자연어 처리 정리 - Deep learning recap 2 SGD - 샘플마다 업데이트하기 때문에 진동이 크다! 모든 샘플을 다 사용하는 batch learning!(epoch learning) local min에 빠질 위험이 크다! 두가지를 섞어서! parameter update = 최적화 오버피팅, 과적합 주황색이 test data겠네요 오버피팅 된 weight의 값은 크다 -> weight의 값을 감소시킨다. 오버피팅 방지, 학습 다향성 증가 인공지능/자연어 처리 2024.04.12
자연어 처리 5강 - Deep Learning Recap 1 Evaluation - Forward propagation == inference 추정하다. exp 사용하는 이유는 최대값에 민감하게 반응하기 때문이ㅏㄷ loss = prediction과 label을 비교하여 차이를 구한다. cross entropy loss를 줄이는 방향으로 학습한다. 항상 경사 하강법을 사용하는 것은 아니다! 그러나 특정 상황에서만 쓴다. 네, 딥러닝에서 파라미터 최적화는 주로 손실 함수의 그래디언트(미분값)를 이용한 방법에 의존합니다. 이는 그래디언트 디센트 방법과 그 변형들이 딥러닝 모델의 학습에 널리 사용되는 이유입니다. 손실 함수의 그래디언트를 계산하고, 이를 사용해 모델의 가중치를 조정함으로써, 모델을 더 좋은 성능으로 이끌어갈 수 있습니다. 그래디언트 기반 방법 이외에도 몇.. 인공지능/자연어 처리 2024.04.12
자연어 처리 정리 - 4강 word embedding 2 문맥에 대한 분포 - 단어와 주변 단어 gram - 문자 단위 임베딩이 이미 다 존재할 때 사용한다. -> 불러와서 다 더한다. Contextualized - 단어의 의미가 문장에 따라 다르다. -> 문장 구성에 따라 임베딩이 업데이트가 된다. 인공지능/자연어 처리 2024.04.12
자연어 처리 정리 - 3강 Word embedding 1 이전엔 단순히 encoding만 했다면 이후로는 embedding으로 진행하였다. 주변 단어를 통해 문맥을 얻을 수 있다. 비슷한 문맥 - 비슷한 벡터 representation = 컴퓨터가 이해할 수 있는 표현 == 백터 TD - 특정 문장에 단어가 등장 횟수 유사도는 이렇게 구할 수 있다. 문서가 많아질수록, 단어가 많아질 수록 효율이 떨어진다. 모든 문서에서 많이 나온다 - 가중치가 낮다 -> 일부 문서에서만 나온다 - 가중치가 높다. TF - 얼마나 나오는지 센다 DF - 총 문서에서 얼마나 나왔냐 이것이 word2Vec 방식이다. 파라미터를 embedding으로 사용하는 것이다. 이러한 형태가 나온다. 그럼 word2vec는 수 많은 문장에서 얻어낸 단어들을 원핫 인 코딩 한 후 문장에 구멍을 .. 인공지능/자연어 처리 2024.04.12
자연어 처리 정리 - 2강 Text mining 자연어 처리 - 검색엔진 (검색어 - Query와 관련된 글 나열), 번역, 긍 부정 판단, 정보 요약, 질문 답변(GPT) NLP는 여러 학문이 종합되어 있고, 언어(자연어)를 컴퓨터가 이해하는 체계로 넘겨주어(embedding, vector representation) 컴퓨터가 처리 언어의 표현을 어렵게 하는 것 - 엄청난 애매모호함, 복잡한 사회 과정, 동음이의어, 공유 지식 인공지능/자연어 처리 2024.04.12
자연어 처리 Python 실습 - 한국어 관계 추출 Introduction Chapter 7. 자연어 이해(NLU) Task 강의의 한국어 관계 추출 Task 실습 강의입니다. 이번 실습에서는 (1) KLUE-BERT base 모델을 KLUE 벤치마크 데이터셋의 KLUE-RE 데이터셋으로 파인튜닝하고, (2) 파인튜닝한 모델의 관계 추출 작업에 대한 성능과 결과를 분석해보겠습니다. !pip install transformers 1. KLUE-BERT 모델 불러오기 오늘 실습에는 대표적인 한국어 BERT 모델인 KLUE-BERT 모델을 사용합니다! KLUE-BERT 모델은 벤치마크 데이터인 KLUE에서 베이스라인으로 사용되었던 모델로,모두의 말뭉치, CC-100-Kor, 나무위키, 뉴스, 청원 등 문서에서 추출한 63GB의 데이터로 학습된 모델입니다. Mo.. 인공지능/자연어 처리 2024.04.11
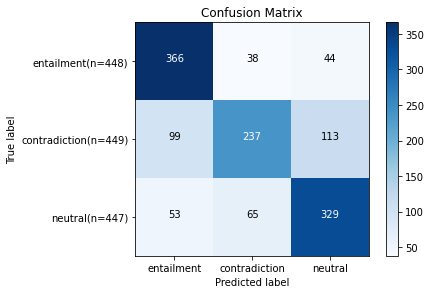
자연어 처리 python 실습 - 한국어 자연어 추론 Task 실습 한국어 자연어 추론 Task 실습 Introduction Chapter 7. 자연어 이해(NLU) Task 강의의 한국어 자연어 추론 Task 실습 강의입니다. 이번 실습에서는 (1) SKTBrain이 공개한 KoBERT를 KLUE 벤치마크 데이터셋의 KLUE-NLI 데이터셋으로 파인튜닝하고, (2) 파인튜닝한 모델의 자연어 추론 작업에 대한 성능과 결과를 분석해보겠습니다. 자연어 추론(NLI) 작업의 목표는 가설 문장과 전제 문장 간의 관계를 추론하는 것입니다. 전제가 주어지면 NLI 모델은 가설이 참(entailment), 거짓(contradiction) 또는 미결정(neutral)인지 결정합니다. 이 작업은 RTE(Recognizing Textual Entailment)라고도 합니다. !pip in.. 인공지능/자연어 처리 2024.04.11
자연어 이해 NLU - Relation Extraction Task 관계 추출 트리플 데이터 - 객체 3개가 연결되어있다. subject에 대한 정보를 달라고 했을 때 object나 relation을 꺼내서 주면 된다. 1. 심볼릭 구조를 뉴럴넷에 활용한 것이다. 2. 로직 룰을 뉴럴넷에 활용했다. 관계 추출 작업은 구조적인 작업이므로 CNN도 활용 가능하다. CNN - 구획적으로 특징을 뽑는다. 임베딩을 이미지처럼 주어주면 CNN이 특징을 잘 뽑는다. 두 엔티티가 관계 정보만 학습한다. 집중해야할 엔티티를 명시적으로 표시해줬다. 학습 초기의 어려운 문제는 노이즈다! 데이터의 학습 순서를 바꾸어 효율적인 학습을 할 것이다. 쉬운 예제를 통해 일반적인 파라미터를 만든 후 어려운 관계 추출을 학습시켜 파라미터를 단단하게 만든다. 한국어로 관계추출 할 경우 이 것을 활용하면 된다. 인공지능/자연어 처리 2024.04.11
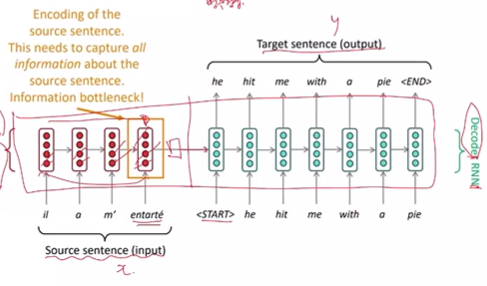
자연어 처리 온라인 강의 - Machine Translation with RNN RNN - 인코더와 디코더로 구성되어 있다. 인코더 인풋 - 번역해야될 문장 디코더 출력 - 번역 된 문장 입력이 들어갈 수록 정보가 사라져서 마지막 입력의 영향이 커지게 된다. -> 정보 병목 현상 -> attention 등장 attention - 딥러닝을 비틀어서 효율적으로 학습시킨 경험적 모델 어떤 단어를 집중해야 하는지 나온다. transformer 계열의 모든 모델에서 attention 개념이 사용된다. 인코더 모델과 디코더 모델의 어텐션을 계산해서 아웃풋을 계산한다. 디코더의 시작값과 인코더 모든 값을 내적하면 인코더 인풋 개수만큼 스칼라 값이 나온다. -> soft max를 취하면 1이 되면 확률 분포가 나온다. = attention distribution을 얻는다. 유사도를 얻게 된다-> .. 인공지능/자연어 처리 2024.04.10
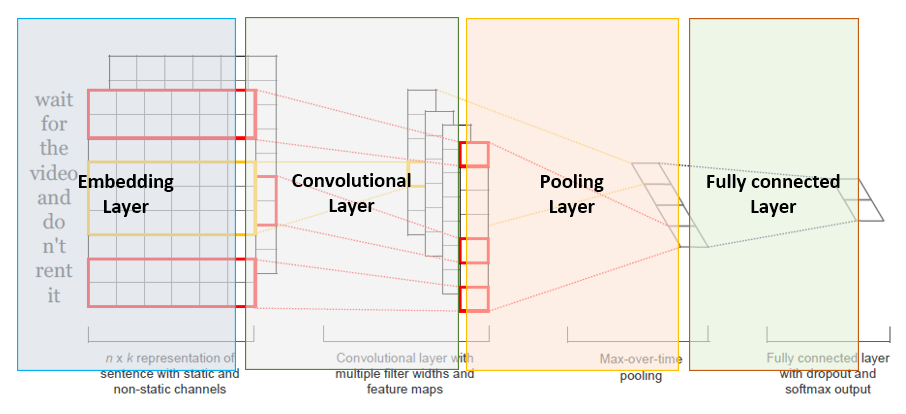
자연어 처리 과제 2 - CNN text classification 감성 분석 기본적인 구조입니다. 전처리를 진행해야죠 # total text tokens total_words = [] for words in words_list: total_words.extend(words) from collections import Counter c = Counter(total_words) # 빈도를 기준으로 상위 10000개의 단어들만 선택 max_features = 10000 common_words = [word for word, count in c.most_common(max_features)] print(common_words.index('행')) print(common_words[248]) 토큰화해서 제일 많이 나온 단어 10000개만 사용할 겁니다. 확인해보면 행이란 단어는 248번째.. 인공지능/자연어 처리 2024.04.10