https://www.sciencedirect.com/science/article/pii/S0004370225000128
LLM을 블랙박스 API로 호출하는 환경에서 사용자 프롬프트에 포함된 민감정보가 서버에게 노출될 수 있음
이를 줄이기 위해 프롬프트를 랜덤화 하여 보호하는 접근들이 있지만 유용성이 줄어든다!

프라이버시가 유출되는 것을 볼 수 있다.
프롬프트를 보호하면서도 프라이버시 노출도와 유틸리티 손실을 동시에 0으로 만들 수 있는가?
=> 저자는 이론적으로 불가능한 방향이며 정략적 하한 형태로 제시

client가 원 프롬프트를 만들면 보호 화 방법에 따라 서버에 보냄
그럼 응답을 보내줌
서버는 보호된 프롬프트를 원문으로 복구하기 위해 공격을 시도함

랜덤화 보호 메커니즘은 토큰 단위 임베딩을 근접 토큰 치환으로 모델링하여 랜덤하게 더해준 벡터값 근처의 토큰 후보를 정한다.
서버가 보호된 입력을 보고 복원해도 그 성능이 랜덤 추측 수전에 가까워지면 입실론은 0에 가까워짐
| 한줄 결론 | 랜덤화(randomization) 기반 프라이버시 보호 LLM 추론에서는, 프라이버시 누출(εₚ)과 유틸리티 손실(εᵤ)을 동시에 무시할 수준으로 만들 수 없고, 두 값의 가중합이 문제-의존 상수로 하한된다. |
| 문제 정의 | 블랙박스 LLM(API) 사용 시 프롬프트에 포함된 개인/기업 민감정보가 서버(모델 제공자)에게 노출될 수 있음. 이를 막기 위해 프롬프트를 랜덤화해 의존성을 줄이지만, 그 대가로 성능(유틸리티) 저하가 발생. |
| 시스템/역할 | 클라이언트가 원 프롬프트 d를 보호 메커니즘 𝓜으로 변환해 보호 프롬프트 d̃를 서버로 전송, 서버 LLM이 응답 r̃ 생성. 서버는 관찰한 입력(보호된 프롬프트/임베딩)으로 원문 복원을 시도 가능. |
| 위협 모델 | 공격자는 LLM 서버. 목적: 원 프롬프트 토큰/단어를 최대한 복원. 능력: semi-honest(정상 추론은 수행하되, 관찰 정보로 프라이버시 추론). 지식: 클라이언트가 랜덤화 보호를 적용함을 인지하고 가용 정보(호스팅 LLM 등)로 공격 수행. |
| 대표 공격 | (1) Input inference attack: BERT 마스킹 기반 토큰 복원 (2) Embedding inversion: 최근접 이웃으로 원 토큰 추정 (3) LLM-assisted recovery: 원격 LLM 자체에 복원 지시를 내려 복원 시도 |
| 보호 메커니즘(𝓜) 핵심 | 블랙박스 API 환경에서는 암호/SMPC 기반 보호가 부적합하므로, 문헌에서 대표적으로 쓰이는 임베딩 랜덤화(노이즈 주입) + 의미적으로 유사한 토큰 치환을 분석 대상으로 채택. |
| 랜덤화 절차(토큰 단위) | 토큰 d(m) → 임베딩 w(m)=E(d(m)) → 노이즈 δ로 w̃(m)=w(m)+δ → w̃(m) 근접 후보(인접 리스트)에서 토큰 d̃(m) 선택 → 모든 토큰 반복해 d̃ 구성 |
| 프라이버시 누출 정의(εₚ) | 보호 임베딩 분포 P̃와 “입력과 독립인 임베딩 분포” P̆에 대해, εₚ = R(P̃) − R(P̆). 여기서 R(·)은 공격이 복원한 토큰들이 원 토큰과 얼마나 가까운지(반복 공격 포함)를 측정하는 “복원 정도”의 기댓값. P̆는 랜덤 추측 베이스라인 역할. |
| 유틸리티 손실 정의(εᵤ) | 원 분포 P 대비 보호 분포 P̃에서의 기대 유틸리티 감소로 εᵤ = U(P) − U(P̃). U(P)=E_{s~P0}E_{w~P}U(w,s)로 테스트 데이터 분포(P0)에 대한 기대 성능을 정의. |
| 목표(최적화) | 클라이언트 목표: 프라이버시 예산(누출 제약 ξ) 하에서 유틸리티 손실 최소화. 즉, min εᵤ s.t. εₚ ≤ ξ. |
| 이론 도구(TV 거리) | 분포 간 Total Variation(TV) 거리를 통해 (i) 프라이버시 누출(εₚ)과 (ii) 유틸리티 손실(εᵤ)을 각각 하한으로 연결하고, 이를 결합해 NFL을 도출. |
| 핵심 정리(Theorem 4.4) | (C₂/C₁)·εₚ + εᵤ ≥ C₂·TV(P ∥ P̆). 우변 TV(P∥P̆)는 “원 임베딩 분포”와 “입력과 독립인 분포” 사이 거리로, 보호 메커니즘과 무관한 문제-의존 상수로 취급. ⇒ εₚ, εᵤ를 동시에 극소로 만들 수 없음(트레이드오프 필연). |
| 실험 목적 | 제안한 정의(εₚ, εᵤ)로 실제 랜덤화 기반 기법에서 프라이버시–유틸리티 트레이드오프가 관측되는지 검증. |
| 검증 알고리즘 | InferDPT를 기반으로 검증: (1) Perturbation module(DP 기반 노이즈+인접 리스트로 입력 교란) (2) Extraction module(로컬 LLM이 원문+원격 LLM 출력으로 최종 산출) |
| 실험 설정 | 데이터: CNN/DailyMail, 입력 50 tokens로 프롬프트 구성 → 원격 LLM이 100 tokens 생성. 모델: 원격 GPT-3.5-turbo, 로컬 Vicuna-7b-4bit(temperature 0.5, max_tokens 150). 프라이버시 수준 24단계로 분할. |
| εₚ(프라이버시) 측정 구현 | Def.3.1의 토큰 단위 정합을 블랙박스 응답에 직접 적용하기 어려워, 원문 vs 복원문 간 cosine similarity로 복원 정도를 근사. 랜덤 추측(R(P̆))은 어휘에서 랜덤 토큰을 뽑아 구성해 비교. |
| εᵤ(유틸리티) 측정 지표 | BERTScore, BLEU, Keyword Coverage, Semantic Similarity, Diversity, Coherence, ROUGE-1/2/L 등 오픈엔드 생성 지표로 U(P), U(P̃) 산출 후 εᵤ 계산. |
| 결과 요약 | 프라이버시 예산/노이즈 강도에 따라 εₚ와 εᵤ가 반대 방향으로 변화하는 트레이드오프 곡선을 관찰(Fig.4~5). 24개 설정점에서 “누출↑ ↔ 손실↓” 관계를 시각화. |
| 한계/주의점(논문 언급) | (1) 복원 측정에서 “전용 iterative recovery 알고리즘” 대신 원격 LLM에 복원 지시를 주는 방식 사용 → 더 강한 복원 알고리즘이면 누출 측정이 달라질 수 있음을 언급. (2) InferDPT 자체도 로컬 LLM/프롬프트 설계 및 하드웨어 자원 요구 등 제약 존재. |
https://aclanthology.org/2024.privatenlp-1.4/
Protecting Privacy in Classifiers by Token Manipulation
Re’em Harel, Yair Elboher, Yuval Pinter. Proceedings of the Fifth Workshop on Privacy in Natural Language Processing. 2024.
aclanthology.org
프라이버시 워크숍에 나온 논문입니다.
LLM API 서비스는 입력 텍스트 자체가 프라이버시 위험이 됨
기존 프라이버시 보호 기법들은 대부분 embedding 단계에서 노이즈를 추가하여 서버 모델 파라미터 접근을 가정하고, 사용자 단말에 연산 및 메모리 부담을 주고, embedding inversion attack에 취약하다

이렇게 진행되면 연산 과정도 많아서 힘들다!
이 연구는 B 수준에서 진행한다.

단순 토큰 매핑은 공격자에게 조금 귀찮을 뿐 복원 가능함
주변 토큰을 가중합하여 가장 가까운 새로운 토큰을 고르며, 원래 토큰은 나오지 않도록 강제함
단순 노이즈 방식은 성능 유지할 수 있겠지만 nearest-neighbor 공격에 극도로 취약하지만 위 방식은 성능 소폭 감소에 복원 난이도가 급격히 증가함
| 문제 정의 | LLM을 원격 서비스로 사용할 때 입력 텍스트가 서버·중간자에게 그대로 노출되어 프라이버시 침해 위험 발생 |
| 기존 접근 한계 | (1) embedding/encoder 단계 노이즈 방식은 서버 파라미터 접근 가정 필요 (2) 사용자 단말 계산 비용 큼 (3) embedding inversion 공격에 취약 |
| 핵심 아이디어 | 모델 내부를 건드리지 않고, 토큰 시퀀스 자체를 조작(token-level privatization) 하여 원문 복원을 어렵게 만들면서 분류 성능 유지 |
| 프라이버시 적용 지점 | Token Privatization (Tokenizer 이후, Embedding 이전 단계) |
| 방법 1: Lossy Token Mapping (Baseline) | vocabulary를 2~3개 토큰 묶음으로 나누어 many-to-one 치환 (랜덤 / 고빈도 / 저빈도 기준) |
| Baseline 결과 | 구현은 단순하나 분류 성능 저하 발생, LLM 기반 확률적 복원 공격에 쉽게 역추적 가능 |
| 방법 2: STENCIL | 주변 문맥(window) 토큰 임베딩을 가중합해 quasi-embedding 생성 후, 가장 가까운 다른 토큰으로 치환 |
| STENCIL 핵심 특징 | (1) 문맥 정보 유지 (2) 원 토큰 직접 노출 차단 (3) 모델 파라미터 접근 불필요 |
| STENCILp 변형 | 중심 토큰 가중치 제거 → 성능 일부 감소 대신 토큰 복원 공격 완전 차단 |
| 실험 데이터셋 | SST-2, IMDb (분류), QNLI (encoder–decoder 기반 분류) |
| 성능 결과 | STENCIL은 noise-based embedding perturbation 대비 성능–프라이버시 균형 우수 |
| 복원 공격 평가 | Baseline 및 Noise 방식은 nearest-neighbor / LLM 공격에 취약 STENCIL은 복원 성공률 크게 감소 |
| 핵심 결론 | 단순 토큰 치환은 불충분하며, 문맥 인지적 토큰 조작이 현실적인 프라이버시 보호 해법 |
| 의의 | 입력 텍스트 보호를 토큰 수준에서 달성 가능한 방향 제시 |
| 한계 및 향후 과제 | (1) 문장 길이 정보는 그대로 노출 (2) 분류 태스크·영어 한정 실험 (3) 생성 모델·다국어 확장 필요 |
https://arxiv.org/abs/2510.05699
Membership Inference Attacks on Tokenizers of Large Language Models
Membership inference attacks (MIAs) are widely used to assess the privacy risks associated with machine learning models. However, when these attacks are applied to pre-trained large language models (LLMs), they encounter significant challenges, including m
arxiv.org
기존 MIA는 LLM의 출력을 공격으로 사용하지만 실제 상용 llm을 scratch부터 재학습하기 어렵고, 평가 모델과 실 모델의 크기 불일치, 학습 데이터의 차이가 있다.
LLM말고 더 단순하고 재현 가능한 구성요소를 공격 벡터로 삼을 수 없나?

데이터도, 학습도 다 다르다!
토크나이저를 공격 벡터로 써서 진행해보자
토크나이저는 LLM 사전학습 데이터와 동일한 데이터 분포로 학습되고, BPE 기반은 학습 과정이 단순하고 재현 가능 함

노크나이저는 특정 데이터셋에만 등장하는 희귀한 토큰이 vocab에 직접 포함되기에 이 토큰들의 존재 여부와, merge 순서, 빈도 특성이 특정 데이터 셋이 해당되었는지를 파악할 수 있게 해줌
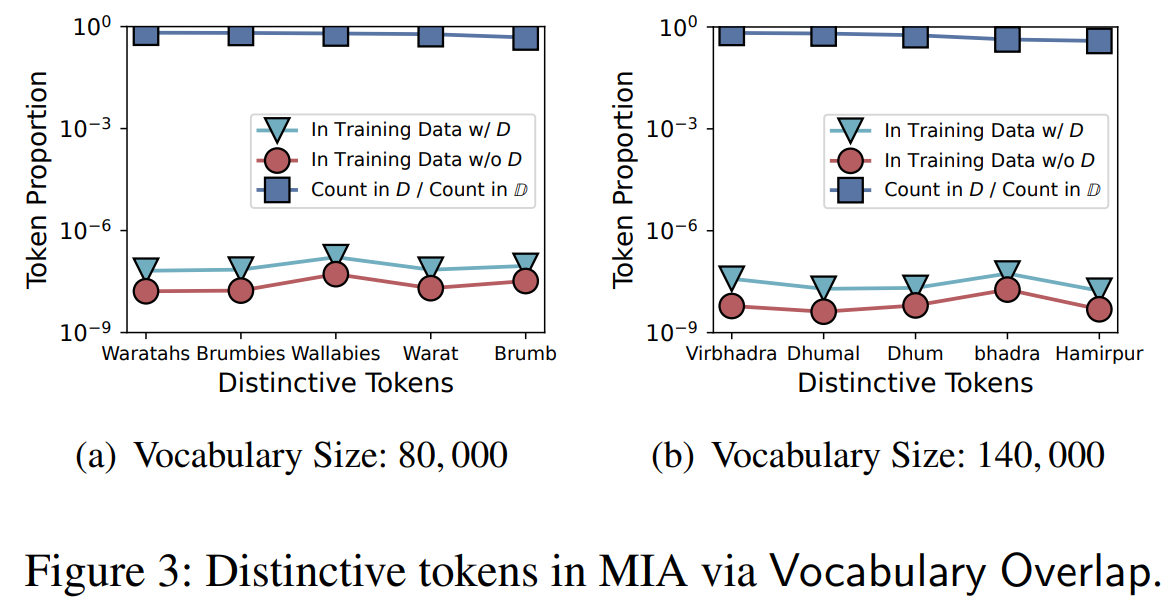
특정 데이터 셋 포함, 미포함시 vocabulary차이를 비교해서 특이 토큰 집합을 멤버쉽 시그널로 확인할 수 있음
| 연구 배경 | 기존 LLM 대상 Membership Inference Attack(MIA)은 모델 재학습 불가, 모델 크기 불일치, 데이터 접근 제약으로 현실적·정량적 평가가 어려움 |
| 핵심 문제의식 | LLM 본체가 아닌, 더 단순하고 재현 가능한 구성요소에서도 학습 데이터 멤버십 누출이 발생하는가? |
| 주요 아이디어 | Tokenizer를 새로운 MIA 공격 대상으로 설정. Tokenizer는 LLM과 동일한 데이터 분포로 학습되며, 공개·재현 가능 |
| 공격 대상 | BPE 기반 Tokenizer의 Vocabulary 및 merge 구조 |
| 핵심 관찰 | Tokenizer는 특정 데이터셋에만 등장하는 distinctive token을 vocabulary에 직접 보존 → 학습 데이터의 fingerprint 역할 |
| 제안 공격 1 | Vocabulary Overlap MIA: target dataset 포함/미포함 shadow tokenizer 간 vocabulary 겹침 정도로 membership 추론 |
| 제안 공격 2 | Frequency Estimation MIA (RTF-SI): token merge 순서 ↔ 빈도 분포(power-law)를 이용한 효율적 추론 |
| 공격 성능 | Vocabulary 200k 기준 AUC ≈ 0.74~0.77, 대규모 데이터셋에서는 AUC 0.88+ |
| 핵심 실험 결과 | (1) Vocabulary가 클수록 MIA 성능 ↑ (2) 데이터셋 규모가 클수록 공격 성공률 ↑ |
| 중요한 발견 | Tokenizer 품질(압축 효율) 향상 = 프라이버시 위험 증가라는 새로운 trade-off 규명 |
| 방어 기법 실험 | Min-count filtering, DP-BPE 적용 → MIA 성능 감소 가능하나 Tokenizer 효율 손실 불가피 |
| 핵심 결론 | 프라이버시 누출은 LLM 이전 단계(Tokenizer)에서 이미 발생하며, Tokenizer는 중립적 전처리 도구가 아님 |
| 연구적 의의 | LLM 프라이버시 위협 모델을 Tokenizer 수준까지 확장한 최초의 체계적 분석 |
| 실무적 시사점 | Tokenizer 공개 자체가 데이터 소유권·프라이버시 분쟁의 직접적 공격 벡터가 될 수 있음 |
'인공지능 > 논문 리뷰 or 진행' 카테고리의 다른 글
| ALIENLM: ALIENIZATION OF LANGUAGE FORPRIVACY-PRESERVING API INTERACTION WITHLLMS (0) | 2026.01.28 |
|---|---|
| Privacy AI 관련 조사 11 (0) | 2026.01.27 |
| Privacy AI 관련 조사 9 (1) | 2026.01.20 |
| Privacy AI 관련 조사 8 (1) | 2026.01.20 |
| Privacy AI 관련 조사 7 (0) | 2026.01.19 |