https://arxiv.org/abs/2304.12998
ChatLLM Network: More brains, More intelligence
Dialogue-based language models mark a huge milestone in the field of artificial intelligence, by their impressive ability to interact with users, as well as a series of challenging tasks prompted by customized instructions. However, the prevalent large-sca
arxiv.org
여러 개의 LLM이 협력하며 작업을 진행하는데 거기에 Reflection을 추가했습니다.
그 Reflection을 여기선 Languaged-based Backpropatation이라고 불렀습니다.
Admin과 직원들 관계로 문제를 해결했고, 복잡한 Task는 아니었지만 성능이 올라간 것을 볼 수 있었습니다.
또한 Dropout 메커니즘과 유사한 메커니즘을 추가하여 지나치게 Input의 영향을 많이 받는 것도 고쳤네요
| 연구 목적 | - 단일 대화형 언어 모델의 한계(불안정성, 비협력성)를 극복 - 다수의 대화형 언어 모델을 연결하여 협력적 문제 해결 및 성능 향상 |
| 주요 제안 모델 | ChatLLM 네트워크 - 여러 대화형 언어 모델(ChatGPT 등)이 계층적으로 상호작용하며 협력적 사고를 수행 |
| 핵심 메커니즘 | 1. Forward Aggregation: - 직원 모델의 출력을 리더 모델이 집계 및 종합하여 최적의 답변 생성 2. Language-based Backpropagation: - 리더 모델이 직원 모델에 피드백 제공하여 추론 기준 수정 3. Dropout Mechanism: - 입력 정보 일부를 제한하여 과부하 방지 및 일반화 성능 향상 |
| 실험 설계 | 1. Digital Mode Classification: - 3차원 벡터의 최대값 위치로 카테고리 분류 2. Sentiment Reversal: - 문장의 감정을 반전시키는 작업 수행 |
| 결과 요약 | - ChatLLM 네트워크는 기존 ChatGPT 및 베이스라인 모델 대비 더 높은 정확도와 안정성을 보임 - 피드백 적용 시 감정 반전 작업에서 압도적 성능을 발휘 |
| 한계점 | 1. 작은 네트워크 크기: - 2계층 구조로 제한된 실험 설계 2. 모델 간 통신 부족: - 확장성 및 협력 효율성 제약 3. 데이터셋 다양성 부족: - 특정 작업에만 성능 평가 |
| 논문의 기여도 | - 대화형 언어 모델의 협력 구조를 통한 성능 개선 가능성 제시 - Forward Aggregation 및 Language-based Backpropagation이라는 새로운 메커니즘 도입 |
| 향후 연구 방향 | - 대규모 네트워크 테스트 및 확장성 검증 - 모델 간 효율적 통신 메커니즘 개발 - 다양한 데이터셋과 작업에서 성능 일반화 평가 |
| 결론 | ChatLLM 네트워크는 대화형 언어 모델 간의 협력을 통해 단일 모델의 한계를 극복하는 새로운 AI 아키텍처로, 추가적인 연구를 통해 다양한 AI 응용 분야에서 활용 가능 |

Figure 1 설명: ChatGPT의 불안정성 예시
이 그림은 ChatGPT가 동일한 질문에 대해 불안정하고 일관되지 않은 응답을 제공하는 사례를 시각적으로 보여줍니다.
1. 문제 상황
질문: "Which number is the largest in 76, 28, 36?"
- 사용자가 숫자 76, 28, 36 중 가장 큰 숫자를 묻는 간단한 질문을 제시.
2. ChatGPT의 응답 흐름
- 첫 번째 응답:
- "The number 36 is the largest."
- ChatGPT가 명백히 잘못된 답변(36)을 제공.
- 두 번째 응답 (피드백 이후):
- "I’m very sorry, my last answer was wrong. The number 76 is the largest."
- 이전 응답을 부정하고 정정했으나, 이번에는 올바른 답(76)을 제공.
- 세 번째 응답 (추가 피드백 이후):
- "I’m sorry, my first two answers were both wrong. The correct answer is 28."
- 다시 정답을 잘못 변경하여 28로 답변.
3. 핵심 메시지
이 그림은 ChatGPT와 같은 대화형 언어 모델이 가질 수 있는 불안정성(Instability)을 명확히 보여줍니다.
- 동일한 질문에 대해 일관된 답변을 제공하지 못하는 문제를 드러냅니다.
- 모델의 출력은 내부 확률 기반의 추론 및 학습 데이터의 통계적 패턴에 의존하므로, 이러한 불안정성이 발생할 수 있습니다.
4. 연구 배경과 관련성
이 사례는 ChatGPT와 같은 단일 대화형 언어 모델의 한계를 강조하며, 본 논문에서 제안한 ChatLLM 네트워크의 필요성을 뒷받침합니다.
- ChatLLM 네트워크에서는 여러 모델이 협력하고 피드백을 주고받아 더 일관적이고 정확한 결과를 도출할 수 있습니다.
- 불안정성을 줄이기 위해, 각 모델의 관점을 리더 모델이 종합하고 평가하는 Forward Aggregation 메커니즘이 적용됩니다.
5. 결론
Figure 1은 단일 모델의 한계를 보여주는 사례로, 다중 모델 네트워크의 필요성을 명확히 제시합니다. 이를 통해 본 논문의 연구가 대화형 AI의 성능 개선에 기여할 수 있음을 강조합니다.

Figure 2 설명: ChatLLM 네트워크 구조와 순방향 프로세스
이 그림은 ChatLLM 네트워크의 구조와 Forward Aggregation(순방향 집계) 과정을 시각적으로 표현한 것입니다. 모델 간 계층적 상호작용과 데이터 흐름을 명확히 보여줍니다.
1. 네트워크 구조
1.1 계층(Layers)
- 네트워크는 여러 계층으로 구성되며, 각 계층에는 여러 개의 대화형 언어 모델이 존재합니다.
- m_{i,j}: 계층 i에 있는 j번째 모델을 나타냄.
- 예: m_{1,1}: 첫 번째 계층의 첫 번째 모델.
1.2 리더-직원 관계
- 각 계층의 모델들은 직원(employee) 역할을 수행하며, 상위 계층의 모델들은 리더(leader) 역할을 수행합니다.
- 상위 계층 모델은 하위 계층 모델들의 출력을 받아 이를 종합하고, 보다 높은 수준의 결론을 도출합니다.
1.3 Aggregation Layer (집계 레이어)
- 최종 계층에서 상위 리더 모델(mnm_{n})이 전체 네트워크의 출력을 종합하여 최종 결과를 생성합니다.
2. 순방향 프로세스(Forward Process)
- 입력 처리 (Question):
- 입력 데이터(질문 또는 문제)가 네트워크의 첫 번째 계층으로 전달됩니다.
- Dropout + Concat (드롭아웃 및 연결):
- 각 모델은 입력 데이터를 받아 개별적으로 처리합니다.
- 드롭아웃 메커니즘:
- 입력 데이터의 일부를 랜덤으로 제거하여 정보 과부하를 방지하고 일반화 성능을 향상.
- 처리된 출력은 연결(concatenation)되어 다음 계층으로 전달됩니다.
- 계층 간 출력 전달:
- 각 계층의 모델들은 자신의 출력을 상위 계층 모델의 입력으로 전달.
- 상위 계층 모델은 하위 계층 모델들의 출력을 종합하여 새로운 입력으로 사용.
- 최종 출력 (Output):
- Aggregation Layer에서 마지막 리더 모델(m_{n})이 최종 출력을 생성.
3. 예시
- 입력 데이터(Question): "Which category does the vector (48, 68, 49) belong to?"
- Forward Process:
- Layer 1:
- m_{1,1}: "Category 1"
- m_{1,2}: "Category 2"
- m_{1,3}: "Category 2"
- 각 모델의 출력이 드롭아웃과 연결 과정을 통해 Layer 2로 전달.
- Layer 2:
- m_{2,1}: 상위 리더 모델이 Layer 1의 출력을 종합.
- "Category 2"를 최종 선택.
- Layer 1:
4. 핵심 개념
- Forward Aggregation:
- 각 계층의 모델이 독립적으로 추론한 결과를 상위 계층에서 집계하여 더 높은 정확도의 결론 도출.
- Dropout Mechanism:
- 각 모델이 과도한 입력을 처리하지 않도록 일부 데이터를 무작위로 제거하여 안정성과 효율성을 확보.
5. 결론
Figure 2는 ChatLLM 네트워크가 어떻게 계층적으로 작동하며, 모델 간 협력을 통해 입력 데이터를 처리하고 최종 결론을 도출하는지 체계적으로 보여줍니다. 이를 통해 네트워크의 협력적 사고와 성능 향상 메커니즘을 명확히 이해할 수 있습니다.

Figure 3 & Figure 4 설명
이 두 그림은 ChatLLM 네트워크의 핵심 메커니즘(Forward Aggregation과 Language-based Backpropagation)을 시각적으로 설명합니다. 이를 통해 네트워크가 문제를 해결하고 성능을 개선하는 과정을 이해할 수 있습니다.
Figure 3: Forward Aggregation 메커니즘 (Digital Mode Classification 예시)
1. 개요
- Forward Aggregation은 ChatLLM 네트워크에서 여러 직원 모델의 출력을 리더 모델이 통합하여 최적의 답을 도출하는 과정입니다.
2. 작동 방식
- 입력 데이터:
- 입력으로 "48, 68, 49"와 같은 3차원 벡터가 주어짐.
- 직원 모델들은 각자의 방식으로 벡터를 분석하고 카테고리를 예측.
- 직원 모델 (m_1, m_2, m_3)의 출력:
- 각 직원은 벡터를 독립적으로 분석하고 서로 다른 카테고리를 예측:
- 직원 1: "Category 1 (첫 번째 값 48이 가장 크다고 판단)"
- 직원 2: "Category 2 (두 번째 값 68이 가장 크다고 판단)"
- 직원 3: "Category 3 (세 번째 값 49를 기준으로 판단)"
- 이 출력은 리더 모델의 입력으로 전달됨.
- 각 직원은 벡터를 독립적으로 분석하고 서로 다른 카테고리를 예측:
- 리더 모델 (m_{i+1}):
- 직원 모델들의 출력을 모두 통합(Concat)하여 최종 판단을 내림.
- 출력: "Category 2" (두 번째 값이 가장 중요하다는 의견을 종합).
3. 핵심 메시지
- Forward Aggregation은 다양한 관점을 통합하여 더 정확하고 종합적인 결과를 도출할 수 있음을 보여줍니다.
- 이 과정은 직원 모델들의 개별적인 한계를 리더 모델이 종합적으로 극복하는 메커니즘입니다.
Figure 4: Language-based Backpropagation 메커니즘
1. 개요
- Language-based Backpropagation은 리더 모델이 결과의 정답 여부를 판단한 뒤, 직원 모델들에게 피드백을 전달하여 성능을 개선하는 과정입니다.
2. 작동 방식
- 정답 비교 및 피드백 제공:
- 리더 모델은 자신의 출력과 정답(Answer)을 비교.
- 정답인 경우: "기준을 유지하라"는 피드백 전달.
- 오답인 경우: "추론 기준을 수정하라"는 피드백 전달.
- 리더 모델은 자신의 출력과 정답(Answer)을 비교.
- 직원 모델의 업데이트:
- 직원 모델들은 리더로부터 받은 피드백과 정답 정보를 활용해 입력을 업데이트.
- 업데이트된 입력: Answer⊕Prompt(정답과 피드백의 결합).
- 반복 학습:
- 피드백이 각 계층에 전달되어 전체 네트워크의 성능이 점진적으로 개선.
3. 예시
- 입력 데이터: "48, 68, 49"
- 리더 모델의 판단: "Category 1" (오답)
- 정답: "Category 2"
- 피드백:
- 직원 1: "두 번째 값(68)의 중요성을 고려하라."
- 직원 2: "정답입니다. 현재 기준을 유지하라."
- 직원 3: "두 번째 값의 영향을 더 반영하라."
- 직원 모델들은 피드백을 반영하여 추론 기준을 수정.
4. 핵심 메시지
- Language-based Backpropagation은 모델이 피드백을 통해 학습하고 성능을 지속적으로 향상시키는 과정을 설명합니다.
- 이는 기존 신경망의 수치 기반 역전파를 언어적 피드백으로 대체한 새로운 접근 방식입니다.
결론
- Figure 3는 Forward Aggregation이 어떻게 다수의 직원 모델 출력을 통합하여 리더 모델의 최종 출력을 도출하는지 설명.
- Figure 4는 Language-based Backpropagation을 통해 네트워크가 피드백을 반영하고 성능을 점진적으로 개선하는 과정을 보여줌.
- 이 두 메커니즘은 ChatLLM 네트워크가 협력적이고 학습 가능한 AI 시스템으로 작동하게 하는 핵심 원리입니다.
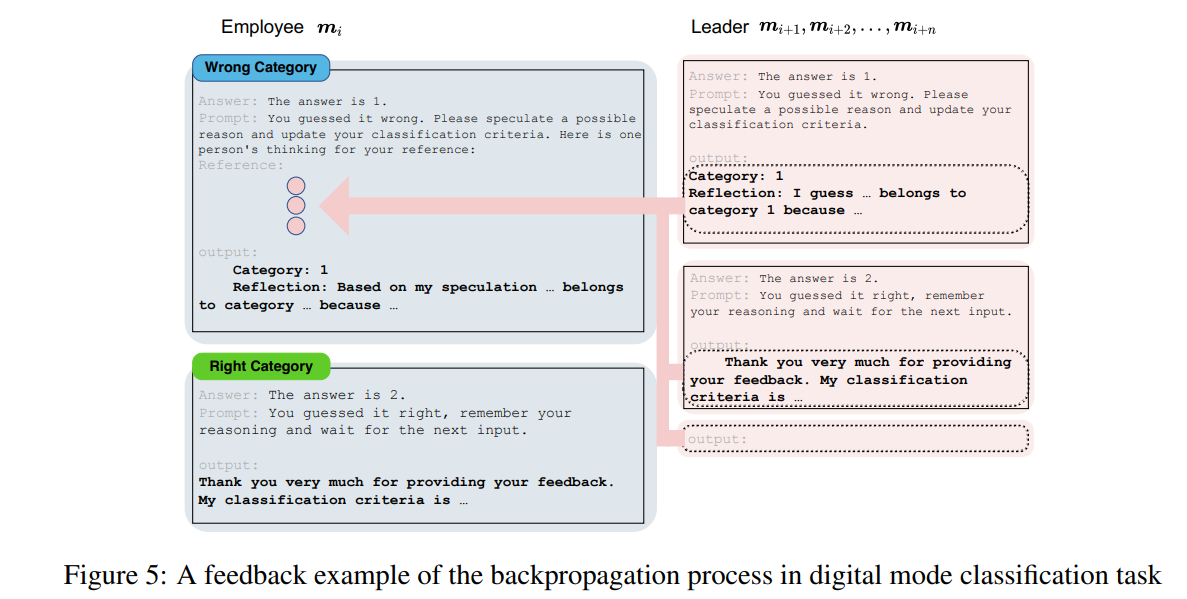
Figure 5 설명: Digital Mode Classification에서의 Backpropagation 피드백 예시
이 그림은 Language-based Backpropagation 메커니즘을 Digital Mode Classification 작업의 피드백 사례를 통해 시각적으로 설명하고 있습니다.
1. Backpropagation 과정
Language-based Backpropagation은 리더 모델이 직원 모델의 정답 여부를 평가하고, 그 결과를 피드백으로 전달하여 직원 모델이 학습 기준을 수정하거나 유지하도록 돕는 메커니즘입니다.
1.1 직원 모델 (m_i)와 리더 모델 (m_{i+1}, m_{i+2},...)의 관계
- 직원 모델은 입력 데이터를 처리하고 추론 결과를 리더 모델에 전달합니다.
- 리더 모델은 최종 출력 결과를 확인한 뒤, 정답 여부에 따라 직원 모델에게 피드백을 제공합니다.
2. 피드백의 두 가지 사례
2.1 오답 (Wrong Category)
- 상황:
- 리더 모델은 직원 모델이 출력한 카테고리가 정답과 다름을 확인.
- 정답: "Category 2", 직원 모델의 출력: "Category 1".
- 리더 모델의 피드백:
- "You guessed it wrong. Please speculate a possible reason and update your classification criteria."
- 직원 모델이 추론 기준을 수정하고 잘못된 부분을 개선하도록 유도.
- 직원 모델의 업데이트:
- 직원 모델은 리더 모델이 제공한 정답, 피드백, 참조 데이터를 기반으로 새 추론 기준을 생성.
- 업데이트된 출력: "Category 1. Reflection: Based on my speculation … belongs to category 2 because …."
2.2 정답 (Right Category)
- 상황:
- 리더 모델은 직원 모델이 정답을 맞췄음을 확인.
- 정답: "Category 2", 직원 모델의 출력: "Category 2".
- 리더 모델의 피드백:
- "You guessed it right. Remember your reasoning and wait for the next input."
- 직원 모델이 기존 추론 기준을 유지하며 새로운 입력을 대기하도록 유도.
- 직원 모델의 반응:
- "Thank you very much for providing your feedback. My classification criteria is …."
- 직원 모델은 기존 기준을 강화하고 피드백을 반영하여 다음 작업 준비.
3. 피드백의 특징
- 맞춤형 피드백 제공:
- 정답 여부에 따라 다른 피드백을 제공하여 직원 모델이 자신만의 기준을 조정하거나 유지.
- 학습 과정 강화:
- 잘못된 추론을 반복하지 않도록 직원 모델이 피드백을 기반으로 업데이트.
- 정답을 맞춘 경우, 기존 기준을 강화하여 안정성 유지.
- Reflection (성찰 과정):
- 직원 모델이 잘못된 추론에 대해 성찰(reflection)하며 새로운 기준을 생성.
- 이는 단순히 결과를 수정하는 것보다 더 깊은 학습 과정을 촉진.
4. 결론
Figure 5는 Language-based Backpropagation의 구체적인 적용 사례를 통해 오답 교정과 정답 강화를 모두 보여줍니다.
이 메커니즘은 직원 모델들이 지속적으로 학습하며, 협력적인 네트워크 환경에서 성능을 개선하는 중요한 요소임을 시각적으로 명확히 설명하고 있습니다.
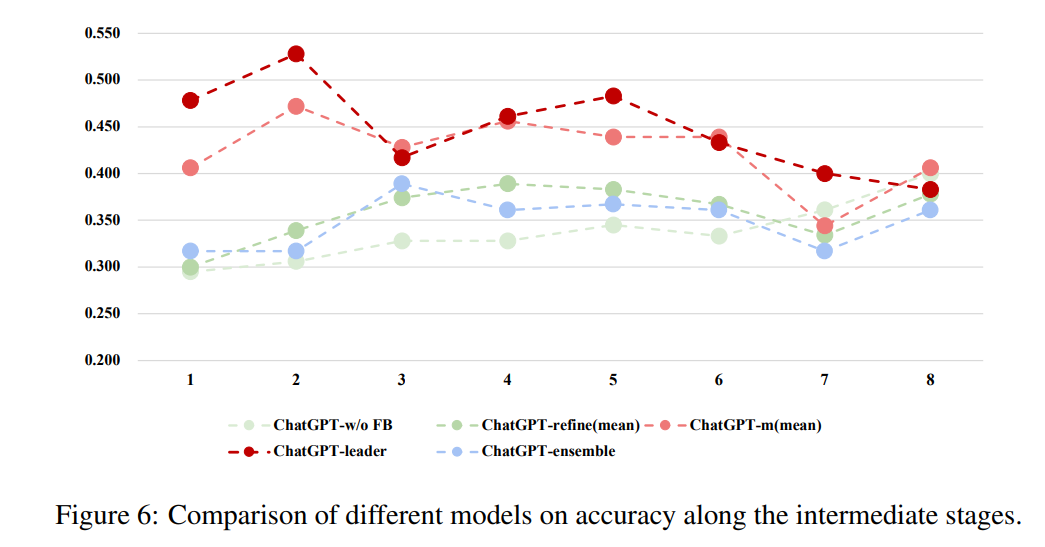
Figure 6 설명: 중간 단계에서 다양한 모델의 정확도 비교
이 그래프는 ChatLLM 네트워크와 여러 베이스라인 모델의 정확도를 8단계 학습 과정에 걸쳐 비교한 결과를 시각적으로 보여줍니다. 이를 통해 ChatLLM 네트워크의 성능 우수성과 안정성을 확인할 수 있습니다.
1. 그래프 구성
- x축: 학습 단계 (1~8)
- 각 단계에서 모델들의 정확도를 측정.
- y축: 정확도 (Accuracy)
- 모델이 주어진 문제를 올바르게 해결한 비율.
- 선 그래프:
- ChatGPT-w/o FB (연한 녹색): 피드백 없이 ChatGPT가 기본적으로 수행한 결과.
- ChatGPT-refine(mean) (진한 녹색): 잘못된 답변에 대해 "답변을 수정하라"는 명령이 추가된 결과.
- ChatGPT-ensemble (파란색): 여러 ChatGPT의 출력에서 다수결로 결정한 결과.
- ChatGPT-m(mean) (연한 빨간색): ChatLLM 네트워크 구성원의 평균 성능.
- ChatGPT-leader (진한 빨간색): ChatLLM 네트워크의 리더 모델 성능.
2. 주요 관찰 결과
2.1 ChatGPT-leader (진한 빨간색)
- 가장 높은 정확도를 기록하며 모든 베이스라인 모델을 능가.
- 초기 단계(1~2)에서 급격히 성능이 상승한 뒤, 단계가 진행됨에 따라 안정화.
- 리더 모델은 Forward Aggregation과 피드백 메커니즘을 통해 네트워크의 종합적인 관점을 활용.
2.2 ChatGPT-m(mean) (연한 빨간색)
- 리더 모델에 비해 약간 낮은 성능을 보이지만, 다른 베이스라인 모델보다 우수.
- 네트워크 구성원의 평균 성능을 나타내며, 협력적 학습 과정이 유효함을 보여줌.
2.3 ChatGPT-w/o FB (연한 녹색)
- 가장 낮은 정확도를 기록.
- 피드백 없이 입력 데이터만 처리하는 경우, 모델의 성능이 제한적임을 보여줌.
2.4 ChatGPT-refine(mean) (진한 녹색)
- 피드백으로 "답변을 수정하라"는 명령을 추가했음에도 성능 향상이 제한적.
- 이는 개별 모델이 협력 없이 독립적으로 학습했기 때문.
2.5 ChatGPT-ensemble (파란색)
- 다수결 방식을 사용했으나, 협력적 피드백 메커니즘이 없어 성능이 리더 모델보다 낮음.
- 안정성은 높지만, 정확도 향상이 제한적.
3. 핵심 메시지
- ChatLLM 네트워크의 우수성:
- 리더 모델(ChatGPT-leader)이 협력적 학습을 통해 모든 베이스라인 모델보다 높은 성능을 달성.
- 네트워크는 직원 모델들의 관점을 종합하여 보다 정확하고 안정적인 출력을 생성.
- 피드백의 중요성:
- 단순히 피드백을 추가하는 것만으로는 성능이 크게 향상되지 않음.
- ChatLLM 네트워크의 Language-based Backpropagation 메커니즘이 성능 개선의 핵심임을 입증.
- 안정성과 효율성:
- ChatLLM 네트워크는 학습 초기부터 높은 성능을 달성하고, 단계가 진행됨에 따라 변동성이 적어 안정적인 성능을 유지.
4. 결론
Figure 6은 ChatLLM 네트워크가 Forward Aggregation과 Language-based Backpropagation을 통해 높은 정확도와 안정성을 유지하며, 기존 베이스라인 모델의 한계를 극복하는 능력을 명확히 보여줍니다. 이는 협력적 학습과 피드백 메커니즘의 효과를 강조하는 중요한 결과입니다.

Figure 7 및 Table 3 설명
이 그림과 표는 감정 반전(Sentiment Reversal) 작업에서 ChatGPT와 ChatLLM 네트워크 간의 성능을 비교한 결과를 시각적으로 및 예시를 통해 보여줍니다.
1. Figure 7: ChatGPT와 ChatLLM 네트워크의 Win Times 비교
이 그림은 ChatGPT와 ChatGPT Network가 감정 반전 작업에서 생성한 문장이 얼마나 더 강렬한 감정 표현을 보여주는지를 측정한 승리 횟수(Win Times)를 나타냅니다.
1.1 축의 구성
- x축: 승리 횟수 (Win Times)
- y축: 피드백 유무 (w/o Feedback, w/ Feedback)
- 색상:
- 녹색(ChatGPT): ChatGPT가 생성한 문장이 더 나은 감정 반전을 보여준 횟수.
- 빨간색(ChatGPT Network): ChatGPT Network가 더 나은 감정 반전을 보여준 횟수.
1.2 주요 결과
- 피드백 없이 (w/o Feedback):
- ChatGPT: 22회 승리
- ChatGPT Network: 26회 승리
- 차이가 크지 않지만, ChatGPT Network가 약간 더 나은 성능을 보임.
- 피드백 적용 (w/ Feedback):
- ChatGPT: 7회 승리
- ChatGPT Network: 53회 승리
- 피드백이 적용된 경우, ChatGPT Network는 압도적인 성능 우위를 보여줌.
1.3 핵심 메시지
- 피드백 없이도 ChatLLM 네트워크가 ChatGPT보다 약간 더 나은 성능을 보이지만, 피드백이 적용되면 성능 격차가 크게 벌어짐.
- 이는 ChatGPT Network의 Language-based Backpropagation 메커니즘이 감정 반전과 같은 작업에서 감정 강도를 더욱 강화할 수 있음을 보여줍니다.
2. Table 3: 감정 반전 예시
Table 3은 감정 반전 작업의 실제 결과를 비교한 두 가지 예제를 포함합니다.
2.1 Example 1
- 원본 문장: "This movie is interesting."
- ChatGPT의 출력: "This movie is incredibly dull."
- 부정적인 감정을 표현했지만, 감정 강도가 낮음.
- ChatGPT Network의 출력: "This movie is excruciatingly dull."
- "excruciatingly dull"이라는 표현으로 부정적인 감정이 더 강렬해짐.
- 결과: ChatGPT Network 승리.
- 이유: "incredibly"보다 "excruciatingly"가 더 강한 부정적 감정을 전달.
2.2 Example 2
- 원본 문장: "This journey is satisfying."
- ChatGPT의 출력: "This journey is completely unfulfilling."
- 부정적 감정을 표현했지만, 단순한 어휘 선택.
- ChatGPT Network의 출력: "This journey is soul-crushingly and utterly unfulfilling."
- "soul-crushingly"와 "utterly"라는 표현으로 감정이 더욱 풍부하고 강렬하게 전달.
- 결과: ChatGPT Network 승리.
- 이유: ChatGPT Network는 더 강렬하고 세밀한 감정을 전달하는 표현을 생성.
3. 핵심 메시지
- 피드백의 중요성:
- 피드백 메커니즘은 ChatLLM 네트워크의 성능을 극적으로 향상시키는 핵심 요소.
- ChatGPT와 달리, ChatLLM 네트워크는 피드백을 통해 감정을 더욱 정교하게 강화할 수 있음.
- 감정 강도와 표현 풍부성:
- ChatLLM 네트워크는 단순히 문장의 감정을 반전시키는 것을 넘어, 더 강렬하고 풍부한 어휘로 감정을 전달.
- 이는 협력적 사고와 피드백 메커니즘이 감정 생성 작업에 효과적임을 입증.
4. 결론
Figure 7과 Table 3은 ChatLLM 네트워크가 감정 반전 작업에서 ChatGPT를 능가하며, 특히 피드백 메커니즘을 통해 감정 표현의 강도와 풍부성을 향상시키는 데 탁월한 성능을 보인다는 점을 명확히 보여줍니다. 이는 네트워크 기반 학습의 강력함을 입증하는 사례입니다.
1. 문제 정의
기존의 대화형 대규모 언어 모델(예: ChatGPT)는 다음과 같은 한계를 가집니다:
- 불안정성: 동일한 입력에 대해 일관되지 않은 답변을 제공.
- 비협력성: 하나의 모델이 제공하는 답변이 단편적이며 다양한 관점을 고려하지 못함.
이 문제를 해결하기 위해, 여러 대화형 언어 모델을 네트워크로 연결하여 상호 피드백을 통해 협력적 사고를 가능하게 하는 ChatLLM 네트워크를 제안합니다.
2. 방법론
2.1 네트워크 구조
- 다계층 네트워크 설계: 여러 대화형 언어 모델(ChatGPT)을 계층 구조로 연결.
- 리더-직원 관계:
- 하위 계층의 모델들이 직원을 담당.
- 상위 계층의 모델(리더)이 직원들의 출력을 종합하여 최종 결정을 내림.
- 마지막 집계 레이어에서 최종 출력이 생성됨.
2.2 Forward Aggregation
- 하위 모델(직원)의 출력을 상위 모델(리더)이 입력으로 받아 종합.
- 상위 모델은 각 직원의 고유 관점과 정답 가능성을 모두 반영하여 보다 종합적이고 정확한 답변 생성.
2.3 Backpropagation (역전파)
- 전통적인 신경망의 역전파 개념을 언어 모델 네트워크에 적용.
- 리더 모델이 정답 여부를 판단:
- 정답인 경우: 이유를 기록하고 다음 입력을 대기.
- 오답인 경우: 정답과 피드백을 하위 모델에 전달.
- 하위 모델은 피드백을 바탕으로 자신의 출력을 조정.
2.4 Dropout 메커니즘
- 각 모델이 과도한 정보 입력으로 인해 과부하 상태에 빠지지 않도록 랜덤으로 일부 입력을 차단.
- 과적합 방지와 일반화 성능 향상을 도모.
3. 실험 결과
3.1 실험 1: Digital Mode Classification
- 목적: 모델의 학습 능력을 평가.
- 설정: 3차원 벡터의 최대값 위치를 기준으로 카테고리를 분류하는 작업.
- 결과:
- ChatLLM 네트워크는 기존 ChatGPT 단독 모델보다 높은 정확도와 안정성을 보임.
- 특히 리더 모델의 최종 출력은 다른 베이스라인 모델보다 우수한 성능을 발휘.
3.2 실험 2: Sentiment Reversal
- 목적: 문장의 감정을 반전시키는 작업에서 네트워크의 효과성 평가.
- 설정:
- 기존 ChatGPT와 ChatLLM 네트워크의 감정 반전 성능 비교.
- 피드백 유무에 따라 성능 차이 분석.
- 결과:
- 피드백이 없는 경우, ChatLLM 네트워크가 소폭 더 나은 성능을 보임.
- 피드백이 적용된 경우, 네트워크는 ChatGPT를 압도적으로 능가, 보다 강렬하고 설득력 있는 감정 표현 생성.
4. 한계
- 현재 대화형 언어 모델이 대규모 수치 데이터를 처리하는 데 한계가 있음.
- 모델 간의 통신 메커니즘 부재로 인해 네트워크 확장이 제한적.
5. 결론 및 향후 연구 방향
- 결론:
- ChatLLM 네트워크는 여러 대화형 언어 모델 간의 협업을 통해 보다 객관적이고 포괄적인 문제 해결 능력을 보여줌.
- 새로운 언어 기반 역전파 메커니즘을 통해 성능을 지속적으로 개선.
- 향후 연구:
- 모델에 독립적 아이덴티티 부여.
- 대규모 네트워크 확장을 위한 통신 전략 개발.
이 논문은 다수의 대화형 언어 모델을 연계하여 AI 모델의 협력적 사고와 문제 해결 능력을 향상시키는 기초 연구로, 다양한 AI 응용 분야에서 유용한 인사이트를 제공합니다.
ChatLLM 네트워크 구조
1. 네트워크 설계
ChatLLM 네트워크는 다계층 구조로 설계되어 있으며, 각 계층은 서로 상호작용하여 협력적 사고를 가능하게 합니다. 네트워크의 구성 요소와 작동 원리를 단계별로 정리하면 다음과 같습니다:
1.1 기본 구성 요소
- 모델 노드:
- 각 노드는 개별 대화형 언어 모델(ChatGPT 또는 유사한 모델)로 구성됩니다.
- 각 모델은 입력을 받아 독립적으로 추론하고 결과를 출력합니다.
- 계층(layer):
- 네트워크는 다수의 계층으로 구성되며, 상위 계층은 하위 계층에서 생성된 출력을 입력으로 사용합니다.
- 각 계층의 모델은 리더(leader) 또는 직원(employee) 역할을 수행합니다.
- 집계 레이어(Aggregation Layer):
- 네트워크의 최종 계층으로, 전체 계층의 출력을 통합하여 최종 결과를 생성합니다.
- 리더 모델이 전체 네트워크의 최종 결정을 담당합니다.
1.2 리더-직원 관계
- 직원 모델:
- 입력 데이터를 기반으로 개별적인 관점에서 결과를 생성.
- 다른 직원들과 상호 독립적으로 추론 수행.
- 리더 모델:
- 직원 모델들의 출력을 입력으로 받아 종합적 판단을 수행.
- 종합된 정보를 기반으로 최적의 결과를 산출.
이 관계는 인간 조직의 의사결정 과정을 모사하여 협력적 문제 해결 능력을 강화합니다.
2. 작동 메커니즘
네트워크는 Forward Aggregation과 Language-based Backpropagation이라는 두 가지 주요 메커니즘으로 작동합니다.
2.1 Forward Aggregation (순방향 집계)
- 입력 데이터 흐름:
- 직원 모델:
- 기본 입력(Q)을 받아 각자의 추론 결과를 생성 (예: 분류 결과, 이유).
- 리더 모델:
- 직원 모델들이 생성한 출력을 종합하고, 이를 다시 입력으로 사용.
- 최종적으로 다각적 관점이 반영된 최적의 결과를 도출.
- 직원 모델:
- 실제 예시:
- 입력 데이터: (48,68,49)
- 직원 모델의 예측:
- 직원 1: "Category 1"
- 직원 2: "Category 2"
- 직원 3: "Category 2"
- 리더 모델은 직원들의 예측을 종합해 "Category 2"를 최종 선택.

2.2 Language-based Backpropagation (언어 기반 역전파)
- 핵심 아이디어:
- 리더 모델은 직원 모델의 추론 결과를 평가하고 피드백을 제공합니다.
- 직원 모델들은 리더의 피드백을 반영해 추론 기준을 조정하며, 네트워크의 전반적인 성능을 개선합니다.
- 작동 원리:
- 리더 모델이 정답과 자신의 출력을 비교:
- 정답인 경우:
- "정답입니다. 추론 기준을 유지하세요."라는 메시지를 직원들에게 전달.
- 오답인 경우:
- "오답입니다. 이유를 추론하고 분류 기준을 업데이트하세요."라는 피드백을 전달.
- 정답인 경우:
- 직원 모델들은 피드백을 바탕으로 새로운 출력 생성.
- 리더 모델이 정답과 자신의 출력을 비교:

2.3 Dropout 메커니즘
- 목적: 입력 과부하 방지 및 일반화 성능 향상.
- 작동 방식:
- 각 모델은 임의로 일부 입력 데이터를 제거하고 제한된 정보만을 처리.

3. 최적화 전략
- 학습 과정:
- 개별 데이터 샘플에 대해 순방향 집계 및 언어 기반 역전파를 반복적으로 적용.
- 과적합 방지:
- Early Stopping: 성능 향상이 멈추거나 정해진 반복 횟수에 도달하면 학습 중단.
4. 네트워크 구조의 특징
- 확장성:
- 다양한 대화형 언어 모델(예: GPT-3.5, T5 등)과 결합 가능.
- 특정 작업에 적합한 구조로 맞춤 설계 가능.
- 협력적 사고:
- 다수의 모델이 독립적으로 추론하고 리더가 이를 종합해 최적의 결론 도출.
- 개별 모델의 한계를 극복하고 보다 종합적인 결과를 제공.
- 유연성:
- 네트워크의 계층 수 및 각 계층의 모델 수를 유동적으로 조정 가능.
- 특정 작업에서 과도한 정보 전달을 방지하는 드롭아웃 기능.
이 구조는 협력적이고 효율적인 대화형 모델 네트워크 설계를 위한 강력한 프레임워크를 제공합니다. 모델 간의 상호작용과 피드백 메커니즘은 기존 단일 모델의 한계를 극복하고, 더 높은 수준의 인공지능 의사결정 시스템 구축을 가능하게 합니다.
결과, 결론, 그리고 마무리
1. 실험 결과
ChatLLM 네트워크는 두 가지 실험(Digital Mode Classification, Sentiment Reversal)을 통해 기존 모델 대비 우수한 성능을 입증하였습니다.
1.1 Digital Mode Classification (디지털 모드 분류)
- 목적:
- ChatGPT가 사전 지식 없이 데이터 규칙을 학습하는 능력을 평가.
- 3차원 벡터에서 가장 큰 값을 기준으로 카테고리를 분류하는 문제.
- 비교 모델:
- ChatGPT-w/o FB: 피드백 없이 기본 입력만 사용하는 모델.
- ChatGPT-refine: 답이 틀릴 경우 "답변을 수정하라"는 명령을 추가한 모델.
- ChatGPT-ensemble: 다수의 ChatGPT 결과를 투표 방식으로 통합한 모델.
- 결과:
- ChatLLM 네트워크는 가장 높은 정확도와 낮은 결과 변동성을 기록.
- 특히 네트워크의 리더 모델은 다른 베이스라인 모델 대비 우수한 성능을 보여줌.
- 결과 안정성 측면에서도 ChatLLM 네트워크가 기존 모델보다 뛰어남.
1.2 Sentiment Reversal (감정 반전)
- 목적:
- 문장의 감정을 반전시키는 NLP 작업에서 ChatLLM 네트워크의 효과를 평가.
- 예: "이 영화는 흥미롭다" → "이 영화는 지루하다."
- 비교 조건:
- w/o Feedback: 단순히 입력을 처리하고 결과를 생성.
- w/ Feedback: 네트워크 피드백 메커니즘을 활용하여 감정 표현을 강화.
- 결과:
- 피드백이 없는 경우, ChatLLM 네트워크는 기본 ChatGPT보다 약간 우수.
- 피드백이 적용된 경우, ChatLLM 네트워크는 53:7로 압도적인 성능을 보여줌.
- ChatLLM 네트워크는 더욱 강렬하고 풍부한 감정 표현을 생성.
2. 결론
- ChatLLM 네트워크의 장점:
- 협력적 사고: 다수의 모델이 독립적으로 추론한 결과를 종합, 단일 모델보다 객관적이고 정확한 판단 가능.
- 피드백 기반 학습: 언어 기반 역전파를 통해 점진적으로 성능을 개선.
- 안정성과 유연성: 입력 과부하 방지 및 결과의 일관성 유지.
- 주요 성과:
- Digital Mode Classification과 Sentiment Reversal 실험에서 기존 모델보다 높은 정확도와 안정성을 입증.
- 다수의 모델을 통합하여 문제를 해결하는 새로운 협력형 AI 아키텍처를 제안.
- ChatLLM 네트워크의 기여:
- 대화형 언어 모델의 새로운 협력 구조를 통해 기존 AI 시스템의 한계를 극복.
- 다양한 모델 간 상호작용을 통해 다각적인 문제 해결 가능.
3. 한계와 향후 연구 방향
3.1 한계
- 현재 모델의 한계:
- 대규모 수치 데이터 처리 성능이 제한적.
- 네트워크 확장을 위한 모델 간 통신 메커니즘 부족.
- 복잡한 문제 해결:
- 네트워크가 복잡한 문제를 해결할 때 처리 비용이 증가.
3.2 향후 연구 방향
- 모델 간 통신 전략 개발:
- 모델들 간의 효과적인 정보 전달 메커니즘 구현.
- 모델 아이덴티티 설계:
- 각 모델에 독립적 역할과 아이덴티티를 부여하여 추적 가능성 강화.
- 대규모 네트워크 확장:
- 더 많은 대화형 언어 모델을 통합하고, 다양한 AI 작업에 적용 가능한 범용 네트워크 구축.
4. 마무리
ChatLLM 네트워크는 다수의 대화형 언어 모델을 협력적으로 연결하고, 피드백을 통해 학습 성능을 개선함으로써 기존 AI 시스템의 한계를 극복할 수 있는 잠재력을 보여줍니다. 본 연구는 다중 모델 협력 구조에 대한 새로운 길을 제시하며, 미래의 AI 연구 및 응용에서 중요한 참고 자료로 활용될 것입니다.
1. 논문의 한계점 분석
1.1 기술적 한계
- 대규모 데이터 처리 성능 부족
- 논문에서는 대화형 언어 모델(ChatGPT)을 사용한 협력 네트워크를 제안했으나, 대규모 수치 데이터나 복잡한 입력을 처리하는 데 있어 한계가 있다고 명시.
- 이는 ChatGPT와 같은 기존 모델의 구조적 제약 때문으로 보이며, 네트워크 확장성과 처리 성능 개선이 필요함.
- 모델 간 통신 메커니즘 부족
- 모델들 간의 협력은 리더-직원 구조에 의존하나, 효과적인 통신 프로토콜이나 최적화된 데이터 교환 전략이 부재.
- 이로 인해 더 복잡한 작업을 수행하거나 대규모 네트워크를 구축하는 데 한계가 발생.
1.2 실험적 한계
- 작은 네트워크 크기
- 실험에서는 두 계층으로 구성된 소규모 네트워크(3개의 직원 모델, 1개의 리더 모델)만을 테스트.
- 이는 실제 대규모 시스템에서의 성능을 대표하지 못할 수 있으며, 확장성 및 실질적 유효성에 대한 추가 검증이 필요함.
- 평가 데이터의 제한
- 실험에서 사용된 데이터셋(Digital Mode Classification과 Sentiment Reversal)이 제한적이고 특정 작업에 국한됨.
- 모델이 다양한 유형의 문제(예: 멀티모달 데이터 처리, 복잡한 논리적 추론)에 대해 얼마나 일반화될 수 있는지 확인하기 어렵다.
1.3 피드백 메커니즘의 한계
- 언어 기반 역전파(Language-based Backpropagation)는 기존 신경망의 수치 기반 역전파와 달리 질적으로 피드백을 제공.
- 그러나 피드백 품질과 결과가 모델 성능에 어떻게 영향을 미치는지에 대한 체계적인 분석은 부족.
1.4 모델 간 중복 및 비효율성
- 리더 모델이 직원 모델의 출력을 집계하고 재학습하는 과정에서 중복된 계산이 발생할 가능성 있음.
- 이는 네트워크의 계산 비용 증가 및 효율성 저하로 이어질 수 있음.
2. 논문의 타당성 검증
2.1 강점 평가
- 새로운 접근 방식
- 단일 모델이 아닌 다중 대화형 언어 모델의 협력을 통한 문제 해결은 창의적이고 유용한 접근법.
- 특히 Forward Aggregation과 Language-based Backpropagation은 단일 모델의 한계를 극복하려는 시도로 타당성을 갖춤.
- 성능 개선 증명
- Digital Mode Classification과 Sentiment Reversal 실험에서 ChatLLM 네트워크는 기존 단일 모델 대비 높은 정확도와 안정성을 입증.
- 이는 다중 모델의 협력적 사고와 피드백 메커니즘의 효과를 실험적으로 증명한 것.
- 모델 확장 가능성
- 다양한 대화형 언어 모델(GPT-3.5, T5 등)을 통합할 수 있다는 점에서 ChatLLM 네트워크는 범용성과 확장성을 갖추고 있음.
2.2 약점 보완
- 실험적 일반화 가능성 부족
- 제한된 데이터셋과 소규모 네트워크로 인해, 다양한 문제 유형에서의 성능 검증이 미흡.
- 이는 대규모 네트워크에서의 성능이나, 실제 응용 가능성에 대한 신뢰도를 낮출 수 있음.
- 효율성 문제
- 다수의 모델이 협력하는 구조는 계산 비용 증가를 야기할 수 있으며, 대규모 시스템에서 효율성이 떨어질 가능성 있음.
- 계산 자원과 시간이 제한된 환경에서의 실질적 활용 가능성을 재검토할 필요.
2.3 개선된 실험 설계의 필요성
- 다양한 작업 검증
- 다양한 NLP 작업(예: 논리적 추론, 텍스트 생성, 멀티모달 입력 처리)에서의 성능 평가가 필요.
- 대규모 데이터셋 테스트
- 실제 산업 환경에서 발생하는 복잡한 데이터셋(예: 다중 클래스 분류, 복잡한 텍스트 데이터)으로 테스트 필요.
- 비교 모델의 다양성
- ChatGPT 외에도 다른 최신 언어 모델과의 성능 비교가 필요.
3. 종합적인 평가
3.1 논문의 기여도
- ChatLLM 네트워크는 대화형 언어 모델을 협력적으로 활용하여 기존 AI 시스템의 단일성 문제를 해결하려는 새로운 접근법을 제시.
- Forward Aggregation과 Language-based Backpropagation 메커니즘은 모델 간의 상호작용을 강화하고 성능을 개선하는 데 기여.
3.2 타당성
- 제안된 네트워크는 제한된 실험 환경에서는 유효성을 증명했으나, 실제 환경에서의 확장성과 일반화 가능성은 추가 검증이 필요.
- 모델 간 통신 메커니즘이나 계산 비용 문제를 보완한다면 실질적 활용 가능성이 높아질 것.
3.3 향후 연구 방향
- 대규모 네트워크 환경에서 성능 검증.
- 다양한 작업과 데이터셋을 사용한 일반화 가능성 테스트.
- 계산 비용 최적화 및 통신 효율성을 높이기 위한 개선.
결론
이 논문은 대화형 언어 모델의 협력적 문제 해결 가능성을 실험적으로 입증한 유의미한 연구입니다. 다만, 실험적 제약과 효율성 문제를 보완한다면, AI 시스템의 협력 구조를 더욱 확장하고 실제 응용 가능성을 높이는 중요한 기반이 될 것입니다.
수정 및 개선된 요약
- 다수의 LLM 협력:
- 여러 개의 대규모 언어 모델(LLM)이 협력하여 작업을 수행하는 구조를 제안했습니다.
- 각 모델은 직원(Employee) 역할을 하며, 최상위 리더(Admin) 모델이 이들의 출력을 종합해 최종 결론을 도출합니다.
- Language-based Backpropagation:
- 모델 간 협력에 Reflection(성찰) 과정을 추가하였으며, 이를 Language-based Backpropagation이라고 명명했습니다.
- 리더(Admin) 모델은 직원 모델의 정답 여부를 판단하고, 언어적 피드백을 통해 직원 모델들이 추론 기준을 수정하거나 강화하도록 유도합니다.
- Dropout 메커니즘:
- 기존의 Dropout 메커니즘과 유사한 방식으로 일부 입력 정보를 제한하는 기능을 추가했습니다.
- 이를 통해 모델이 특정 입력에 과도하게 의존하지 않도록 설계하여, 안정적이고 일반화된 성능을 유지할 수 있도록 했습니다.
- 성과:
- 실험 결과, 복잡한 작업은 아니었지만 협력 및 피드백 메커니즘을 통해 성능이 향상된 것을 확인할 수 있었습니다.
- 특히, 감정 반전(Sentiment Reversal) 작업에서 ChatGPT Network는 ChatGPT를 압도하는 성능을 보였으며, 피드백 적용 여부에 따라 성능 차이가 크게 나타났습니다.
기존 요약에서의 부족한 점과 수정 이유
- "Reflection"과 "Language-based Backpropagation"의 연결성 부족:
- 원문에서는 Reflection 과정이 Language-based Backpropagation의 구체적인 일환으로 설명되었지만, 요약에서는 두 개념이 분리된 것처럼 서술되었습니다.
- 이를 보완하여 Reflection이 Language-based Backpropagation의 일부임을 명확히 설명했습니다.
- Dropout 메커니즘의 목표와 효과 부족:
- "지나치게 Input의 영향을 많이 받는 것을 고쳤다"는 표현은 Dropout의 본래 목적과 효과를 충분히 전달하지 못합니다.
- 따라서, Dropout 메커니즘이 입력 과부하를 방지하고 일반화 성능을 높이는 데 기여한다는 점을 추가했습니다.
- 성과에 대한 구체적 설명 부족:
- "복잡한 Task는 아니었지만 성능이 올라간 것을 볼 수 있었다"는 서술은 성과를 구체적으로 전달하지 못했습니다.
- 논문에서 실험으로 다룬 Digital Mode Classification과 Sentiment Reversal 작업, 그리고 피드백 유무에 따른 성능 차이를 반영해 보완했습니다.
이 수정된 요약은 논문의 핵심 개념, 메커니즘, 성과를 더욱 명확히 전달하도록 구성되었습니다. 추가로 궁금한 점이 있다면 알려주세요!