https://arxiv.org/abs/2410.09457
Power-Softmax: Towards Secure LLM Inference over Encrypted Data
Modern cryptographic methods for implementing privacy-preserving LLMs such as Homomorphic Encryption (HE) require the LLMs to have a polynomial form. Forming such a representation is challenging because Transformers include non-polynomial components, such
arxiv.org
HE 기반의 LLM Inference는 Polynomial이어야 함!
But transformer의 핵심인 Softmax-attention은 지수, 나눗셈, max 연산 등 non-polynomial 연산에 강하게 의존함
PTA -> 고차 다항식 필요 -> HE에서 Latency, noise 폭증
Softmax 제거 -> 안정성, 스케일링 붕괴 -> LLM으로 확장 불가
=> Softmax를 근사하지 말고, HE에 적합한 새로운 Attention을 만들자

exp 대신에 거듭 제곱을 활용해서 완전한 다항식 구조로 바꾸고, 정규화, 상대적 중요도 강조등 attention의 본질적 성질은 유지하였다.
Softmax의 확률적 의미가 아니라 상대적 가중치 증폭 + 정규화라는 기능적 본질만 취했습니다.
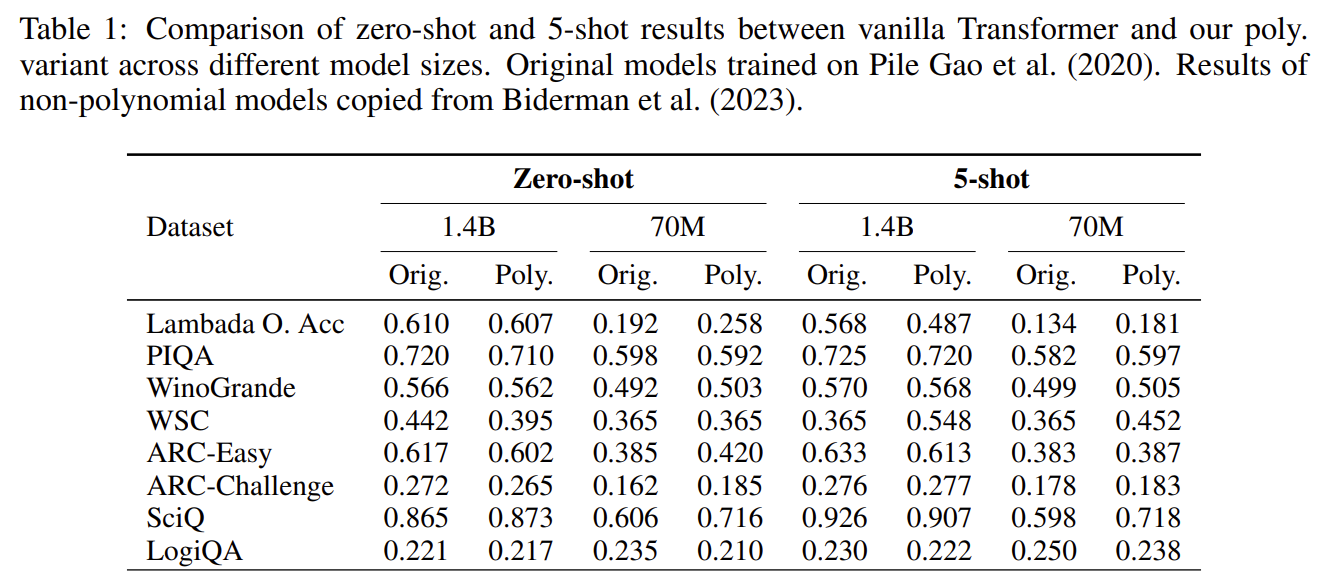
기존 polynomial transformer 대비 10배이상 스케일을 확장 함
성능 측면에서 LLM 답게 동작하는 모습을 보여줌
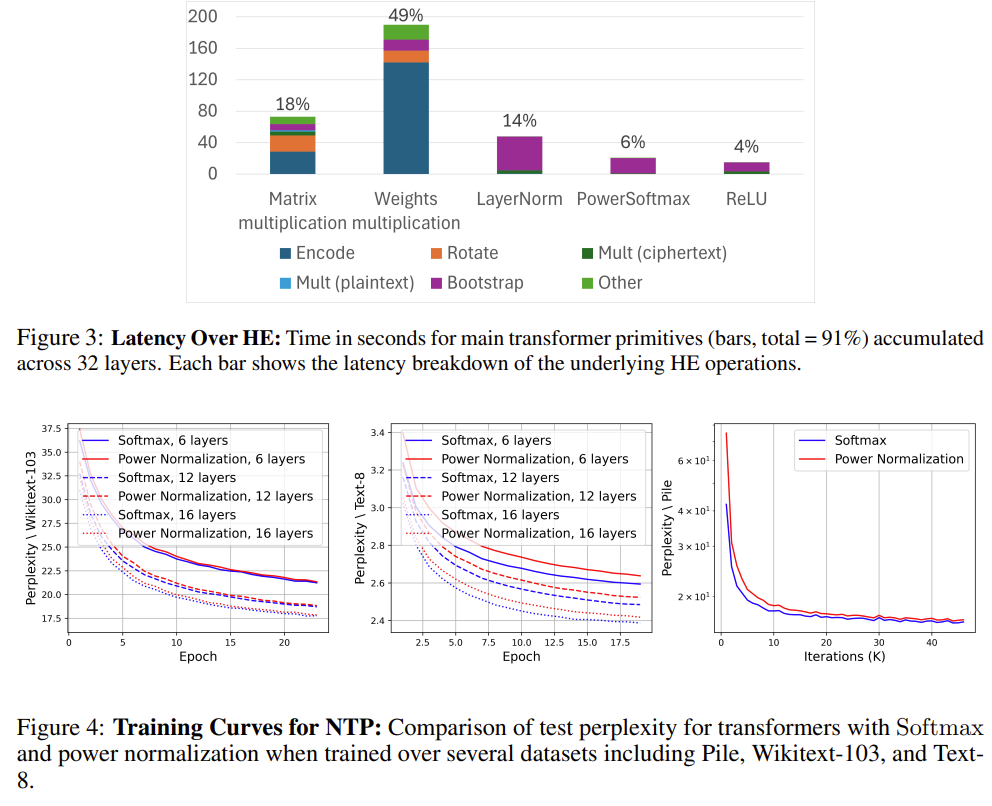
| 연구 배경 / 문제 정의 | Homomorphic Encryption(HE) 환경에서는 모든 연산이 다항식(polynomial) 이어야 하나, Transformer의 핵심인 Softmax-Attention은 지수·나눗셈·max 등 비다항 연산에 의존함. 기존 polynomial approximation 기반 접근은 불안정하거나 대규모 LLM으로 확장 불가 |
| 기존 방법의 한계 | (1) Post-Training Approximation: 고차 다항식 필요 → HE에서 latency·noise 급증 (2) Softmax 제거형 Attention: 학습 안정성·성능 붕괴 → billion-scale 불가 |
| 핵심 아이디어 | Softmax를 근사하지 않고, HE에 적합한 새로운 Attention 연산 자체를 설계 |
| 제안 방법 (핵심 연산) | PowerSoftmax Attention: → x^p / (∑x^p) (p는 짝수) • exp 제거 → 완전한 다항식 구조 • Attention의 정규화·가중치 증폭 성질 유지 |
| 학습 안정화 기법 | Stable PowerSoftmax: 입력을 ||x||∞로 스케일링 → overflow/underflow 방지 (Softmax의 log-sum-exp 역할을 다항식적으로 대체) |
| HE 근사 용이화 기법 | ε-Lipschitz Division: 분모에 ε 추가 → division을 안정적으로 저차 다항식 근사 가능 |
| 긴 시퀀스 대응 | Length-Agnostic Attention: sum 대신 mean 기반 정규화 → 시퀀스 길이 증가해도 근사 난이도 고정 |
| 전체 파이프라인 | (1) Attention 구조를 PowerSoftmax로 교체 후 학습 (2) Range-Minimization Loss로 비다항 연산 입력 범위 축소 (3) Division·LayerNorm·GELU를 다항식으로 치환 |
| 모델 스케일 | 32-layer, 1.4B 파라미터 polynomial LLM — 기존 polynomial transformer 대비 10배 이상 규모 확장 |
| 성능 결과 | Zero-shot / Few-shot 성능이 동일 크기 일반 Transformer와 거의 동일 ARC, LogiQA 등 Reasoning 및 ICL 능력 유지 |
| HE 추론 효율 | Attention 당 단 1회의 division 근사만 필요 → 기존 방법 대비 HE latency 및 bootstrap 비용 대폭 감소 |
| 기술적 기여 요약 | • HE-friendly Attention의 새로운 설계 패러다임 제시 • 최초의 billion-scale polynomial LLM 실현 • 실제 HE 환경에서의 latency breakdown 제공 |
| 논문의 핵심 메시지 | 프라이버시 보존 LLM의 병목은 ‘근사 기법’이 아니라 ‘아키텍처 설계’이며, Transformer의 본질은 Softmax 자체가 아니라 정규화된 상대적 중요도 학습임을 증명 |
| 의미 / 임팩트 | HE 기반 Secure LLM을 toy model → 실사용 가능한 LLM 단계로 끌어올린 전환점 |
https://arxiv.org/abs/2410.02486
Encryption-Friendly LLM Architecture
Large language models (LLMs) offer personalized responses based on user interactions, but this use case raises serious privacy concerns. Homomorphic encryption (HE) is a cryptographic protocol supporting arithmetic computations in encrypted states and prov
arxiv.org
ICLR 2025에 붙은 논문입니다.
사용자 데이터가 LLM 서버에 평문으로 노출 되는 것이 문제이나 GDPR/CCPA 등은 규제로 실사용 제약이 증가한다.
HE는 이론적 해법이지만 연산 비용, 정확도, 부트스트래핑 문제가 치명적이다.
=> 암호 친화적 Transformer 아키텍쳐를 통해 암호화된 상태에서 fine-tuning과 inference를 가능하게 한다.
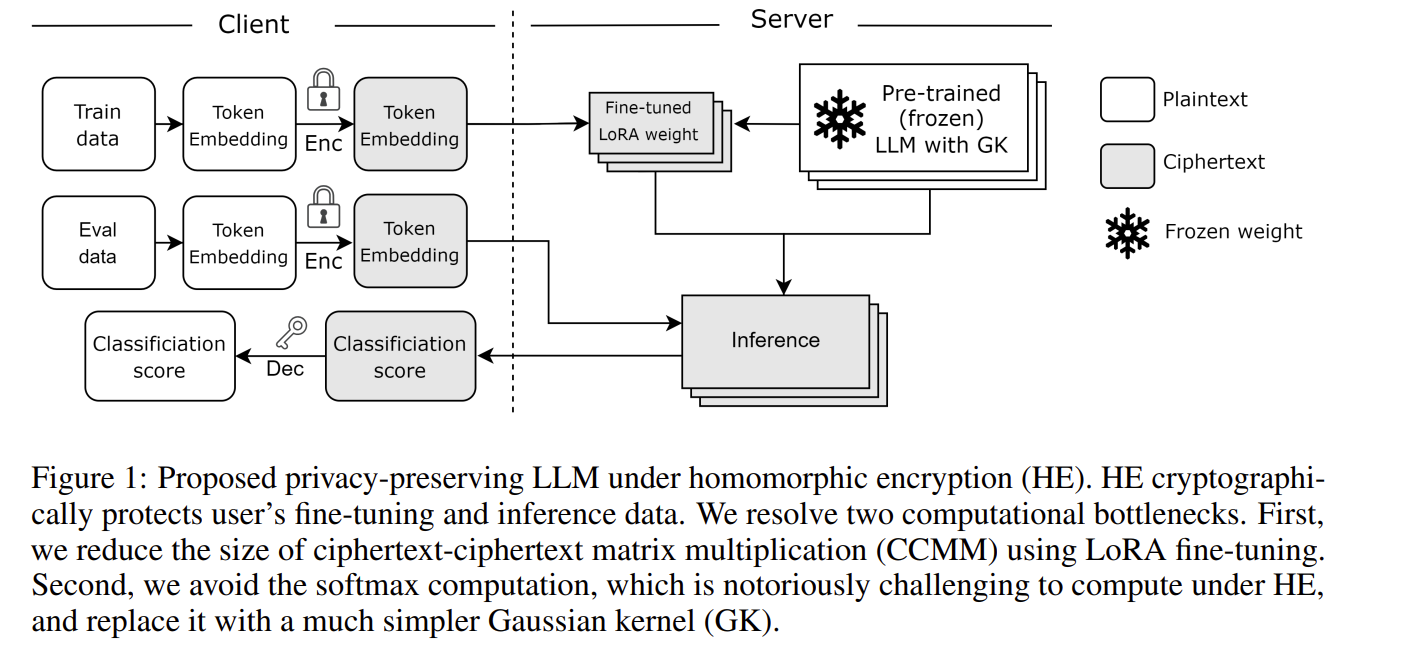
LoRA를 통해 CCMM 폭발 문제를 해결
Softmax를 제거해 Gaussian Kernel Attention을 통해 정규화를 제거하고, exp를 x<=0 구간에서만 근사하여 안정화를 진행
Client는 입력 토큰 임베딩을 CKKS로 암호화
LoRA 가중치 또한 사용자 데이터의 요약본으로 암호화 진행

파인튜닝은 6.94배 빨라지고, inference는 2.3배 빨라지며 fine-tuning 대비 정확도 감소는 제한적임
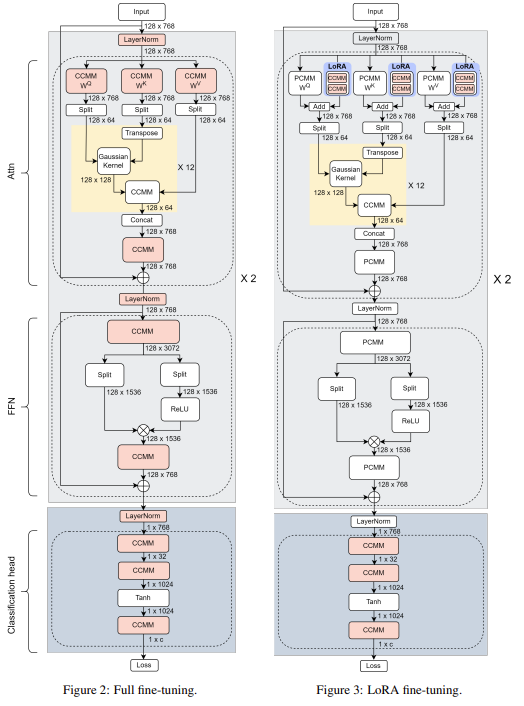
그림으로 이해하기 쉽게 해준 것이 하나 있길래..
| 문제의식 | 개인화 LLM 서비스에서 사용자 입력·파인튜닝 데이터가 서버에 평문 노출 → GDPR/CCPA 등 규제 충돌. 기존 HE 기반 연구는 inference-only에 머물러 개인화 fine-tuning을 보호하지 못함 |
| 목표 | 사용자 데이터 기반 개인화 파인튜닝 + 추론 전체를 암호화 상태에서 수행 가능한 LLM 아키텍처 제안 |
| 위협 모델 | Semi-honest server. 서버는 연산은 수행하지만 사용자 데이터·개인화 정보는 의미적으로 해석 불가 (semantic security, CKKS 가정) |
| 핵심 설계 철학 | 암호화는 “사용자 정보에만” 적용: 사전학습 LLM 가중치는 서버 자산 → 평문, 사용자 입력·LoRA 가중치는 사용자 정보 → 암호문 |
| 기술적 병목 ① | HE 환경에서 Ciphertext–Ciphertext Matrix Multiplication (CCMM) 이 극도로 비쌈 |
| 해결 ① | LoRA Fine-tuning 적용 → 대규모 가중치 업데이트 제거, 소규모 CCMM + 대규모 PCMM 구조로 변환 |
| 기술적 병목 ② | Softmax (exp, div, max) 는 HE에서 고차 다항 근사 + 잦은 Bootstrapping 필요 |
| 해결 ② | Gaussian Kernel Attention (GK) 도입 → Softmax 제거, x≤0 구간 exp 근사만 사용, division/max 불필요 |
| 암호 기술 | CKKS Homomorphic Encryption (HEaaN 라이브러리) |
| 시스템 구조 | Client: 입력 임베딩 암호화 → Server: 평문 사전학습 가중치 + 암호문 LoRA/입력으로 암호화된 fine-tuning & inference 수행 |
| 실험 모델 | 2-layer BERT-style encoder (hidden 768, 12 heads) |
| 벤치마크 | GLUE (CoLA, MRPC, RTE, STS-B, SST-2, QNLI) |
| 속도 성능 | Fine-tuning 6.94× 가속, Inference 2.3× 가속 (Full fine-tuning + Softmax 대비) |
| 정확도 | Plaintext Full fine-tuning 대비 성능 저하 매우 제한적, HE 추론 결과 ≈ Plaintext 추론 |
| 핵심 기여 | 암호화된 개인화 LLM 파이프라인을 실제로 구현한 최초 수준의 아키텍처 |
| 의의 | HE 기반 LLM을 “inference-only”에서 “personalization-capable” 단계로 확장, Privacy-preserving LLM-as-a-Service의 기준점 제시 |
초반 후반부 Layer에서 유출 가능성?
가능한 “평문 추론” 상황이라면 말씀하신 것처럼 초반/후반 layer의 hidden state로 입력 토큰을 복원하는 류의 공격(embedding inversion, activation inversion 등)이 성립할 수 있습니다.
하지만 이 논문 설정(HE/CKKS) 에서는 그 전제가 깨집니다.
핵심은 한 가지입니다.
서버는 layer 출력(hidden state), logits, attention score를 “보긴” 하지만, 그 값이 전부 암호문(ciphertext) 이라서 의미를 해석(복호)할 수 없습니다.
왜 “원본 모델 가중치가 평문”이어도 토큰을 유추 못하나?
HE 추론은 형태가 이렇게 됩니다.
- 클라이언트가 토큰을 임베딩까지 만든 뒤(혹은 임베딩 결과를 얻은 뒤) 그 임베딩을 CKKS로 암호화해서 서버에 보냄
- 서버는 평문 가중치 (W)로 연산하지만, 입력이 암호문이므로
- 중간의 (h_1, h_2, ...)는 항상 ct(·) 형태 (암호문)로만 존재
- 서버는 비밀키를 갖고 있지 않으니 ct(h_t)를 보고 h_t를 읽을 수 없음
→ 따라서 “초반 layer 표현을 보고 토큰을 복원” 같은 건 관측 자체가 불가능합니다. (논문은 CKKS의 semantic security(IND-CPA) 가정 하에서 서버가 사용자 데이터를 해석할 수 없다고 둡니다.)
즉, 가중치가 평문이라는 사실은 “계산을 가능하게” 할 뿐이고, “정보를 노출”시키지는 않습니다.
정보 노출은 서버가 중간값/입력값을 평문으로 관측할 때 발생하는데, 여기선 그 관측이 차단됩니다.
그럼 서버가 “무엇을 유추할 수 있는가?” (현실적인 누출면)
이 논문 위협모델/구현에서 남을 수 있는 누출은 보통 다음 계열입니다.
- 메타데이터 누출
- 시퀀스 길이(고정 길이로 패딩하면 완화), 요청 횟수, 처리량 등
- 사이드채널
- (구현에 따라) 시간, 메모리, GPU 스케줄링 차이로 인한 미세 누출
- 다만 HE는 보통 “암호문 값에 따라 분기”가 거의 불가능해서, 데이터 의존 분기는 제한적입니다. 그래도 시스템 레벨 사이드채널은 별도 이슈입니다.
- 악성 서버(semihonest가 아니라 malicious) 가정이면
- 서버가 프로토콜을 어기고 “출력에 신호를 심어서” 클라이언트의 후속 행동을 유도하는 류의 공격을 고민해야 합니다.
- 하지만 이 논문은 semi-honest라 그 범위를 벗어납니다.
“생성 토큰”은 더 까다로운 이유 (중요)
이 논문은 실험이 주로 분류형(GLUE) 이고, 서버가 샘플링(top-k, argmax, temperature) 같은 비다항/비교 연산을 해야 하는 decoder-only 생성은 별도 난제가 됩니다.
- 만약 생성까지 HE로 끝까지 하려면:
- 샘플링을 서버가 하려는 순간 비교/정렬이 필요 → HE 단독으론 매우 어렵고 MPC/인터랙티브가 섞이거나,
- 또는 서버가 logits(또는 일부 정보)을 평문으로 보게 되는 설계가 섞이면 누출 위험이 커집니다.
- 반대로, 매 스텝 logits를 암호문으로 클라이언트에 보내고 클라이언트가 복호/샘플링하면 프라이버시는 강해지지만,
- 통신/지연이 늘고
- 서버가 “몇 스텝 생성했는지(early stop 포함)” 같은 메타정보는 알 수 있습니다.
정리
- 이 논문 설정에서는 서버가 초반/후반 layer로 입력 토큰을 유추하는 게 원리적으로 어렵다
(서버가 보는 건 전부 암호문 hidden state라서 “유추에 필요한 관측값”이 없다) - 다만, 남는 이슈는 (i) 메타데이터, (ii) 시스템 사이드채널, (iii) malicious 서버 모델, (iv) 생성(decoding) 단계의 샘플링입니다.
원하시면, 당신이 관심 갖는 방향(“생성 텍스트를 서버/네트워크에 남기지 않기”)에 맞춰서
decoder-only 생성에서 안전하게 샘플링까지 처리하는 설계 옵션 3가지(HE-only / HE+MPC / HE+TEE) 를 장단점과 함께 바로 정리해드리겠습니다.
좋습니다. HE를 “암호문으로 본다”는 말을 수학/암호 배경 없이 직관적으로 설명하겠습니다.
1) “암호로 본다” = 서버가 보는 값은 의미 없는 숫자 덩어리라는 뜻
사용자가 보내는 건 “토큰 번호(예: 15243)” 자체가 아닙니다.
HE(특히 CKKS)에서는 보통 토큰을 먼저 임베딩 벡터로 바꾼 뒤, 그 실수 벡터를 암호화해서 보냅니다.
- 평문 세계:
- 토큰 → 임베딩 벡터 (x \in \mathbb{R}^{768})
- HE 세계:
- (x) 를 암호화해서 ciphertext(암호문) = ct(x) 로 보냄
서버가 받는 건
- “15243” 같은 토큰 ID가 아니라,
- ct(x) 라는 “자물쇠로 잠긴 상자”입니다.
서버는 그 상자를 들고 있을 뿐,
- 상자 안에 뭐가 들어있는지(임베딩 값이 무엇인지) 열어볼 수 없습니다.
2) 그런데 서버가 계산은 어떻게 해? (핵심 직관)
HE는 특이하게도 상자를 열지 않고도 상자끼리 계산을 할 수 있습니다.
비유로 아주 정확하게 말하면:
서버는 “잠긴 계산기”를 돌릴 수 있다.
숫자는 잠겨있지만, 더하기/곱하기 버튼은 눌러서 결과도 잠긴 채로 얻는다.
예시(정확한 개념):
- 사용자가 (x) 를 암호화해 ct(x)로 보냄
- 서버가 ct(x)에다 평문 가중치 (W) 를 적용해 선형층을 계산:
- 평문이면: (y = xW)
- HE면: 서버는 ct(y) = Eval(ct(x), W) 를 계산
- 결과도 ct(y) 라는 잠긴 상자 형태로 나옴
- 이걸 클라이언트가 받아서 비밀키로 열면 (y) 를 얻음
즉 서버는
- “계산은 했는데”
- “결과가 뭔지는 모르는 상태”로만 존재합니다.
3) “토큰 번호를 암호화해서 보내는 거 아니야?”에 대한 정리
엄밀히는 이렇게 합니다.
(A) 토큰 ID를 그대로 암호화하면 곤란
토큰 ID는 정수 1개인데, LLM 연산은 거대한 실수 벡터 연산이죠.
그래서 보통은:
(B) 클라이언트가 임베딩(lookup)을 먼저 수행
- 토큰 ID → 임베딩 벡터 (x) 를 만든 뒤
- (x) 를 암호화해서 서버로 보냄
그래서 서버는 토큰 ID를 볼 기회 자체가 없고,
임베딩 벡터도 암호문이라 못 봅니다.
(논문에서도 “token embedding layer는 암호화하지 않고 업데이트하지 않는다”는 식으로 구성합니다. 즉 embedding은 고정이며, 사용자 데이터 보호는 embedding 이후부터 HE로 감싸는 구조입니다.)
4) “해석 못한다”는 게 정확히 무슨 의미?
서버 입장에서 ciphertext(ct)는 이런 상태입니다:
- 겉보기엔 “숫자”가 들어있긴 한데
- 그 숫자들은 암호학적으로 섞여 있어서
- 비밀키 없이는 원래 값(임베딩/hidden state/logit)을 알아내는 게 거의 불가능
여기서 “거의 불가능”은
- “시간이 좀 걸리면 가능”이 아니라
- 현재 컴퓨팅 자원으로는 현실적으로 불가능(암호 가정 하에서)이라는 뜻입니다.
5) 한 단계 더 쉬운 비유 (가장 직관적인 그림)
🔒 자물쇠 상자 비유
- 평문 값 (x) = 상자 안의 내용물
- 암호문 ct(x) = 잠긴 상자
- 비밀키 = 상자 열쇠(클라이언트만 가짐)
서버는:
- 상자끼리 더하기/곱하기는 할 수 있음 (특수한 공구가 있음)
- 하지만 상자를 열 수는 없음
그래서 서버는:
- 입력이 뭔지 모른 채로
- 모델 연산을 진행하고
- 출력도 “잠긴 상자”로 돌려줌
클라이언트만:
- 출력 상자를 열어서 결과를 읽음
6) 그래서 “원본 모델이 평문이면 유추 가능?”이 왜 아니냐
유추 공격이 되려면 서버가 중간 표현을 평문으로 관측해야 합니다.
그런데 HE에서는
- 중간 hidden state도 전부 ct(hidden) 형태의 잠긴 상자라서
- 서버는 “레이어 출력이 어떤 값인지”를 관측할 수 없습니다.
따라서
- 초반 layer hidden으로 입력 복원
- 후반 layer hidden으로 생성 토큰 유추
같은 공격이 관측값이 없어서 성립하기 어렵습니다.
마지막으로, 정말 중요한 한 줄 요약
HE에서 서버는 데이터를 ‘보지’ 못하고,
대신 보지 못하는 상태로 계산만 한다.
원하시면 제가 이해 확인용으로 아주 간단한 장난감 예시를 들어서
“암호문 상태로 덧셈/곱셈을 하면 결과도 암호문으로 나온다”를
숫자 2~3개로 직관적으로 시뮬레이션(개념 예시)해드릴까요?
핵심 혼동이 “ct(x)가 (1×100)처럼 보이면, 그 숫자들로 x를 역추정할 수 있지 않나?” 인데, HE(특히 CKKS)에서 ciphertext는 ‘x를 살짝 섞은 벡터’가 아닙니다. 개념적으로만 “x를 담고 있다”고 말할 뿐, **서버가 보는 ct(x) 자체는 암호학적으로 ‘거의 랜덤한 큰 수 덩어리’**라서 x를 복원하는 게 계산적으로 불가능하다고 보는 게 정확합니다.
아래를 단계적으로 보면 감이 잡힙니다.
1) “차원(1×100)”은 표현 방식일 뿐, 서버가 보는 데이터 구조가 x와 같지 않습니다
- 평문에서는 (x \in \mathbb{R}^{100}) 같은 벡터가 “100개의 실수”죠.
- CKKS에서는 이 100개 실수를 ciphertext의 슬롯(slot) 에 “포장(packing)”합니다.
- 하지만 ciphertext 자체는 보통 (큰 다항식 2개 이상) 같은 형태(매우 큰 정수 계수들)로 저장됩니다.
즉, ct(x)의 물리적 크기/구조는 x(1×100)와 전혀 다릅니다.
논문 구현도 “ciphertext 하나에 2^15개 정도 값을 SIMD로 담는다”는 식의 packing을 쓰고(예: 128×256을 한 ciphertext에 pack), HE 연산(Add/Mult/Rot) 위에서만 의미가 있습니다.
정리: “ct(x)가 1×100처럼 생겼다”는 건 보통 우리가 그렇게 해석해서 넣어둔 것이지, 서버가 보는 원시 데이터가 x와 동형인 벡터라는 뜻이 아닙니다.
2) 서버가 ct(x)로 x를 못 맞추는 1차 이유: 확률적(랜덤) 암호화
HE 암호화는 일반적으로 같은 x를 두 번 암호화해도 매번 다른 ct(x) 가 나옵니다(랜덤이 들어감).
- 만약 서버가 ct(x)를 보고 x를 유추할 수 있다면,
- 동일 x에 대해 여러 개 ciphertext를 봤을 때 “같은 x”임을 식별하거나
- 딕셔너리 매칭 같은 게 가능해야 하는데,
- 확률적 암호화에서는 ct만 보고 동일성/값을 판별하기가 어렵게 설계됩니다.
이게 바로 논문이 말하는 “서버는 CKKS의 semantic security(의미적 보안성)에 의존한다”는 문장의 직관적 의미입니다.
3) 서버가 ct(x)로 x를 못 맞추는 2차 이유: 비밀키가 없으면 ‘복호 방정식’이 성립하지 않음
CKKS/RLWE 계열 암호를 아주 단순화하면 ciphertext는 대충 이런 관계를 가집니다(직관용):
- ct는 (a, b) 같은 형태이고
- (b \approx a\cdot s + \text{noise} + \text{encode}(x))
여기서 서버는
- a, b는 보지만
- 비밀키 s를 모릅니다
- noise도 섞여 있습니다
즉 서버 입장에서는
“모르는 s와 noise가 섞인 거대한 식”만 주어진 상태라서, 그걸 풀어 x를 얻는 문제는 RLWE 가정 하에서 계산적으로 매우 어렵다고 봅니다.
4) “그럼 서버가 모델 가중치 W(평문)를 아니까, Eval 결과로 역추정 가능?”에 대해
서버는 다음을 할 수 있습니다:
- 입력: ct(x)
- 계산: ct(y) = Eval(W, ct(x)) (여기서 W는 평문)
- 출력: ct(y)
하지만 여기서도 서버는 ct(y)만 얻습니다. y(평문)를 못 보죠.
만약 서버가 ct(x)와 평문 W만으로 x를 알아낼 수 있다면,
그건 “암호문을 보고 평문을 복원”하는 능력이 있다는 뜻이고, 곧 CKKS 보안을 깨는 것과 동일합니다. 논문이 전제하는 위협 모델에서는 그게 불가능하다고 가정합니다.
5) 현실적으로 남는 “누출”은 무엇이냐? (중요한 현실 체크)
HE가 “ct로부터 x 복원”을 막아주는 건 맞지만, 시스템 차원에서 다음은 별개 이슈입니다.
- 메타데이터 누출: 길이, 요청 패턴, 타이밍 등
- 사이드채널: 구현/하드웨어/스케줄링 기반 누출
- 생성(decoding) 단계: 샘플링/argmax는 HE 단독으로 까다로워서 설계에 따라 정보 노출면이 달라질 수 있음
하지만 질문하신 **“ct(x) 자체로 x를 유추”**는, 올바른 파라미터/구현 + 비밀키 비공개 + semantic security 가정 하에서는 실질적으로 어렵다가 핵심입니다.
한 문장로 결론
ct(x)는 x를 ‘같은 차원으로 가린 값’이 아니라, 비밀키 없이는 해석할 수 없는 암호학적 객체라서 서버가 ct(x)만으로 x를 유추하는 건(가정 하에서) 불가능에 가깝습니다.
원하시면, “토큰 ID를 직접 암호화하면 왜 위험/비효율인지”와 “왜 보통 임베딩 이후를 암호화하는지”를 **1분짜리 예시(아주 작은 벡터/연산)**로 더 직관적으로 보여드릴게요.
큰 틀에서는 맞습니다. 이 논문(HE/CKKS) 설정에서는 서버가 끝까지 “암호문 상태로만” 연산하고, 평문으로 푸는(복호) 건 클라이언트(사용자)만 합니다.
다만 “그게 끝이냐?”에 대해선 태스크가 분류/회귀인지, 생성(decoding)인지에 따라 실무 흐름이 달라집니다.
아래에 가장 현실적인 형태로 정리해드릴게요.
1) 분류/회귀(논문이 실험한 GLUE 같은 경우)면 거의 “그게 끝”에 가깝다
전체 파이프라인 (클라이언트/서버 역할)
- 클라이언트
- 텍스트 → 토크나이즈
- 토큰 ID → 임베딩 벡터로 변환(embedding layer는 고정, 업데이트 안 함)
- 임베딩(및 필요한 입력 텐서들)을 CKKS로 암호화 → ct(input)
- 서버
- 모델 본체(Transformer, FFN, attention 등) 가중치는 평문으로 보유
- ct(input)을 받아서, HE 연산(PCMM/CCMM, 근사 다항식, BTS 등)으로 복호 없이 계산
- 결과도 평문 logits가 아니라 ct(output) 로 생성해서 반환
- 클라이언트
- ct(output) 복호 → output(예: logits, 회귀값)
- 로컬에서 argmax/스코어 계산 후 결과 확인
➡️ 분류/회귀는 한 번 보내고 한 번 받으면 끝인 구조로 설계하기 쉽습니다.
2) “사용자 컴퓨터는 임베딩만 있으면 되냐?” → 거의 맞지만, 실제로는 아래가 추가로 필요합니다
클라이언트에 필요한 것들
- (필수) 임베딩 레이어(가중치) + 토크나이저
- (필수) HE 키 생성/보관
- secret key(복호키): 클라이언트만 보관
- public/evaluation keys(연산용 키들: rotation/relinearization/bootstrapping 관련): 서버에 제공(연산을 가능하게 해주는 키이지, 복호를 가능하게 해주진 않음)
- (실무상 필수) 입력 길이/패킹 규격
- HE는 보통 고정 길이(패딩)와 패킹(slot) 규칙이 필요합니다(논문도 packing/블록 MM을 자세히 다룹니다).
클라이언트에 “GPU가 꼭 필요하냐?”
- 보통 복호/암호화는 CPU로도 가능한 경우가 많지만,
- 설정(파라미터, 길이, 배치)과 라이브러리에 따라 비용이 커질 수 있습니다.
- 논문은 서버 측이 GPU를 사용해 HE 연산을 가속하는 쪽에 초점입니다.
3) 그런데 “생성(Decoder-only)까지” 가면, 그게 끝이 아니다 (중요)
당신이 처음에 관심 가진 “출력 토큰을 숨긴 채 전달”은 보통 생성/디코딩 쪽 이슈인데, 이때는 문제가 생깁니다:
- 생성은 토큰을 하나 뽑고 → 그 토큰을 다시 입력에 붙여서 → 다음 토큰을 뽑는 반복입니다.
- 서버가 복호를 못 하므로, 서버 혼자서는 “이번 스텝에서 어떤 토큰을 선택했는지”를 결정하기 어렵습니다(비교/argmax/샘플링은 HE에 불리).
그래서 생성에서는 보통 둘 중 하나로 갑니다:
- 클라이언트-주도 디코딩
- 서버가 매 스텝 ct(logits) 를 보내고
- 클라이언트가 복호해서 토큰 선택 후 다시 암호화해 다음 스텝 입력으로 전송
→ 프라이버시는 강하지만, 왕복 통신이 많아짐.
- HE + MPC/인터랙티브 프로토콜
- 서버/클라이언트가 일부 상호작용해서 안전하게 샘플링/argmax를 수행
→ 통신/프로토콜 복잡도 증가.
- 서버/클라이언트가 일부 상호작용해서 안전하게 샘플링/argmax를 수행
논문은 주로 BERT-style encoder + 분류(GLUE) 중심이라, 생성 디코딩의 완전한 종단 솔루션이라기보다는 “암호화된 개인화/추론이 가능해진다”에 초점이 있습니다.
4) 한 문장 결론
- 분류/회귀 같은 1-shot 추론이면: 지금 말한 흐름(클라 임베딩+암호화 → 서버 암호문 연산 → 클라 복호)으로 거의 끝입니다.
- 생성(토큰 디코딩)까지 완전히 “텍스트를 서버에 남기지 않기”를 하려면: 디코딩 설계가 추가로 필요합니다(클라 디코딩 또는 HE+MPC).
원하시면, 당신이 원래 찾던 목적(“출력 텍스트가 서버/네트워크에 평문으로 남지 않게”)에 맞춰서
(A) 클라이언트 디코딩 방식 vs (B) HE+MPC 디코딩 방식을 비용/지연/보안면에서 비교 표로 바로 정리해드릴까요?
https://arxiv.org/abs/2510.03662
Operationalizing Data Minimization for Privacy-Preserving LLM Prompting
The rapid deployment of large language models (LLMs) in consumer applications has led to frequent exchanges of personal information. To obtain useful responses, users often share more than necessary, increasing privacy risks via memorization, context-based
arxiv.org
ICLR 2026에 제출했네요
LLM 사용 과정에서 발생하는 과잉 정보 제공 문제를 다룸
사용자가 더 나은 답변을 기대하며 불필요하게 많은 개인 정보를 프롬프트에 포함시키지만 실제로 그 정보가 없어도 동일한 수준의 답변 품질을 유지할 수 있는 경우가 많음
기존에는 개인 정보 탐지 및 마스킹에 집중하고, 얼마나 줄여도 되는가를 정량적으로 정의 및 측정하지 못했음. 또한 LLM-as-a-Judge 기반 접근은 모델 능력에 따라 판단이 흔들림
=> 데이터 최소화를 최적화 문제로 공식화
입력 프롬프트의 민감한 Span 마다 RETAIN < ABSTRACT < REDACT 라는 프라이버시 강도 순서를 갖는 행동 공간을 정의함
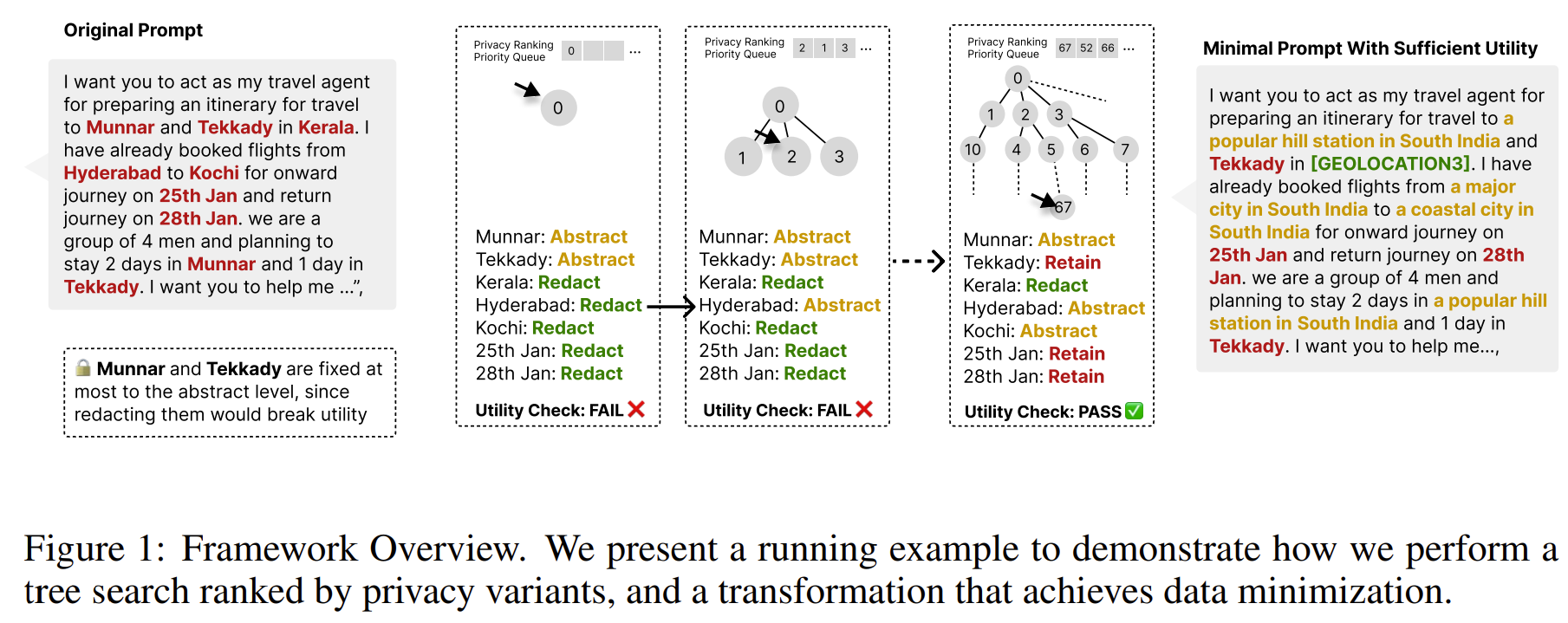
우선순위 큐를 통해 가장 프라이버시 친화적 후보부터 탐색하여 LLM으로 응답을 생성하고, Utility predicate로 성능 유지 여부를 판별한 뒤 처음으로 유틸리티를 만족하는 지점이 데이터 최소화 oracle로 판별한다.
이 오라클은 모델별, 테스크 별로 다르기에 정답이 되는 최소 프롬프트를 실험적으로 계산한다는 점이 핵심이다.
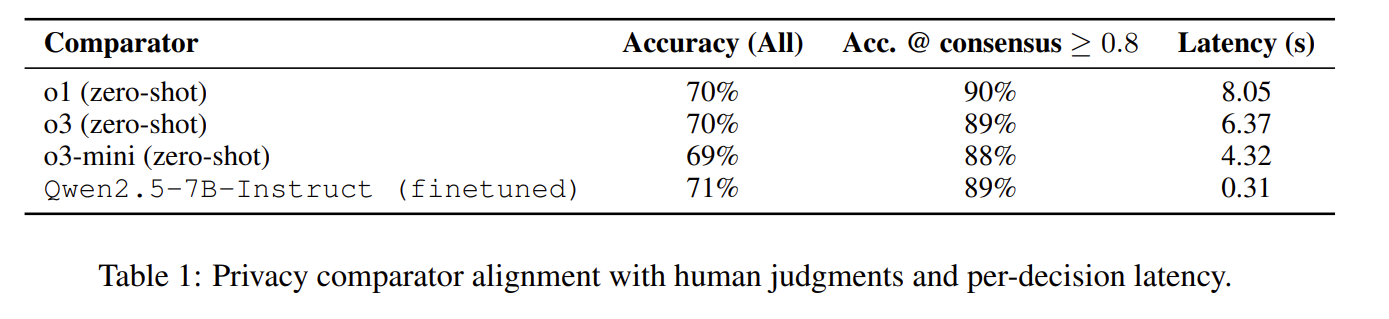
모델이 커질수록 더 강하게 최소화 해도 버텼으며 최신 gpt 모델은 프롬프트 대부분을 REDACT 해도 성능을 유지했다.
=> 모델 능력이 곧 데이터 최소화 여유도
LLM에게 예측하라고 했을 때 필요 없는 정보까지 남기는 경향이 매우 커서 모델이 스스로 무엇이 필요한지 모른다는 능력이 결함되었다.
| 문제 정의 | LLM 사용 시 사용자가 필요 이상으로 개인정보(PII)를 프롬프트에 포함하는 oversharing 문제가 만연함. 기존 연구는 PII 탐지·마스킹에 집중했을 뿐, 유틸리티를 유지하면서 최소한으로 공개해야 할 정보를 정량적으로 정의·계산하지 못함. |
| 핵심 질문 | 주어진 LLM과 태스크에서, 답변 품질을 유지하기 위해 실제로 필요한 최소한의 정보는 무엇인가? |
| 핵심 개념 | Data Minimization을 “유틸리티 제약 하에서 프라이버시 노출을 최소화하는 최적화 문제”로 공식화. |
| 행동 공간 | 각 민감 span에 대해 { RETAIN < ABSTRACT < REDACT } (프라이버시 강도 순서) |
| 방법론 | Privacy 순서로 정렬된 priority-queue 기반 tree search를 통해, 가장 프라이버시 친화적인 프롬프트부터 탐색 → 최초로 유틸리티 조건을 만족하는 지점을 data minimization oracle로 정의 |
| 유틸리티 판별 | Open-ended task: 응답 품질 비교 / Closed-ended task: 정답 정확도 유지 여부 |
| 평가 데이터셋 | Open-ended: ShareGPT, WildChat Closed-ended: MedQA, CaseHOLD |
| 평가 모델 | GPT-5, GPT-4.1, Claude, Exaone, Mistral, Qwen 등 총 9개 LLM |
| 주요 실험 결과 ① | Frontier LLM일수록 더 강한 데이터 최소화 가능 → GPT-5: open-ended 기준 85.7% REDACT, Qwen2.5-0.5B: 19.3% REDACT |
| 주요 실험 결과 ② | Closed-ended 태스크에서는 거의 모든 PII 제거 가능 (GPT-4.1: 98% REDACT) |
| 주요 실험 결과 ③ | LLM 단독 예측은 oracle 대비 Overshare가 지배적이며, 특히 ABSTRACT 편향이 강함 |
| 공격자 검증 | 별도 공격 LLM을 통한 span/type 복원 실험에서, 제안한 최소화 프롬프트는 복원 가능성 대폭 감소 |
| 핵심 발견 | 이는 단순한 프라이버시 실패가 아니라, LLM이 “무엇이 필요한 정보인지”를 잘 인식하지 못하는 capability gap임 |
| 의의 | 데이터 최소화를 프라이버시 규칙이 아닌 모델·태스크 종속적 최적화 문제로 정식화. 입력 프라이버시 보호 + LLM 해석 관점의 새로운 연구 방향 제시 |
| 한계 및 향후 과제 | 모델별 necessity 인식 차이의 원인 규명 필요, on-device predictor / client-side 최소화 모델로의 확장 필요 |
https://icml.cc/virtual/2025/poster/45418
ICML Poster An Efficient Private GPT Never Autoregressively Decodes
The wide deployment of the generative pre-trained transformer (GPT) has raised privacy concerns for both clients and servers. While cryptographic primitives can be employed for secure GPT inference to protect the privacy of both parties, they introduce con
icml.cc
ICML 2025 Poster 논문이네요
클라이언트 입력과 서버 모델을 동시에 보호하기 위해 HE, MPC 기반 2PC를 사용하지만 디코딩 단계에 매 토큰마다 수백 라운드 통신하고, 비선형 연산으로 인해 지연이 매우 크다.
기존 연구들은 암호 프로토콜을 최적화 하고 Transformer 구조를 수정하여 1-step secure decoding 구조는 유지하였다.
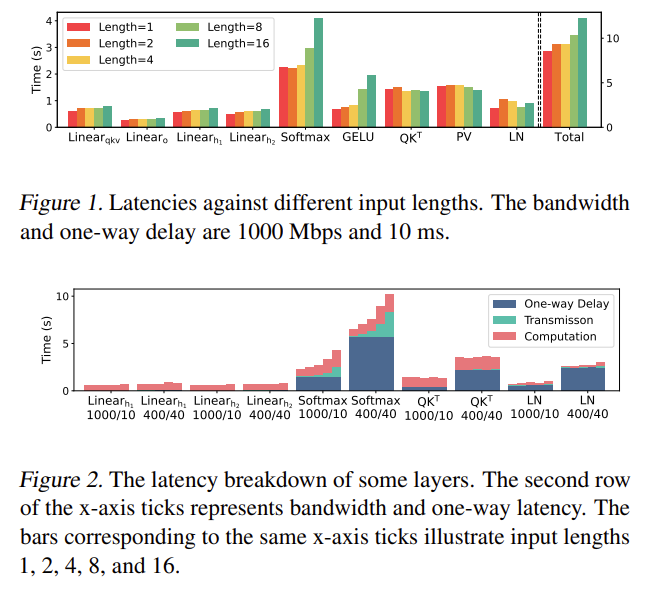
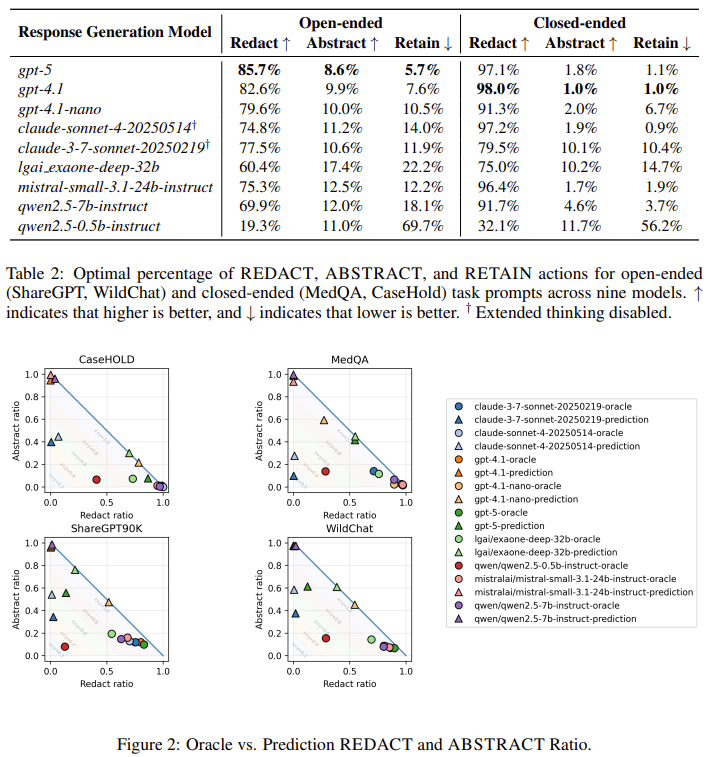
figure 1 실험을 통해 secure decoding의 latency는 입력 토큰 길이에 거의 민감하지 않음을 보여주었다.
토큰 길이가 16배 증가해도 전체 layency는 1.1 ~ 1.5배 수준이었다.
한 토큰이든 여러 토큰이든 secure forward 비용은 거의 같다.
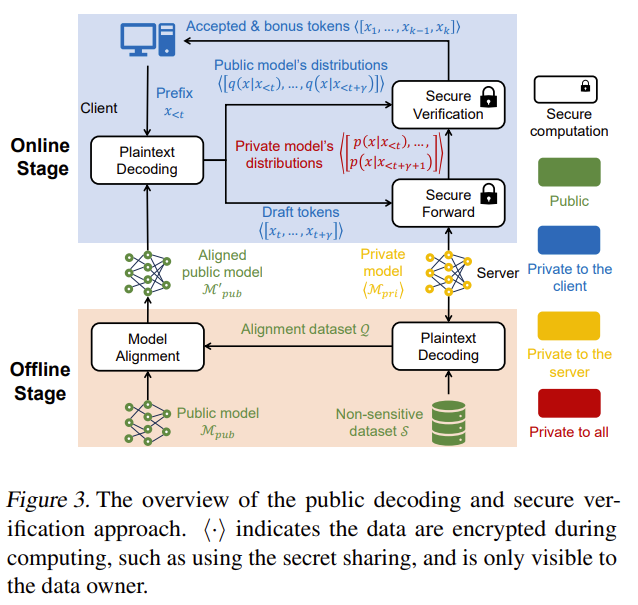
POST = Public decOding and Secure verificaTion
= Autoregressive decoding을 secure 하게 하지 말고, 공개 모델로 미리 여러 토큰을 만들고 private 모델은 한 번에 검증만 하자!
“작은 모델을 큰 모델에 distill해서 aligned public model을 만들고, online 단계에서는 public model이 n개의 draft token을 평문으로 생성한다.
그 후 prefix와 draft를 조건으로 한 n+1 step의 private model 분포를 한 번의 secure forward로 계산하고, secure speculative verification을 통해 앞에서부터 accept된 토큰까지만 채택한다.
reject 이후는 private 분포에서 bonus token을 샘플링하고 다음 step으로 넘어간다.”
근데 distill은 결국 큰 모델 만큼 성능이 나와야 하는 거니까.....

| 연구 문제 | Secure GPT inference에서 autoregressive decoding은 토큰당 1회 secure forward가 필요하여 HE/MPC 기반 추론이 극도로 느림 |
| 핵심 관찰 | Secure decoding의 latency는 입력 토큰 길이에 거의 무관 (1 token ≈ 8~16 tokens) |
| 핵심 아이디어 | 토큰 생성(generate) 과 검증(verify) 를 분리하여, 생성은 public model, 검증만 private model이 secure하게 수행 |
| 제안 방법 | POST (Public decOding and Secure verificaTion) |
| Offline 단계 | Public model을 private model의 output distribution(top-k)에 맞게 knowledge distillation하여 aligned public model 생성 (사용자 입력과 무관) |
| Online 단계 – 1 | Client가 aligned public model로 γ개의 draft tokens를 평문으로 생성 |
| Online 단계 – 2 | Client+Server가 1회 secure forward로 private model의 분포를 암호화 상태로 계산 |
| Online 단계 – 3 | Secure speculative verification: 각 draft token을 secure reject/accept 판단 |
| Reject 처리 | 첫 reject 지점에서 private 분포에서 bonus token 1개 재샘플, 이후 즉시 다음 step으로 이동 |
| 보안 핵심 | Server는 입력을 모르고, Client는 private model 내부 분포를 모름 → 표준 secure inference와 동일한 privacy 보장 |
| 정확도 보장 | Speculative sampling 이론에 의해 private model 단독 decoding과 동일한 output distribution 보장 |
| 암호 최적화 | Division 제거(곱셈 변환), vocab 전체 비교 제거(OT 기반 selection) → secure sampling overhead ~10× 감소 |
| 실험 모델 | Vicuna-7B / FLAN-T5-XL (private) + LLaMA-68M·160M / T5-small·base (public) |
| 실험 환경 | LAN(1Gbps, 10ms), WAN(400Mbps, 40ms), SecretFlow-SPU + BumbleBee/Nimbus |
| Acceptance Ratio | Distillation 후 52% ~ 85% (모델 계열이 같을수록 높음) |
| 성능 향상 | End-to-end secure decoding 2.1× ~ 6.0× speedup |
| 기존 연구 대비 차별점 | 암호 프로토콜/모델 구조 변경 없이 decoding 구조 자체를 재설계 |
| 확장성 | 더 강한 public model, 서버 제공 aligned model일수록 성능 지속 향상 |
| 한 줄 결론 | Secure GPT의 병목은 암호가 아니라 autoregressive 구조였으며, POST는 이를 구조적으로 제거한 접근 |
별로....
'인공지능 > 논문 리뷰 or 진행' 카테고리의 다른 글
| Privacy AI 관련 조사 10 (0) | 2026.01.26 |
|---|---|
| Privacy AI 관련 조사 9 (1) | 2026.01.20 |
| Privacy AI 관련 조사 7 (0) | 2026.01.19 |
| Multi-turn, Long-context Benchmark 논문 2 (0) | 2026.01.18 |
| Multi-turn, Long-context Benchmark 논문 1 (0) | 2026.01.17 |