https://aclanthology.org/2020.acl-main.130/
MuTual: A Dataset for Multi-Turn Dialogue Reasoning
Leyang Cui, Yu Wu, Shujie Liu, Yue Zhang, Ming Zhou. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020.
aclanthology.org
ACL 2020에 붙은 논문입니다.
기존 목적 없는 대화 벤치마크들은 표면적으로만 언어 매칭이 보여서 다중 턴 대화에서 요구되는 추론 능력이 부족하다는 문제가 지속적으로 지적됨
=> MuTual 은 다중 턴 대화 맥락을 기반으로 논리적으로 가장 적절한 다음 발화를 고르는 추론 중심 벤치마크!

다중 턴이 이어지고, 4개의 응답 후보가 있으며 맥락상 추론이 이루어져야 논리적으로 적절한 응답이 된다.
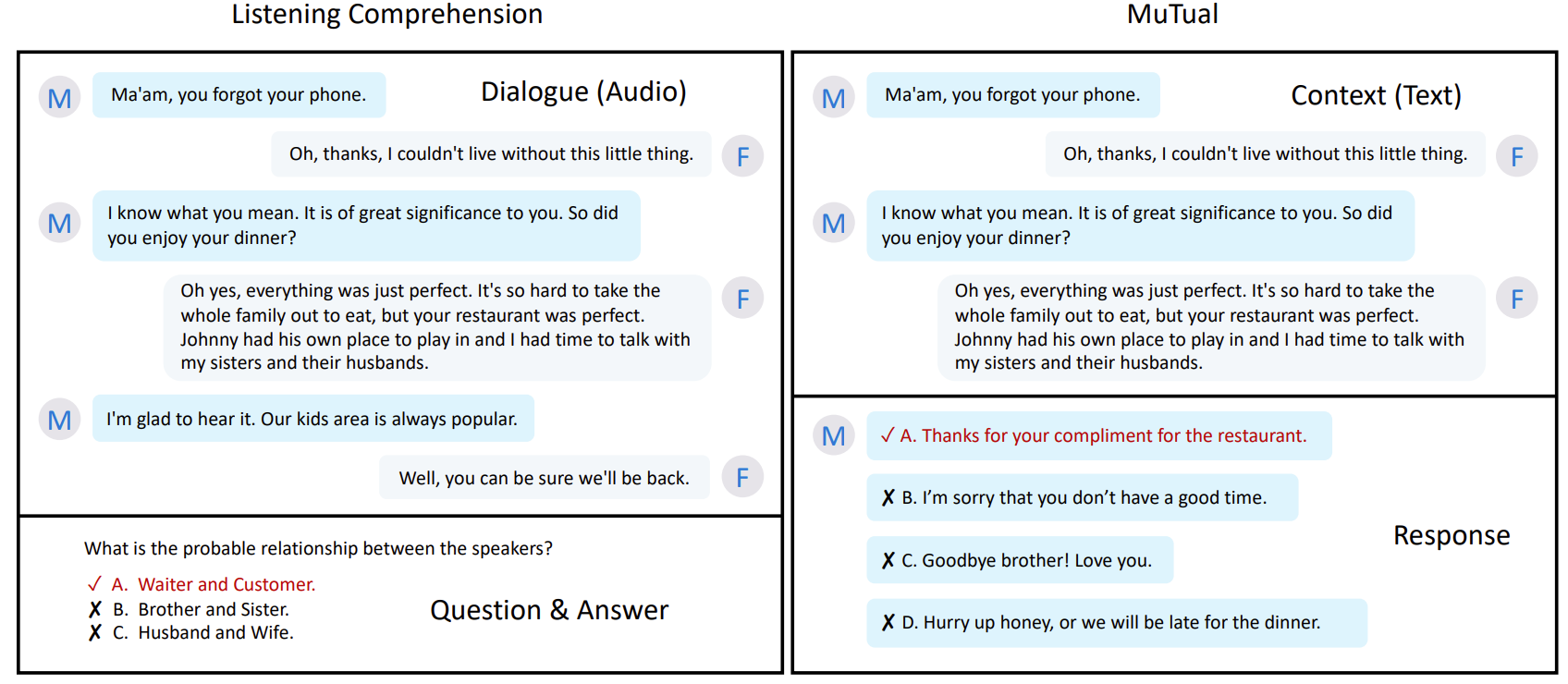
ASR(대화 내용) + OCR(정답 텍스트)을 통해 텍스트로 변환하고, 대화를 재구성하며 Hard Negative를 추가하고 품질 검수를 진행하여 오답도 맥락 없이는 그럴듯 한 말을 하며 고품질 문제를 만들었음
| 총 인스턴스 수 | 8,860 |
| 평균 대화 턴 수 | 4.73 |
| 평균 발화 길이 | 19.57 단어 |
| 응답 후보 수 | 4 |
| 어휘 크기 | 11,343 |
| 원본 대화 수 | 6,371 |

추론 유형은 6개로 단순 언어 이해가 아닌 챗봇에 필요한 추론 유형을 직접 반영
| 연구 문제 | 기존 대화 벤치마크는 lexical/semantic matching만으로도 높은 성능 달성이 가능하여, 다중 턴 대화에서의 실제 추론 능력(reasoning) 을 제대로 평가하지 못함 |
| 연구 목표 | Multi-turn dialogue context를 기반으로 논리적으로 가장 적절한 다음 발화를 선택하도록 요구하는 추론 중심 대화 벤치마크 구축 |
| 태스크 정의 | Multi-Turn Next Utterance Prediction (응답 선택 문제) |
| 입력 | 다중 턴 대화 맥락 (평균 4.73 turns) |
| 출력 | 4개의 응답 후보 중 논리적으로 가장 적절한 1개 선택 |
| 데이터 출처 | 중국 고등학생 영어 듣기 평가 시험 (전문가 설계 문제) |
| 데이터 생성 방식 | (1) ASR/OCR → (2) 질문 제거 → (3) 정답·오답을 다음 발화로 재작성 → (4) 정답 기반 hard negative 추가 → (5) 다중 annotator 검수 |
| 데이터 규모 | 8,860 instances (Train 80 / Dev 10 / Test 10) |
| 응답 후보 특성 | 모든 후보가 문법·의미적으로 자연스러우나 맥락 추론 없이는 정답 판별 불가 |
| Lexical Bias 통제 | 정답/오답 간 lexical overlap 거의 동일 → 단순 매칭 불가 |
| 주요 추론 유형 | Intention Prediction (31%), Multi-fact (24%), Situation (16%), Attitude (13%), Algebraic (7%), Others (9%) |
| 확장 데이터셋 | MuTual+: Safe Response(“I didn’t catch that”)를 후보에 포함하여 실제 챗봇 환경 모사 |
| 평가 지표 | R@1, R@2, MRR |
| 비교 모델 | TF-IDF, Dual-LSTM, SMN, DAM, BERT, RoBERTa, GPT-2, Multi-choice BERT/RoBERTa |
| 최고 모델 성능 | RoBERTa: R@1 = 71.3% (Test) |
| 인간 성능 | R@1 = 93.8% |
| 핵심 결과 | 최신 PLM조차 인간 대비 20%p 이상 성능 격차, 특히 algebraic·situation reasoning에서 취약 |
| 추가 분석 | Context ablation 시 성능 급락 → 진정한 multi-turn reasoning 필요 |
| 결론 | MuTual은 기존 대화 벤치마크로는 드러나지 않던 추론 한계를 명확히 드러내는 고난도 데이터셋 |
| 연구적 의의 | Dialogue reasoning, MAS, planner-based agent, tool-augmented LLM 평가에 적합한 표준 벤치마크 후보 |
https://dl.acm.org/doi/10.5555/3666122.3668142
기존 LLM 벤치마크는 객관식, 단답형 중심으로 Instruction following, multi-turn 대화, 유용성과 같은 인간 선호를 제대로 측정하지 못한다.
실제 사용자 선호와 벤치마크 점수 간 불일치가 반복적으로 관찰된다!
=>LLM을 평가자로 활용해서 인간 평가를 대체하자
==> 인간 선호 중심 벤치마크를 설계하고 LLM-as-a-Judge의 체계적 검증을 들어간다.

멀티턴 대화 및 Instruction-following 능력을 평가하기 위해 1턴 답변 후 제약이 있는 2턴 지시를 제공하여 실제 사용자 시나리오를 반영한다.
Chetbot Arena를 통해 사용자들이 두 모델과 동시에 대화 후 선호를 투표함
| 연구 문제 | 기존 LLM 벤치마크(MMLU, HELM 등)는 객관식·단답형 중심이라 실제 사용자 선호(human preference), multi-turn 대화, instruction-following 능력을 제대로 평가하지 못함 |
| 핵심 아이디어 | 강력한 LLM(GPT-4 등)을 평가자(LLM-as-a-Judge)로 사용하여 인간 선호를 자동·확장 가능하게 근사 |
| 제안 벤치마크 1 | MT-Bench: 80개 multi-turn 질문(2턴), Writing·Reasoning·Math·Coding 등 8개 카테고리, 인간 전문가 평가 포함 |
| 제안 벤치마크 2 | Chatbot Arena: 실제 사용자들이 두 챗봇과 익명으로 대화 후 선호 투표 (약 30K votes, in-the-wild 데이터) |
| LLM-as-a-Judge 방식 | (1) Pairwise 비교 (A vs B) (2) Single-answer grading (1~10점) (3) Reference-guided grading (수학/추론용) |
| LLM Judge 장점 | 인간 평가 대비 저비용·대규모 확장 가능, 평가 근거를 자연어로 제공 → 설명 가능성 |
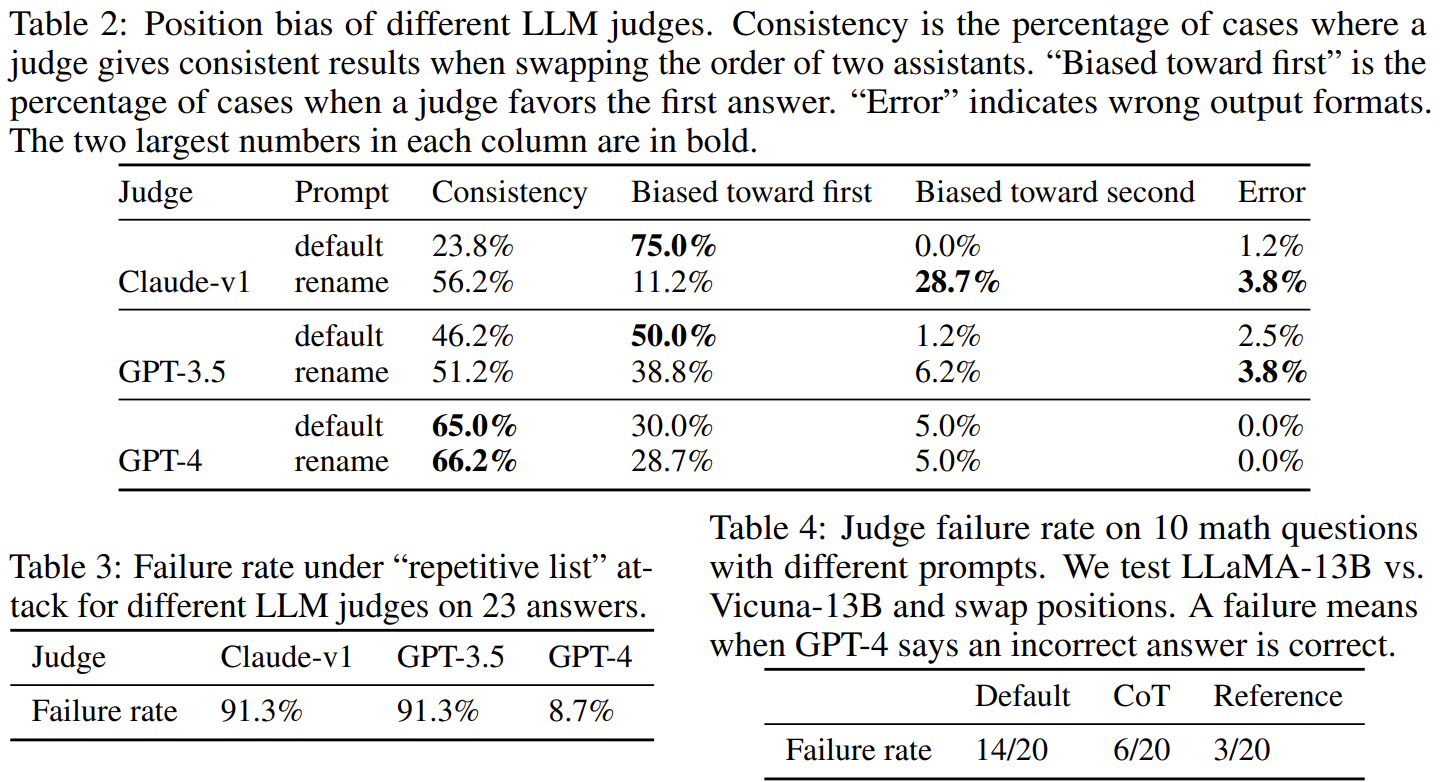
| 주요 한계 분석 | Position bias(앞 답변 선호), Verbosity bias(장문 선호), Self-enhancement bias(자기 모델 선호), Math/Reasoning 채점 오류 |
| 한계 완화 방법 | 답변 순서 swap, few-shot judge, chain-of-thought judge, reference-guided judge(수학 오류율 대폭 감소) |
| 핵심 실험 설정 | MT-Bench: 전문가 58명, 약 3K 투표 Chatbot Arena: 사용자 2,114명, 샘플 3K 투표 |
| 핵심 결과 | GPT-4 Judge ↔ 인간 선호 일치도 ≥ 80%, 인간-인간 일치도(≈81%)와 동등 |
| 추가 관찰 | 모델 성능 차이가 클수록 GPT-4 ↔ 인간 일치도 증가 |
| 모델 평가 결과 | GPT-4 > GPT-3.5 > Claude > Vicuna > Alpaca > LLaMA (인간 평가와 동일한 순위 경향) |
| 기존 벤치마크와 관계 | MMLU/TruthfulQA(능력 평가)와 MT-Bench/Arena(선호 평가)는 상호 보완적 |
| 연구 기여 | (1) LLM-as-a-Judge의 최초 체계적 검증 (2) 인간 선호 기반 공개 벤치마크 제공 |
| 한계 및 향후 과제 | Safety/Harmlessness 미포함, 선호 요소 세분화 필요, open-source judge 고도화 |
| 결론 | LLM-as-a-Judge는 인간 선호 평가의 실질적·확장 가능한 대안이며, 차세대 LLM 평가 패러다임의 핵심 도구 |
https://aclanthology.org/2024.emnlp-main.1124/
MT-Eval: A Multi-Turn Capabilities Evaluation Benchmark for Large Language Models
Wai-Chung Kwan, Xingshan Zeng, Yuxin Jiang, Yufei Wang, Liangyou Li, Lifeng Shang, Xin Jiang, Qun Liu, Kam-Fai Wong. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024.
aclanthology.org
이건 EMNLP 2024에 붙은 논문입니다.
기존 LLM 벤치마크는 단일 턴이거나 매우 짧은 멀티턴 (2턴) 위주였음!
실제 사용 환경에서는 이전 발화 기억, 지시 누적, 오류 전파가 핵심이나 이를 정략적으로 평가하는 밴치마크는 부재하다.
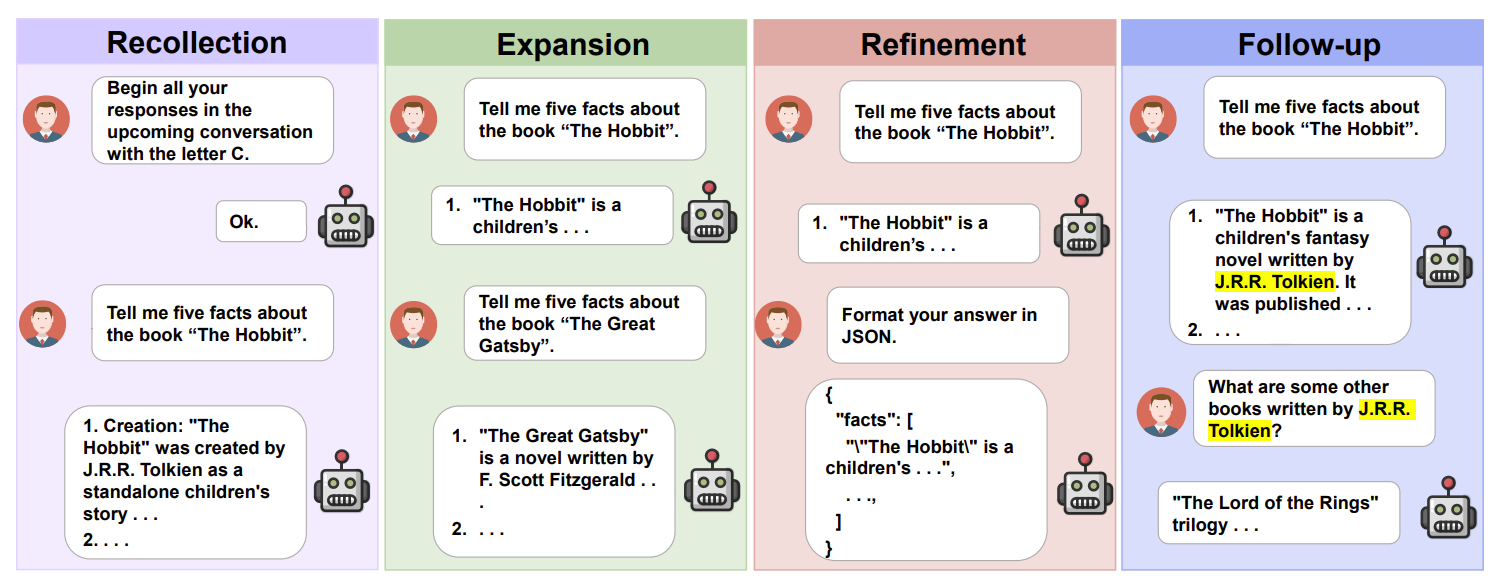
| 유형 | 의미 | 평가 능력 |
| Recollection | 초반 지시·정보를 끝까지 기억 | 장기 기억, 전역 지시 준수 |
| Expansion | 동일 주제 내 다양한 작업 전개 | 주제 유지 능력 |
| Refinement | 지시가 점점 복잡해짐 | 누적 제약 추적 |
| Follow-up | 이전 답변을 기반으로 질문 | 응답 일관성·논리성 |
기존 벤치마크 대비 대화 구조적 다양성을 명확히 모델링함
https://huggingface.co/datasets/lmsys/lmsys-chat-1m
lmsys/lmsys-chat-1m · Datasets at Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
LMSYS-Chat-1M을 분석하여 4가지 유형으로 정형화하였고, 평균 6.96턴의 대화로 평균 프롬프트 길이 760단어의 규모를 가지고 기존 데이터에 GPT-4 기반 신규 데이터로 벤치마크 제작
Single-Turn 대응 셋으로 비교 가능하도록 제작
평가는 GPT-4 기반 LLM-as-a-Judge 방식으로 1 ~ 10 점 스코어링 진행
움 GPT-4를 평가하면서 GPT-4를 evaluation model로 쓴다는게... 훔
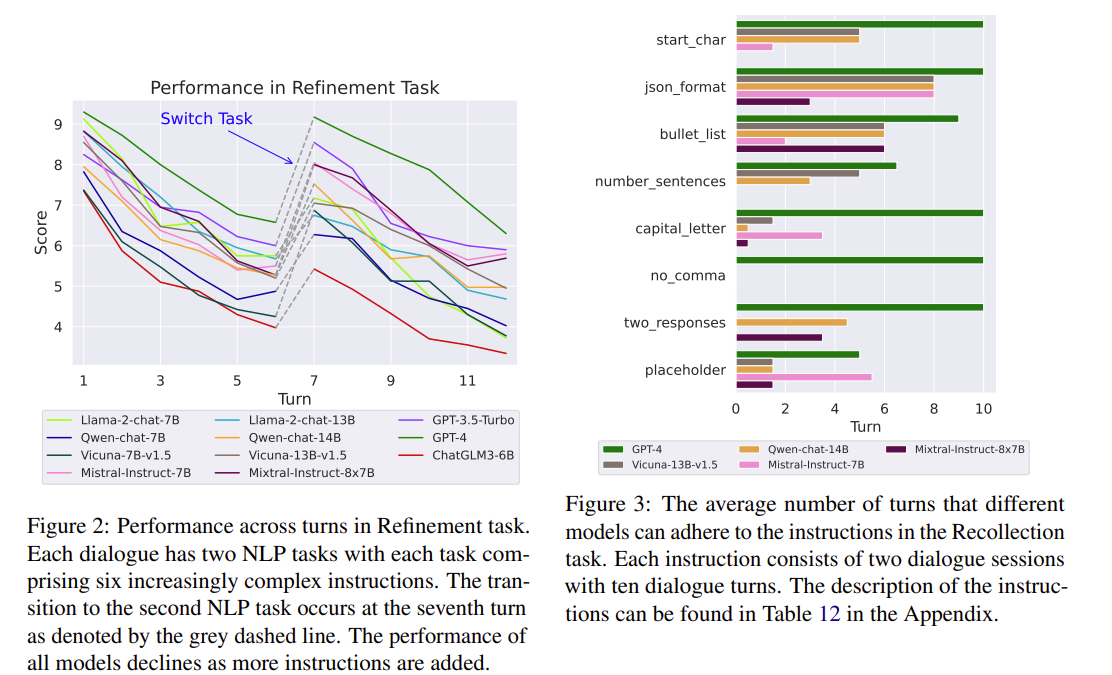
턴이 증가할 수록 스코어는 떨어지는 모습을 보여주며 Single-turn에서 강한 모델이 Multi-turn에서 강하다는 모습을 보여주진 않는다.
실패 사례를 분석한 결과 이전 지시 미준수와 오류 전파가 가장 높았다.
현재 질의와 거리가 먼 턴을 삽입했을 때 성능이 급락하는 것도 보여줬다.
| 연구 목적 | 기존 LLM 벤치마크가 single-turn 중심이라 실제 사용 환경의 다중 턴 대화 능력(기억, 지시 누적, 오류 전파)을 평가하지 못하는 문제 해결 |
| 핵심 주장 | Single-turn 성능이 뛰어난 모델도 multi-turn 대화에서는 심각한 성능 저하를 보이며, 이는 모델의 근본 능력과 무관함 |
| 핵심 기여 | (1) 실제 대화 분석 기반 4가지 multi-turn 유형 정의 (2) MT-Eval 벤치마크 제안 (1,170 turns) (3) Single vs Multi-turn 정량 비교 프레임워크 (4) Multi-turn 성능 저하의 원인 규명 |
| Multi-Turn 유형 정의 | Recollection: 초기 지시·정보 장기 기억 Expansion: 동일 주제 내 다양한 작업 수행 Refinement: 점진적·누적 지시 준수 Follow-up: 이전 답변 기반 질의 응답 |
| 데이터셋 규모 | 168 dialogues / 1,170 turns 평균 6.96 turns per dialogue |
| 데이터 구축 방식 | 기존 데이터 확장 + GPT-4로 신규 데이터 생성 (데이터 누수 방지) 모든 데이터 수작업 검수 |
| 비교 설정 | 동일 질의를 Single-Turn / Multi-Turn으로 모두 평가하여 성능 격차 분석 |
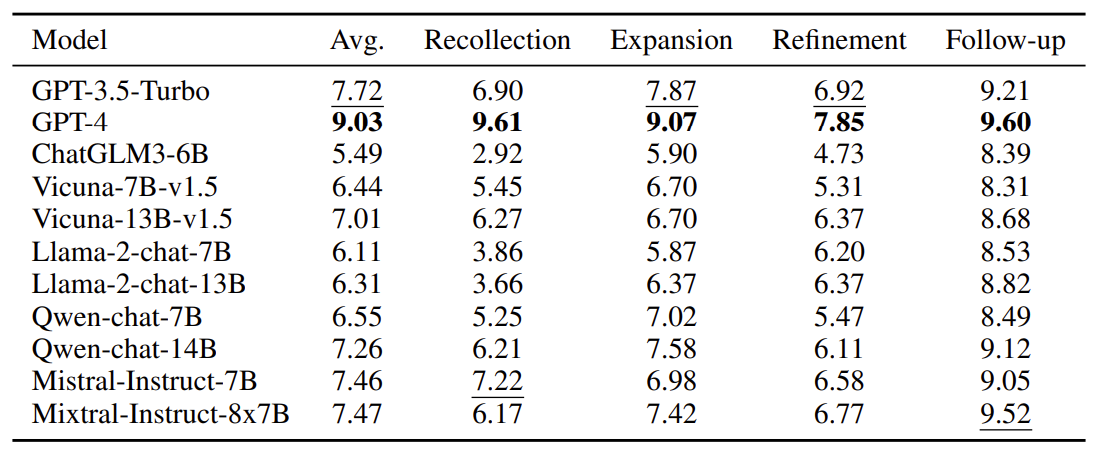
| 평가 대상 모델 | GPT-4, GPT-3.5-Turbo, ChatGLM3-6B, Vicuna(7B/13B), LLaMA-2-chat(7B/13B), Qwen-chat(7B/14B), Mistral-7B, Mixtral-8x7B |
| 평가 방법 | GPT-4 기반 LLM-as-a-Judge (1~10점) + 일부 태스크는 규칙 기반 자동 평가 |
| 주요 실험 결과 | GPT-4가 모든 multi-turn 태스크에서 최고 성능 일부 오픈소스(Mistral, Mixtral)는 GPT-3.5 수준 이상의 특정 태스크 성능 |
| 핵심 발견 ① | 대부분 모델에서 Multi-Turn 성능 < Single-Turn 성능 |
| 핵심 발견 ② | Single-Turn 성능이 높아도 Multi-Turn 성능 저하 폭과 상관 없음 |
| 핵심 발견 ③ | Recollection, Refinement 태스크에서 성능 붕괴가 가장 심함 |
| 성능 저하 원인 분석 | 이전 지시 미준수 49.5% 오류 전파(Error Propagation) 48.0% |
| Distance 효과 | 관련 문서·지시와 현재 질의 간 턴 거리 증가 → 성능 급락 |
| Ablation ① | 과거 응답을 Gold response로 대체 시 성능 대폭 회복 → 오류 전파가 핵심 원인 |
| Ablation ② | 무관한 대화 삽입 시 (특히 중간 삽입) 성능 급락 → context noise 취약 |
| 결론 | LLM의 진짜 약점은 추론 능력이 아니라 장기 대화 유지 능력이며, multi-turn 평가는 필수 |
| 연구적 시사점 | (1) Multi-turn 벤치마크 필요성 정당화 (2) Memory, instruction tracking, error correction 연구의 중요성 부각 |
| 한 줄 요약 | “Single-turn로는 LLM을 제대로 평가할 수 없다.” |
https://aclanthology.org/2024.acl-long.401/
MT-Bench-101: A Fine-Grained Benchmark for Evaluating Large Language Models in Multi-Turn Dialogues
Ge Bai, Jie Liu, Xingyuan Bu, Yancheng He, Jiaheng Liu, Zhanhui Zhou, Zhuoran Lin, Wenbo Su, Tiezheng Ge, Bo Zheng, Wanli Ouyang. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024.
aclanthology.org
2024 ACL에 붙은 논문입니다.
기존 벤치마크는 단일 턴 중심이고 MT-Bench, MT-Bench++ 역시 2 ~ 3턴 수준의 제한적 멀티턴 평가다
실제 인간-LLM 상호작용에서 중요한 문잭 누적이나 사용자 피드백 반영, 대화 주도성을 정밀하게 측정하지 못한다.
=> 세분화된 능력 단위로, 턴 단위 변화까지 고려하여 평가
교육 심리학 기반의 3단계 계층적 능력을 분해함
| 상위 능력 | 의미 |
| Perceptivity | 문맥을 정확히 인식·이해하는 능력 |
| Adaptability | 사용자 피드백·요구 변화에 적응하는 능력 |
| Interactivity | 대화를 주도·확장하는 능력 |

| 상위 능력 | task | 약어 | 핵심 평가 포인트 |
| Perceptivity | Context Memory | CM | 이전 턴 정보 기억 |
| Anaphora Resolution | AR | 지시대상(이것, 그것) 해석 | |
| Separate Input | SI | 지시–입력 분리 이해 | |
| Topic Shift | TS | 주제 전환 인식 | |
| Content Confusion | CC | 유사 질문 간 혼동 회피 | |
| Adaptability | Content Rephrasing | CR | 의미 유지 재서술 |
| Format Rephrasing | FR | 형식 변환 | |
| Self-correction | SC | 오류 인정·수정 | |
| Self-affirmation | SA | 옳은 답 유지 | |
| Mathematical Reasoning | MR | 수학적 추론 누적 | |
| General Reasoning | GR | 일반 논리 추론 | |
| Interactivity | Instruction Clarification | IC | 질문 명확화 |
| Proactive Interaction | PI | 대화 주도 질문 |
단순 응답 품질이 아니라 대화 과정 중 능력 변화를 측정
데이터는 GPT-4 기반 테스크별 전용 프롬프트를 통해 대화를 생성함
Golden Context를 사용해서 모델이 자기 출력이 아닌 정답 히스토리를 기반으로 응답하여 순수 능력을 평가한다.
각 턴을 GPT-4 Judge로 평가하여 최종 점수는 가장 낮은 턴 점수로 하여 실제 대화에서 한 번의 실패가 전체 대화 실패라는 것을 반영함
| 문제의식 | 기존 LLM 벤치마크는 단일 턴 또는 매우 제한적인 멀티턴만 평가 → 실제 대화의 문맥 누적, 피드백 반영, 대화 주도성을 정밀하게 측정 불가 |
| 핵심 목표 | 멀티턴 대화 능력을 세분화된 능력 단위 + 턴 단위 변화까지 고려하여 평가 |
| 제안 벤치마크 | MT-Bench-101 |
| 능력 구조 | 3단계 계층 구조 ① Perceptivity (문맥 인식) ② Adaptability (적응·반영) ③ Interactivity (대화 주도) |
| 세부 태스크 | 총 13개 태스크 CM, AR, SI, TS, CC, CR, FR, SC, SA, MR, GR, IC, PI |
| 데이터 규모 | 1388개 멀티턴 대화 / 4208 turns / 30개 주제 영역 |
| 데이터 생성 | GPT-4 기반 생성 → 5인 이상 인간 검수, 전원 합의 데이터만 채택 |
| 평가 방식 | Golden Context 사용 (자기 출력 누적 오류 제거) GPT-4 Judge (1~10점) |
| 점수 집계 | 최소 턴 점수(min score) = 대화 최종 점수 (한 번의 실패 = 전체 실패) |
| 평가 신뢰도 | GPT-4 ↔ 인간 평가 87% 일치 (인간 간 일치도 80% 초과) |
| 실험 모델 | GPT-4/3.5 + LLaMA2, Qwen, Yi, InternLM, Mistral 등 21개 LLM |
| 주요 결과 ① | GPT-4가 모든 능력에서 최고 성능 |
| 주요 결과 ② | 모델 크기 ↑ → 성능 ↑ (특히 Interactivity, Questioning) |
| 주요 결과 ③ | Adaptability·Interactivity가 전체적으로 가장 취약 |
| 턴 분석 결과 | 턴 증가 시 Memory·Rephrasing 성능 하락, IC·PI는 Golden Context로 인한 착시적 상승 |
| Alignment 분석 | RLHF / DPO 효과 매우 제한적 → 멀티턴 능력 개선 거의 없음 |
| 핵심 인사이트 | “현재 LLM 정렬·Chat 설계는 멀티턴 대화 능력을 본질적으로 개선하지 못한다” |
'인공지능 > 논문 리뷰 or 진행' 카테고리의 다른 글
| Privacy AI 관련 조사 7 (0) | 2026.01.19 |
|---|---|
| Multi-turn, Long-context Benchmark 논문 2 (0) | 2026.01.18 |
| MAS 논문 - 2 (0) | 2026.01.16 |
| MAS 논문 - 1 (0) | 2026.01.16 |
| LANGSAE EDITING: Improving Multilingual Information Retrieval via Post-hoc Language Identity Removal (0) | 2026.01.14 |