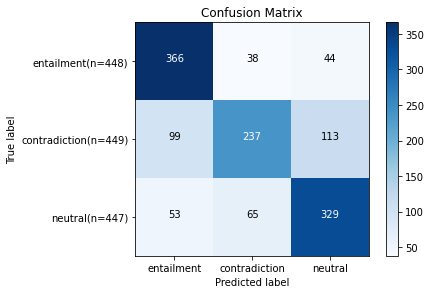
Introduction Chapter 7. 자연어 이해(NLU) Task 강의의 한국어 관계 추출 Task 실습 강의입니다. 이번 실습에서는 (1) KLUE-BERT base 모델을 KLUE 벤치마크 데이터셋의 KLUE-RE 데이터셋으로 파인튜닝하고, (2) 파인튜닝한 모델의 관계 추출 작업에 대한 성능과 결과를 분석해보겠습니다. !pip install transformers 1. KLUE-BERT 모델 불러오기 오늘 실습에는 대표적인 한국어 BERT 모델인 KLUE-BERT 모델을 사용합니다! KLUE-BERT 모델은 벤치마크 데이터인 KLUE에서 베이스라인으로 사용되었던 모델로,모두의 말뭉치, CC-100-Kor, 나무위키, 뉴스, 청원 등 문서에서 추출한 63GB의 데이터로 학습된 모델입니다. Mo..