https://kimjaehee0725.github.io/publications/
Publications
Selected publications and manuscripts in natural language processing and trustworthy AI.
kimjaehee0725.github.io
리뷰 받는 중 인 것 같은데 여기서 찾았습니다
기존 Inference 방법론들은 API환경에서 제한적이거나 성능 감소가 매우 컸음
토큰 수준에서 치환을 통해 fine-tuning을 진행하고 이를 통해 성능 평가를 했을 때 80%의 성능을 유지함을 보여줌
의료, 금융, 교육과 같은 API 응용 환경에서 민감한 데이터를 보호할 수 있음

토큰 암호화를 통해 사람이 읽을 수 없는 언어로 학습을 진행한다.
API 사용이 가능하고, 인간은 읽을 수 없으며 LLM은 학습할 수 있도록 진행해야 한다.
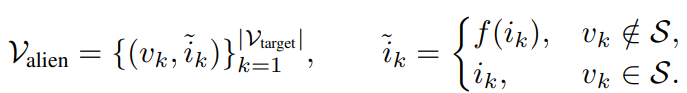
토큰 문자열을 v라고 하고 그에 대응하는 ID를 i라고 할 때 치환해서 안되는 특수 토큰 집합(pad나 eos와 같은 토큰)을 제외하고 변환한다. 전단사 함수 f:I→I를 도입하고 alien 어휘를 정의함

τ(x;V)이를 통해서 텍스트 x를 토큰 ID로 매핑하고, ID를 텍스트로 돌리는 τ^-1(i;V)가 존재
f를 통해 alien 어휘로 맞춰줌
이를 통해 토크나이저 위에 클라이언트 번역을 정의

ρ∈[0, 1]는 암호화 비율을 제어함
D_ρ(E_ρ(x))=x 이게 항상 성립함
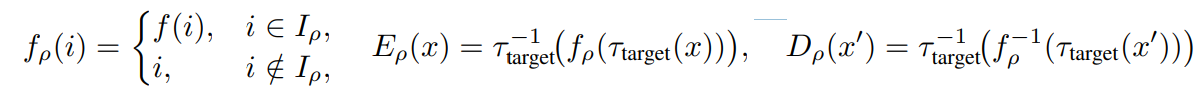
이제 ρ가 주어지면 암호화 비율에 따라 토큰이 뒤섞이게 됨
ρ가 증가할 수록 글을 알아볼 수 없게 되지만 성능 저하도 심해짐
사람에게는 읽기 어렵지만 모델에게는 학습 가능하게 하려면 embedding space에서의 거리가 중요하다.

이렇게 거리를 정의한다.

활성 도메인에 대해 거리가 설정한 파라미터를 넘지 않도록 진행한다.

유사도 제약을 λ≥0로 완화하면 위와 같은 식을 얻고, μ가 크면 llm 학습 가능성을, 작으면 인간 불투명성을 더 중시한다.
API 모델에서는 embedding에 접근할 수 없어 오픈 소스 llm 임베딩에서 근사하여 대체한다.
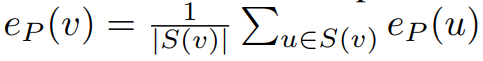
vocab이 다를 수 있으니 평균 임베딩을 사용함....
또한 10^5에서 전단사를 정확히 푸는 것은 비실현적으로 k-NN 기반 후보 축소를 사용하는 greedy search를 적용

그래서 현실적인 e_P를 활용함
그 후 텍스트 예제만을 사용해 Encryption Adaptation Training인 EAT를 진행하여 얼라인 시킴
학습 함수는 동일함
추론은 평문 x를 E를 통해 x'로 바꿔 API에 전송하고, 서버는 이를 출력하여 y'를 만들고, 클라이언트는 이를 받아서 다시 복호화 해 y를 만든다.
이를 통해 민감 데이터가 학습 및 추론 과정에서 보호됨
1 대 1 교환인 점이 조금 아쉬운데...
k-nn에 1대1 교환이면 embedding space에서 top - 100 정도로 잡고, 쫙 통계 내면 잡을 수 있지 않나 싶기도 하고...
학습은 이 데이터로 진행하였습니다.
https://huggingface.co/datasets/Magpie-Align/Magpie-Pro-300K-Filtered
Magpie-Align/Magpie-Pro-300K-Filtered · Datasets at Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
https://huggingface.co/datasets/Magpie-Align/Magpie-Reasoning-V1-150K
Magpie-Align/Magpie-Reasoning-V1-150K · Datasets at Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
baseline으로 기본 모델과, Substitution은 EAT 없이 추론만 진행한 것, SentinelLM은 임베딩을 수정하고 암호화된 데이터로 파인튜닝해 모델을 암호화된 입력에 적응시키는 법이다.
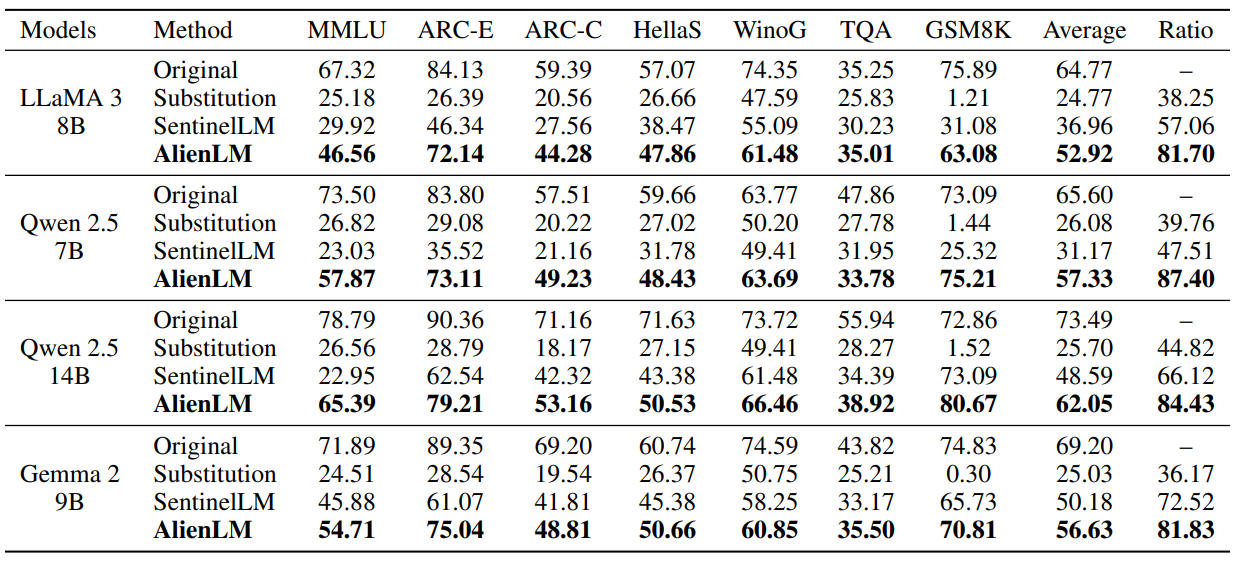
AlienLM의 성능이 높게 나타났다.
백본 전반에서 80%의 성능을 유지하는 반면 다른 방법은 성능이 많이 떨어짐
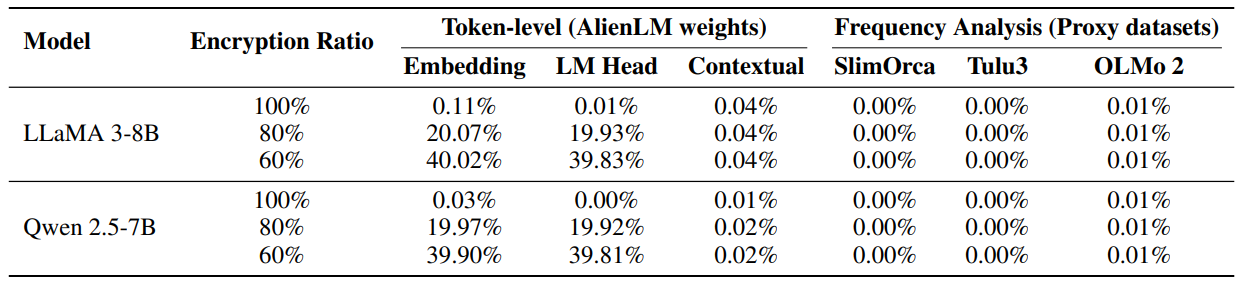
top-1만을 봐서 그런건지 0.11% 로 보호 성능이 뛰어납니다.
암호화 비율에 따라 딱 적절하게 확률을 보여주는 것을 볼 수 있다.
토큰 매핑 공격
LLM 서버 제공자나 내부 접근자가 공격자로 모델 가중치에 접근은 가능하지만 사용자 키(f)는 모르고 평문 - 암호문 쌍도 모른다
=> 원래 무슨 토큰인지 확인하기
단순 토큰 하나를 고른뒤 embedding matrix에서, 출력 로짓 이전의 hiddenstate, context 상에서의 hiddenstate를 확인 함
그래서 가장 가까운 top-1 토큰을 선택함 (이게 좀 아쉽네요 )
공격 빈도 분석
공격자는 외부 공격자로 alien 텍스트만 보고 맞춰야 한다.
text를 통해 공개 코퍼스에서 통계를 수집하고 alien에서 가장 자주 나오는 토큰이 일반 코퍼스에서 가장 자주 나오는 토큰이라고 하여 치환 테이블을 만들려고 했으나 실패함
고정적 빈도 분석으로 알파벳 다누이가 아닌 서브월드 단위이기 때문에...
그리고 도메인 불일치도 있기에 불가능함

암호화 비율이 증가할 수록 성능도 떨어지는 것을 볼 수 있다.

수학과 코딩에 맞춘 도메인 특화 EAT를 진행하였다
기존 300K 학습 데이터에 도메인 특화 데이터를 150k 추가하여 진행함
코드나 수학 데이터가 없으면 박살나는 것을 볼 수 있음 - 수가 엄청 섞이는데 그에 대한 적응을 못하면 어쩔 수 없는 것일지도...

서로 다른 랜덤 시드를 통해 실험을 진행한 결과 성능이 적절히 유지되는 것을 볼 수 있다.
random으로 섞으면 성능은 엄청 떨어지는 것을 봐 embedding 공간에 대한 고려는 필요함


| 문제 정의 | 상용 LLM의 black-box API 환경에서 프롬프트·출력·fine-tuning 데이터가 서버에 평문으로 노출됨. 기존 HE/MPC/TEE는 white-box·고비용, DP/FL은 추론 단계 보호 불충분 |
| 핵심 아이디어 | 암호화를 언어 변환(language translation)으로 재해석. 토큰 수준 전단사 치환으로 사람이 읽을 수 없는 Alien Language를 만들고, 모델을 그 언어에 API-only로 적응 학습 |
| 핵심 구성요소 | (1) Vocabulary-level bijection (token ID 전단사 치환) (2) Client-side Translator (암·복호화) (3) EAT (Encryption Adaptation Training): 암호화된 텍스트만으로 API fine-tuning |
| 수식적 정의 | 암호화 E_ρ(x)=τ^{−1}(f_ρ(τ(x))), 복호화 D_ρ(E_ρ(x))=x ρ\rho: 암호화 비율(privacy–utility trade-off) |
| Bijection 설계 원리 | 목적함수로 human opacity (edit distance ↑) + LLM learnability (embedding similarity ↑) 동시 최적화. Black-box 제약으로 proxy embedding 사용 |
| 알고리즘 | 대규모 vocab(≈10⁵) 대응을 위해 k-NN 후보 축소 + greedy pairing 근사 해법 (실행시간 ≤20분) |
| 위협 모델 | Weight-private, black-box API. 서버·외부 공격자는 alien text만 관측, 토큰 매핑·빈도 분석 시도 가능 |
| 실험 모델 | LLaMA-3 8B, Qwen-2.5 (7B/14B), Gemma-2 9B |
| 벤치마크 | MMLU, ARC-Easy/Challenge, HellaSwag, WinoGrande, TruthfulQA, GSM8K (총 7개) |
| 비교 방법 | Substitution(치환만), SentinelLM 변형, AlienLM (치환+EAT) |
| 주요 성능 결과 | 원래 성능의 81~87% 유지(평균). Substitution/기존 방법 대비 큰 폭 우수 |
| 보안 결과 | 토큰 매핑 복구 공격 성공률 <0.1%, 빈도 분석 <0.01% |
| 추가 실험 | (1) ρ 조절로 privacy–utility 제어 (2) Domain-specific EAT로 code/math 성능 향상 (3) Seed 다양화로 키 분산(overlap <2%) |
| 핵심 인사이트 | LLM의 과제 수행 능력은 언어 표면과 분리 가능. 모델은 “외계어”도 학습 가능 |
| 실용적 의의 | ❌ white-box 불필요 ❌ 특수 HW 불필요 ✅ 기존 상용 API 그대로 사용 가능한 배포형 프라이버시 레이어 |
| 한계 | bijection 최적화는 근사적, 전역 ρ 사용. Span/content-level 암호화, 더 강한 이론 분석은 미해결 |
| 향후 과제 | adaptive adversary 하 learnability–opacity 이론화, span-level ρ 스케줄링, DP/FL/TEE와 결합 |
| 한 줄 요약 | “암호화를 언어로 만들어, API LLM이 스스로 배워 쓰게 한다.” |
'인공지능 > 논문 리뷰 or 진행' 카테고리의 다른 글
| Privacy AI 관련 조사 12 (0) | 2026.02.02 |
|---|---|
| Multi-turn, Long-context Benchmark 논문 3 (0) | 2026.01.31 |
| Privacy AI 관련 조사 11 (0) | 2026.01.27 |
| Privacy AI 관련 조사 10 (0) | 2026.01.26 |
| Privacy AI 관련 조사 9 (1) | 2026.01.20 |