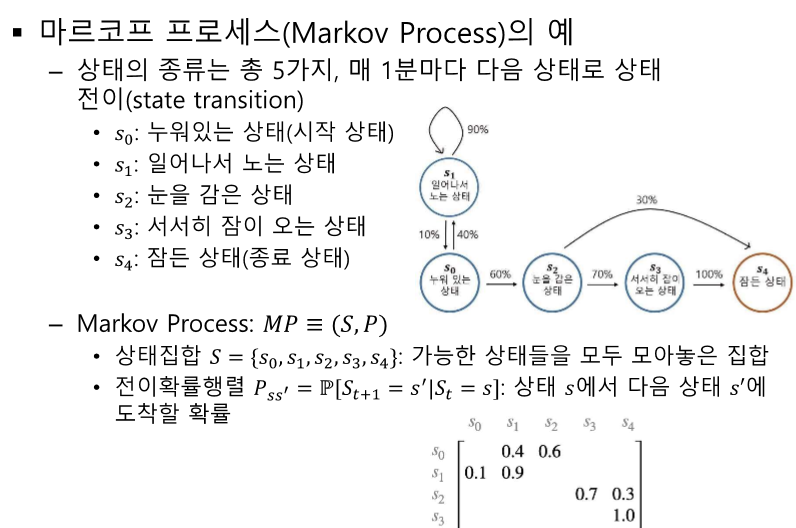
모든 상태를 행렬로 포함한다. - 행별로 쭉 더해서 1이 되는지 확인 확률로 정의하는데 t 이전의 과거는 필요없다! -> 메모리 감소 효과도 있다. 체인 룰에 의해서 다음을 계속 예측할 수 있다. 모든 상황이 마르코프 상태가 맞는 것은 아니라 정답이 아닐 수 있다. 그러나 모델링은 가능하다! 자율주행에서의 현재 상태 == 한 장만으로는 판단할 수 없다. - 10초간의 여러 사진을 하나로 볼 수 있다. 감쇠인자를 통해 미래 보상의 불확실성을 표현할 수 있따. 리턴의 정의 : 특정 시점, 상태에서의 리워드 합 G: 리턴, R: 보상, S: 상태 리턴(G)가 과도하게 커지면 프로그램의 숫자 표현형을 넘길 수 있고, 게임이 안 끝날 수 있다. 가치(V) != 리워드(R)! 내가 미래에 무엇을 받을 지 모르니 기..