728x90
728x90
import tensorflow as tf
import numpy as np
import pandas as pd
from keras.datasets.mnist import load_data
from keras.models import Sequential, Model
from keras.layers import Dense, Input ,Flatten, Dropout, Conv2D, MaxPooling2D, GlobalAveragePooling2D,Conv1D, MaxPooling1D, GlobalAveragePooling1D,LSTM
from keras.utils import plot_model, to_categorical
from keras.regularizers import l2
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
from tensorflow.keras.callbacks import ModelCheckpoint
from tensorflow.keras.models import load_model
import scipy.io
tf.debugging.set_log_device_placement (False)
import tensorflow_decision_forests as tfdf
import h5py
import seaborn as sns
from sklearn.metrics import confusion_matrix
import itertools
from tensorflow.keras import layers, models
from tensorflow.keras.optimizers import RMSprop
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.callbacks import ReduceLROnPlateau항상 맨 앞줄에서 없으면 섭섭한 친구들
print('Loading and Visualizing Data ...')
A_scan_amp = scipy.io.loadmat( "/kaggle/input/2-data/과제2_Data/A_scan_amp.mat" )
A_scan_time = scipy.io.loadmat("/kaggle/input/2-data/과제2_Data/A_scan_time.mat")
FFT_frequency = scipy.io.loadmat("/kaggle/input/2-data/과제2_Data/FFT_frequency.mat")
FFT_magnitude = scipy.io.loadmat("/kaggle/input/2-data/과제2_Data/FFT_magnitude.mat")
with h5py.File('/kaggle/input/2-data/과제2_Data/STFT_ArbMag.mat', 'r') as file:
# 파일 내의 데이터셋 이름 확인
print(list(file.keys()))
STFT_ArbMag = file['STFT_ArbMag'][:]파일 읽는데 파일 중 하나가 scipy로는 읽히지 않아서 h5py를 사용하여 읽었다.
FFT_magnitude= FFT_magnitude['FFT_Magtitude']
FFT_frequency = FFT_frequency['FFT_frequency']
A_scan_amp = A_scan_amp['A_scan_Amp']
데이터 형 정리하기 !
728x90
A_scan_amp_train = A_scan_amp[:,21*12:]
A_scan_amp_test = A_scan_amp[:,:21*12]
FFT_magnitude_train = FFT_magnitude[:,21*12:]
FFT_magnitude_test = FFT_magnitude[:,:12*21]
STFT_ArbMag_train = STFT_ArbMag[21*12:,:,:]
STFT_ArbMag_test = STFT_ArbMag[:12*21,:,:]
A_scan_amp_train = A_scan_amp_train.reshape(1638,10001,1)
A_scan_amp_test = A_scan_amp_test.reshape(252,10001,1)
FFT_magnitude_train = FFT_magnitude_train.reshape(1638,3504,1)
FFT_magnitude_test = FFT_magnitude_test.reshape(252,3504,1)
STFT_ArbMag_train = STFT_ArbMag_train.reshape(1638,1836,100,1)
STFT_ArbMag_test = STFT_ArbMag_test.reshape(252,1836,100,1)트레이닝, TEST 데이터 나누고, 사용하기 편하게 형태도 바꿔준다.
A_scan_amp_train_sclae = A_scan_amp_train/np.max(A_scan_amp_train)
A_scan_amp_test_sclae = A_scan_amp_test/np.max(A_scan_amp_train)
FFT_magnitude_train_sclae = FFT_magnitude_train/np.max(FFT_magnitude_train)
FFT_magnitude_test_sclae = FFT_magnitude_test/np.max(FFT_magnitude_train)
STFT_ArbMag_train_sclae = STFT_ArbMag_train/np.max(STFT_ArbMag_train)
STFT_ArbMag_test_sclae = STFT_ArbMag_test/np.max(STFT_ArbMag_train)그래프가 그려지는 데이터들이 많아서 그래프의 모양을 유지하기 위해 최대값을 1로 만들었다.
vector = np.arange(0, 105, 5)
y_test = np.tile(vector, 12)
y_train = np.tile(vector, 90-12)정답자체가 이렇게 분포된 데이터이므로 만들어준다.
def r_squared(y_true, y_pred):
ss_res = tf.reduce_sum(tf.square(y_true - y_pred))
ss_tot = tf.reduce_sum(tf.square(y_true - tf.reduce_mean(y_true)))
r2 = 1 - ss_res / ss_tot
return r2
def r_squared_numpy(y_true, y_pred):
ss_res = np.sum(np.square(y_true - y_pred))
ss_tot = np.sum(np.square(y_true - np.mean(y_true)))
r2 = 1 - ss_res / ss_tot
return r2
판단 지표에 대한 함수도 만들어준다.
checkpoint_path = "best_model.h5"
checkpoint = ModelCheckpoint(
checkpoint_path,
monitor='val_loss', # 검증 손실을 모니터링
verbose=1,
save_best_only=True, # 가장 좋은 모델만 저장
mode='min' # 'val_loss'의 경우 최소값이 최고 성능을 의미
)가장 좋을 때 저장하기 위해 체크 포인트를 만들어준다. h5가 오래되어 힘들다고 하지만 일단 여기선 내가 만든 평가지표이기 때문에 h5를 사용한다.
728x90
input_2d = tf.keras.Input(shape=(1836, 100, 1))
x = tf.keras.layers.Conv2D(32, (3, 3), activation='relu', padding = 'same')(input_2d)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Conv2D(64, (3, 3), activation='relu', padding = 'same')(x)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Conv2D(128, (3, 3), activation='relu', padding = 'same')(x)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Conv2D(256, (3, 3), activation='relu', padding = 'same')(x)
x = GlobalAveragePooling2D()(x)
x = tf.keras.Model(inputs=input_2d, outputs=x)
# 1D 데이터(예: 벡터)를 위한 입력 경로
input_1d = tf.keras.Input(shape=(10001,1))
y =Conv1D(filters=36, kernel_size=3, activation='relu', padding='same')(input_1d)
y = MaxPooling1D(pool_size=2)(y)
y =Conv1D(filters=64, kernel_size=3, activation='relu', padding='same')(y)
y = MaxPooling1D(pool_size=2)(y)
y =Conv1D(filters=128, kernel_size=3, activation='relu', padding='same')(y)
y = MaxPooling1D(pool_size=2)(y)
y =Conv1D(filters=256, kernel_size=3, activation='relu', padding='same')(y)
y = GlobalAveragePooling1D()(y)
y = tf.keras.Model(inputs=input_1d, outputs=y)
input_scalar = tf.keras.Input(shape=(3504,1))
z = Conv1D(filters=36, kernel_size=3, activation='relu', padding='same')(input_scalar)
z = MaxPooling1D(pool_size=2)(z)
z = Conv1D(filters=64, kernel_size=3, activation='relu', padding='same')(z)
z = MaxPooling1D(pool_size=2)(z)
z = Conv1D(filters=128, kernel_size=3, activation='relu', padding='same')(z)
z = MaxPooling1D(pool_size=2)(z)
z = Conv1D(filters=256, kernel_size=3, activation='relu', padding='same')(z)
z = GlobalAveragePooling1D()(z)
z = tf.keras.Model(inputs=input_scalar, outputs=z)
# 두 경로의 결합
combined = tf.keras.layers.concatenate([x.output, y.output, z.output])
# 추가 레이어 및 최종 예측 레이어
final_layer = tf.keras.layers.Dense(128, activation='relu', kernel_regularizer = l2(0.05))(combined)
final_layer = Dropout (0.2)(final_layer)
final_layer = tf.keras.layers.Dense(64, activation='relu', kernel_regularizer = l2(0.05))(final_layer)
final_layer = Dropout (0.2)(final_layer)
final_layer = tf.keras.layers.Dense(32, activation='relu', kernel_regularizer = l2(0.05))(final_layer)
final_output = tf.keras.layers.Dense(1)(final_layer) # 예: 이진 분류 문제
# 최종 모델
model = tf.keras.Model(inputs=[x.input, y.input, z.input], outputs=final_output)
# 모델 컴파일
model.compile(optimizer = tf.keras.optimizers.Adam(learning_rate = 0.001), loss='mse', metrics=[r_squared])네트워크는 convolution을 최대한 활용했다. 전부다 dense로 하기엔 feature수가 너무 많아 파라미터가 과하게 많아질 것을 방지하기 위해 convolution을 사용했고 마지막에 FCN은 최대한 단순하게, CNN은 최대한 깊게 했다.
plt.subplot(1,2,1)
plt.plot(hist.history['loss'],label = 'train loss')
plt.plot(hist.history['val_loss'], label = 'val loss')
plt.legend()
plt.subplot(1,2,2)
plt.plot(hist.history['r_squared'],label = 'train r_squared')
plt.plot(hist.history['val_r_squared'], label = 'val r_squared')
plt.legend()
그래프를 한번 확인하면 엄청난 오버피팅을 확인할 수 있다. 그래도 validation이 최소일 때 저장해놨기 때문에 그것을 그대로 사용해준다.
from tensorflow.keras.models import load_model
# 저장된 모델 파일 경로
saved_model_path = "best_model.h5"
# 모델 불러오기
loaded_model = load_model(saved_model_path, custom_objects={'r_squared': r_squared})
# 불러온 모델을 사용한 예측 또는 평가
# 예를 들어, 테스트 데이터셋에 대한 평가를 수행할 수 있습니다.
#loss, rsquare = loaded_model.evaluate([STFT_ArbMag_test, A_scan_amp_test, FFT_magnitude_test])
#print("Test Loss:", loss)
#print("Test rsquare:", rsquare)
batchsize = 21
yhat =[]
for i in range (0,252,batchsize) :
pred = loaded_model.predict([STFT_ArbMag_test_sclae[i:i+batchsize,:,:,:], A_scan_amp_test_sclae[i:i+batchsize,:,:], FFT_magnitude_test_sclae[i:i+batchsize,:,:]])
print(loaded_model.evaluate([STFT_ArbMag_test_sclae[i:i+batchsize,:,:,:], A_scan_amp_test_sclae[i:i+batchsize,:,:], FFT_magnitude_test_sclae[i:i+batchsize,:,:]],y_test[i:i+batchsize]))
yhat.extend(pred)일단 데이터가 너무 커서 kaggle GPU의 사이즈를 초과해버려서 배치를 줬다. 이렇게 하면 밑에 처럼 나온다.

yhat_array = np.concatenate(yhat, axis=0)
r2_value = r_squared_numpy(np.array(y_test), yhat_array)
print("R-squared:", r2_value)
plt.plot(y_test,label = 'real')
plt.plot(yhat_array, label = 'pred')
plt.legend()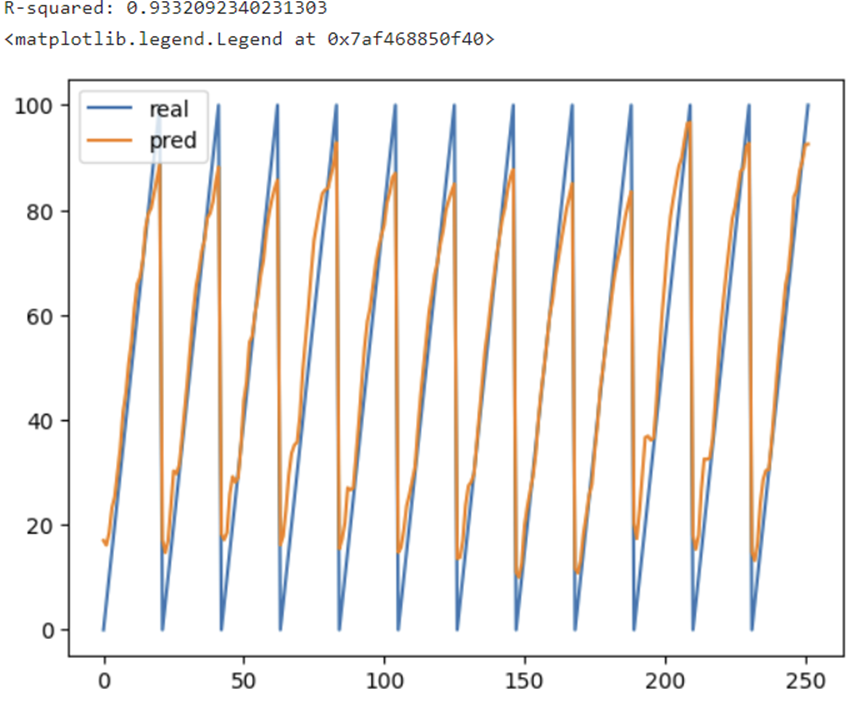
이렇게 결과를 확인해서 마무리할 수 있다.
내일은 아직은 안 배운 개념인 LSTM을 한번 배워보고 사용해보겠다.
728x90
'인공지능 > 공부' 카테고리의 다른 글
| 센서신호, FFT, STFT data를 통해 하중 예측하기 -3 스케쥴러 (34) | 2023.11.30 |
|---|---|
| 센서신호, FFT, STFT data를 통해 하중 예측하기 -2 LSTM (33) | 2023.11.30 |
| 드디어 첫 수상 (34) | 2023.11.27 |
| AI 챌린지 본선 (25) | 2023.11.24 |
| AI 챌린지 예선 (1) | 2023.11.24 |