데 유용하다.
양방향 RNN은 전 방향, 후방향 레이어를 모두 사용하여 과거 및 미래 정보에 모두 엑세스할 수 있다.
단방향 RNN보다 강력하지만 전체 입력 시퀸스를 사용할 수 있어야 한다.
2차시 - RNN 2
RNN은 장기적 의존성을 가지고 있어 문제 처리에 오랜 시간이 걸리면 오래 전의 일을 기억할 수 없어 Gradient가 사라지거나 폭발적으로 증가하는 문제가 발생할 수 있다.
Vanishing Gradient : 역전파 시 단계에 따라 기울기가 계속 곱해지기 때문에 0에 가까워 지는 것
Exploding Gradient : 소멸과 반대로 gradient가 너무 커져서 과도한 가중치 업데이트로 이어져 모델이 불안정
RNN 개선 - LSTM. GRU
소실 그라디언트 : 기억을 저장하는 특수한 방식을 가지고 있어 큰 기억은 단순 RNN처럼 바로 지워지지 않음
폭발 그라디언트 : 그라디언트 클리핑을 통해 임계값을 설정해서 넘어가지 못하게 한다.
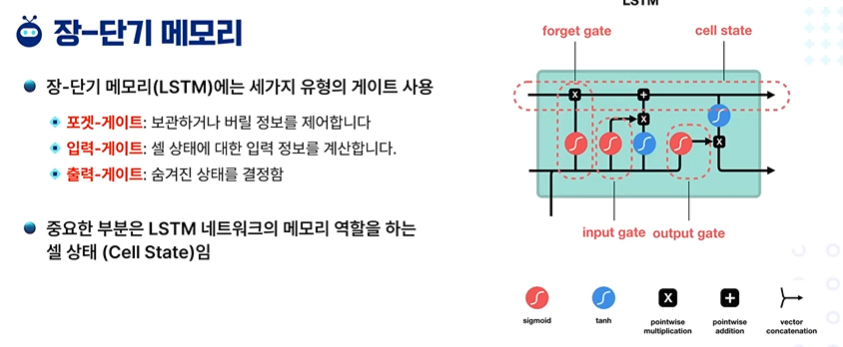
LSTM은 세가지 유형의 게이트를 사용한다.
foregt gate(포겟-게이트) : 보관하거나 버릴 정보를 제어
input gate(입력-게이트) : 셀 상태(Cell state: 메모리 역할)에 대한 입력 정보를 계산
output gate(출력-게이트) : 숨겨진 상태를 결정함
GRU : Gated Recurrent Unit - 게이트형 재귀 장치 = 두 가지 유형의 gate만 사용하여 LSRM을 간소화
LSTM의 cell state 대신 Hidden state
Forget gate와 Input gate 대신 Update gate
Output gate 비슷한 역할을 하는 Reset gate
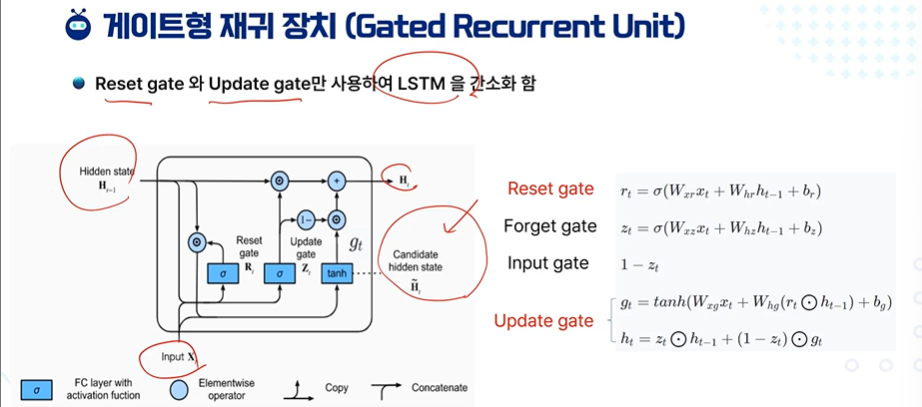
리셋 게이트 : 이전과 지금 값 가중치 해서 더하기 - 이전 상태를 얼마나 잊을지 결정 (0에 가까우면 과거 정보를 많이 잊고, 1에 가까우면 현재 정보를 많이 잊는다.)
포겟 게이트 : 리셋이랑 비슷하다
인풋 게이트 : 1 - 포
업데이트 게이트 : 현재 상태와 새로운 정보를 얼마나 혼합할지 결정 (0이면 새정보만, 1이면 이전 상태만)
설마 코딩하는게 나오겠어...
3차시 - Attention 1
인코더 : 인코딩 단계에서 첫 번째 노드가 단어를 입력하면 후속 노드가 이전 노드의 숨겨진 상태로 다음 단어를 입력한다. 그래서 인코더는 컨텍스트를 출력하고, 이 컨텍스트는 디코더 입력으로 사용된다.
디코더: 디코더를 통과하는 각 노드에 대해 번역된 단어를 출력하고, 디코더의 숨겨진 상태를 다음 계층의 입력으로 사용한다.
RNN 기반 번역은 입력 시퀸스를 고정된 벡터 표현으로 인코딩하여 긴 모델은 벡터 표현 학습이 어렵다.
해결책으로 가변 길이 백터를 사용하는 아키텍처를 쓰거나 Attention 메커니즘을 추가한다.
주의 메커니즘 : 신경망 기계 번역이라는 논문에서 처음 발표됨
attention을 이용해 디코딩을 위해 내부 고정 길이 벡터에 의존하는 기존 인코더 - 디코더의 한계 극복
입력 시퀸스에 대한 LSTM의 중간 출력을 유지한다.
입력에서 선택적으로 학습하고 모델 출력에서 출력 시퀸스와 상관 관계를 갖도록 모델을 훈련함으로써 해결
디코더는 attention 출력의 가중치에 따라 인코딩 상태에 집중한다.
RNN 인코더 - Decoder with Attention
각 인코더 셀은 각 입력 위치에 해당하는 숨겨진 상태 집합을 생성한다.
attention 메커니즘은 각 입력 위치의 관련성을 타나내는 가중치를 계산한다.
디코더는 주의 가중치를 사용하여 출력 시퀸스를 생성
인코더에서 양방향 RNN을 사용하고, 디코더에선 한뱡향 RNN을 사용하며 중간에 attention이 있다.
긴 문장에서 높은 BLEU 점수를 얻는다.
인코더와 디코더, RNN 기반 번역 및 주의 메커니즘 설명
인코더 (Encoder)
- 첫 번째 노드 입력: 단어를 입력받음.
- 후속 노드: 이전 노드의 숨겨진 상태를 받아 다음 단어를 입력.
- 출력: 문장의 컨텍스트를 출력.
- 컨텍스트 사용: 디코더의 입력으로 사용.
디코더 (Decoder)
- 노드 처리: 각 노드가 번역된 단어를 출력.
- 숨겨진 상태: 디코더의 숨겨진 상태를 다음 계층의 입력으로 사용.
RNN 기반 번역의 한계 및 해결책
- 고정된 벡터 표현: 입력 시퀀스를 고정된 벡터로 인코딩, 긴 문장의 경우 학습 어려움.
- 해결책:
- 가변 길이 벡터 사용 아키텍처.
- Attention 메커니즘 추가.
주의 메커니즘 (Attention Mechanism)
- 발표 논문: "신경망 기계 번역"에서 처음 제안.
- 기존 한계 극복: 고정된 벡터에 의존하는 인코더-디코더의 한계를 극복.
- 중간 출력 유지: LSTM의 중간 출력을 유지.
- 선택적 학습: 입력에서 선택적으로 학습하고 출력 시퀀스와의 상관 관계를 학습.
- 디코더 역할: Attention 출력의 가중치에 따라 인코딩 상태에 집중.
RNN 인코더-디코더 with Attention
- 인코더 셀: 각 입력 위치에 해당하는 숨겨진 상태 집합을 생성.
- Attention 메커니즘: 각 입력 위치의 관련성을 나타내는 가중치를 계산.
- 디코더: 주의 가중치를 사용하여 출력 시퀀스를 생성.
양방향 및 한방향 RNN
- 양방향 RNN: 인코더에서 사용.
- 한방향 RNN: 디코더에서 사용.
- 중간에 Attention 사용.
BLEU 점수
- 긴 문장: 높은 BLEU 점수를 얻음.
이렇게 이해하면 더 명확하게 이해할 수 있습니다. 각각의 부분이 어떻게 동작하는지, 그 한계와 이를 극복하는 방법에 대해 설명했습니다.
확인해본 결과, 여러 부분에서 약간의 혼동이 있을 수 있습니다. 한 줄 한 줄 자세히 설명해 드리겠습니다.
인코더와 디코더
인코더:
- 설명: "인코딩 단계에서 첫 번째 노드가 단어를 입력하면 후속 노드가 이전 노드의 숨겨진 상태로 다음 단어를 입력한다."
- 설명: 인코더는 단어를 하나씩 입력받고, 각 단어의 정보를 RNN 셀(혹은 LSTM 셀)을 통해 다음 셀로 전달합니다. 이 과정에서 각 셀은 자신의 숨겨진 상태(hidden state)를 다음 셀로 전달합니다.
- 설명: "그래서 인코더는 컨텍스트를 출력하고, 이 컨텍스트는 디코더 입력으로 사용된다."
- 설명: 인코더의 최종 출력은 입력 시퀀스의 전체 컨텍스트를 나타내는 벡터입니다. 이 컨텍스트 벡터는 디코더의 입력으로 사용됩니다.
디코더:
- 설명: "디코더를 통과하는 각 노드에 대해 번역된 단어를 출력하고, 디코더의 숨겨진 상태를 다음 계층의 입력으로 사용한다."
- 설명: 디코더는 인코더의 출력 컨텍스트를 입력으로 받아 시퀀스를 생성합니다. 각 디코더 셀은 단어를 출력하고, 자신의 숨겨진 상태를 다음 셀로 전달합니다.
RNN 기반 번역:
- 설명: "입력 시퀸스를 고정된 벡터 표현으로 인코딩하여 긴 모델은 벡터 표현 학습이 어렵다."
- 설명: RNN 기반 번역에서는 입력 시퀀스를 고정된 크기의 벡터로 인코딩하는데, 긴 시퀀스의 경우 이 벡터로 충분히 정보를 표현하기 어렵습니다.
- 설명: "해결책으로 가변 길이 백터를 사용하는 아키텍처를 쓰거나 Attention 메커니즘을 추가한다."
- 설명: 이를 해결하기 위해 가변 길이 벡터를 사용하는 아키텍처나 Attention 메커니즘을 사용합니다. Attention은 각 시퀀스의 중요한 부분을 동적으로 선택할 수 있게 합니다.
주의 메커니즘 (Attention Mechanism):
- 설명: "신경망 기계 번역이라는 논문에서 처음 발표됨."
- 설명: Attention 메커니즘은 Bahdanau et al.의 논문에서 처음 소개되었습니다.
- 설명: "attention을 이용해 디코딩을 위해 내부 고정 길이 벡터에 의존하는 기존 인코더 - 디코더의 한계 극복."
- 설명: Attention은 고정된 벡터에 의존하지 않고, 입력 시퀀스의 다양한 부분을 동적으로 참조할 수 있게 합니다.
- 설명: "입력 시퀸스에 대한 LSTM의 중간 출력을 유지한다."
- 설명: Attention 메커니즘은 인코더의 각 타임스텝에서 생성된 숨겨진 상태들을 저장하고 사용합니다.
- 설명: "입력에서 선택적으로 학습하고 모델 출력에서 출력 시퀸스와 상관 관계를 갖도록 모델을 훈련함으로써 해결."
- 설명: 모델은 입력 시퀀스의 중요한 부분을 선택적으로 학습하고, 이를 디코더 출력과 관련지어 학습합니다.
- 설명: "디코더는 attention 출력의 가중치에 따라 인코딩 상태에 집중한다."
- 설명: 디코더는 Attention 메커니즘을 통해, 인코더의 숨겨진 상태 중 중요한 부분에 가중치를 두고 이를 기반으로 출력을 생성합니다.
RNN 인코더-디코더 with Attention:
- 설명: "각 인코더 셀은 각 입력 위치에 해당하는 숨겨진 상태 집합을 생성한다."
- 설명: 인코더의 각 셀은 각 입력 단어에 대해 숨겨진 상태를 생성합니다.
- 설명: "attention 메커니즘은 각 입력 위치의 관련성을 타나내는 가중치를 계산한다."
- 설명: Attention 메커니즘은 디코더의 현재 상태와 인코더의 각 숨겨진 상태 간의 관련성을 나타내는 가중치를 계산합니다.
- 설명: "디코더는 주의 가중치를 사용하여 출력 시퀸스를 생성."
- 설명: 디코더는 Attention 가중치를 사용하여 인코더의 숨겨진 상태들 중 중요한 부분에 집중하고, 이를 기반으로 출력을 생성합니다.
인코더와 디코더 RNN:
- 설명: "인코더에서 양방향 RNN을 사용하고, 디코더에선 한방향 RNN을 사용하며 중간에 attention이 있다."
- 설명: 인코더는 양방향 RNN을 사용하여 입력 시퀀스의 양쪽 정보를 모두 학습합니다. 디코더는 한 방향 RNN을 사용하며, 중간에 Attention 메커니즘이 적용됩니다.
성능 측면:
- 설명: "긴 문장에서 높은 BLEU 점수를 얻는다."
- 설명: Attention 메커니즘을 사용하면 긴 문장에서도 더 나은 번역 성능(BLEU 점수)을 얻을 수 있습니다.
이러한 설명을 통해 인코더-디코더 모델, Attention 메커니즘, 그리고 RNN 기반 번역 시스템의 작동 방식을 이해하는 데 도움이 되길 바랍니다.
4차시 - attention 2
attention 함수의 본질은 쿼리를 키-값 쌍의 집합에 매핑하는 것으로 설명할 수 있다.
유사도 계산은 Query와 key에 대해 수행되어 가중치를 얻는다.
이 가중치는 softmax 함수를 사용하여 정규화 한다.
가중치와 해당 key 값에 가중치를 부여하고, 합산하여 최종 attention을 끌 수 있다.
글로벌 어텐션 모델의 아이디어는 컨텍스트 벡터 C를 도출할 때 인코더의 모든 숨겨진 상태를 고려한다.
5차시 - 간단한 언어 번역
NLP에서 언어 변역은 계산 방법과 알고리즘을 사용하여 한 언어의 텍스트나 음성을 다른 언어로 자동 변환
NLP 기반 언어 번역은 기계, neural net, transformer와 같은 기술을 사용하여 다양한 언어의 복잡성 처리 및 고품질 번역 생성
여기선 Seq2Seq 모델을 사용하여 영어 -> 프랑스어 번역
data set엔 영어와 프랑스어 문장 쌍
각각 단어는 숫자로 변환되어 one-hot vector(원샷 벡터)로 표현
문장 시작 SOS, 문장 끝 EOS
Seq2Seq는 입력 시퀸스를 읽고 단일 벡터를 출력하는 인코더와 해당 벡터를 읽어 출력 시퀸스를 생성하는 디코더 두개의 RNN으로 구성되어 있다
attention이 문맥을 계산하여 디코더에 적용되어 attention 디코더를 만든다.
퀴즈
다음 문장의 빈칸에 들어갈 가장 적절한 단어를 고르시오.
“ 순환 신경망(Recurrent Neural Network) 은 _____또는 _______를 위해 설계된 신경망 모델의 한 유형”
하나를 선택하세요.
1.
순차적, 시계열
2.
역차적, 도르레열
3.
오차적, 열감지열
4.
배차적, 전자열
딱 떠오르는 것이 없어서 소거형으로 하려고 했지만 너무 1번이었고, 나머지는 ....
다음 문제 중 올바르지 않는 것을 고르시오.
장-단기 메모리(LSTM)의 세가지 유형의 게이트가 아닌것은?
하나를 선택하세요.
1.
쿠다-게이트
2.
포켓-게이트
3.
입력-게이트
4.
출력-게이트
쿠다는 엔디비아 GPU사용할 때 쓰는 것 아닌가요,,,,?
여기서 포켓 게이트가 망각 게이트네요
3.다음 문장의 빈칸에 들어갈 가장 적절한 단어를 고르시오.
“시퀀스 대 시퀀스(seq2seq) 네트워크는 _____와______라는 두 개의 RNN으로 구성된 모델입니다.”
하나를 선택하세요.
1.
돼코더와 엔코더
2.
인코더와 디코더
3.
디스코와 앵코스
4.
코트라와 앵갤스
이것도 직전에 배운 내용이네요
인코더와 디코더는 땔 수 없는 관계....
4.다음 문장의 빈칸에 들어갈 가장 적절한 단어를 고르시오.
“어텐션 함수의 본질은 _____를 _______쌍의 집합에 매핑하는 것으로 설명할 수 있습니다."
하나를 선택하세요.
1.
보리 샵-값
2.
퀴리 키-값
3.
사리 솝-값
4.
소리 푼-값
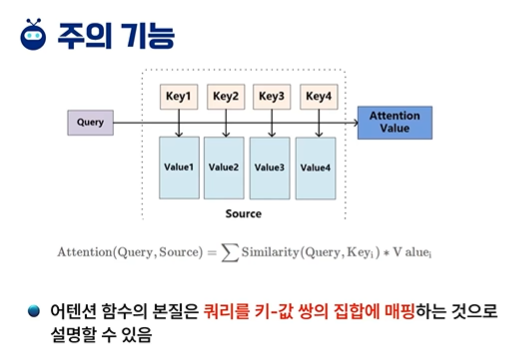
여기서 나왔었습니다. query를 key, value 쌍의 집합에 매핑한다!
오히려 퀴리라고 하니까 모르겠네요... 퀴리 부인밖에 안 떠오르는 ....
5.다음 문장의 빈칸에 들어갈 가장 적절한 단어를 고르시오.
"RNN 인코더-디코더 성능 제한의 해결책은 _____________를 사용하는 아키텍처를 사용하고 ______________을 추가하는 것입니다."
하나를 선택하세요.
1.
고변 길이 벡터, 고의 메커니즘
2.
개변 길이 벡터, 조절 메커니즘
3.
가변 길이 벡터, 주의 메커니즘
4.
전변 길이 벡터, 확인 메커니즘
이 것도 직전에 나왔었습니다.
오 사진을 못 찾겠네요....?
흠...
이 문제의 정답은 3. 가변 길이 벡터, 주의 메커니즘입니다. RNN 인코더-디코더 아키텍처의 성능 제한을 해결하기 위해, 가변 길이 벡터를 사용하고 주의(어텐션) 메커니즘을 추가하는 방법이 자주 사용됩니다. 이러한 아키텍처는 입력 시퀀스를 고정된 길이의 벡터로 압축하는 대신, 시퀀스의 각 요소에 대한 가중치를 계산하여 문맥을 더 잘 파악할 수 있게 합니다.
3주 차 - Deep Learning
1차시 - Convolution이란 ?
머신러닝은 Feature extraction과 Downstream task가 분리 되어 있으나 딥러닝은 결합되어 있고, feature extraction도 모델에 의해 학습되므로 수작업으로 특징을 만들 필요가 없다.
Convolution은 두 함수를 결합하여 세 번째 함수를 생성하는 수학적 연산이다.
이미지 처리에서 convolution은 전체 이미지에서 각 픽셀과 그 로컬 이웃에 커널을 적용하여 이미지 변환하는 프로세스
딥러닝에서는 이미지 입력에서 특징을 추출하기 위해 신경망에 컨볼루션 수행.
딥러닝에서 convolution의 사용 목적은 feature의 계층적 표현을 만드는 것
convolution layer는 입력 영상과 커널(필터)가 주어지면 이미지 입력의 각 요소는 커널의 각 요소에 쌍 단위로 곱해진다.
곱해진 각 쌍의 결과를 합산하여 feature map의 새로운 요소를 생성.
커널은 영상의 모든 요소 집합에 적용된다.
feature Map size = (org - filter + 2 * padding) / stride
stride는 필터의 이동 단위이다.
padding은 feature map이 작아지는 것을 막고, 입력 feature 맵의 경계 정보 손실을 막기 위해 사용한다.
입력 행렬에서 필터와 동일한 크기의 데이터가 선택, 계산 수행되고, 해당 위치의 곱의 합을 계산
Convolution은 CNN에서 사용되며 이미지 분류, 객체 감지, 인스턴스 세분화, 시맨틱 세분화, 팬옵틱 세분화 등 컴퓨터 비전 작업에서 사용된다.
2차시 - 다층 구조 신경망 ANN
ANN == 인공 신경망으로 인간 두뇌의 신경 구조에서 영감을 얻었다.
최신 딥러닝 알고리즘의 기본 구성 요소로 입력, 숨겨진, 출력 레이어로 총 세 가지 주요 계층으로 구성
입력 레이어는 data set의 feature 또는 영상의 픽셀 값일 수 있는 원시 입력 데이터를 수신
입력 레이어의 각 뉴런은 하나의 feature 또는 하나의 픽셀을 나타내며 활성화된 뉴런은 다음 레이어로 전달
숨겨진 레이어는 입력과 출력 레이어 사이의 중간 레이어로 학습 데이터에서 직접 관찰할 수 없고, 네트워크가 학습하면서 생성하는 추상적인 표현이기 때문에 '숨겨진'이라는 용어가 생겼다.
hidden layer를 통해 네트워크는 입력 데이터에서 계층적 특징과 패턴을 학습한다.
일반적으로 신경망에 여러 개의 숨겨진 레이어가 있으며 많을 수록 네트워크가 심측적이라 할 수 있다.
출력 레이어는 최종 예측 또는 출력을 생성한다.
뉴런 수는 네트워크가 해결하도록 설계된 작업 특성에 따라 달라지며, multi class classification task에서는 각 class에 대해 하나의 뉴런이 있다.
actication function은 네트워크에 비선형성을 도입하여 데이터의 복잡한 패턴과 관계를 학습
활성화 함수가 없는 신경망은 선형 모델로 한계가 있다.
ex ) 선형(Linear), 정류된 선형 단위(ReLU), 시그모이드(Sigmoid)
하이퍼 파라미터는 훈련 과정에서 데이터로부터 학습되지 않고 훈련 전에 사용자가 수동으로 설정하는 구성 설정이다.
이러한 매개변수는 신경망 동작에 영향 미치며 학습 알고리즘이 데이터에 적응하는 방식에 영향을 미친다.
적절한 hyperparameter의 선택은 최적의 성능을 달성하고 overfitting, underfitting과 같은 문제를 방지하는데 매우 중요.
ex ) Epoch, Learning rate, Batch Size, Optimizer
3차시 - 다층 구조 신경망 구조
CNN의 주요 구성 요소
Convolution Layer : 입력 데이터에 필터를 적용하여 데이터의 패턴과 특징을 감지
Pooling Layer : 입력 데이터의 공간적 차원을 줄여 가장 중요한 기능을 요약하고 선택해 필수 정보 보존
Fully-Connected Layer : FCN을 통해 최종 출력 생성
기타 구성 요소
Vormalization Layer : 이전 레이어의 활성화를 표준화하여 훈련 중 모델의 안정성과 수렴 향상
Dropout Layer : 훈련 중 무작위 뉴런을 비활성화 하여 overfitting을 방지하고 신경망 견고성 장려
Flatten Layer : 다 차원 입력을 1차원 벡터로 재구성하여 FCN을 할 수 있도록 만든다.
FCN 장 단점
장점 : 원하는 output을 충실하게 이행
단점 : 계산량이 많아 네트워크를 유지하기 어렵다
LeNet : mnist를 위해 설계, 이미지 분류 작업에서 CNN의 효율성을 확립하는데 중요한 역할
Conv -> max pooling -> Conv -> max pooling -> FCN 3개
AlexNet : ImageNet에서 우승하여 딥러닝 분야에 혁명을 일으키고, CNN의 잠재력을 보여줌
Convolution을 2개의 GPU로 작동하여 따로따로 진행 후 서로 섞었다.
VGG : 이미지 분류 작업에서 탁월한 성능을 달성, 깊이의 중요성에 대한 인사이트 제공
3*3 convolution filter가 16,19개가 있는 단순하고 깊은 딥러닝
GoogleNet : inception을 통해 매개변수를 크게 줄이고, 효율적이고 다양한 규모의 feature 추출의 중요성 입증
다양한 사이즈의 filter를 병렬로 사용한 후 합쳐서 다양한 규모의 정보를 효율적으로 캡처
ResNet : Skip connection을 통해 심층 네트워크에서도 효과적으로 훈련할 수 있게 만들었다.
기울기 소실 문제를 해결하여 매우 깊은 네트워크도 효과적 훈련 가능
DenseNet : 각 레이어가 이전 레이어의 feature map을 수신하여 정보 흐름 촉진, feature 재사용을 촉진하는 고밀도 연결성
고밀도 블록은 효율적인 파라미터 활용을 가능하게 파라미터 수 감소, 경사 흐름을 개선하여 성능과 학습 효율 향상
4차시 - 다층 구조 신경망의 학습
Feedforward - 네트워크 레이어를 통해 입력 데이터를 전파.
Conv, activation, pooling 과 같은 연산을 순차적으로 적용하여 최종 출력을 생성하는 프로세스
Loss function == 비용함수 == 목적함수 == 손실함수 = 모델 예측과 label의 차이를 정량화하기 위해 사용되는 척도
주요 목적은 큰 오류에 불이익을 주고, 모델이 예측과 실제 목표 사이의 불일치를 최소화하도록 유도하여 정확한 예측을 하게함
손실 함수의 선택은 classification, regression or 특수 작업과 같이 처리하는 특정 task에 따라 달라진다.
MSE == 평균 제곱 차이 = 낮을수록 모델의 예측이 실제 목표 값에 가까워져 더 나은 성능을 나타낸다.
최적화 알고리즘(Optimization algorithm) : 모델의 파라미터를 조정하는 중요한 구성요소
모델의 예측과 실제 목표 값 간의 불일치를 나타내는 손실 함수의 값을 최소화하는 목표를 가짐
손실을 줄이는 방향으로 모델의 파라미터를 반복적으로 업데이트하며 일반적으로 SGD, ADAM, RMSprop 등을 사용
미니 배치 데이터를 사용해 손실 함수의 기울기 계산 후 기울기와 학습률에 따라 파라미터를 업데이트한다.
손실이 최소로 수렴하거나 중지 기준을 충족 or epoch에 도달할 때 까지 반복한다.
BackPropagation은 출력레이어에서 역방향으로 파라미터에 대한 손실 함수의 기울기를 계산
체인 규칙을 사용하여 파라미터를 효율적 업데이트하여 손실을 줄이며 성능을 미세 조정
이 프로세스도 모델이 수렴될 때 까지 반복적으로 수행, 손실을 최소화, 정확한 예측을 수행
5차시 - CNN의 한계
카메라를 기반으로 하는 자율 주행에서 카메라 이미지를 변조하는 적대적 공격에 취약하다.
높은 정확도를 위해선 광범위한 데이터를 통해 이미지 패턴을 학습해야 하는데 세트가 제한적이면 overfitting이 발생하여 새로운 데이터에 대해 성능이 저하될 수 있다.
이동 불변성 : 물체의 방향이나 위치를 약간만 변경해도 해당 물체를 인식하는 뉴런이 활성화되지 않을 수 있다.
데이터 증강으로 어느정도 해결할 수 있지만 완전히 해결된 것은 아니다
Pooling layer는 전체와 부분 간의 상관관계가 무시되며 매우 중요한 정보가 소실될 수 있다.
좌표 프레임 및 부분과 전체의 관계
물체의 방향과 특징을 해석하는데 도움이 되는 정신적 좌표 프레임이 없기 때문에 내부 표현이 의미있는 부분과 전체의 관계가 아닌 픽셀 클러스터로 제한되었다.
적대적 공격에 취약성
입력 데이터를 의도적으로 조작하여 잘못된 결과를 생성하는 적대적 공격으로부터 자유롭지 않다.
자율 주행차와 같이 안전이 중요한 어플에서 심각한 우려를 일으켜 견고성을 보장하는 것이 매우 중요하다.
퀴즈
1. 다음 문장의 빈칸에 들어갈 가장 적절한 단어를 고르시오.
“ 머신 러닝에서 ________과 _____________은 분리되어 있음”
머신러닝은 사람이 직접 특징을 추출해줘야 한다고 했으니 1번빼고는 다 사라지네요.
다운 스트림이 뭔지는...?
정답은 "1. 특징 추출, 다운스트림 작업"입니다.
설명: 머신 러닝에서 '특징 추출'과 '다운스트림 작업'은 서로 분리되어 있습니다. 특징 추출(feature extraction)은 원시 데이터로부터 유용한 정보를 추출하여 학습에 사용할 수 있는 형태로 변환하는 과정입니다. 다운스트림 작업(downstream task)은 특징 추출을 통해 얻은 데이터를 바탕으로 실제로 문제를 해결하기 위한 다양한 머신 러닝 알고리즘의 적용을 의미합니다. 예를 들어, 이미지에서 객체를 인식하기 위한 특징을 추출하고, 이 특징을 바탕으로 객체 분류나 객체 탐지 같은 다운스트림 작업을 수행할 수 있습니다.
2. 다음 문장의 빈칸에 들어갈 가장 적절한 단어를 고르시오.
“이동 불변성(Translational Invariance)이란 동일한 물체의 ______이나______를 약간만 변경해도 해당 물체를 인식하는 뉴런이 활성화되지 않을 수 있다는 의미”
이전 시간에 나왔죠 물체를 회전하거나 이동시키면 못 맞춘다고! 여기선 회전이 다른거랑 있으니 방향으로 봐도 되겠네요
정답은 "2. 방향, 위치"입니다.
설명: 이동 불변성(Translational Invariance)은 동일한 물체의 방향이나 위치를 약간만 변경해도 해당 물체를 인식하는 뉴런이 활성화되지 않을 수 있다는 개념을 의미합니다. 이는 컴퓨터 비전 시스템이나 뉴런 네트워크가 이미지 내의 객체 위치나 방향의 작은 변화에도 불구하고 해당 객체를 동일하게 인식할 수 있음을 나타냅니다. 이러한 성질은 특히 컨볼루션 신경망(CNN)에서 중요하게 다루어지는 개념으로, 이미지 처리에서 객체의 위치나 방향이 달라져도 동일한 특징을 추출하여 인식할 수 있도록 돕습니다.
3. 활성화 함수의 기능이 아닌것은?
ㅎㅎ... 코싸인은 나중에 유사도를 구할때 사용됩니다.
정답은 "4. 코싸인"입니다.
설명: 활성화 함수는 신경망에서 입력 신호의 총합을 출력 신호로 변환하는 함수입니다. 주로 비선형 변환을 수행하며, 신경망이 복잡한 문제를 해결할 수 있게 합니다. "쌍곡탄젠트(Tanh)", "정류된 선형 단위(ReLU)", 그리고 "시그모이드"는 모두 널리 사용되는 활성화 함수입니다. 반면, "코싸인" 함수는 일반적인 활성화 함수로 사용되지 않습니다. 활성화 함수는 일반적으로 입력 값을 적절한 범위 내의 출력 값으로 매핑하여 신경망의 비선형성을 도입하는 역할을 하며, 코싸인 함수는 이러한 목적에 맞게 특별히 설계된 함수가 아닙니다.
4. 다음 문제 중 올바르지 않는 것을 고르시오.
컨볼루션 신경망의 주요 구성 요소가 아닌것은?
오 생성적 대립 신경망은 레이어라고 볼 수 있나요...? GAN아닌가요?
정답은 "4. 생성적 대립 신경망 레이어"입니다.
설명: 컨볼루션 신경망(CNN)의 주요 구성 요소는 컨볼루션 레이어(Convolutional Layer), 풀링 레이어(Pooling Layer), 그리고 완전 연결 레이어(Fully Connected Layer)입니다. 컨볼루션 레이어는 이미지의 특징을 추출하는 역할을 하고, 풀링 레이어는 특징 맵의 크기를 줄이는 역할을 하며, 완전 연결 레이어는 분류 등의 최종 결정을 내리는 역할을 합니다. 반면, 생성적 대립 신경망(Generative Adversarial Network, GAN) 레이어는 컨볼루션 신경망의 구성 요소가 아니며, 실제 이미지와 유사한 이미지를 생성하는데 사용되는 별도의 신경망 구조입니다. GAN은 생성자(Generator)와 판별자(Discriminator) 두 가지 네트워크로 구성되어 상호 경쟁하면서 학습합니다.
5. 다음 문장의 빈칸에 들어갈 가장 적절한 단어를 고르시오.
“최적화 알고리즘(Optimization algorithm)은 학습 과정에서 모델의 파라미터_______및_______를 조정하는 중요한 구성 요소”
parameter와 bias를 어떻게 조정하느냐에 따라 학습이 오래걸리냐, local minimum에 빠지냐 등 안좋은 요건에 걸릴 수 있기 때문에 이 optimizer가 잘 해줘야죠. 즉 가중치와 편향!
정답은 "2. 가중치, 편향"입니다.
설명: 최적화 알고리즘은 학습 과정에서 모델의 가중치(Weight)와 편향(Bias)을 조정하여, 예측 오차를 최소화하고 모델의 성능을 개선하는 중요한 역할을 합니다. 가중치와 편향은 모델이 입력 데이터에서 학습할 수 있는 매개변수로, 이들의 조정을 통해 모델이 보다 정확한 예측을 수행할 수 있게 됩니다.
괜히 한글로 번역하니까 알아보기 더 불편하네요...
4주 차 NLP
1차시 - 워드 임베딩
워드 임베딩 : 단어를 고차원 벡터 공간에서 밀도가 높은 벡터로 표현하는 NLP 기술
단어 간의 의미 관계를 알고 유사한 단어 끼리 유사한 벡터 표현을 가질 수 있도록 하고, 단어의 문맥과 의미를 보다 효율적인 방식으로 학습할 수 있도록 한다.
단어 표현 방식이란 단어를 숫자 벡터로 변환하여 머신러닝 알고리즘이 알아들을 수 있도록 하는 것
ex ) one-hot encoding, BOW, TF-IDF, Word2Vec, GloVe, Fast Text, Contestual Word Embeddings
One-Hot Encoding은 단어와 같은 범주형 데이터를 숫자로 표현하기 위해 널리 사용되는 기술
각 단어는 어휘에 단어 인덱스에 1이 하나 있고 나머지는 0이 있는 이진 벡터로 의미론적 관계가 부족, 계산 비효율적
Bag-of-Words는 단어의 빈도를 계산하여 문서 or 문장을 벡터로 변환하는 작업
어순과 문맥은 무시, 단어의 발생 여부만 중요하여 희소하고, 고차원적인 벡터로 표현
BOW도 단순하고 효율적이지만 의미 관계를 포착하진 못한다.
TF-IDF는 특정 문서에 많이 나오는 단어에 높은 가중치를 할당하여 단어의 의미를 파악할 수 있게 해준다.
TF = 용어 빈도 = 문서에서 얼마나 자주 나타나는지, IDF = 역문서 빈도 = 전체 말뭉치에서 얼마나 드문지
tf = 그냥 많이 나오는 단어, idf= 적게 나오지만 중요한 단어
중요한 단어를 잡아내는 역활을 할 수 있지만 결국 문맥은 다 사라진다.
Word2Vec는 고차원 공간에서 조밀하고 연속적인 벡터로 변환한다.
Skip gram 및 CBOW와 같은 신경망 구조를 사용해 빈칸 단어 맞추기나 주변 단어 맞추기로 단어를 학습
단어 간의 의미 관계를 캡쳐해 비슷한 의미를 가진 단어가 비슷한 벡터 표현을 가질 수 있도록 해 단어 유추 및 의미론적 산술이 가능하다.
GloVe는 전체 말뭉치에서 글로벌 단어 동시 발생 통계와 행렬 인수분해를 결합하여 단어 표현을 학습
고차원에서 조밀하고 연속적인 벡터로 표현하여 단어간 의미론적 관계와 구문론적인 관계 모두 포함
Word2Vec와 TF-IDF와 같은 기존 카운팅 기반 방법의 한계를 몇 개 극복
FastText는 문자 수준 n-그램인 하위 단어 임베딩의 합으로 단어를 나타낸다.
어휘에 벗어난 단어를 처리하고, 형태학적으로 풍부한 언어의 의미를 보다 효과적으로 포착할 수 있다.
하위 단어를 활용해 의귀하거나 철자가 틀린 단어를 표현하고, 단어 구조가 복잡한 언어의 경우 더 나은 임베딩 달성
Contextual Word Embedding은 문장이나 문서에서 주변 문맥을 기반으로 단어의 의미 캡처
기존 임베딩과 달리 단어가 나타나는 문맥에 따라 달라지는 임베딩을 생성한다.
문맥적 뉘양스를 포착하여 모델이 단어의 의미와 관계를 보다 효과적으로 이해할 수 있도록 지원한다.
각 임베딩 방식의 작동 방식과 예시를 통해 이해를 돕겠습니다.
1. Bag of Words (BOW)
설명: 단어의 존재 유무를 나타내는 단순한 모델. 문장을 단어 집합으로 표현.
예시:
- 문장1: "I love cats"
- 문장2: "I love dogs"
- 단어 집합: ["I", "love", "cats", "dogs"]
- 문장1 벡터: [1, 1, 1, 0]
- 문장2 벡터: [1, 1, 0, 1]
2. TF-IDF (Term Frequency-Inverse Document Frequency)
설명: 문서 내 단어의 빈도와 전체 문서에서의 역빈도를 고려하여 가중치를 부여.
예시:
- 문서1: "I love cats and cats are great"
- 문서2: "I love dogs"
- TF: 각 문서에서 단어의 빈도.
- IDF: 전체 문서에서 단어의 희귀성.
- 문장1 TF-IDF 벡터: [0.5, 0.25, 0.5, 0.5, 0, 0]
- 문장2 TF-IDF 벡터: [0.5, 0.25, 0, 0, 0.5, 0.5]
3. Word2Vec
설명: 단어를 밀집 벡터로 표현하는 방식. 단어 간 유사도를 학습.
예시:
- 입력 문장: "I love playing football"
- Word2Vec 모델 학습 후:
- "I" -> [0.1, -0.2, 0.3, ...]
- "love" -> [0.4, -0.1, 0.5, ...]
- "playing" -> [0.3, 0.2, -0.3, ...]
- "football" -> [-0.2, 0.1, 0.4, ...]
4. GloVe (Global Vectors for Word Representation)
설명: 전체 코퍼스에서 단어 간 공기 발생 행렬을 기반으로 단어 벡터를 학습.
예시:
- 입력 문장: "I love playing football"
- GloVe 모델 학습 후:
- "I" -> [0.2, -0.1, 0.4, ...]
- "love" -> [0.3, 0.1, 0.2, ...]
- "playing" -> [0.1, 0.3, -0.2, ...]
- "football" -> [-0.1, 0.4, 0.2, ...]
5. FastText
설명: 단어를 문자 단위 n-그램으로 나누어 벡터를 학습하여 희귀 단어도 표현 가능.
예시:
- 입력 문장: "I love playing football"
- "playing" -> ['pla', 'lay', 'ayi', 'yin', 'ing']
- FastText 벡터:
- "I" -> [0.2, -0.1, 0.3, ...]
- "love" -> [0.4, 0.2, 0.1, ...]
- "playing" -> [0.1, 0.2, -0.2, ...] (각 n-그램 벡터의 합)
6. Contextual Word Embeddings (예: BERT)
설명: 문맥에 따라 단어의 의미가 달라지므로 문맥을 고려한 단어 벡터를 생성.
예시:
- 입력 문장1: "He went to the bank to deposit money"
- 입력 문장2: "She sat by the river bank"
- BERT 모델 학습 후:
- "bank" (문장1) -> [0.3, 0.1, -0.2, ...]
- "bank" (문장2) -> [-0.1, 0.2, 0.4, ...]
이러한 예시를 통해 각 임베딩 방식의 차이점과 특징을 이해할 수 있습니다.
2차시 - Self attention 1
self attention = 확장된 도트-프로덕트 주의 - 각 요소를 처리할 때 모델이 입력 시퀸스의 다른 부분에 집중 가능하게 함
외부 요소에 초점을 맞추는 기존 attention과 달리, self-attention은 모델이 입력 시퀸스 자체 내에서 종속성과 관계 설정
self-attention은 문장 내 단어 간 관계를 이해하고, 장거리 종속성을 효과적으로 판단하기 위해 transformer에서 활용
관련 단어에 주의를 기울이고 문맥의 중요성을 학습하여 모델이 번역, 감정 분석 등 다양한 언어 작업에서 능력 발휘
attention score calculate : Query 벡터와 Key 벡터의 내적을 취해 현재 입력에 대한 각 입력의 관련성 측정
크기 조정 : 쿼리 벡터 차원의 제곱근으로 나눠 매우 큰 도트 곱을 방지하여 메커니즘을 보다 안정적으로 만듬
soft max : 정규화하여 최대 1로 합산되는 가중치를 생성한다.
context vector : Value Vector와의 곱을 통해 가장 관련성 높은 정보를 강조한다.
가중 합에서 얻은 context vector는 주어진 입력 벡터에 대해 스케일링된 도트-프로덕트 주의 메커니즘으로 출력
문장 내의 연관 관계를 따지는데 q,k,v를 통해 문장 내의 context가 자동으로 계산된다.
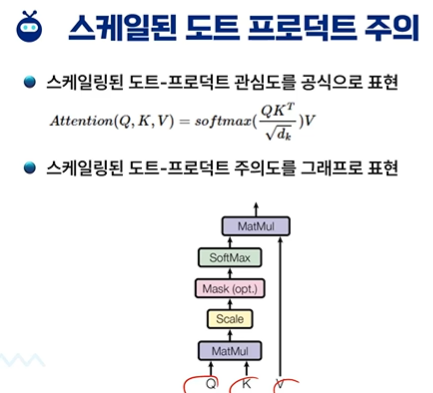
attention mask - 어떤 위치에 주목할 수 있는지 제어한다.
값의 가중치 합계를 계산하기 전에 어텐션 점수에 적용되어 특정 위치를 효과적으로 마스킹하고 요소의 하위 집합으로 attention을 제한한다.
진짜 용어 한글 영어 이상하게 해놓으니까 햇갈려 죽겠네요
3차시 - Self attention 2
scale dot product attention을 구현하는 것은 간단하다.
1. Query 및 transpose된 key 행렬에 dot 곱을 수행한다.
2. 점수를 key vector 차원의 제곱근으로 나눈다.
3. 필요한 경우 masking 진행
4. softmax 적용
5. attention 확률(?, 4번의 결과물)과 value에 대해 dot product를 수행한다.
self-Attention의 장점
장거리 종속성 파악 : 멀리 떨어져 있는 요소 간의 관계를 포착할 수 있게 해주며, 복잡한 어순과 종속성을 가진 언어의 문맥을 이해하는데 유용하다. - Long range Association Dependency : RNN 단점 보안
상황에 맞는 유연성 있는 이해 : 입력의 다른 부분을 고려하여 표현을 구성할 수 있도록 하며, 단어 간의 특정 관계를 기반으로 문맥을 이해하는데 도움이 된다. - Context 문맥 잘 이해
병렬 처리 : 쉽게 병렬화가 가능하여 학습 및 추론 속도가 빨라져 self attention 기반 구조를 효과적으로 만들 수 있다.
가변 길이 시퀸스의 효율적인 처리 : 다양한 길이의 입력에서 잘 작동하여 다양한 길이의 문장이나 문서 포함 작업 가능
계층 구조 관계 : 여러 수준의 세부 수준에서 작동하여 로컬 및 글로벌 종속성을 모두 파악, 계층적 구조를 포함하는 작업에 유용함 - CNN과 유사한 구조를 가지고 있다.
확장성 : 계산 비용이 길이에 따라 기하급수적으로 증가하긴 해도 RNN, CNN보단 관리하기 쉬움
Pre-training : 대규모 코퍼스를 대상으로 사전학습하는데 효과적, 특정 downstream task에 맞게 fine tuning할 수 있다.
Multi-modal application : 멀티 모달 어플리케이션에서 이미지, 오디오 등 다른 데이터 유형을 처리하도록 확장됨
해석 가능한 attention : Attention Weights가 해석 가능하여 모델이 특정 예측을 하는 이유를 이해할 수 있도록 도와줌
4차시 - Multi head Attention
각 헤드(여러 Query, Key, Value의 집합)에서 생성된 attention score는 뚜렷한 패턴과 관계를 포착하여 다양한 context struct에 대한 model의 이해를 강화한다.
각 헤드에 대한 attention score를 계산한 후 출력을 Concat하고, 선형적으로 변환하여 최종 다차원 표현을 형성한다.
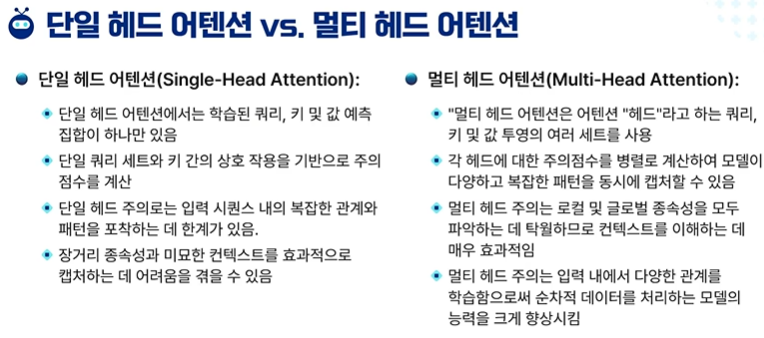
Single-Head Attention
Query, Key, Value 집단이 하나만 있다.
단일 Query와 key 간의 상호작용을 기반으로 attention score를 계산
입력 시퀸스 내의 복잡한 관계와 패턴을 포착하는데 한계가 있음
장거리 종속성과 미묘한 컨택스트를 효과적으로 캡쳐하는데 어려움을 겪을 수 있다.
Multi-Head Attention
헤드 = Query, Key, Value의 여러 세트
각 헤드에 대한 attention score를 병렬로 계산하여 모델이 다양하고 복잡한 패턴을 동시에 캡쳐 가능
local 및 global 종속성을 모두 파악하는데 탁월하므로 문맥을 이해하는데 효과적
입력 내에서 다양한 관계를 학습함으로써 순차적 데이터를 처리하는 모델의 능력을 크게 향상시킴
ex) 단어 임베딩 512차원을 64차원 벡터로 분할하여 이 벡터를 Query, Key, Value로 사용한다.
64차원의 단어 임베딩을 각 세트에 대해 attention을 수행
마지막 단계에서 결과 출력이 concat되고, 512차원의 context embedding vector가 형성된다.
Multi-Head attention의 장점
빠른 연산 : 각 헤드가 독립적으로 작동해 동시에 계산을 수행할 수 있고, attention 계산 프로세스 속도가 빨라짐
상황별 이해도 향상 : 병렬 처리를 통해 다양한 패턴과 관계를 동시에 포착할 수 있고, 이는 모델이 데이터의 다양한 측면에 동시에 attention할 수 있기 때문에 보다 포괄적인 맥락의 이해로 이어진다.
향상된 성능 : 여러개의 헤드를 병렬적으로 처리함으로써 데이터의 복잡한 종속성과 뉘양스를 보다 효율적으로 포착할 수 있고, 그 결과 다양한 자연어 처리 작업에서 모델 성능이 향상되는 경우가 많다. - NLP 가 많이 발전됨
확장 가능성 : 헤드 수가 증가함에 따라 병렬 처리를 통해 계산 시간이 오래 걸리지 않고, 더큰 입력을 효과적으로 처리
적용 가능성 : 헤드마다 서로 다른 유형의 관계나 패턴을 포착하는데 특화될 수 있고, 병렬 처리를 통해 전문화된 기능을 동시에 적응적으로 학습할 수 있다.
효율적인 하드웨어 활용도 : 최신 하드웨어는 병렬 연산에 최적화 되어 있기 때문에 하드웨어 리소스를 효율적으로 활용하여 훈련 및 추론 속도를 높일 수 있다.
유연성 : 병렬 처리는 헤드 수에 유연성을 제공하고, 복잡성이나 리소스에 따라 헤드 수를 조절 가능하다.
5차시 - Transformer 작동 원리
Transformer = Encoder + Decoder
Encoder = Multi-Head Attention + Feed Forward + Normalization
Decoder = Encoder + Mask Multi-Head Attention
인코더는 동일한 레이어 스택으로 구성되며 각 레이어에는 2개의 하위 레이어가 포함되어 있다.
Multi-Head Self Attention : 입력 요소간의 attention을 계산하여 모델이 여러 위치의 중요도에 가중치를 부여할 수 있게 함
Feed Forward Networks : 각 포지션의 표현은 FCN을 통해 독립적으로 변환된다.
ADD & Norm은 각 하위 레이어 후에 적용되어 훈련을 안정화하고 용이하게 한다.
Encoder는 입력의 context화된 표현을 생성하여 요소 간의 관계에 대한 정보를 유지한다.
인코더의 출력은 디코더를 통과하여 단계별로 출력을 생성한다.
Decoder는 동일한 레이어가 스택으로 구성되며 3개의 하위 레이어가 포함된다.
Mask Multi-Head Self Attention : 디코딩 중에 뒤에 있는 내용이 영향을 주지 않도록 한다.
Multi-Head Encoder-Decoder Attention : 인코딩 입력을 처리하여 모델이 출력을 생성하는 동안 컨텍스트를 고려할 수 있도록 한다.
Feed Forward Network : Encoder에서와 마찬가지로 위치별로 표현을 변환한다.
Norm & ADD가 출력에 적용된다.
Decoder는 이전에 생성도니 위치를 기반으로 한번에 한 위치씩 예측하여 출력을 생성한다.
Positional Encoding - Transformer가 위치 정보를 고려하지 않기 때문에 입력되는 embedding에 위치 정보를 추가한다.
Linear and softmax - decoder 각 단계에서 토큰을 예측하여 최종 목표 출력을 생성, 단어의 확률 분포를 생성하기 위해 soft-max 과정을 거친다.
진짜 교안..................ㅋㅋ....
퀴즈
1. 다음 문제 중 올바르지 않는 것을 고르시오.
자기주의(Self-Attention)의 이점 아닌것은?
으음...?
병렬 처리가 된다고 했고, 장거리 종속성 파악도 된다고 했고, 병렬 처리== 이중 모드 애플리케이션 아닌가?


"이중 모드 애플리케이션"은 자기 주의(Self-Attention)의 이점과는 직접적인 연관이 없는 선택지입니다. 자기 주의 메커니즘의 주된 이점은 다음과 같습니다:
장거리 종속성 파악: Self-Attention은 입력 시퀀스 내의 임의의 두 위치 간의 직접적인 관계를 모델링할 수 있기 때문에, 문장이나 시퀀스 내에서 멀리 떨어진 요소들 간의 관계를 학습할 수 있습니다. 이는 특히 긴 문장이나 시퀀스를 다룰 때 유용합니다.
병렬 처리: 전통적인 RNN이나 LSTM은 이전 단계의 출력을 다음 단계의 입력으로 사용하는 순차적 처리 방식 때문에 병렬 처리가 어렵습니다. 반면, Self-Attention 메커니즘은 입력 시퀀스의 모든 요소를 동시에 처리할 수 있어 GPU 등 병렬 처리 하드웨어를 효과적으로 활용할 수 있습니다.
확장성: Self-Attention은 입력 시퀀스의 길이에 관계없이 각 요소 간의 관계를 계산하기 때문에, 모델의 확장성 측면에서 유리합니다. 이는 특히 긴 시퀀스를 처리할 때 계산 비용이 증가하는 문제를 해결할 수 있습니다.
이중 모드 애플리케이션은 특정 애플리케이션의 사용 모드와 관련된 용어로, 자기 주의의 이점과는 별개의 개념입니다. 따라서, 올바르지 않는 선택지로 "이중 모드 애플리케이션"을 고른 것입니다.
2. 다음 문장의 빈칸에 들어갈 가장 적절한 단어를 고르시오.
“ 자기주의(Self-attention), 확장된 도트-제품 주의라고도 하는 확장된 도트-제품 주의는 _____ 및 _________의 메커니즘으로, 각 요소를 처리할 때 모델이 입력 시퀀스의 다른 부분에 집중할 수 있게 함”
읭
자연어 처리랑 딥러닝 인가요?
올바른 선택지는 "1. 딥러닝, 자연어처리"입니다.
자기주의(Self-attention) 또는 확장된 도트-제품 주의는 딥러닝과 자연어 처리(Natural Language Processing, NLP) 분야에서 널리 사용되는 메커니즘입니다. 이 메커니즘을 통해 모델은 입력 시퀀스 내의 각 요소를 처리할 때, 시퀀스의 다른 부분에 어떻게 집중해야 하는지를 학습할 수 있습니다. 이는 특히 문장이나 문서 등의 자연어 데이터를 처리할 때, 문맥 이해와 의미 파악에 큰 도움을 줍니다.

3.다음 문제 중 올바르지 않는 것을 고르시오.
트랜스포머 모델의 구성 요소가 아닌것은?
인코더 디코더 다 있고, 위치 기반으로 진행하는데 임베딩이 모델의 구성요소 인가...?
임베딩 된 것을 트랜스 포머에 집어 넣는거 같은데
올바르지 않는 선택지는 "4. 위치 기반 피드 포워드 네트워크"입니다.
트랜스포머 모델의 주요 구성 요소는 인코더(encoder), 디코더(decoder), 임베딩(embedding)입니다. 위치 인코딩(Positional Encoding)이 트랜스포머 모델에 포함되어 시퀀스의 위치 정보를 제공하지만, "위치 기반 피드 포워드 네트워크"는 트랜스포머 모델의 구성 요소가 아닙니다. 트랜스포머 모델의 각 인코더 및 디코더 레이어에는 위치와 상관없이 동일한 처리를 하는 피드 포워드 네트워크(Feed Forward Network, FFN)가 포함되어 있습니다.

...?

인코더에 위치 기반 피드 포워드 네트워크가 존재하고, 트랜스 포머에는 임베딩을 직접 하진 않으니까 임베딩이 정답 아닌가...?
트랜스포머 모델의 구성 요소가 아닌 것을 고르는 문제입니다. 트랜스포머 모델에는 인코더, 임베딩, 디코더가 포함되어 있습니다. 그러나 위치 기반 피드 포워드 네트워크는 트랜스포머 모델의 표준 구성 요소가 아닙니다. 트랜스포머 모델에서는 위치 인코딩을 사용하여 단어의 순서 정보를 제공하지만, '위치 기반 피드 포워드 네트워크’라는 용어는 트랜스포머 모델의 표준 구성 요소가 아닙니다. 따라서 올바르지 않은 선택지는 4번입니다. 😊
코파일럿까지 이러면 내가 뭐 어쩔 수 없지...
아니 임베딩 맞잖아;
4. 다음 문장의 빈칸에 들어갈 가장 적절한 단어를 고르시오.
“ 워드임베딩(Word embedding)은 단어를 고차원 벡터 공간에서 밀도가 높은 벡터로 표현하는 ____의 기술이다”
자연어 처리의 기술이죠. NLP !
한글 쓸꺼면 한글만 써줬으면...

올바른 선택지는 "3. NLP"입니다.
워드임베딩(Word embedding)은 자연어 처리(Natural Language Processing, NLP)의 기술로, 단어를 고차원 벡터 공간에서 밀도가 높은 벡터로 표현합니다. 이 방법을 통해 컴퓨터는 단어 간의 의미적 관계를 학습하고 이해할 수 있게 됩니다.
5. 다음 문제 중 올바르지 않는 것을 고르시오.
멀티 헤드 어텐션(Multi-Head Attention)의 장점이 아닌것은?
오잉 축소는 누가봐도 아니네요

올바르지 않는 것은 "2. 상황별 이해도 항상"입니다.
멀티 헤드 어텐션의 장점으로는 빠른 연산, 다양한 관점에서의 정보 통합으로 인한 향상된 성능, 그리고 다양한 부분에 대한 동시 주의를 가능하게 하는 축소(reduction)가 있습니다. 하지만 "상황별 이해도 항상"이라는 표현은 멀티 헤드 어텐션의 장점을 정확하게 설명하지 않습니다. 멀티 헤드 어텐션은 모델이 다양한 관점에서 정보를 통합할 수 있게 함으로써 상황별 이해를 개선할 수는 있지만, 이해도가 '항상' 향상된다고 보장할 수는 없습니다.
GPT5 빨리 나와라....
멀티 헤드 어텐션(Multi-Head Attention)의 장점이 아닌 것을 고르는 문제입니다. 멀티 헤드 어텐션은 여러 개의 어텐션 메커니즘을 병렬로 사용하여 서로 다른 부분을 동시에 주목할 수 있게 합니다. 이로 인해 빠른 연산과 향상된 성능을 기대할 수 있습니다. 또한, 다양한 관점에서 정보를 처리할 수 있어 상황별 이해도가 높아집니다.
그러나 "상황별 이해도 항상"이라는 표현은 멀티 헤드 어텐션의 장점을 정확하게 설명하지 않습니다. 멀티 헤드 어텐션은 상황별 이해도를 향상시킬 수는 있지만, 모든 상황에서 항상 이해도가 높다고 보장할 수는 없습니다. 따라서 올바르지 않은 선택지는 2번입니다. 😊
코파일럿도....
5주 차
1차시 - Transformer - 영상 패치 임베딩
Image Patch Embedding : 컴퓨터 비전 분야에서 사용되는 기술로 이미지를 작은 패치 단위로 분할 후 각 패치를 고정된 차원의 벡터로 변환하는 과정
패치 단위로 이미지를 처리하기 때문에 작은 지역적 특징을 잘 포착할 수 있고, 패치 간의 관계를 모델에 반영하기 쉽고, 이미지의 전역적인 특징과 지역적 특징을 모두 고려하는 효과를 얻을 수 있다. 또한 패치 단위로 이미지를 처리하므로 입력 크기가 고정되며, 큰 이미지를 다루는 데에도 효율적이다.
영상 패치 임배딩 방법
Transformer는 1D embedding을 필요로 하므로 이미지 패치를 만드로 1D embedding으로 만든다.
단어 처럼 이미지 나누기 -> 분할된 이미지를 N 차원 공간에 embedding(매핑)
영상을 패치로 나누기
단어 삽입을 수행할 때 문장의 구분은 매우 명확하다
그러나 사진은 특별히 뚜렷한 구분선이 없기 때문에 2D 사진을 1D Vector로 직접 가져오는데 이렇게 하면 계산 리소스가 과도하게 소모되고, 이미지 크기에 제한이 있다.
[H,W,C] -> [N, P, P, C] (N: 패치 개수, P : 패치 크기 => N = H * W / (P * P)
N 차원 공간 매핑
각 패치 이미지를 평평하게 만든다 (Embedding_dim D = p*p*c)
이미지의 치수는 N,D로 표현 가능하다. -> 2D 이미지를 1D 패치로 매핑한다.
ViT 가 발전하여 Swin, PVT 등이 나왔다.
2차시 - Transformer - ViT 모델
ViT는 영상 분류(Image Classification)을 하고자 하며 Input으로 새로운 이미지가 입력되었을 때 분류한다.
패치 평탄화 및 임베딩, Transformer encoder, MLP 헤드로 이루어져 있다.
Flatten Patchs
input 이미지를 196개의 패치로 나눠준다.( 224 * 224 * 3 -> N * 16 * 16 * 3)
이 패치를 평평하게 만들어 768 크기의 vector 196개를 얻는다.(3, 244, 244 -> 196, 3, 16, 16 -> 196, 768)
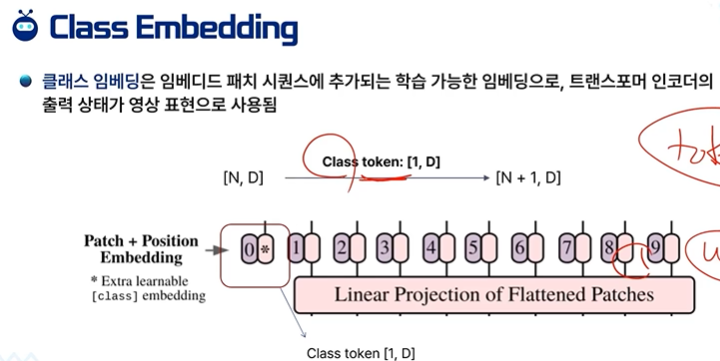
Class Embedding
임베딩 패치 시퀸스에 추가되는 학습 가능한 임베딩으로 Transformer Encoder의 출력 상태가 영상 표현으로 사용됨
[N,D] -> [N+1 , D] Class token이 붙은 것이다.
Position Embedding
순서대로 각각의 패치들을 embedding하여 transformer encoder에 넣어준다. 하지만 각각의 패치에는 순서가 중요하며 가장 앞부분에 position embedding을 주어 위치를 보전한다.
Transformer Encoder
Multi-Head Self Attention Layer (MSP) : 이미지의 loacl, global적인 의존성을 학습한다. 차원에 맞게 연결해준다.
Layer Norm(LN) : 이미지 간 의존성을 포함하지 않기 때문에 각 블록 앞에 추가함
Residual Cinnections : 네트워크를 직접 흐를 수 있도록 연결해줌
Multi-Layer Perceptrons (MLP) Layer = FCN :Gaussian Error Linear Unit(GELU)가 있는 두 개의 레이어가 포함
GELU도 activation functino이었네요
https://blog.naver.com/vail131/222239155999
활성화함수 sigmoid / tanh / ReLU / GeLU
왜 여러개가 존재하며 각각의 쓰임새는 무엇일까? AI를 공부하며 자주 접하게 되는 활성화함수(Activata...
blog.naver.com
MLP HEAD : 학습 가능한 클래스 토큰이 추가되어 분류 작업을 수행할 때 클래스 토큰만 가져간다.
Vit 성능
ViT는 기존 CNN 모델들과 다른 특징을 가지며, 많은 작업들에서 뛰어난 성능을 보여주고 있다.
데규모 데이터셋에서 pre trained viT 모델을 작은 데이터 셋으로 Transfer Learning 시킬 때 좋은 결과를 얻을 수 있으며, 이를 통해 소량의 데이터로도 강력한 이미지 인식 모델을 구축 할 수 있다.
ViT 한계 및 단점
계산 비용 : CNN 모델보다 계산 비용이 높으며, 이미지를 패치 단위로 분할하고 Transformer에 적용하는 과정이 연산량이 커서 시간과 자원이 더 필요하다.
데이터 양과 크기 : 대규모 데이터 셋에서 가장 잘 작동하지만 작은 데이터 셋에서는 pre trained가 충분하지 않을 수 있고, overfitting 문제가 발생할 수 있으므로 ViT를 작은 데이터 셋에서 사용하려면 전이 학습 등의 기법을 활용해야한다.
이미지 크기 제한 : 이미지를 작은 패치로 분할하므로 입력 이미지 크기가 모델의 성능에 영향을 미친다. 패치 크기도 적절히 선택해야 하고, 큰 이미지를 다루기 힘들 수 있다.
공간 정보 손실 : 패치 단위로 이미지를 처리하는 것은 공간적인 정보를 일부 손실 할 수 있으며, 작업에 따라 공간적 특징을 잘 포착하지 못할 수 있다.
패치 크기와 모델 크기 조정 : 패치 크기와 모델 크기는 성능에 영향을 미치는 하이퍼 파라미터이며, 적절한 선택이 중요하고, 이를 조절하는데 시간과 자원을 소모해야 한다.
자연어 처리에 비해 초기 개발 단계 : Transformer 모델은 주로 자연어 처리에 적용되었으며, CV로 확장된지 얼마 되지 않았으며, 따라서 여전히 최적화나 특화된 구조가 아닐 수 있다.
3차시 - Transformer - U - net 형 model
U-net : Image Segmentation 즉 각 픽셀마다 class를 할다하는 작업을 하려고 한다.
각 픽셀마다 N개의 클래스에 대한 확률을 나타내야 하므로 H * W * N 형태를 나타낸다.
U-Net 모델 네트워크 : encoder - decoder 구조이다.
encoder : pooling layer로 공간 차원을 줄인다. skip connection을 통해 정보를 전달한다.
decoder : 디테일과 공간 차원을 복구한다. Transposed Conv를 통해 차원을 두배로 늘림
encoder와 decoder 사이에 skip, residual connection이 존재하여 디코더가 객체의 세부 사항을 잘 복구하게 한다.
Encoder의 Convolution Block - 3*3 conv n개 + Batch Norm + ReLU가 반복됨 = ConvBlock
EncoderBlock = ConvBlock + Max pooling + skip connection
Decoder Block = Conv Transpose + concat + ConvBlock
Prediction Network - 출력하는 부분으로 1*1 conv를 통해 feature map을 처리하여 카테고리 개수 만큼 필터를 쓴다.
class가 1개라면 sigmoid를, 여러개라면 soft max를 사용한다.
U-Net 장점
sementation에 적합한 구조 : Fully Convolution Network (FCN)의 한 종류로서, segmentation task에 적합한 구조이다.
U자형 구조 : 영상의 공간적인 정보를 보존하면서 크기를 줄이고, feature를 추출하는데 용이. 구조를 분할할 때 효과적
데이터 부족 문제 해결 : 작은 데이터 셋에서도 잘 작동하며, 데이터가 부족한 의료 영상 분야에서 장점이다.
다양한 응용 분야 : 자율 주행 자동차, 얼굴, 사물 인식 등 다양한 분야에서 활용 중이다.
U-Net 단점, 한계
채널 정보 제한 : 채널 정보가 반복적으로 축소 되기 때문에 깊이가 증가할 수록 전체적인 특징 파악이 어렵다
클래스 불균형 문제 : 특정 class 픽셀이 매우 적은경우 segmentation 성능이 떨어질 수 있다.
정확도와 속도의 트레이드 오프 : 높은 정확도를 보이지만 상대적으로 느릴 수 있으며, 큰 이미지엔 리소스가 많이 든다.
이미지 회전 등의 변환에 민감함 : 회전, 크기 변경 등 변환에 민감하여 데이터 증강 기법을 사용해 보정해야 한다.
그런데 이게 왜 transformer?
4차시 - Multi-Head Attention
Multi-Head Attention은 입력의 여러 부분의 관련성을 파악하기 위한 attention 메커니즘의 확장
NLP에서 Multi-Head Attention은 각 위치가 동시에 다른 위치에 미치는 의존성을 파악할 수 있게 해준다.
CV에서는 서로 다른 영역의 픽셀 간에 종속성이 있는 이미지 분할 작업과 같은 이미지 데이터에도 Multi-Head Attention을 사용하여 서로 다른 영역 간의 관꼐를 더 잘 캡쳐할 수 있다.
CV에서 Multi-Head Attention
Soft Attention : 가중치가 적용된 특징 표현을 어딕 위해 입력 데이터의 가중치 평균을 의미 - 그라데이션식
Hard Attention : 가장 중요한 데이터를 선별하여 모델의 입력으로 사용하기 위해 입력 데이터를 선택하는 것 - 0,1
소프트 어텐션
0~1 사이로 가중치가 할당되어 출력에서 해당 부분의 중요성을 나타내며 모든 가중치의 합계는 1이 된다.
그림의 물체, 색상, 질감 등과 같이 그림의 여러 부분에 서로 다른 수준의 attention을 기울일 수 있다.
하드 어텐션
입력 데이터의 고정된 부분에만 집중할 수 있으며 모델의 계산 노력을 줄여주지만 정확도가 저하될 수 있다.
특정 영역을 명시적으로 선택하는데 전체 그림의 국소화된 영역일 수도 있고, 객체나 영역일 수 있다.
Multi-Head Attention의 장점
다양한 관점 학습 : 각 헤드가 서로 다른 관점에서 정보를 추출하므로 여러 가지 특징을 학습 가능
표현 능력 강화 : 여러 헤드를 사용하면 attention 메커니즘의 표현 능령이 강화되어 더 복잡한 패턴, 관계 학습
병렬 처리 가능 : 각 헤드가 독립적으로 계산되기 때문에 병렬 처리 가능 => 학습 추론 속도 향상 가능
5차시 - 영상 트랜스포머 응용 1
Transformer의 영상 분류
종종 CNN과 함꼐 사용된다
ViT는 입력을 패치로 분할하고, Transformer Encoder에 전달하여 기존 CNN보다 더 뛰어나고 해석 가능성을 제공
Transformer에 의한 물체 감지
입력 이미지를 패치로 분할하고, 패치에 대해 객체를 감지하고 분류하는데 Transformer가 사용된다.
DETR은 입력 이미지를 feature Vector 집합으로 인코딩하고 Transformer의 Decoder를 사용하여 객체의 위치와 Class를 예측하는 Transformer 기반 표적 감지 모델이다. COCO 데이터 셋에서 기존 모델과 성능이 비슷하지만 훨씬 더 간단, 효율적
Image Segmentation
CNN에 비교하여 더 정확한 segmentation을 제공할 수 있으며 Self-attention을 통해 더 넓은 영역의 정보 파악 가능
SERT은 Encoder외에도 Convolution Decoder가 Segmentation 작업을 수행하는데 사용된다 ????
사용 가능성과 발전 가능성
멀티 모달 처리 : 다른 센서 정보와 결합하여 Multi Modal 처리에 사용될 수 있다.
지능형 로봇 및 드론 : 지능형 시스템에서 활용되거나, 로봇의 시각적 환경 인식, 드론의 공간 탐색에 활용
증강 현실 및 가상 현실 : AR과 VR 환경을 구상하거나 돕는데 사용할 수 있으며, 실제 영상 기반으로 만들 수 있다.
의료 영상 분석과 진단 : 더 정확한 진단을 제공하는데 활용될 수 있다.
환경 모니터링 및 보안 : CCTV를 통해 이상 행동이나 위험 요소 감지 및 모니터링, 보안에 활용될 수 있다.
퀴즈
1. 다음 문제 중 올바르지 않는 것을 고르시오.
U-Net의 장점 및 성능의 이점이 아닌것은?

올바르지 않는 것은 "4. 채널 정보 제한"입니다.
U-Net은 의료 이미지 세그멘테이션과 같은 작업에서 뛰어난 성능을 보이는 구조로, 다음과 같은 특징을 가집니다:
1. **세그멘테이션에 적합한 구조**: U-Net은 다운샘플링과 업샘플링을 통해 이미지의 세그멘테이션을 효과적으로 수행할 수 있는 구조를 가지고 있습니다. 이는 세그멘테이션 작업에 매우 적합합니다.
2. **데이터 부족 문제 해결**: U-Net은 작은 데이터셋으로도 효과적인 학습이 가능하게 설계되었습니다. 데이터 증강(augmentation)과 같은 기법을 통해 데이터 부족 문제를 해결할 수 있습니다.
3. **U자형 구조**: U-Net의 명칭은 그 구조가 'U'자 형태를 닮았기 때문에 붙여졌습니다. 이 구조는 컨텍스트 정보와 위치 정보를 효과적으로 결합하여, 높은 정밀도의 세그멘테이션 결과를 도출할 수 있게 합니다.
4. **채널 정보 제한**: 실제로 U-Net은 채널 정보를 제한하지 않습니다. 오히려, U-Net 구조는 특징 맵(feature map)의 채널 수를 점진적으로 증가시키면서 이미지의 세부 정보를 효과적으로 포착합니다. 따라서, "채널 정보 제한"은 U-Net의 장점이나 성능 이점이 아니며, 오히려 U-Net은 다양한 채널 정보를 활용하여 세그멘테이션의 정확도를 높입니다.
2. 다음 문장의 빈칸에 들어갈 가장 적절한 단어를 고르시오.
“ 트랜스포머는 처음에 ________ 및 텍스트 생성과 같은 _______에 사용하기 위해 제안 되었음”
이미지분석, 신호처리
자동번역, 데이터 마이닝
기계 번역, 자연어 처리
트랜스포머는 자연어 처리를 위해 나왔죠. 즉 4번 밖에 없네요
가장 적절한 단어는 "4. 기계 번역, 자연어 처리"입니다.
트랜스포머 모델은 처음에 기계 번역 및 텍스트 생성과 같은 자연어 처리(NLP) 작업에 사용하기 위해 제안되었습니다.
3. 다음 문장의 빈칸에 들어갈 가장 적절한 단어를 고르시오.
“ 클래스 임베딩(Class Embedding)은 임베디드 패치 시퀀스에 추가되는 학습 가능한 _______으로, 트랜스포머 인코더의 출력 상태가 이미지 표현으로 사용됨”
읭 문제에 답이 있네요
가장 적절한 단어는 "1. 임베딩"입니다.
클래스 임베딩(Class Embedding)은 임베디드 패치 시퀀스에 추가되는 학습 가능한 임베딩으로, 트랜스포머 인코더의 출력 상태가 이미지 표현으로 사용됩니다.
4. 다음 문장의 빈칸에 들어갈 가장 적절한 단어를 고르시오.
“ 영상 패치 임베딩 (Image Patch Embedding)은 컴퓨터 비전 분야에서 사용되는 기술 중 하나로, 이미지를 작은 _____단위로 분할하고 각 패치를 고정된 차원의 _____로 변환하는 과정”
어우야 패치 단위로 분할하고 백터로 변환한다고 했었죠

가장 적절한 단어는 "3. 패치, 벡터"입니다.
영상 패치 임베딩 (Image Patch Embedding)은 컴퓨터 비전 분야에서 사용되는 기술 중 하나로, 이미지를 작은 패치 단위로 분할하고 각 패치를 고정된 차원의 벡터로 변환하는 과정입니다.
5. 다음 문장의 빈칸에 들어갈 가장 적절한 단어를 고르시오.
“ 컴퓨터 비전에는 일반적으로 사용되는 두 가지 어텐션 메커니즘, 즉 ______과 _______이 있음”
음 소프트와 하드!

가장 적절한 단어는 "3. 소프트 어텐션, 하드 어텐션"입니다.
컴퓨터 비전에는 일반적으로 사용되는 두 가지 어텐션 메커니즘, 즉 소프트 어텐션과 하드 어텐션이 있습니다.
'인공지능 > 공부' 카테고리의 다른 글
| 생성형 인공지능 입문 11 ~ 14주 차 정리, 퀴즈 (1) | 2024.06.14 |
|---|---|
| 생성형 인공지능 입문 6~7, 9 ~10 주 차 정리, 중간 고사, 퀴즈 (1) | 2024.06.13 |
| 모두를 위한 머신러닝 기말고사 (0) | 2024.06.10 |
| 모두를 위한 머신러닝 9 ~ 14주차 정리 (0) | 2024.06.10 |
| 모두를 위한 머신러닝 1 ~ 7주차 정리 (0) | 2024.06.09 |