이제 Inference를 할 때 text 생성 부분에서 프라이버시를 지켜야 하기 때문에...
https://arxiv.org/abs/2305.18396
LLMs Can Understand Encrypted Prompt: Towards Privacy-Computing Friendly Transformers
The community explored to build private inference frameworks for transformer-based large language models (LLMs) in a server-client setting, where the server holds the model parameters and the client inputs its private data (or prompt) for inference. Howeve
arxiv.org
prompt가 서버에 평문으로 노출됨!
또한 서버의 모델 파라미터 또한 보호해야 한다
Private Inference가 해결책이지만 Transformer 기반 LLM에서는 연산량과 통신량이 과도하고, GELU, Softmax, LayerNorm 같은 연산이 HE/MPC 환경에서 병목임
=> Transformer 구조를 그대로 두고는 실용적인 Private Inference가 불가능!
프라이버시에 친화적이지 않은 연산자를 암호 연산에 유리한 연산자로 근사하여 대체하고, fine-tuning으로 성능 복구하자
GELU, Softmax, Layernorm을 변경
선형연산인 FC와 Attention MatMul을 Homomorphic Encryption(BFV, RLWE 기반) 으로 변경
비선형 연산인 GELU와 Softmax, LN은 MPC (Oblivious Transfer 기반)으로 변경하여 모든 중간 결과는 secret sharing 상태를 유지한다.
GELU => RELU
GELU는 tanh + 다중 곱셈으로 MPC 비용이 폭팔하여 RELU로 변경하고 fine-tuning 하면 정확도 손실 거의 없고, 연산량 및 통신량 감소
Softmax => ReLU 기반 정규화
exp, max, recip을 제거하고 ReLU로 Attention mask −∞ 문제도 처리. Q/K/V projection만 재학습하면 됨.
LayerNorm => Centering + Affine
sqrt, division 제거하고 분산 정보를 γ, β가 흡수하도록 fine-tuning
뒤쪽 레이어부터 차근 차근 교체하여 성능유지를 진행
Layer 2, 8, 12개 가진 모델들을 테스트하며 진행
통신량과 연산 시간을 모두 줄임!
| 연구 목적 | LLM 서버-클라이언트 환경에서 입력 프롬프트와 모델 파라미터를 모두 보호하면서도 실용적인 속도의 private inference를 달성 |
| 문제 정의 | Transformer 기반 LLM은 GELU, Softmax, LayerNorm 때문에 HE/MPC 환경에서 연산·통신 비용 폭증 |
| 핵심 관찰 | Private inference 비용의 70% 이상이 비선형 연산(GELU/Softmax/LN) 에서 발생 |
| 기본 암호 프레임워크 | • 선형 연산: Homomorphic Encryption (BFV, RLWE 기반) • 비선형 연산: MPC (Oblivious Transfer 기반) |
| 주요 아이디어 | 암호 친화적이지 않은 연산자를 구조적으로 대체하고 fine-tuning으로 정확도 복구 |
| 연산자 대체 전략 | • GELU → ReLU • Softmax → ReLU + 합 정규화 • LayerNorm → (x−mean)·γ+β (분산 제거) |
| Substitution 방법론 | • 뒤 레이어부터 점진적 교체 • 각 단계마다 fine-tuning + 검증 • 허용 정확도 하락 ≤ 2% |
| 수치 안정화 기법 | Fixed-point overflow 방지를 위해 Bound-aware loss 추가 |
| 실험 모델 | BERT-Tiny (2L), BERT-Medium (8L), RoBERTa-Base (12L) |
| 데이터셋 | GLUE: MRPC, SST-2, QNLI |
| 성능 결과 (속도) | 기존 Iron 대비 최대 5× 추론 속도 향상 |
| 성능 결과 (통신) | 통신량 최대 80% 감소 |
| 정확도 변화 | 대부분 task에서 동등 또는 소폭 향상 |
| 중요한 발견 | ReLU 기반 Transformer가 fine-tuning 환경에서는 GELU보다 성능이 더 좋은 경우 존재 |
| 보안 모델 | Semi-honest adversary, 입력·모델 프라이버시 보장 |
| 논문의 핵심 기여 | 1) Transformer private inference 병목 정량화 2) Privacy-Computing Friendly Transformer 설계 원칙 제시 3) SOTA 수준의 속도·통신 효율 |
| 한계 및 향후 과제 | • 초기 LayerNorm 일부는 교체 어려움 • Decoder-only LLM 확장 필요 • Distillation / pruning 결합 가능성 |
https://arxiv.org/abs/2508.09442
Shadow in the Cache: Unveiling and Mitigating Privacy Risks of KV-cache in LLM Inference
The Key-Value (KV) cache, which stores intermediate attention computations (Key and Value pairs) to avoid redundant calculations, is a fundamental mechanism for accelerating Large Language Model (LLM) inference. However, this efficiency optimization introd
arxiv.org
LLM 추론 가속을 위해 사용되는 KV-Cache는 성능을 위한 설계지만 이로부터 prompt를 복구할 수 있는 프라이버시 취약점이 발생
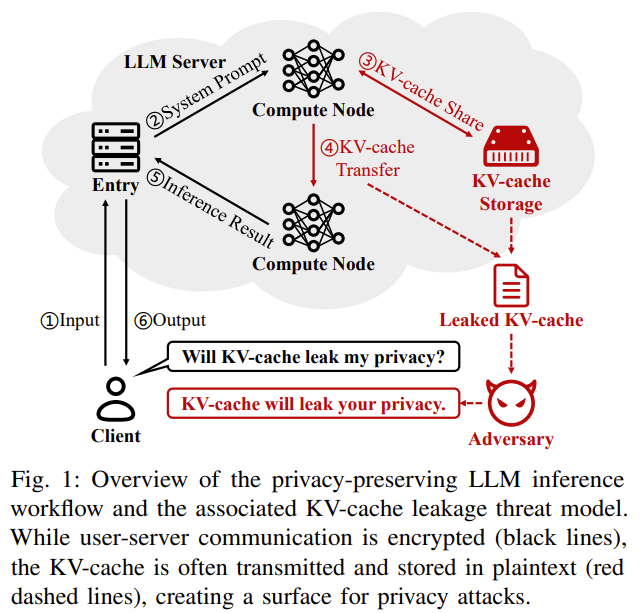
공격자는 LLM 추론 서비스 제공자 또는 내부자로 정하고, 공격자는 모델 가중치를 알며 prompt를 복원하려고 시도한다.
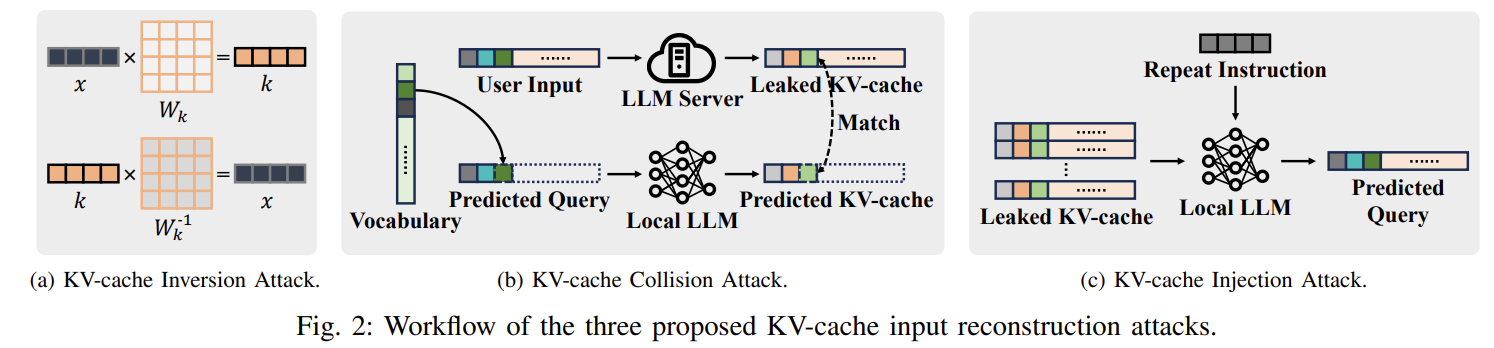
k = x * Wk 이므로 W가 가역이면 x를 역 연산할 수 있다.
이를 통해 MHA와 첫 번째 레이어일 경우 복구하는 것을 볼 수 있었다.
prompt injection도 완벽한 복원은 아니지만 의미적 정보를 대량으로 유출하는 것을 볼 수 있었음
기존 암호화 방법(AES/HE)는 지연이 너무 심하고, DP에서 의미있는 ε는 정확도가 붕괴하며 KV-Shield는 고정된 permutation으로 collision/CPA에 취약하고, RoPE가 비호환이다.
KC-Cloak를 통해 보안 극대화
| 연구 배경 | LLM 추론 가속을 위해 사용하는 KV-cache가 실무 환경에서 평문으로 저장·전송됨. 이는 성능 최적화를 위한 설계 선택이지만, 사용자 입력(prompt)이 직접 유출될 수 있는 새로운 프라이버시 공격면을 형성 |
| 핵심 문제의식 | 기존 프라이버시 연구는 출력(output)이나 embedding 중심 → KV-cache라는 중간 상태(intermediate state)의 위험성은 거의 미연구 |
| 연구 질문 (RQ) | RQ1: KV-cache로부터 사용자 입력을 복원할 수 있는가? RQ2: 정확도 저하 없이, 실무적으로 이를 방어할 수 있는가? |
| 위협 모델 | 공격자는 KV-cache + 모델 가중치(gray-box) 접근 가능 (CSP/내부자). GPU 레지스터 등 일시적 activation은 접근 불가. 목표는 입력 텍스트의 정확·의미적 복원 |
| 공격 1: Inversion Attack | K,V = x·W → W가 가역이면 x 역산. • 1st layer + MHA에서만 효과적 • GQA/MLA, deep layer에서는 거의 실패 |
| 공격 2: Collision Attack (핵심) | 후보 토큰을 하나씩 넣어 생성된 KV-cache와 leaked KV-cache 간 거리 최소화로 토큰 식별 • 모든 layer, 최신 LLM(GQA 포함)에 적용 • 확률 기반 pruning + batch outlier detection으로 실용적 공격 속도 달성 • CPA 활용 시 거의 100% 입력 복원 |
| 공격 3: Injection Attack | 탈취한 KV-cache 뒤에 “Repeat the previous content” 같은 instruction을 주입 → LLM이 스스로 cache를 해석해 의미적 정보 유출 • 단 1회 inference • verbatim은 아니지만 의미 유출(BERTScore≈0.58) |
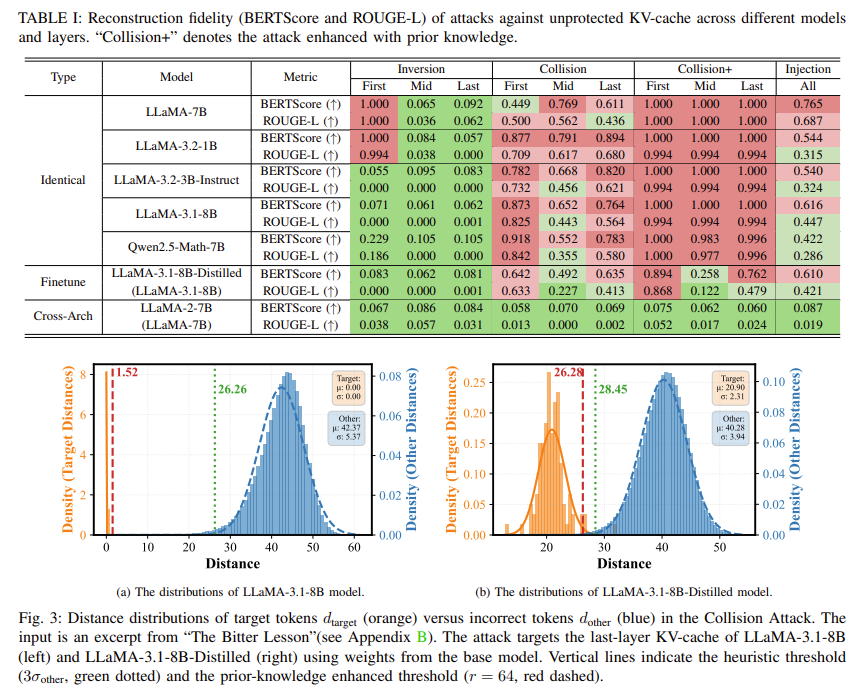
| 공격 실험 결과 | Plain KV-cache에서는 대부분의 모델에서 높은 입력 복원율 확인 → KV-cache 유출은 이론이 아닌 실질적 위협임을 입증 |
| 기존 방어의 한계 | • 암호화(AES/HE): KV-cache 크기 때문에 지연 과다 • DP: 의미 있는 ε에서 정확도 붕괴 • KV-Shield: 고정 permutation → Collision/CPA에 취약, RoPE 비호환 |
| 제안 기법: KV-Cloak | 가역 선형 변환 + block-wise one-time permutation으로 KV-cache를 통계·의미적으로 무력화 K' = S P^(K + A)M |
| 기술적 핵심 1 | One-time permutation으로 토큰 위치–cache 대응 완전 붕괴 → Collision Attack 원천 차단 |
| 기술적 핵심 2 | Operator Fusion: 변환 행렬을 attention weight에 사전 결합 → RoPE 호환, 정확도 수식적으로 동일 |
| 보안성 평가 | Inversion / Collision / Collision+ / Injection 모두 실패 → 복원 결과가 랜덤 문자열과 통계적으로 구분 불가 |
| 정확도(Utility) | MMLU, SQuAD 등에서 Plaintext와 완전히 동일 → Lossless defense 입증 |
| 성능 오버헤드 | KV-Cloak(fused): ~15 ms / GB → prefill 대비 < 0.5% |
| 아키텍처 호환성 | vLLM, PagedAttention(block 16/32/64)와 완전 호환 |
| 논문의 핵심 기여 | ① KV-cache를 LLM 프라이버시의 핵심 취약점으로 정식화 ② 실질적 입력 복원 공격(Collision) 제시 ③ 정확도 손실 없는 KV-cache 전용 방어(KV-Cloak) 제안 |
| 한계 및 향후 과제 | • Key 관리(TEE 의존) • Quantized KV-cache(INT8/4) 확장 • activation/MoE routing 보호로 확장 가능 |
| 한 줄 요약 | “KV-cache는 LLM 프라이버시의 새로운 핵심 공격면이며, KV-Cloak은 이를 거의 유일하게 lossless로 막는 실무적 해법이다.” |
https://icml.cc/virtual/2025/poster/45330
ICML Poster Hidden No More: Attacking and Defending Private Third-Party LLM Inference
Large language models (LLMs) are often run by third-party services, raising serious concerns about user data privacy. This risk motivates the need for protocols which run LLMs on encrypted prompts instead of raw user data. While many such protocols are pro
icml.cc
ICML에 붙은 논문입니다!
그냥 Prompt를 text로 넣는 것 부터 시작해서 prompt를 보호하기 위해 초반과 후반 layer는 user 단에 두고, 연산량이 큰 middle layer는 서버에 둬서 진행하는 방법이 나오고 있다.
그러나 이렇게 진행해도 prompt의 유출은 막을 수 없다!
Hidden state를 볼 수 있으면 이전 layer를 활용하여 구할 수 있기 때문이다.

autoregressive 구조와 공개된 모델 가중치를 이용해 hidden state와 가장 잘 맞는 토큰을 어휘 단위로 하나씩 역추적하여 선형 수준의 복잡도로 프롬프트를 복원할 수 있다.
Cascade는 hidden state를 토큰 단위로 분할(sharding)하여 어느 단일 파티도 완전한 시퀀스 정보를 볼 수 없게 설계한다.
암호학적 MPC보다 훨씬 낮은 통신, 연산비용이 들며 기존 hidden-state / logit reversal 공격을 모두 방어함
| 연구 배경 | 대규모 LLM을 직접 실행하기 어려워 서드파티 추론이 보편화됨. 프롬프트 대신 hidden state / embedding만 서버에 보내면 안전하다는 기존 가정이 널리 사용됨 |
| 핵심 문제의식 | “hidden state만 노출되어도 원본 프롬프트가 복원 가능한가?” |
| 위협 모델 | Open-weights LLM, 공격자는 모델 가중치 + 중간 hidden state(또는 permutation된 형태) 에 접근 가능한 semi-honest party |
| 제안 공격 | Vocab-Matching Attack: autoregressive 특성을 이용해 hidden state와 가장 잘 맞는 토큰을 어휘 단위로 순차 복원 |
| 공격 성능 | Gemma-2-2B-IT, Llama-3.1-8B-Instruct 등에서 프롬프트 복원 정확도 ≈ 99~100% |
| 무력화된 방어 | Sequence permutation, Hidden-dim permutation, Factorized-2D permutation, Gaussian noise, Quantization → 모두 실질적 방어 실패 |
| 핵심 실증 결과 | LLM hidden state는 고차원에서도 매우 비충돌적(non-colliding) → 사실상 원문과 동형 |
| 기존 방식 한계 | “Permutation 공간이 크다 = 안전하다”는 통계적 직관이 실제 추론 구조에서는 성립하지 않음 |
| 제안 방어 | Cascade: token-dimension sharding 기반 multi-party inference |
| Cascade 핵심 아이디어 | 어떤 단일 파티도 연속 토큰의 hidden state를 보지 못하게 구조적으로 차단 |
| Cascade 보안성 | vocab-matching 공격 및 기존 hidden/logit reversal 공격 모두 방어 가능 |
| Cascade 효율성 | MPCFormer, Puma 대비 최대 90~160× 빠르고 통신량 대폭 감소 |
| 한계 | Layer-0 embedding은 본질적으로 토큰 복원 가능 → 완전 보안은 SMPC 결합 필요 |
| 결론 | hidden state는 plaintext와 다르지 않음. 구조적 분리 없이 representation만 숨기는 방식은 안전하지 않음 |
| 연구적 의의 | private inference, embedding privacy, hidden-state obfuscation에 대한 기본 가정 자체를 붕괴시킴 |
https://arxiv.org/abs/2509.08383
Efficient Decoding Methods for Language Models on Encrypted Data
Large language models (LLMs) power modern AI applications, but processing sensitive data on untrusted servers raises privacy concerns. Homomorphic encryption (HE) enables computation on encrypted data for secure inference. However, neural text generation r
arxiv.org
동형 암호(HE) 환경에서 LLM 텍스트 생성을 실질적으로 가능하게 하는 것을 목표로!
HE는 덧셈이나 곱셈과 같은 다항 연산만 지원하지만 LLM Decoding의 핵심인 argmax나 top-p나 nucleus sampling은 비교, 정렬, 조건 분기 등 비다항 연산에 의존함
그래서 기존 HE argmax는 vocab이 커질수록 지연 시간이 지속적으로 늘어나 LLM이 암호화된 상태에서 여러 토큰을 생성하는 것은 비현실적
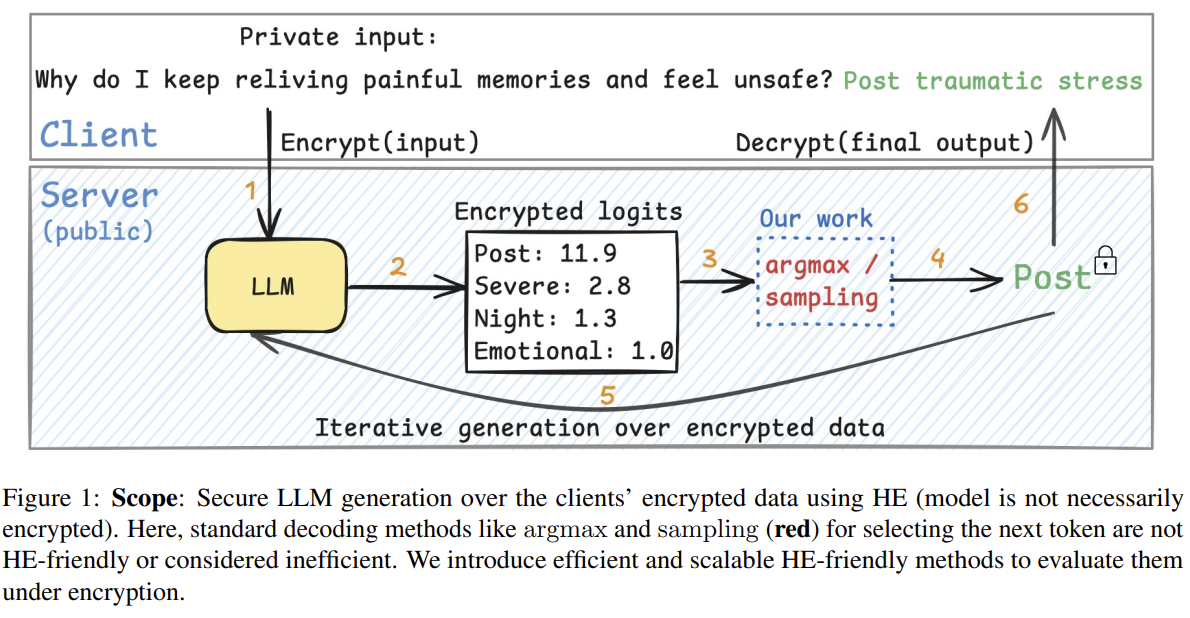
CutMax는 비교 연산을 제거하고, 반복적인 다항 연산으로 최대값만 살아남게 함
최대값과 차순위 값의 비율을 지수적으로 증폭시키면 비교 없이도 argmax가 됨!

연산 속도는 40배 가까이 줄이면서 정확도는 기존 argmax와 동일하게 유지함
이를 통해서 확률적 decoding도 가능하게 만들었음
| 연구 배경 / 문제의식 | 동형암호(HE) 환경에서는 덧셈·곱셈 같은 다항 연산만 가능하여, LLM decoding의 핵심인 argmax·sampling이 비현실적으로 느림. 기존 HE 기반 LLM 연구는 추론(inference)은 가능했지만, 텍스트 생성(decoding) 은 사실상 불가능했음 |
| 핵심 병목 | 기존 HE argmax는 SIGN 근사 기반 비교 연산에 의존 → 깊은 multiplicative depth, 잦은 bootstrap, vocabulary 증가 시 수십~수백 초 지연 |
| 핵심 아이디어 | 비교를 완전히 제거하고, 평균·분산 정규화 + odd power 반복으로 최댓값과 차순위 값의 gap을 지수적으로 증폭시켜 argmax를 구현 |
| 제안 방법 ① (CutMax) | 반복적 다항 연산만으로 argmax를 근사하는 HE-friendly argmax 알고리즘. 소수 iteration(T≤3~4) 만에 one-hot에 수렴 |
| 제안 방법 ② (HE Nucleus Sampling) | Gumbel/Beta noise + CutMax를 결합한 세계 최초 HE-compatible top-p(nucleus) sampling. 단 1회 CutMax 호출로 샘플링 |
| 이론적 기여 | CutMax가 max/runner-up gap ratio를 iteration마다 지수적으로 증폭시킨다는 수렴 정리 증명 |
| 차별점 (기존 대비) | SIGN 기반 tournament/league 방식 제거 → 깊이·연산량 대폭 감소, vocabulary 크기에 거의 무관한 iteration 수 |
| 추가적 중요 포인트 | CutMax와 sampling이 plaintext에서도 완전 미분 가능 → STE 없이 gradient-based sequence-level 학습 가능 |
| 논문의 핵심 주장 | “LLM 텍스트 생성은 HE 환경에서도 실용적으로 가능하며, decoding을 다항 연산으로 재설계하면 프라이버시·효율·정확도를 동시에 달성할 수 있다” |
| 연구적 의미 | Privacy-preserving LLM을 inference → generation 단계까지 확장, secure generative AI의 결정적 병목 해결 |
'인공지능 > 논문 리뷰 or 진행' 카테고리의 다른 글
| Privacy AI 관련 조사 9 (1) | 2026.01.20 |
|---|---|
| Privacy AI 관련 조사 8 (1) | 2026.01.20 |
| Multi-turn, Long-context Benchmark 논문 2 (0) | 2026.01.18 |
| Multi-turn, Long-context Benchmark 논문 1 (0) | 2026.01.17 |
| MAS 논문 - 2 (0) | 2026.01.16 |