https://aclanthology.org/2024.tacl-1.9/
Lost in the Middle: How Language Models Use Long Contexts
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, Percy Liang. Transactions of the Association for Computational Linguistics, Volume 12. 2024.
aclanthology.org
tacl 2024에 붙은 논문입니다.
장문의 컨텍스트를 입력으로 받는 LLM은 실제 컨텍스트 전체를 고르게 활용하냐?
-> LLM이 Long Context를 잘 활용하면 정답 정보의 위치가 성능에 영향을 주지 않아야 한다.
여러 문서 중 하나에만 정답이 존재하고, 정답 문서의 위치랑 문서 수를 조절해서 확인한다.
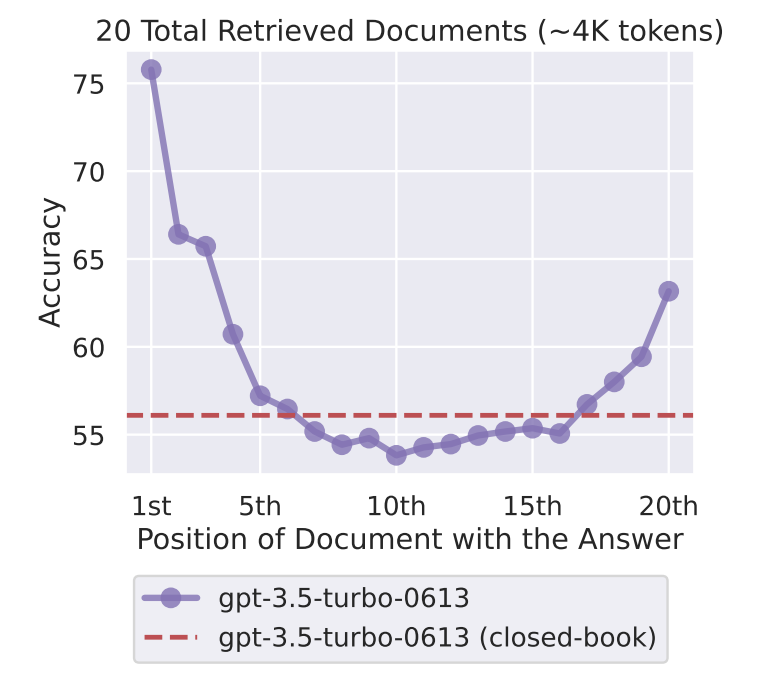
입력이 초반 또는 후반에 있을 때 최고 성능을 보여주고, 중간 위치에 존재하면 성능이 급락한다.


다들 성능이 나빠진다...
| 연구 문제 | 장문 컨텍스트(수천~수만 토큰)를 입력으로 받는 최신 LLM들이 실제로 컨텍스트 전체를 고르게 활용하는가? 특히 중간 위치 정보(middle context)를 제대로 사용하는지에 대한 실증적 분석 부족 |
| 핵심 가설 | 만약 LLM이 long context를 robust하게 활용한다면, 정답 정보의 위치가 성능에 거의 영향을 주지 않아야 함 |
| 주요 태스크 | (1) Multi-Document Question Answering (MD-QA) – 여러 문서 중 하나에만 정답 존재 – 정답 문서의 위치(앞/중간/뒤) 및 문서 수(k) 조절 (2) Key-Value Retrieval (Synthetic) – UUID 기반 key-value 쌍에서 특정 key의 value 추출 – 의미 정보 제거 → 순수 retrieval 능력 측정 |
| 평가 모델 | GPT-3.5 / GPT-3.5-16K, Claude-1.3 / 100K, MPT-30B-Instruct, LongChat-13B-16K, Flan-T5 / Flan-UL2, GPT-4(부분) |
| 핵심 결과 ① | U-shaped 성능 곡선 관찰 → 정답이 입력 초반(Primacy) 또는 후반(Recency)에 있을 때 성능 최고 → 중간에 위치하면 성능 급락 |
| 핵심 결과 ② | • GPT-3.5는 중간 위치에서 문서 제공 안 한 closed-book 성능보다 더 낮아짐 • Extended context 모델(16K, 100K)도 동일한 현상 → 컨텍스트 길이 증가 ≠ 활용 능력 향상 |
| Key-Value 실험 결과 | • 일부 모델(Claude)은 완벽에 가까움 • 다수 모델은 중간 key retrieval 실패 → reasoning 이전에 단순 retrieval부터 취약 |
| 원인 분석 ① | • Encoder-Decoder (Flan-UL2)는 훈련 시 본 길이 이내에서는 비교적 robust • 하지만 훈련 길이 초과 시 다시 U-shape 발생 |
| 원인 분석 ② | • Query를 앞+뒤에 배치하면 Key-Value retrieval은 거의 해결 • 그러나 MD-QA에서는 효과 미미 |
| 원인 분석 ③ | • Base 모델도 U-shape 존재 → Instruction tuning이 주원인은 아님 • 다만 worst-case 성능은 소폭 완화 |
| Case Study | • Retriever recall은 계속 증가 • Reader 성능은 20 docs 부근에서 포화 → 더 많은 문서 = 비용↑ / 성능↑ 거의 없음 |
| 핵심 결론 | 현재 LLM은 “long context를 받을 수 있을 뿐, 잘 쓰지는 못함” → 중간 정보 활용 실패는 구조적 한계 |
| 저자 제안 평가 기준 | Long-context LLM 주장 시, best vs worst 위치 성능 차이를 반드시 보고해야 함 |
| 실질적 시사점 | • RAG에서 reranking / truncation 필수 • 중요한 정보는 앞이나 뒤로 밀어야 함 • 단순히 “더 많이 넣기”는 역효과 가능 |
https://arxiv.org/abs/2601.07226
Lost in the Noise: How Reasoning Models Fail with Contextual Distractors
Recent advances in reasoning models and agentic AI systems have led to an increased reliance on diverse external information. However, this shift introduces input contexts that are inherently noisy, a reality that current sanitized benchmarks fail to captu
arxiv.org
최신 reasoning LLM과 Agentic AI는 RAG, 툴사용, 멀티턴 상호작용에 강하게 의존하지만 현실 환경에서는 무작위 문서, 무관한 대화 이력, 유사하지만 틀린 정보가 필연적으로 존재한다.
기존 벤치마크는 Clean 입력만 평가하여 실제 환경에서의 취약성이 가려진다.
=> Reasoning 모델과 Agent는 노이즈가 포함된 컨텍스트에서 얼마나 쉽게 붕괴되는가
RAG, 추론, 정렬, 툴 사용을 어우르는 11개의 데이터 셋을 통해 Noisy Bench를 만들었음

ND(No Distractor) - 기존 Clean 환경
RD(Random Documents) - 무작위 문서 삽입
RC(Random Chat History) - 무관한 대화 이력
HN(Hard Negative) - 질문과 겉보기 유사하지만 오답인 문서
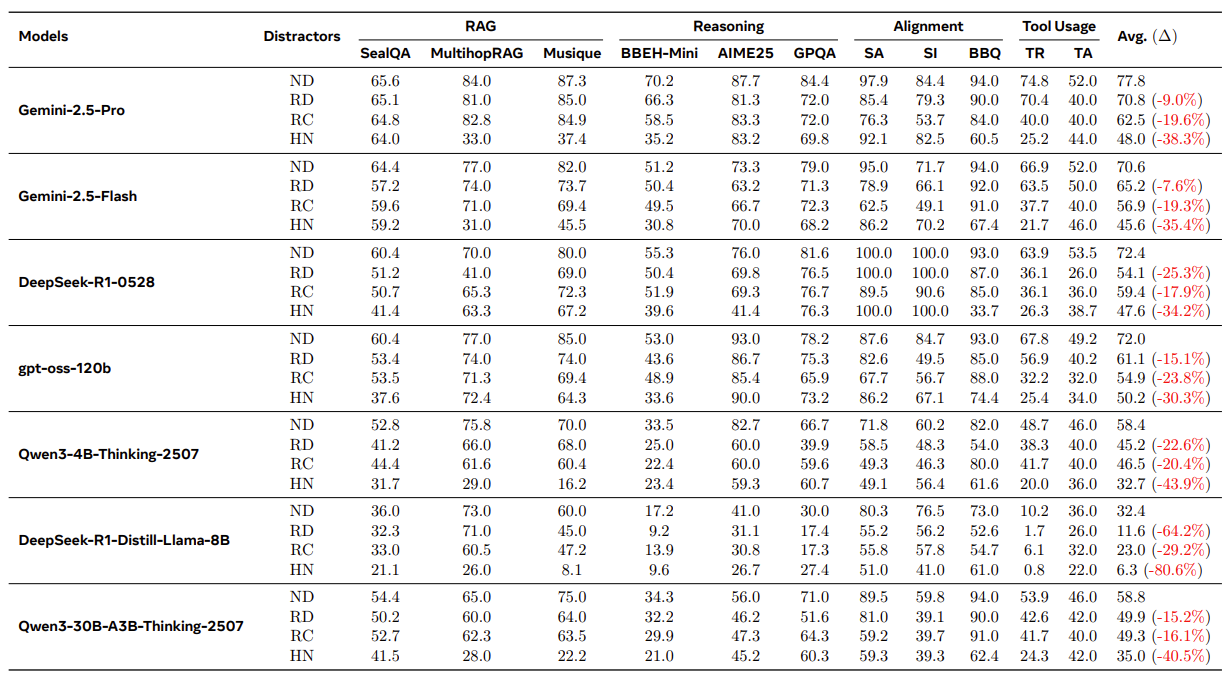
모든 모델에서 성능 붕괴가 일어남
HN가 가장 치명적으로 일어남!
악의 없는 랜덤 노이즈 만으로도 alignment 붕괴가 일어남
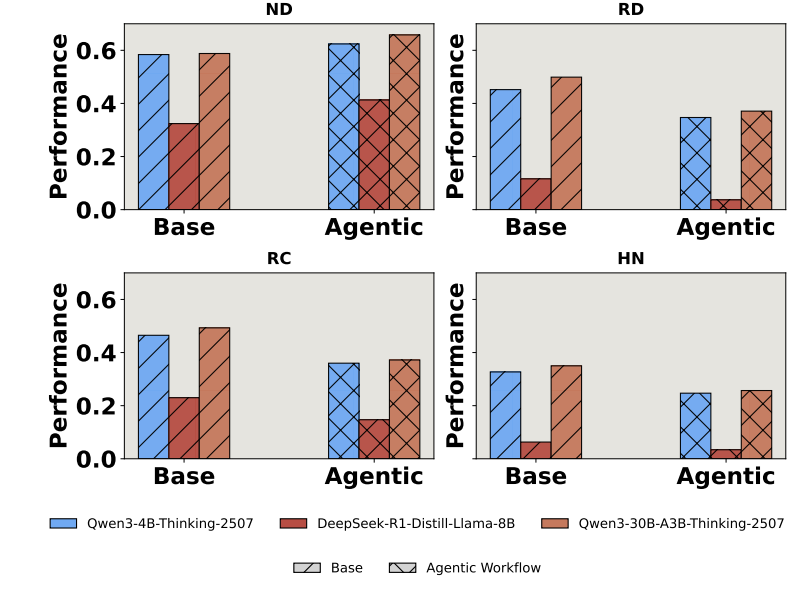
노말한 상호아에선 agentic이 성능이 좋지만 조금의 노이즈만 들어가도 agentic이 성능 감소폭이 더 심하다
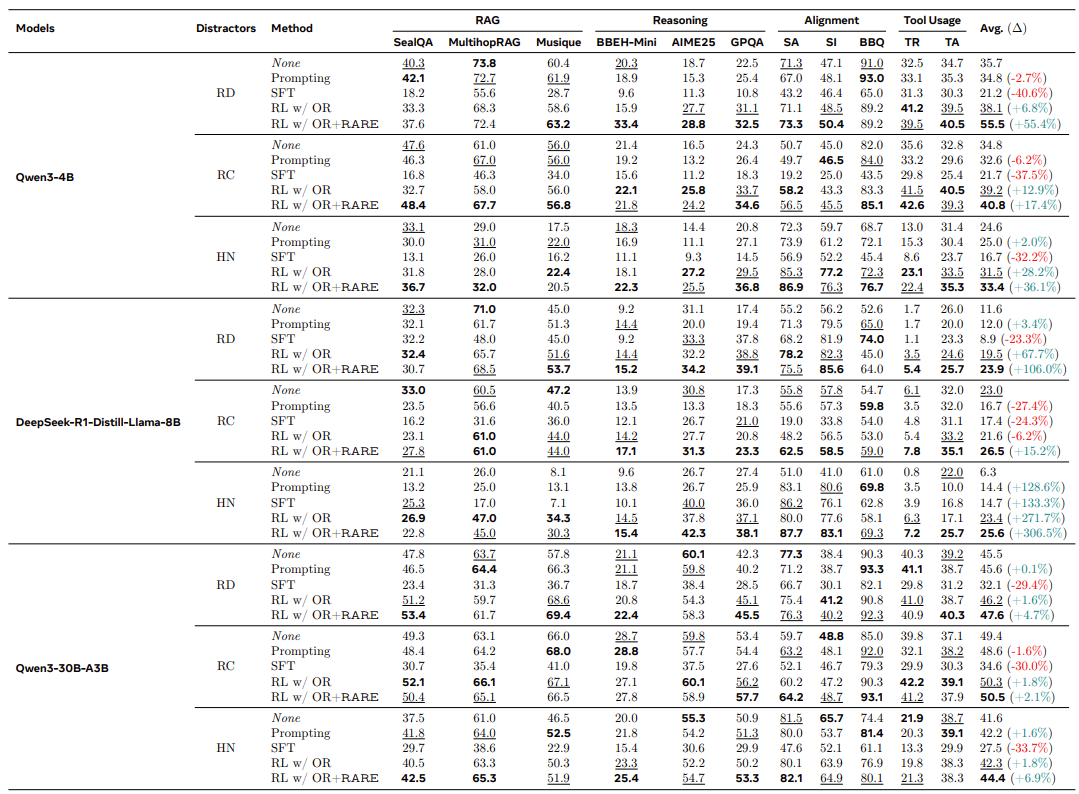
RARE - 정답 여부가 아니라 유용한 정보에 근거한 추론을 보상! => Accuracy 대폭 향상
| 연구 배경 | 현실의 LLM·Agent 환경은 무작위 문서, 무관한 대화 이력, 유사하지만 틀린 정보 등 노이즈가 필연적이나, 기존 벤치마크는 clean context만 평가 |
| 핵심 문제 | Reasoning LLM과 Agentic AI가 contextual distractor에 얼마나 취약한지, 그리고 그 실패 양상이 무엇인지 체계적으로 분석되지 않음 |
| 연구 목표 | (1) 노이즈 환경에서의 실제 추론·정렬·RAG·툴 사용 능력 측정 (2) 모델 실패의 원인 규명 (3) 견고성 향상 방법 제안 |
| 제안 벤치마크 | NoisyBench: 11개 데이터셋, 4가지 환경 ND(클린), RD(Random Docs), RC(Random Chat), HN(Hard Negative) |
| 평가 태스크 | RAG (SealQA, Musique 등) Reasoning (BBEH-Mini, GPQA, AIME25) Alignment (BBQ, SI) Tool-use (TauBench) |
| 대상 모델 | Gemini-2.5-Pro/Flash, DeepSeek-R1, GPT-OSS-120B, Qwen3 (4B/30B), Distilled LLaMA 등 |
| 주요 발견 ① | 최대 80% 성능 붕괴 발생 → Clean 성능이 높아도 Robustness 보장 안 됨 |
| 주요 발견 ② | 악의 없는 랜덤 노이즈만으로도 emergent misalignment 발생 (Alignment 성능 급락) |
| 주요 발견 ③ | Agentic workflow는 노이즈에서 오히려 더 취약 → Tool output 과신 + 오류 전파 |
| 행동 분석 | 질문–distractor 유사도 증가 시 Accuracy ↓, Reasoning token ↑ (혼동) |
| 불확실성 분석 | Distractor 수 증가 → Entropy 증가, Confidence 감소 |
| Attention 분석 | 오답일수록 distractor token에 과도한 attention 집중 |
| 중요 현상 | Inverse Scaling Law: 노이즈 환경에서는 test-time reasoning을 늘릴수록 성능 악화 |
| 기존 대응 한계 | Prompting, Context engineering: 효과 미미 SFT: catastrophic forgetting Outcome-only RL: 제한적 |
| 제안 방법 | RARE (Rationale-Aware Reward) → 정답 여부가 아닌, 유효 정보에 근거한 추론 과정을 보상 |
| RARE 효과 | Distracted CoT 감소, Noise filtering 능력 향상 평균 성능 +55% 개선 |
| 핵심 결론 | 현실적 노이즈 환경에서 LLM은 더 많이 생각할수록 더 틀릴 수 있음 |
| 연구적 시사점 | Robust reasoning = 토큰 수 증가 ❌ 정보 선택·억제 능력이 핵심 |
| 후속 연구 방향 | Noise-aware reward modeling Attention suppression Tool 신뢰도 추정 기반 Agent 설계 |
https://aclanthology.org/2025.findings-emnlp.1264/
Context Length Alone Hurts LLM Performance Despite Perfect Retrieval
Yufeng Du, Minyang Tian, Srikanth Ronanki, Subendhu Rongali, Sravan Babu Bodapati, Aram Galstyan, Azton Wells, Roy Schwartz, Eliu A Huerta, Hao Peng. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025.
aclanthology.org
EMNLP 2024 findings 에 붙었네요
기존 통념으론 Long-context LLM 성능 저하의 주 원인은 Retrieval failure이어서 정보를 제대로 찾지 못해서 성능이 떨어진다고 가정했다.
그러나 Retrieval 이 완벽하다면 긴 컨텍스트에서도 short-context와 동일한 성능을 낼 수 있는가? 라는 의문을 가지게 되었음
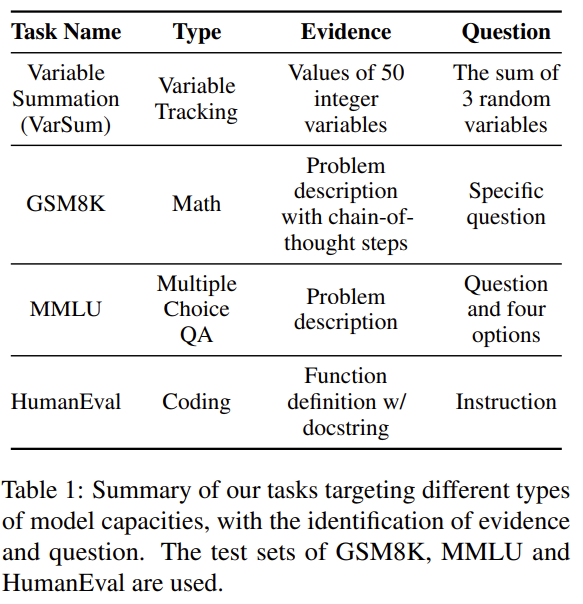
- Evidence: 문제 해결에 필요한 모든 정보
- Distraction: 길이만 늘리기 위한 토큰
- Question: 질의 및 출력 포맷
[Evidence] + [Distraction Tokens] + [Question]Evidence는 맨 앞에 넣어 Lost-in-the-Middle 문제를 제거

whitespace는 distraction을 최소화한 것으로 성능 저하
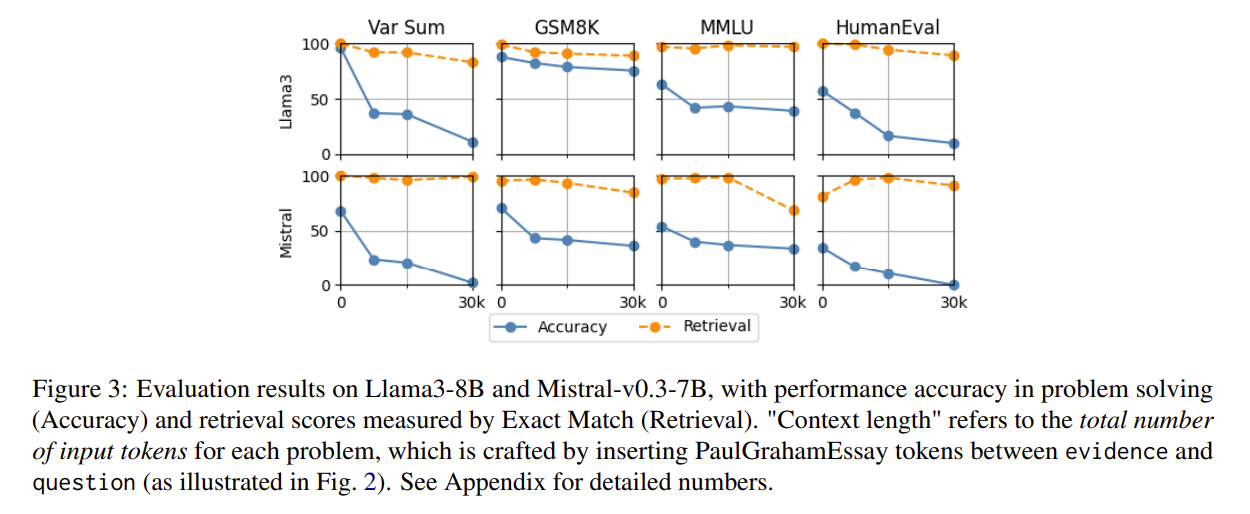
Retrieval 측정 방식은 Evidence와 Question을 토큰 단위로 100% 동일하게 복사 시 성공으로 Retrieval이 안 돼서 틀린 것이라는 반론을 차단
Retrieval은 성능이 좋으나 Accuracy 성능은 급락하는 것을 보여줌
=> 정보는 명확히 알고 있지만 사용하지 못하는 것을 알 수 있음
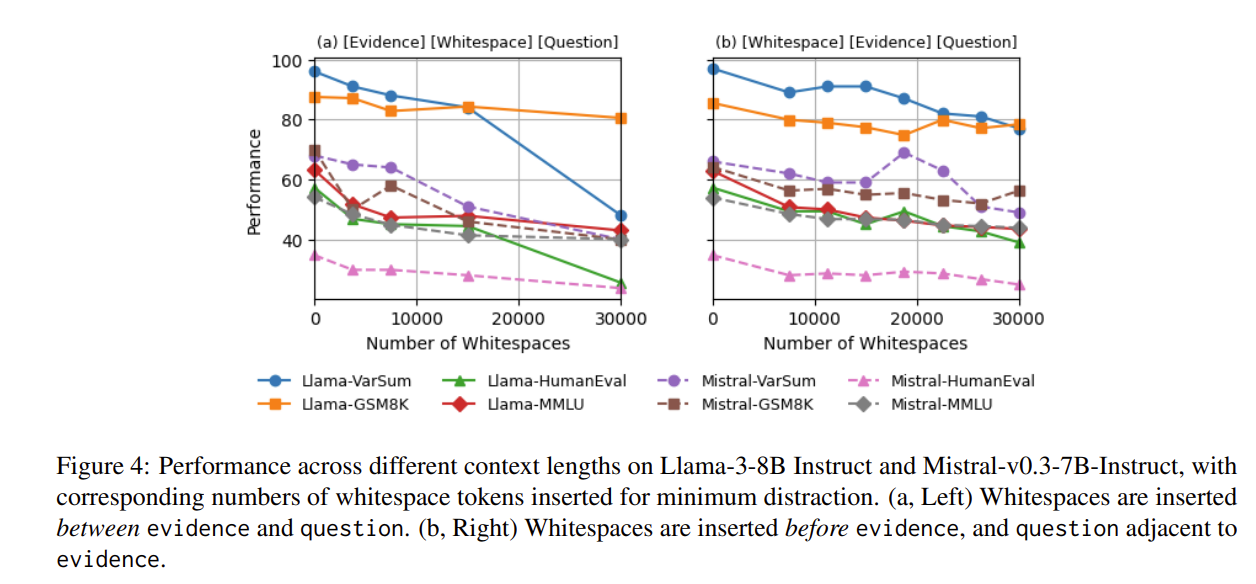
정보 위치를 바꿔도 그대로 못 함....
=> RTR로 LongContext에서 Evidence를 먼저 가져와서 question과 함께 새로운 짧은 prompt를 만든다.
그 다음 Reasoning을 실행!
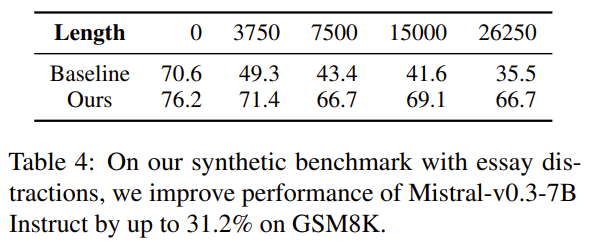
학습 없이 적용 가능함
| 연구 문제 | Long-context LLM 성능 저하의 원인이 정말 retrieval failure뿐인가? |
| 핵심 질문 | Retrieval이 완벽해도 컨텍스트가 길어지면 성능이 유지되는가? |
| 핵심 주장 | ❌ 아니다. 컨텍스트 길이 그 자체(context length alone)가 reasoning 성능을 직접 저해함 |
| 실험 핵심 아이디어 | Short-context 문제를 [Evidence + Distraction + Question] 형태로 확장하여 길이만 증가 |
| Retrieval 통제 | Evidence·Question을 exact match로 recite → 100% retrieval 확인 |
| 사용 태스크 | VarSum (synthetic), GSM8K (math), MMLU (QA), HumanEval (coding) |
| 사용 모델 | Llama-3.1-8B, Mistral-7B (open) / GPT-4o, Claude, Gemini (closed) |
| 주요 실험 조건 | (1) Essay distraction (2) Whitespace (최소 방해) (3) Attention masking (distraction 완전 제거) |
| 핵심 결과 ① | Retrieval 성능은 유지되지만 정답률은 최대 13.9%~85% 급락 |
| 핵심 결과 ② | Whitespace·Masking 상황에서도 성능 저하 발생 → distraction 원인 아님 |
| 핵심 결과 ③ | Evidence를 Question 바로 앞에 둬도 성능 저하 → distance/position 문제 아님 |
| 핵심 결론 | 입력 길이 자체가 LLM 추론 능력을 약화시키는 독립적 요인 |
| 제안한 해결책 | Retrieve-then-Reason: evidence를 먼저 recite → 짧은 prompt로 재질의 |
| 해결책 효과 | GSM8K: 최대 +31% RULER (GPT-4o): 최대 +4% 개선 |
| 이론적 시사점 | Long-context 성능 = Retrieval + Reasoning + Context-Length Effect |
| 실무적 의미 | RAG, Long-CoT에서 “많을수록 좋다”는 가정이 깨짐 |
| 한계 | 모델/태스크 수 제한, 완벽한 retrieval 가정 필요 |
| 한 줄 요약 | LLM은 정보를 “알아도”, 컨텍스트가 길면 “사용하지 못한다”. |
https://arxiv.org/abs/2505.06120
LLMs Get Lost In Multi-Turn Conversation
Large Language Models (LLMs) are conversational interfaces. As such, LLMs have the potential to assist their users not only when they can fully specify the task at hand, but also to help them define, explore, and refine what they need through multi-turn co
arxiv.org
마소 논문입니다.
기존 llm 평가는 single-turn에 과도하게 집중되어 있고, 실제 사용자 대화는 multi-turn + underspecified 형태가 일반적임
기존 Multi-turn Benchmark는 episodic 구조로 각 턴을 사실상 독립 평가 -> 현실과 괴리가 있다
==> LLM 정보가 여러 턴에 걸쳐 점진적으로 주어지는 대화에서, 신뢰성 있게 문제를 해결할 수 있는가!

Aptitude는 15% 떨어지고, Unreliability는 +112%로 잘할 수 있는데 결과의 편차가 큰 것을 볼 수 있음
| Underspecification | 초기에 모든 요구사항이 주어지지 않고, 대화 중 점진적으로 드러나는 상황 |
| Lost in Conversation | LLM이 초반에 잘못된 가정을 하고, 이후에도 이를 수정하지 못해 성능이 급락하는 현상 |
| Aptitude (A) | best-case 성능 (90th percentile) |
| Unreliability (U) | best–worst 성능 격차 (90th − 10th percentile) |
| Performance (P) | 평균 성능 |
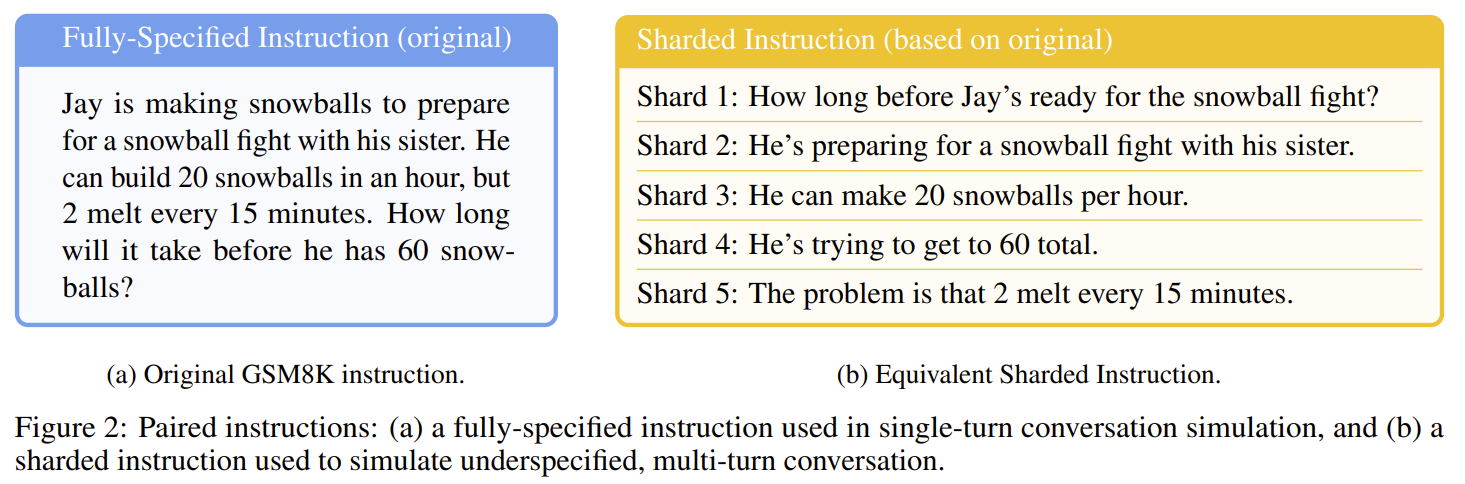
기존 single-turn benchmark를 정보 조각 단위로 분해해서 턴당 1개의 shard만 공개하여 마지막 턴에 모든 정보가 주어지도록 설계되어있다.

| 설정 | 설명 |
| FULL | 모든 정보가 1턴에 제공 (single-turn baseline) |
| SNOWBALL | multi-turn이지만 매 턴 모든 과거 정보를 누적 제공 |
| SHARDED | 진짜 multi-turn underspecified 대화 (핵심 실험) |

Translation task는 문장 단위로 분해가 가능한 episodic task로 sharded에서도 성능을 유지함
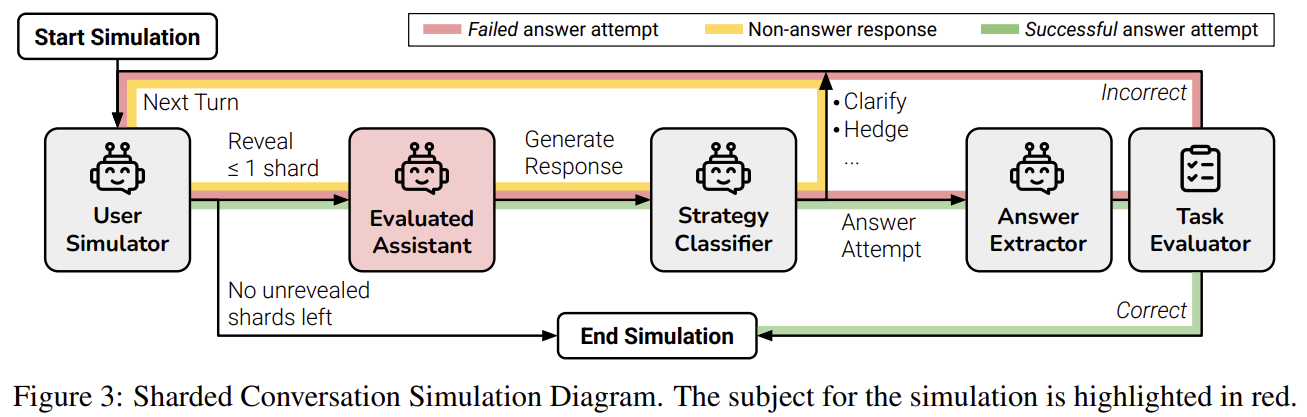
논문은 4가지 주요 원인을 실증적으로 분석함:
- Premature Answer Attempt
- 충분한 정보가 없는데도 초반에 완성 답변 생성
- 늦게 답변을 시작할수록 성능 ↑ (2배 이상 차이)
- Incorrect Assumptions
- underspecified 정보를 스스로 채워 넣음
- 이후 사용자 요구와 충돌해도 수정 실패
- Over-reliance on Previous Answers
- 이전의 잘못된 답변을 기준점(anchor)으로 삼음
- 결과적으로 bloated answer 생성
- Loss-in-Middle-Turns
- 중간 턴에서 제공된 정보가 무시됨
- 첫 턴/마지막 턴 정보에 과도하게 집중
| 연구 문제 | 기존 LLM 평가는 single-turn·fully-specified 설정에 치우쳐 있으며, 실제 사용 환경인 multi-turn·underspecified 대화에서의 성능과 신뢰성을 제대로 측정하지 못함. LLM이 대화 도중 잘못된 가정을 하면 이후 턴에서 회복하지 못하는 현상이 존재하는지 규명 |
| 핵심 가설 | LLM의 multi-turn 성능 저하는 단순한 추론 능력(aptitude) 감소가 아니라, 신뢰성(reliability)의 붕괴에서 기인 |
| 방법론 | 기존 single-turn 벤치마크를 정보 단위로 분해하는 Sharded Multi-Turn Simulation 제안. 한 턴당 하나의 정보 shard만 공개하여 실제 underspecified 대화를 모사 |
| 비교 설정 | FULL: 모든 정보 1턴 제공 (single-turn baseline) CONCAT: multi-turn이지만 모든 과거 정보를 누적 제공 SHARDED: 턴마다 일부 정보만 공개되는 진짜 multi-turn underspecified 대화 |
| 평가 지표 | Performance (P): 평균 성능 Aptitude (A): 90th percentile (best-case 성능) Unreliability (U): 90–10 percentile 차이 (best–worst 성능 격차) |
| 실험 규모 | 6개 생성 태스크(Code, Math, DB, Data-to-Text, Summary 등) 15개 LLM (GPT-4.1, Gemini 2.5 Pro, Claude, LLaMA3 등) 600 instructions × 10 runs × 3 설정 → 200,000+ 시뮬레이션 |
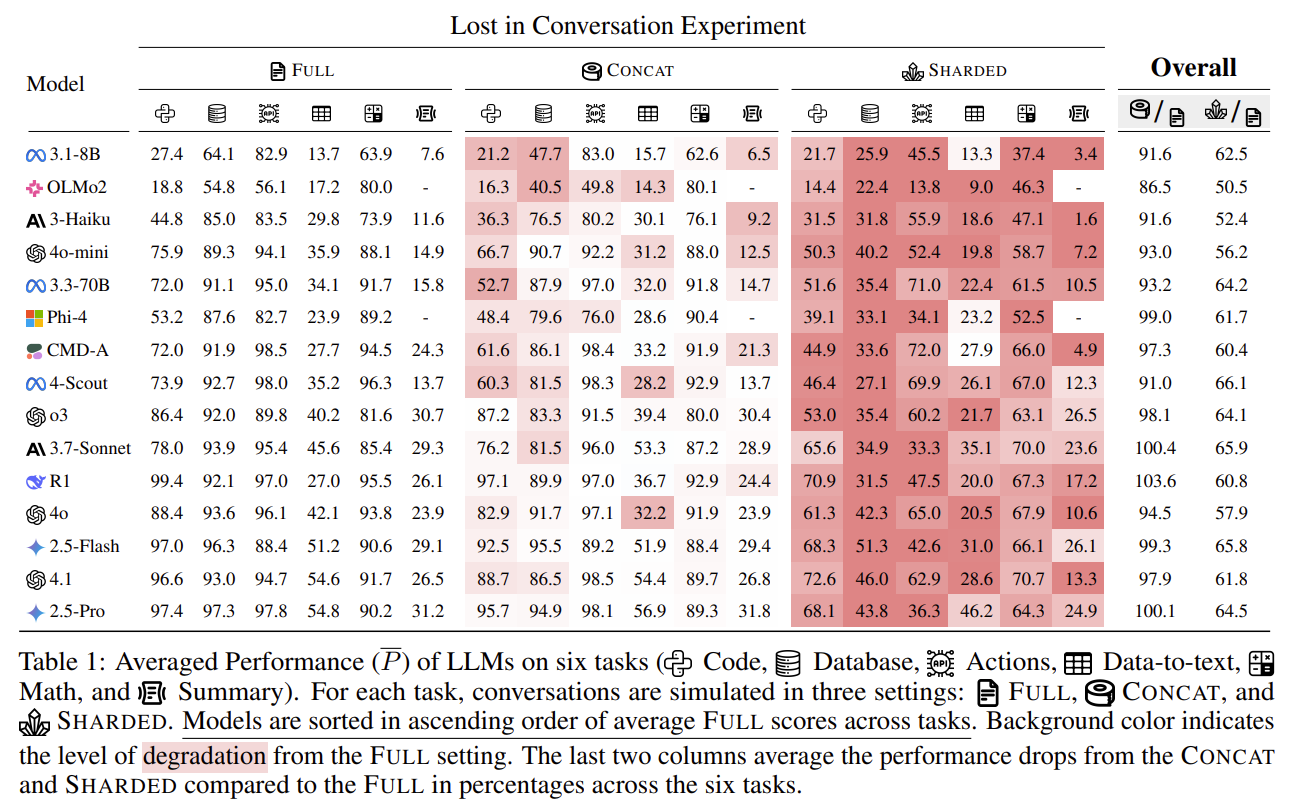
| 핵심 결과 | SHARDED 설정에서 모든 모델 성능 급락 • 평균 성능: ~90% → ~65% (−25~39%) • Aptitude: 약 −15% (소폭 감소) • Unreliability: +112% (2배 이상 증가) |
| 핵심 발견 | multi-turn 성능 붕괴의 주원인은 능력 부족이 아니라 신뢰성 붕괴. 좋은 모델도 multi-turn에서는 결과 변동성이 극단적으로 커짐 |
| 원인 분석 | (1) 정보가 부족한 상태에서 조기 답변 생성 (2) underspecified 정보를 임의 가정 (3) 이전 잘못된 답변에 과도하게 의존 (4) loss-in-middle-turns: 중간 턴 정보 무시 |
| 예외 사례 | Translation과 같은 episodic·분해 가능한 태스크는 multi-turn에서도 성능 유지 |
| 기존 해결책 평가 | Reasoning 모델, temperature 감소, agent-style concat 모두 근본적 해결 실패 |
| 사용자 시사점 | 대화가 꼬이면 새 대화에서 재시작, 모든 요구사항을 한 번에 정리(consolidate) |
| 연구/시스템 시사점 | multi-turn 평가에는 Reliability 중심 지표 필수. Agent framework는 우회책일 뿐, LLM 자체의 multi-turn 신뢰성 개선이 핵심 과제 |
| 한 줄 결론 | LLM은 multi-turn 대화에서 “모르는 상태를 유지”하지 못하며, 한 번 잘못된 가정을 하면 회복하지 못한다 |
'인공지능 > 논문 리뷰 or 진행' 카테고리의 다른 글
| Privacy AI 관련 조사 8 (1) | 2026.01.20 |
|---|---|
| Privacy AI 관련 조사 7 (0) | 2026.01.19 |
| Multi-turn, Long-context Benchmark 논문 1 (0) | 2026.01.17 |
| MAS 논문 - 2 (0) | 2026.01.16 |
| MAS 논문 - 1 (0) | 2026.01.16 |