Cut the Crap: An Economical Communication Pipeline for LLM-based Multi-Agent Systems
Requests for name changes in the electronic proceedings will be accepted with no questions asked. However name changes may cause bibliographic tracking issues. Authors are asked to consider this carefully and discuss it with their co-authors prior to reque
proceedings.iclr.cc
기존 MAS 시스템은 단일 에이전트 대비 고난도 추론이나 코딩 문제에서 집단 지능을 보여줬지만 토큰 폭증이나 경제적 비효율, 배포 불가능성, 보안 취약성을 보였다.
에이전트간 메세지의 상당 부분은 실제 성능에 기여하지 않는 것을 통해 라운드간의 연결을 무작위로 제거했을 때 성능이 오르는 것을 발견 => Communication Redundancy로 공식 정의

여기서 보면 연결이 너무 많아 토큰 폭증으로 이어짐

프루닝을 진행했더니 성능이 오른다!!

DAG Sampling으로 cycle 발견시 edge인 메세지를 랜덤으로 제거한다.

비용을 줄이고, 성능을 유지하는 Agent 진행 가능
| 연구 문제 | LLM 기반 Multi-Agent System(MAS)은 에이전트 간 과도한 메시지 교환으로 인해 토큰 비용 폭증, 추론 노이즈 증가, 배포 비현실성, 악성 에이전트 취약성 문제를 가짐 |
| 핵심 관찰 | 에이전트 통신의 상당 부분은 성능에 기여하지 않는 중복(redundancy)이며, 통신을 10~30% 제거해도 성능 저하 없이 오히려 향상되는 경우가 존재 |
| 핵심 아이디어 | MAS를 Spatial–Temporal Communication Graph로 모델링하고, 성능에 중요한 통신 edge만 학습 기반으로 선택(pruning) |
| 그래프 정의 | 노드: 에이전트 / 엣지: Spatial(동일 round), Temporal(이전 round) → MAS 전체를 시공간 그래프로 표현 |
| 문제 정식화 | 전체 성능을 유지(또는 향상)하면서 그래프에서 최대한 많은 통신 edge 제거 |
| 제안 방법 | AgentPrune: 통신 그래프에 대해 differentiable mask를 학습하고, low-rank 제약을 통해 중요한 소수의 통신만 남김 |
| 학습 전략 | 초기 K′ round 동안 mask 학습 → One-shot pruning으로 Top-K edge만 남기고 이후 고정 |
| 비교 대상 | AutoGen, GPTSwarm 등 기존 MAS 프레임워크 |
| 성능 결과 | MMLU, GSM8K 등에서 기존 성능 유지 또는 최대 +2~3% 향상 |
| 비용 절감 | 토큰 사용량 28.1% ~ 72.8% 감소, GPT-4 기준 비용 $43.7 → $5.6 |
| 보안/강건성 | 악성 에이전트 공격 시, 해당 agent와 연결된 edge가 제거되어 성능 붕괴 방지 및 회복 |
| Ablation 결과 | Random pruning, low-rank 제거 시 성능 붕괴 → 학습 기반 구조 선택이 필수 |
| 기술적 기여 | MAS에서 “통신 구조 자체를 학습 대상” 으로 다룬 최초의 체계적 접근 |
| 연구적 의의 | “더 많은 토큰 ≠ 더 좋은 협업” → 효율적 협업은 구조 설계 문제임을 입증 |
| 확장성 | 기존 MAS에 plug-and-play로 적용 가능, debate 없는 협업 구조에도 적합 |
https://iclr.cc/virtual/2025/32752
ICLR MAS-GPT: Training LLMs To Build LLM-Based Multi-Agent Systems
LLM-based multi-agent systems (MAS) have shown significant potential in tackling diverse tasks. However, to design effective MAS, existing approaches heavily rely on manual configurations or multiple calls of advanced LLMs, resulting in inadaptability and
iclr.cc
https://openreview.net/forum?id=3CiSpY3QdZ
MAS-GPT: Training LLMs to Build LLM-based Multi-Agent Systems
LLM-based multi-agent systems (MAS) have shown significant potential in tackling diverse tasks. However, to design effective MAS, existing approaches heavily rely on manual configurations or...
openreview.net
기존 MAS System은 사람이 설계한 고정 구조를 사용하고 inference cost가 너무 높다!
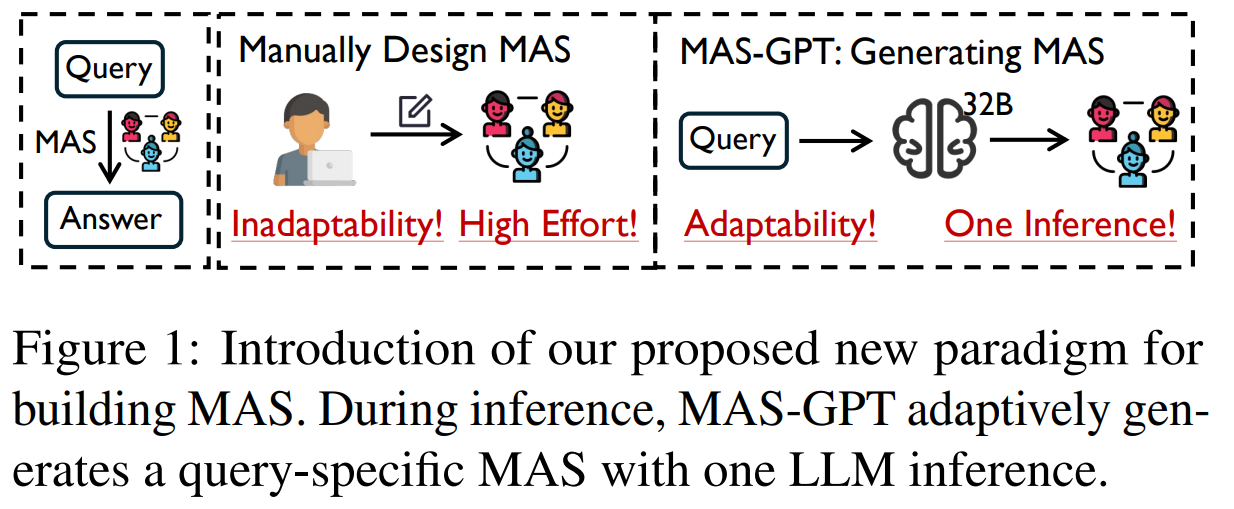
쿼리마다 적절한 MAS를 만들고 싶지만 사람 손이 많이 가거나 LLM 호출 비용이 너무큼!

LLM이 답을 생성하도록 하는 것이 아닌 에이전트 시스템을 생성하도록 LLM을 학습한다!
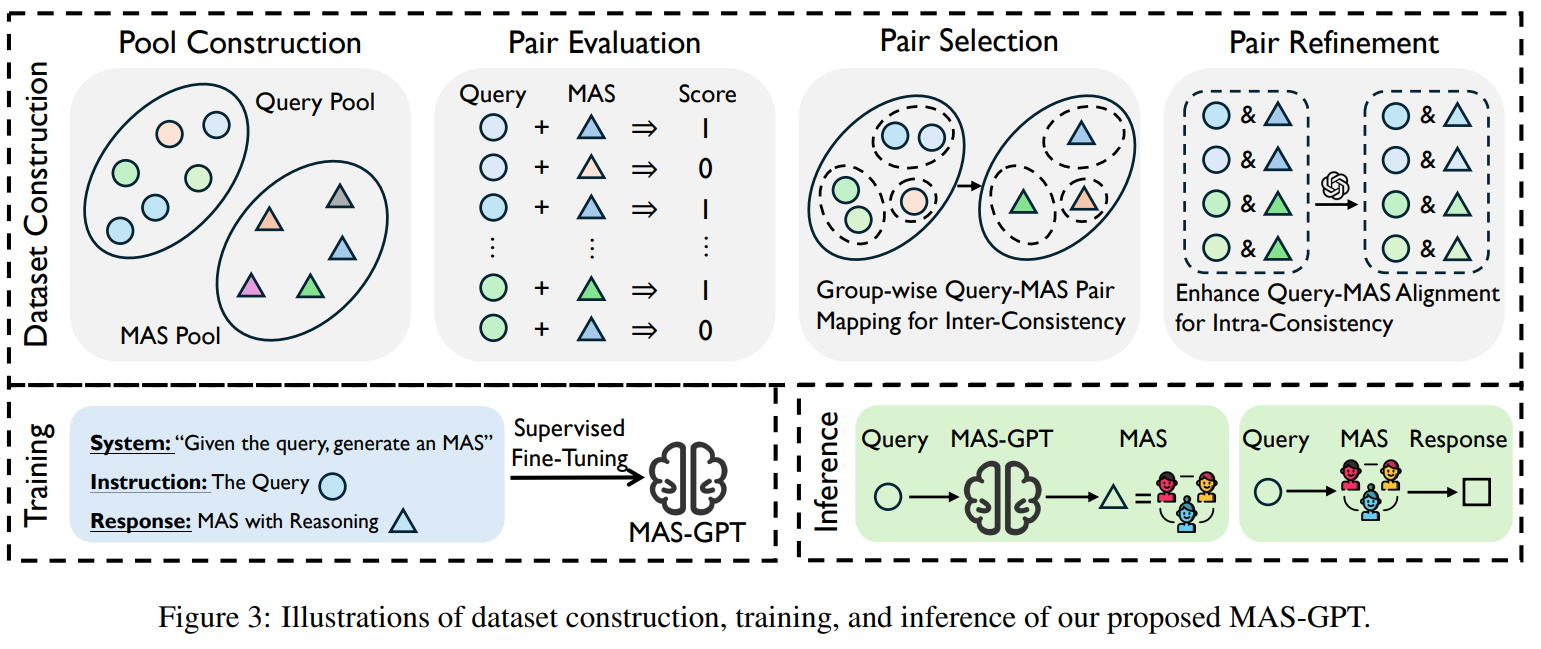
Query : 수학, 코드, QA 등 정답 검증 가능한 문제
MAS Pool : Debate, Self-Consistency, Self-Refine 등 기존 MAS 재구현으로 수작업 설계가 되어 있는 기존 MAS 구조다
모든 Query와 MAS 쌍에 대해 실행 후 정답 여부를 판단하고, Query 하나 당 MAS 별 성능을 알 수 있게 된다.
같은 유형의 Query에 서로 다른 MAS가 붙으면 어떤 MAS가 맞는지 모르기에 유사 Query를 클러스터링해서 그룹 내 누적 성능이 가장 좋은 MAS 하나만 선택하여 같은 Query 유형 -> 같은 MAS를 사용하여 일반화 패턴을 학습할 수 있게 된다.
선택된 MAS가 Query와 정확하게 맞지 않을 수 있는데 Closed - LLM을 통해 Agent 역할을 query에 맞게 수정하고, 이 MAS가 필요한지 Reasoning 문단을 생성하여 구조적 정합성과 의미적 정합성을 확보한다.
이렇게 데이터를 생성하여 MAS 생성이라는 새로운 task를 학습한다.
| 논문 핵심 문제 | 기존 LLM 기반 Multi-Agent System(MAS)은 (1) 사람이 수동으로 설계해야 하거나, (2) 쿼리마다 여러 번 LLM 호출이 필요하여 적응성 부족 + 높은 추론 비용이라는 구조적 한계를 가짐 |
| 핵심 아이디어 | MAS 설계 자체를 언어 생성 문제로 재정의: 입력은 사용자 쿼리, 출력은 해당 쿼리를 처리하는 실행 가능한 MAS |
| 제안 모델 | MAS-GPT: 단 한 번의 LLM inference로 쿼리-적응형 MAS 코드를 생성하는 LLM |
| MAS 표현 방식 | 모든 MAS를 Python forward() 함수 형태의 코드로 통일 (Agent = prompt 변수, 추론 = call_llm, 상호작용 = 문자열 결합) |
| 학습 목표 | “정답 생성”이 아닌 “적절한 Multi-Agent 구조 + 역할 분담을 생성”하도록 LLM을 SFT |
| 데이터 구축의 핵심 난제 | LLM은 원래 MAS 설계 지식이 없으며, (Query, MAS) 대응 데이터가 존재하지 않음 |
| 데이터 구축 파이프라인 | ① Query Pool & MAS Pool 구성 → ② Query-MAS 실행·정답 평가 → ③ Inter-Consistency 기반 Pair Selection → ④ Intra-Consistency 기반 Pair Refinement + Reasoning 생성 |
| Inter-Consistency | 유사한 Query 묶음에 대해 누적 성능이 가장 좋은 MAS 하나만 매핑 → 같은 유형의 문제는 같은 MAS를 학습하도록 유도 |
| Intra-Consistency | 선택된 MAS를 Query에 맞게 Agent 역할 수정 + “왜 이 MAS가 필요한지”에 대한 Reasoning 문단 생성 |
| 최종 학습 데이터 형태 | (System Prompt, Query, [Reasoning + MAS Code]) |
| 학습 방식 / 모델 | Supervised Fine-Tuning (SFT) / Qwen2.5-Coder-32B-Instruct |
| 데이터 규모 | 약 11.4K Query-MAS 쌍, 평균 MAS 길이 ≈ 785 tokens |
| 비교 대상 | Single LLM, CoT, Self-Consistency, Debate, Self-Refine, AgentVerse, GPTSwarm, DyLAN 등 10+ MAS 방법 |
| 평가 벤치마크 | MATH, GSM8K, GSM-Hard, HumanEval(+), MMLU, GPQA, SciBench, AIME-2024 |
| 주요 성능 결과 | 모든 벤치마크 평균에서 MAS-GPT 1위, 2위 대비 약 +3.9%p |
| Out-of-Domain 일반화 | 학습에 포함되지 않은 GPQA, SciBench에서도 성능 유지 |
| Reasoning LLM 결합 효과 | o1-preview 기준 AIME-2024에서 +13.3%, DeepSeek-R1 기준 +10.0% |
| 비용 효율성 | MAS 생성에 LLM 1회 호출만 필요 (AFlow, DyLAN은 10회 이상) |
| Ablation 핵심 결론 | Inter-Consistency, Intra-Consistency, Reasoning 모두 제거 시 성능 크게 하락 |
| 스케일링 특성 | 데이터 ↑ → 실행 실패 ↓ / 모델 크기 ↑ → 성능 ↑ |
| 핵심 기여 요약 | (1) MAS 생성을 학습 가능한 언어 과제로 정식화 (2) 실행 가능한 MAS 코드 생성 LLM 제안 (3) 데이터 일관성 중심 학습 전략 제시 |
| 한 줄 요약 | “MAS-GPT는 답을 생성하는 LLM이 아니라, 문제에 맞는 Multi-Agent 시스템을 설계하는 LLM이다.” |
https://arxiv.org/abs/2505.16997
X-MAS: Towards Building Multi-Agent Systems with Heterogeneous LLMs
LLM-based multi-agent systems (MAS) extend the capabilities of single LLMs by enabling cooperation among multiple specialized agents. However, most existing MAS frameworks rely on a single LLM to drive all agents, constraining the system's intelligence to
arxiv.org
기존 MAS는 단일 LLM기반으로 모델이 약한 부분에서 MAS를 구성하면 task 자체가 붕괴된다.
또한 에이전트 수는 늘었지만 지능의 다양성은 늘지 않았음
각 Agent를 서로 다른 LLM으로 구동하여 집단 지능을 단일 모델의 한계가 아니라 모델 집합의 상한으로 확장함

단일 LLM은 크기에 따라 성능이 확정되는 것도 아니고, 특정 도메인에서 붕괴되는 현상도 종종 나와 프롬프트나 구조는 동일하게 가져가고, llm 종류만 바꿔서 진행 => 성능 오름!
| 연구 문제 | 기존 LLM 기반 Multi-Agent System(MAS)은 모든 에이전트를 단일 LLM(homogeneous) 로 구동 → 모델의 한계·편향·환각이 전체 시스템에 전파되어 집단 지능이 단일 모델 상한에 갇힘 |
| 핵심 가설 | 에이전트를 이질적인 LLM(heterogeneous LLMs) 로 구동하면, MAS 성능은 단일 모델 한계를 넘어 모델 집합의 집단 지능으로 확장될 수 있음 |
| 핵심 제안 | X-MAS: 역할별로 서로 다른 LLM을 사용하는 Heterogeneous LLM-driven MAS |
| 벤치마크 | MAS 관점 최초의 체계적 LLM 벤치마크 |
| 평가 축 | 5 Functions × 5 Domains = 25 설정 • Functions: QA, Revise, Aggregation, Planning, Evaluation • Domains: Math, Coding, Science, Medicine, Finance |
| 평가 대상 LLM | 총 27개 LLM (Chatbot + Reasoner, Generalist + Specialist) |
| 실험 규모 | 1.7M+ evaluations |
| 핵심 관찰 1 | 모든 상황에서 최고인 단일 LLM은 존재하지 않음 |
| 핵심 관찰 2 | 동일 LLM이라도 도메인·에이전트 역할(Function)에 따라 성능 편차 큼 |
| 핵심 관찰 3 | 소형·전문화 LLM이 대형 LLM을 이기는 경우 다수 |
| 설계 제안 | 기존 MAS 구조·프롬프트·워크플로우는 그대로 유지하고, 에이전트별 LLM만 X-MAS-Bench 결과 기반으로 교체 |
| 적용 대상 MAS | AgentVerse, LLM-Debate, DyLAN, X-MAS-Proto |
| Chatbot-only 결과 | Homogeneous 대비 최대 +8.4% (MATH) 성능 향상 |
| Chatbot + Reasoner 결과 | AIME-2024 기준: • AgentVerse: 20% → 50% • DyLAN: 40% → 63% |
| 일반화 성능 | AIME-2025, MATH-MAS 등 미사용 벤치마크에서도 +30~40%p 향상 |
| Ablation 결과 | 후보 LLM 수 증가 → 성능 단조 증가 (도메인 적합성 중요) |
| 핵심 결론 (Conclusion) | MAS 성능 향상의 핵심은 구조나 Debate가 아니라, 역할별 LLM 다양성과 적합성 |
| 연구 의의 (Impact) | • Debate 없는 MAS 설계에 강력한 근거 제공 • LLM Routing / Agent-LLM 매핑 학습 연구의 토대 • 비용 효율적·확장 가능한 MAS 설계 방향 제시 |
https://aclanthology.org/2024.naacl-long.15/
Unleashing the Emergent Cognitive Synergy in Large Language Models: A Task-Solving Agent through Multi-Persona Self-Collaboratio
Zhenhailong Wang, Shaoguang Mao, Wenshan Wu, Tao Ge, Furu Wei, Heng Ji. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2024.
aclanthology.org
지식 집약적 task에서 사실 오류가 빈번하고 추론 집약적 task에선 깊은 사고가 부족하며, cot나 self-refine는 한계가 존재한다.
단일 LLM이 외부 에이전트나 추가 파인튜닝 없이도 사람처럼 '역할 분담 + 협업'을 수행할 수 있는가? 가 문제임
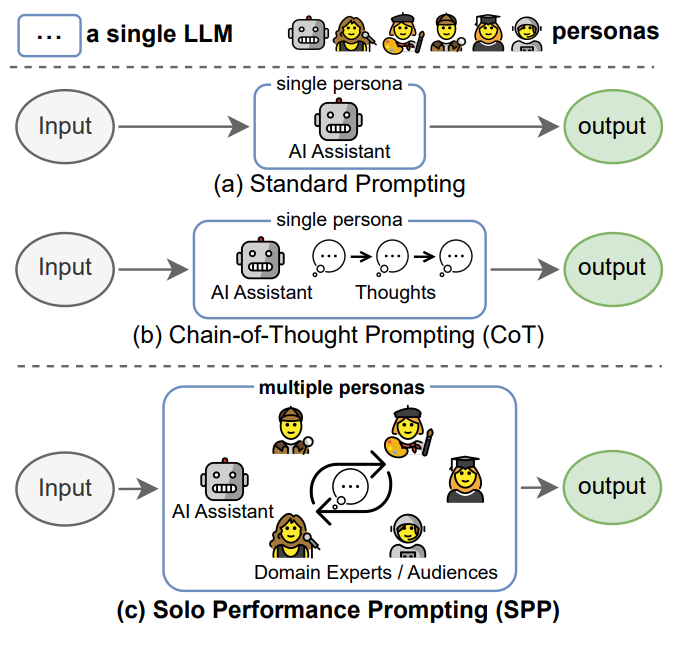
SPP는 하나의 LLM이 여러 persona를 동적으로 생성해서 자기 자신과 다중 턴 협업을 진행하며 최종 해답에 도달하도록 유도하는 zero-shot prompting 기법임
=> 단일 LLm + Multi presona
| ① Persona Identification | 입력 태스크를 보고 필요한 전문가/청중 역할을 자동 생성 |
| ② Brainstorming | 각 persona가 자신의 관점에서 지식·힌트 제공 |
| ③ Iterative Collaboration | AI Assistant(리더)가 초안 생성 → 다른 persona들이 비판·피드백 → 반복 |
| ④ Final Answer | 모든 persona가 만족하는 시점에서 결과 출력 |
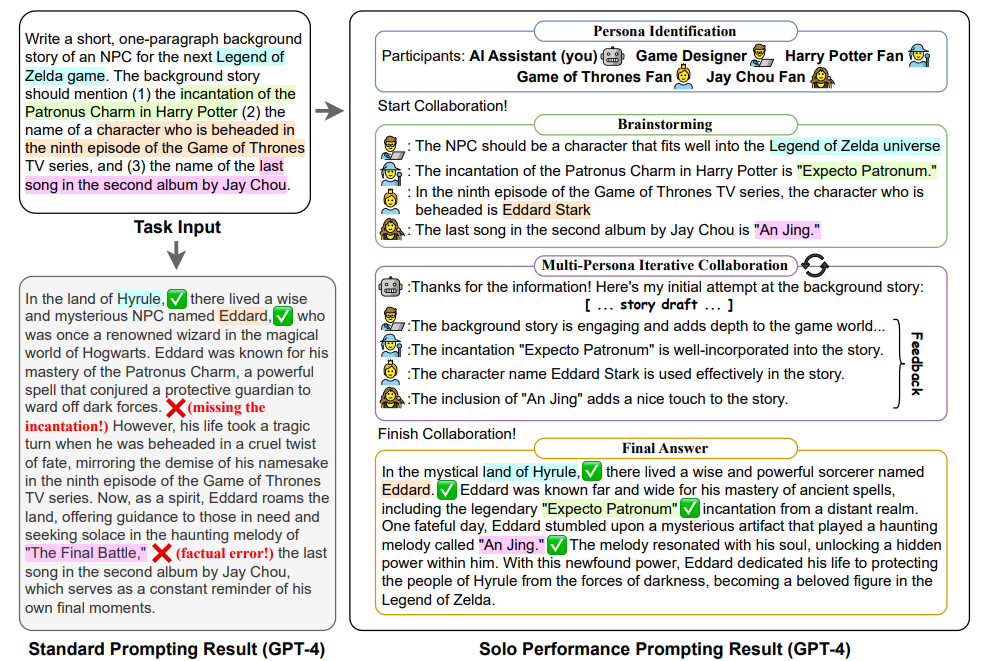
SPP = Presona 생성 + Brainstorming + iterative feedback이 포함된 확장 구조

| 연구 문제 | 단일 LLM이 외부 멀티에이전트·파인튜닝 없이도 인간처럼 역할 분담 기반 협업(cognitive synergy)을 통해 지식 정확도와 추론 성능을 동시에 향상시킬 수 있는가 |
| 기존 한계 | CoT·Self-Refine는 추론은 개선하지만 사실 오류(hallucination) 감소에는 한계, 멀티에이전트 방식은 비용·복잡도 증가 |
| 제안 방법 | Solo Performance Prompting (SPP): 하나의 LLM이 입력 태스크에 따라 여러 persona를 동적으로 생성하고, 다중 턴 자기 협업을 수행 |
| SPP 절차 | (1) Persona Identification → (2) Persona별 Brainstorming → (3) AI Assistant(리더) 초안 생성 → (4) Persona 피드백·비판 → (5) 반복 후 최종 답변 |
| 핵심 차별점 | 단일 LLM, zero-shot, retrieval·fine-tuning 불필요, dynamic fine-grained persona 사용 |
| 평가 태스크 | Trivia Creative Writing (지식 집약), Codenames Collaborative (지식+추론+ToM), Logic Grid Puzzle (추론 집약) |
| 비교 기법 | Standard Prompting, Chain-of-Thought, Self-Refine |
| 주요 성능 결과 (GPT-4) | 모든 태스크에서 SPP 최고 성능: 특히 Trivia CW(N=10) +10%p, Codenames +~5%p, Logic Puzzle에서도 CoT 대비 경쟁력 |
| 핵심 관찰 ① | CoT는 추론 태스크에는 유효하나 지식 정확도 개선에는 한계 |
| 핵심 관찰 ② | SPP는 사실 오류 감소 + 추론 유지를 동시에 달성 |
| Emergent 분석 | Cognitive synergy는 GPT-4에서만 명확히 발현, GPT-3.5·LLaMA2에서는 실패(early termination) |
| Ablation 결과 | Dynamic persona > Fixed persona, persona profile 추가는 효과 미미 |
| 이론적 시사점 | Cognitive synergy는 단순 prompting 기법이 아니라 모델 능력에 의존하는 emergent ability |
| 한계점 | persona가 항상 정답 보장 ❌, 동일 demo prompt 사용의 비최적성, multi-turn으로 인한 계산 비용 |
| 향후 연구 | 입력 조건별 demo 적응, SPP → 실제 multi-agent cabinet 구조 확장 |
| 연구 기여 요약 | GPT-4 수준 LLM에서 zero-shot으로 지식·추론 동시 향상을 달성한 최초의 multi-persona self-collaboration 프레임워크 |
'인공지능 > 논문 리뷰 or 진행' 카테고리의 다른 글
| Multi-turn, Long-context Benchmark 논문 2 (0) | 2026.01.18 |
|---|---|
| Multi-turn, Long-context Benchmark 논문 1 (0) | 2026.01.17 |
| MAS 논문 - 1 (0) | 2026.01.16 |
| LANGSAE EDITING: Improving Multilingual Information Retrieval via Post-hoc Language Identity Removal (0) | 2026.01.14 |
| NaviAgent, AGENTORCHESTRA (0) | 2026.01.11 |