Reflective Multi-Agent Collaboration based on Large Language Models
Requests for name changes in the electronic proceedings will be accepted with no questions asked. However name changes may cause bibliographic tracking issues. Authors are asked to consider this carefully and discuss it with their co-authors prior to reque
proceedings.neurips.cc
MAS는 복잡한 문제에서 단일 에이전트 대비 성능 향상을 보임!
그리고 Self-Reflection은 단일 에이전트 성능 향상에 효과적이다!
=> 기존 Reflection을 Multi-Agent로 확장을 해보자! - 근데 보상은 전체 시스템 성능만 반영해서 기여 분리가 불가하고, 에이전트 수 만큼 reflector를 학습해야 하며, actor는 학습하지 않아 reflection 품질이 reflector의 성능에 크게 의존한다.
Counterfactual PPO Enhanced Shared Reflector (COPPER)
→ “반사실적 보상 + 공유 Reflector + PPO 학습”
| 구성 요소 | 역할 |
| Actor (Frozen LLM) | GPT-3.5 / GPT-4 등, 실제 행동 생성 |
| Context Model | 토큰 제한 대응용 단기 메모리 |
| Reflector (Trainable LLM) | 이전 trajectory + reward 기반 reflection 생성 |
| Shared Reflector | 모든 에이전트가 공유하는 단일 reflector |
Reflection 생성 과정
- Multi-Agent 협업 수행
- 에이전트들이 순차적으로 행동 → trajectory τ 생성
- 환경 보상 획득
- 성공/실패 기반 sparse reward
- Agent-specific Reflection 생성
- 입력:
- 에이전트 프로필 (역할, 제약)
- 전체 trajectory (fully observable)
- reward
- 입력:
- Reflection을 Long-term Memory에 저장
- 다음 trial에서 Actor 프롬프트로 활용

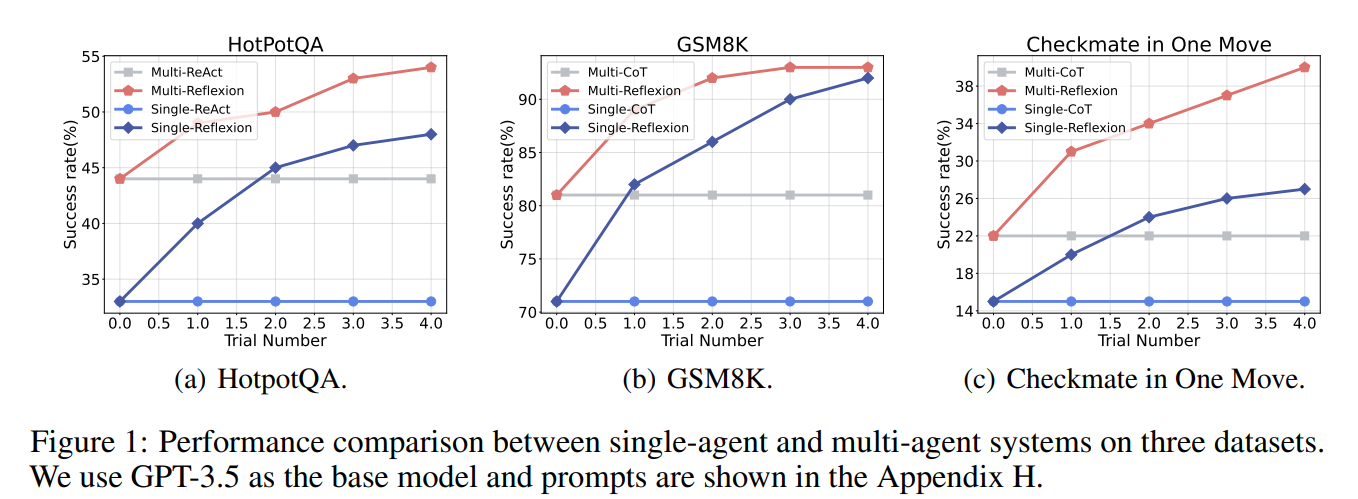
전체 리워드는 누가 잘했는지 구분하지 못 하기에 잘못된 reflection도 높은 보상을 받게 된다!
=> 전체에서 특정 에이전트의 reflection을 제거해서 개별 reflection 기여도를 정량화한다.
그래서 shard reflector를 학습해서 사용
SFT + PPO를 진행하여 성능을 높임
| 연구 목적 | LLM 기반 Multi-Agent System에서 self-reflection을 학습 가능하게 최적화하여 협업 성능을 향상 |
| 문제의식 | (1) Multi-Agent 환경에서 reflection의 credit assignment 불가, (2) 에이전트 수 증가에 따른 reflector 학습 비용 폭증, (3) frozen LLM의 한계 |
| 핵심 제안 | COPPER: Counterfactual PPO Enhanced Shared Reflector |
| 핵심 아이디어 | (a) Counterfactual Reward로 개별 agent reflection 기여도 정량화 (b) Shared Reflector로 모든 agent의 reflection을 하나의 모델로 학습 (c) PPO 기반 RLHF로 reflection 품질 최적화 |
| Actor 모델 | GPT-3.5 / GPT-4 (Frozen) |
| Reflector 모델 | LongChat / LLaMA-3 (Trainable, Shared) |
| Reflection 입력 | Agent profile + 전체 trajectory (fully observable) + 환경 reward |
| Reflection 출력 | 다음 trial에서 actor prompt를 수정하는 자연어 피드백 |
| Counterfactual Reward 정의 | 전체 reflection 포함 성능 − 특정 agent reflection 제거 후 성능 |
| 학습 방식 | SFT → Counterfactual PPO (Reward Model 포함) |
| 비교 Baseline | ReAct, CoT, Reflexion (GPT-3.5/LongChat), Retroformer (Multi) |
| 실험 태스크 | HotPotQA (Multi-hop QA), GSM8K (수학 추론), Checkmate in One Move (체스) |
| 주요 성능 향상 | 초기 대비 +31.8% (HotPotQA), +18.5% (GSM8K), +86.4% (Chess) |
| Ablation 결과 | Counterfactual Reward 제거 시 성능 급락 PPO 제거 시 장기 성능 저하 |
| 강점 | Debate 없이도 협업 성능 향상 가능 Agent 내부 개선(loop refinement)에 적합 |
| 한계점 | Counterfactual 계산 비용 큼 (N번 rollout) Long-term memory 구조 단순 |
| 연구적 의의 | Reflection을 보조 기법이 아닌 학습 대상(policy)으로 정식화 |
| 확장 가능성 | Reward 근사 critic, vector memory, intra-agent multi-agent 구조 |
CVPR 2025 Open Access Repository
Deciding the Path: Leveraging Multi-Agent Systems for Solving Complex Tasks Iman Abbasnejad, Xuefeng Liu, Atanu Roy; Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2025, pp. 4255-4264 Abstract We present
openaccess.thecvf.com
범용 LLM은 복잡한 task에서 도메인 특화 정확도가 부족하고, 불필요한 토큰/ 툴 호출로 비효율이 있으며 단일 추론 경로로 인해 오류가 누적된다.
그리고 Agent 프레임 워크도 사람 개입이 필요하며 도구 선택이 비체계적이고, Agent간 협업이 정형화되지 않는다.
=> 복잡한 테스크를 사람 개입 없이, 효율적으로 정확하게 해결할 수 있는 MAS 구조를 어떻게 만드냐!
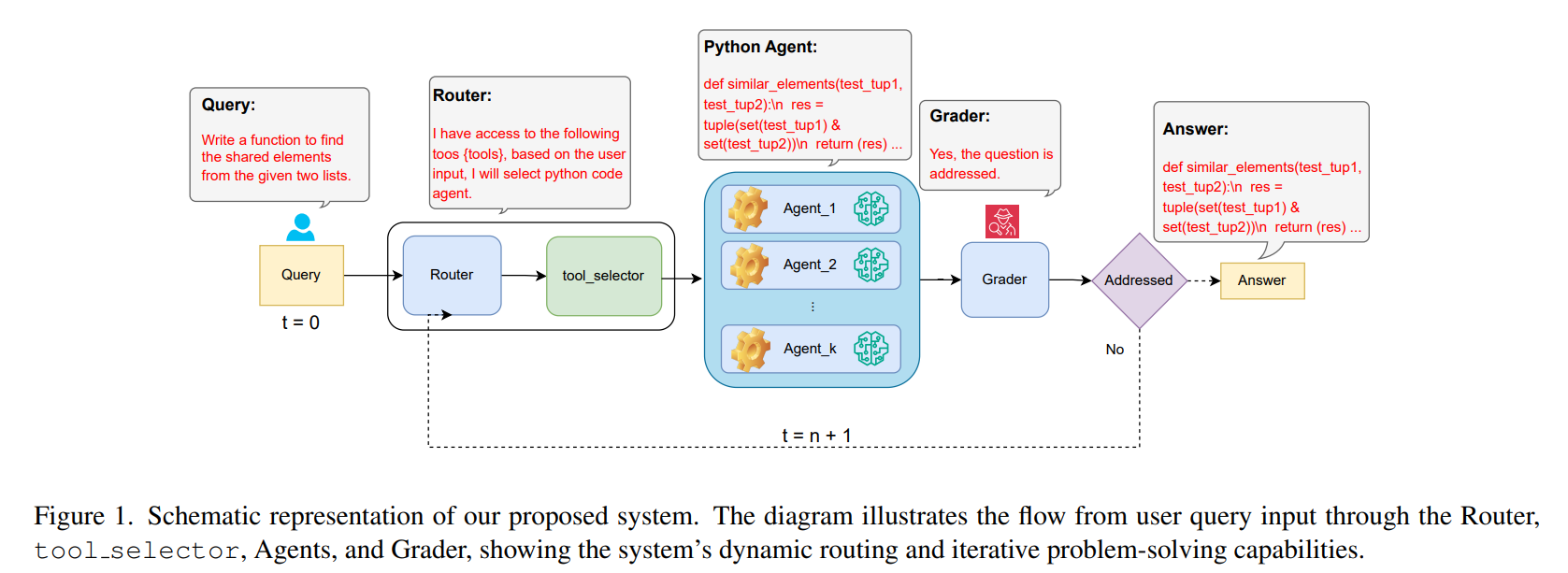
==> 지능형 Router, Tool Selector, 전문화된 Multi-Agent, Grader로 구성된 MAS 프레임워크를 사용
| 구성요소 | 역할 |
| Router (MR) | 입력 쿼리를 분석해 최적 Agent로 라우팅 |
| Tool Selector | Agent가 사용할 Tool subset을 사전 축소 |
| Multi-Agent (Mi) | 도메인 특화 LLM + 전용 Tool을 이용해 문제 해결 |
| Grader (MG) | 답변이 문제를 해결했는지 CoT 기반 판별 (Yes / No) |
Multi Agent 내부는 M = (L, R, S, T)로 구성
L = 사용 LLM
R = Agent 역할 설명
S = current state
T = Tool 집합
Agent는 자기 역할에 자기 Tool만 사용하여 진행하고, Router가 Task 단위로 Agent를 선택하여 디베이트 없이 순수 실행 중심으로 협업을 진행
Graph기반으로 시스템 전체를 시간에 따라 모델링하여 흐름을 구성
| 연구 목적 | 복잡한 태스크를 대상으로 사람 개입 없이 정확도·효율성을 동시에 향상시키는 자율적 Multi-Agent 시스템 설계 |
| 문제의식 | 단일 LLM은 도메인 특화 정확도, 툴 활용 효율, 장기 추론에서 한계가 있으며, 기존 Agent 시스템은 human-in-the-loop·비효율적 툴 호출 문제가 존재 |
| 핵심 아이디어 | Router 기반 동적 라우팅 + Tool Selector + 역할 고정 Multi-Agent + Grader를 결합한 완전 자동 협업 구조 |
| 전체 구조 | (1) Router(MR): 입력 쿼리 분석 후 최적 Agent 선택 (2) Tool Selector: Agent가 사용할 Tool subset 사전 축소 (3) Multi-Agent(Mi): 도메인 특화 LLM + 전용 Tool로 문제 해결 (4) Grader(MG): 답변의 문제 해결 여부를 CoT 기반 Yes/No 판정 |
| Agent 정의 | 각 Agent는M_i=(L_i,R_i,S_i,T_i) 로 구성 (LLM, 역할, 상태, Tool 집합) |
| 추론 방식 | Debate 없음, ReAct 기반 실행 중심 추론 + 실패 시 재라우팅 |
| 상호작용 모델 | 시간 흐름에 따른 Graph 기반 Agent–Tool 메시지 패싱 구조 |
| 주요 데이터셋 | Math 401 (수학), MBPP (코드 생성), BIRD SQL (Text-to-SQL) |
| 평가 지표 | Accuracy / RE / NNR (Math), pass@1 (Code), VES·Execution Accuracy (SQL), RAR·ACR (효율성) |
| 핵심 성능 결과 | Math 401: 90.29% Acc (SOTA) MBPP: 91.3% pass@1 (SOTA) BIRD SQL: 56.28% VES / 54.39% EX (SOTA) |
| 비교 우위 | GPT-4, DeepSeek-V3, Autogen, MetaGPT, MathViz-E, QualityFlow 등 범용·전용 모델 모두 상회 |
| 효율성 기여 | Tool Selector로 반복 액션 감소(RAR↓), 종료 인식 정확도 향상(ACR↑) → 토큰·연산 비용 절감 |
| 차별점 요약 | Debate 없는 MAS, 완전 자동 Orchestration, Tool 사용 최소화, 역할 고정 Agent 설계 |
| 한계 | Agent 수 증가 시 시스템 복잡도 및 재시도 횟수 증가 가능 |
| 연구적 시사점 | Debate 없는 Heterogeneous MAS도 충분히 SOTA 가능함을 실증 → 산업·실서비스 지향 MAS 설계에 매우 현실적 |
https://ojs.aaai.org/index.php/AAAI/article/view/34478
Orpheus: Engineering Multiagent Systems via Communicating Agents | Proceedings of the AAAI Conference on Artificial Intel
ojs.aaai.org
기존 MAS 프로그래밍은 Reactive model에 가깝다!
그래서 프로토콜 위반 메세지를 컴파일이나 런타임에서 방지할 수 없고 프로토콜이 조금만 바뀌어도 Agent code를 바꿔야 하며, 메세지 조합이 늘수록 plan이 증가하며 비동기, 순서 비보장 환경에서 오류가 난다!
메세지를 받았으니 무엇을 할까 => 현재 내가 가진 정보로 어떤 메세지를 보내는 것이 가능한가!
메세지는 상태가 아니라 정보로 제약되며 메세지 전송 가능 여부는 in, out 파라미터를 통해 결정되며 정보 의존성이 핵심이 된다.
=> 비동기, 병렬, 다자간 프로토콜에 적합하다
위 프로토콜을 입력으로 받아 role-specific adapter를 생성하여 Local protocol state을 유지하고, Enabled message를 계산하며, 메세지 송 수신시 protocol consistency를 검증하여 개발자가 프로토콜 상태 관리 코드 작성이 불필요 하다

그리고 Orpheus는 enablement 기반 패턴을 제안
| Primitive | 의미 |
| enabled(m) | 현재 local state에서 전송 가능한 메시지 |
| complete(m) | ⌜out⌝ 파라미터를 채워 메시지 완성 |
| attempt(m1,...,mk) | 여러 메시지를 동시에 전송 시도 (일관성 검사 포함) |
Goal 발생
↓
enabled(...) 질의
↓
complete(...) (결정 로직은 개발자 책임)
↓
attempt(...) → protocol-safe send메세지 수신에 반응하지 않고, 목표 달성 관점에서 메세지를 보냄
전이 시스템으로 Orpheus를 공식화하여 Protocol correctness가 semantics 차원에서 보장되어 개발자는 complete만 정의하면 된다.
기존 프로토콜 변경에 강건성을 가져서 agent code 수정이 최소화 된다.
| 연구 문제 | 기존 MAS 프로그래밍은 reactive model 기반으로, 프로토콜 의미가 코드에 내재되지 않아 semantic error, 낮은 유연성, 상태 폭발, 비동기 환경 취약성 문제가 발생 |
| 기존 한계 | (1) 메시지 수신 기반 반응형 프로그래밍 (2) 프로토콜의 비공식적 명세(UML/FIPA) (3) 상태 머신 수작업 관리 (4) 다자간·비동기·순서 무관 상호작용에 취약 |
| 핵심 아이디어 | “메시지를 받았기 때문에 행동”이 아니라 “현재 가진 정보로 어떤 메시지가 가능한가”를 중심으로 agent를 설계 |
| 기반 이론 | Information Protocol (BSPL): 메시지 순서가 아닌 정보 의존성(in/out/key) 으로 상호작용을 제약 |
| 제안 방법 | BSPL 프로토콜로부터 role-specific Orpheus adapter를 자동 생성하여, agent 내부에서 프로토콜 상태·정합성을 관리 |
| 프로그래밍 모델 | Enablement-based Programming • enabled(m): 현재 상태에서 전송 가능한 메시지 • complete(m): out 파라미터 결정 (개발자 책임) • attempt(m₁,…,mₖ): 상호 일관성 검사 후 동시 전송 |
| Agent 역할 분리 | • Adapter: 프로토콜 의미론, 상태 추적, 정합성 보장 • Agent logic: 목표(goal)와 의사결정 로직만 기술 |
| 형식적 기여 | RECV / ENABLED / ATTEMPT / SEND 규칙으로 구성된 운영 의미론(Operational Semantics) 제시 |
| 주요 장점 | (1) 프로토콜 변경 시 코드 수정 최소화 (2) 다자간 정보 상관(correlation) 자동 처리 (3) 비동기·순서 비보장 통신에 안전 (4) semantic error 구조적 방지 |
| 평가 방식 | 정량 실험 대신 설계 변화 시 코드 복잡도·유연성 비교 중심의 개념적 평가 |
| 한계 | 파라미터 순서·스키마 오류는 정적 타입 수준에서 완전 방지 불가 |
| 확장 방향 | commitment 기반 MAS, communicative action 기반 프로토콜, LLM agent 및 orchestration과의 결합 |
| 핵심 기여 한 줄 요약 | BDI agent를 goal-driven이면서 protocol-aware하게 만드는 최초의 실질적 프로그래밍 모델 |
'인공지능 > 논문 리뷰 or 진행' 카테고리의 다른 글
| Multi-turn, Long-context Benchmark 논문 1 (0) | 2026.01.17 |
|---|---|
| MAS 논문 - 2 (0) | 2026.01.16 |
| LANGSAE EDITING: Improving Multilingual Information Retrieval via Post-hoc Language Identity Removal (0) | 2026.01.14 |
| NaviAgent, AGENTORCHESTRA (0) | 2026.01.11 |
| ToolOrchestra: Elevating Intelligence via Efficient Model and Tool Orchestration (0) | 2026.01.09 |